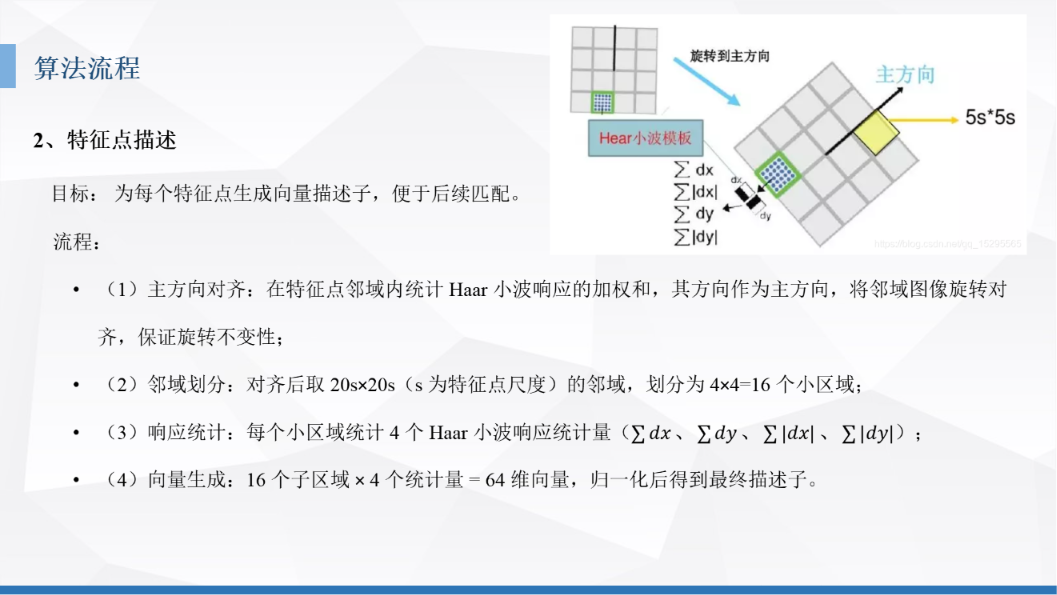
特征
Color Moments(颜色矩)
这里的矩就是概率论与数理统计中的那个矩的意思,这里借用了这个数学方法对图片各通道的颜色进行处理。一般是用到三个矩。

对于三阶矩:若为正值或负值,则分别对应颜色分布呈现右偏或左偏的状态,可用于判断图像是否存在偏色问题。
GLCM(灰度共生矩阵)
统计固定角度,固定距离的两个像素灰度关系的矩阵。举个例子很好理解。
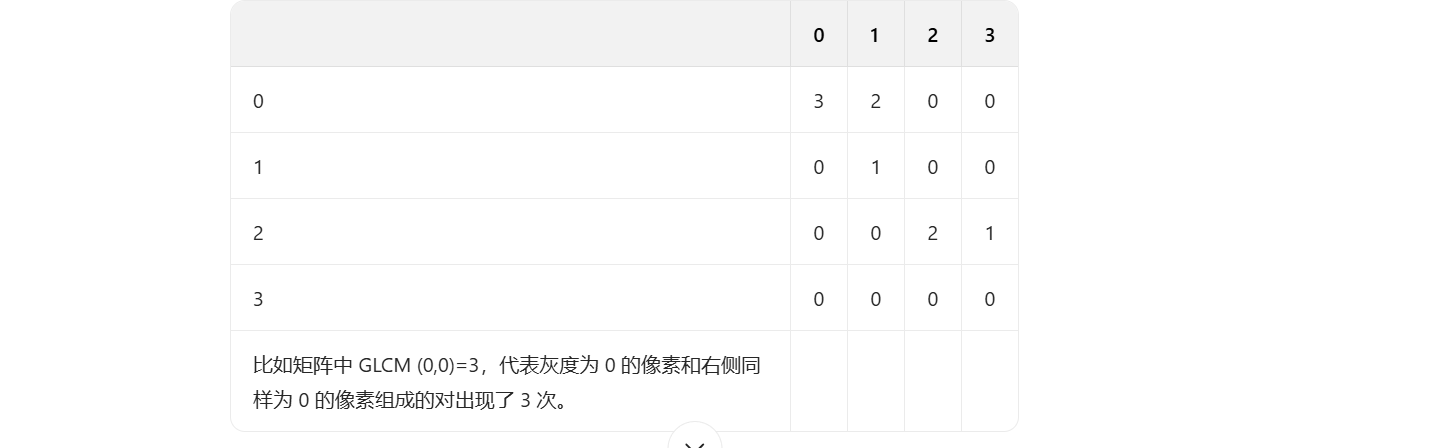
原始灰度图,灰度级设为 0 - 3。
| 0 | 0 | 1 | 1 |
|---|---|---|---|
| 0 | 0 | 1 | 1 |
| 0 | 2 | 2 | 2 |
| 2 | 2 | 3 | 3 |
空间参数:选择水平方向(0°,即像素右侧相邻)、像素间距 d=1,避免复杂计算聚焦核心逻辑。
则GLCM为:
计算完矩阵后在利用特征提取函数提取特征即可:
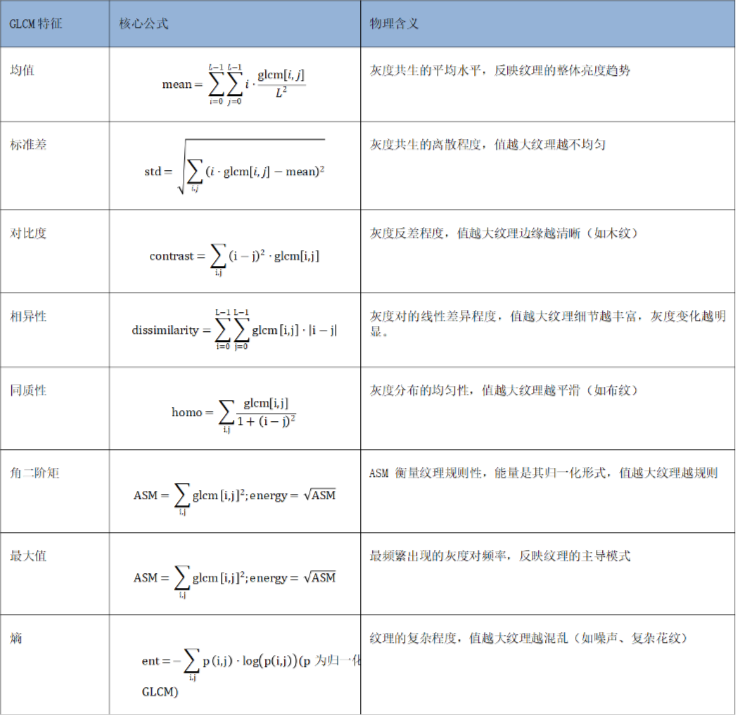
其中常用的有:

实验图像:
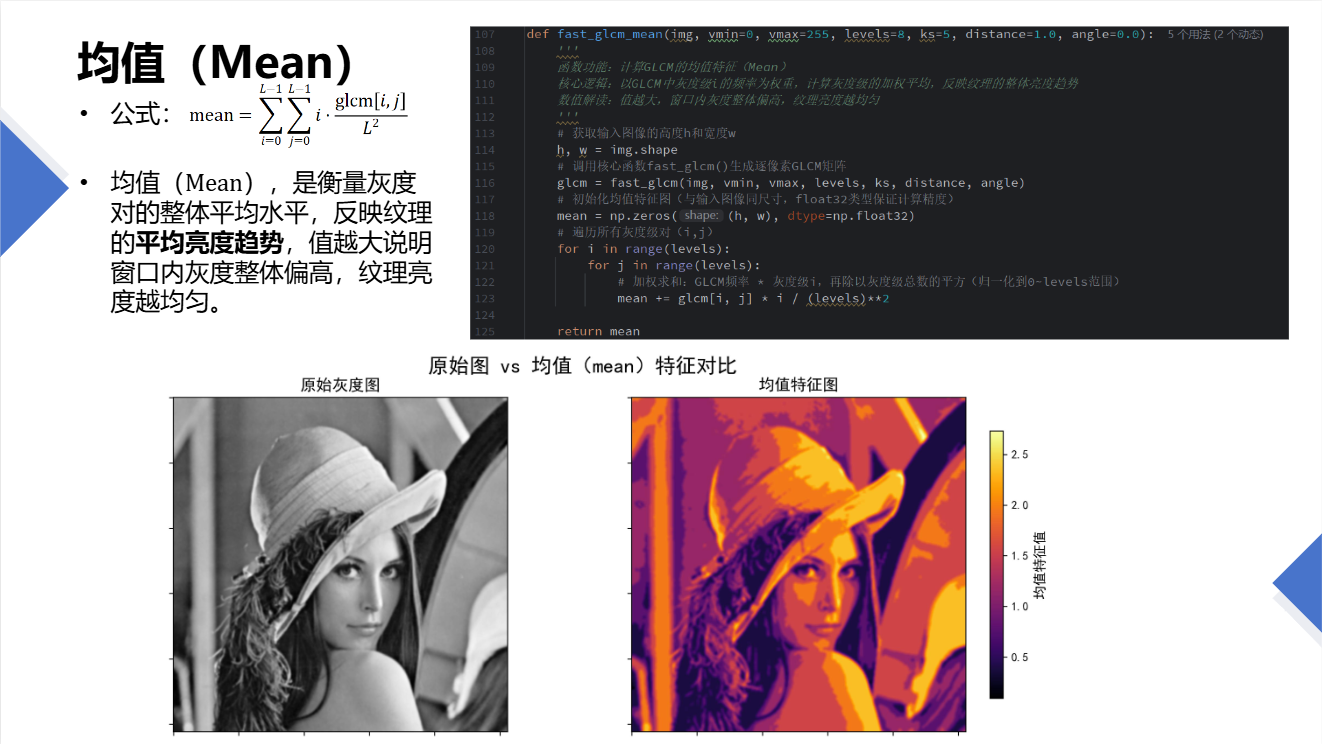
这里使用了滑动窗口的方式用GLCM计算局部的特征均值,得到了整体图像的平均亮度趋势。
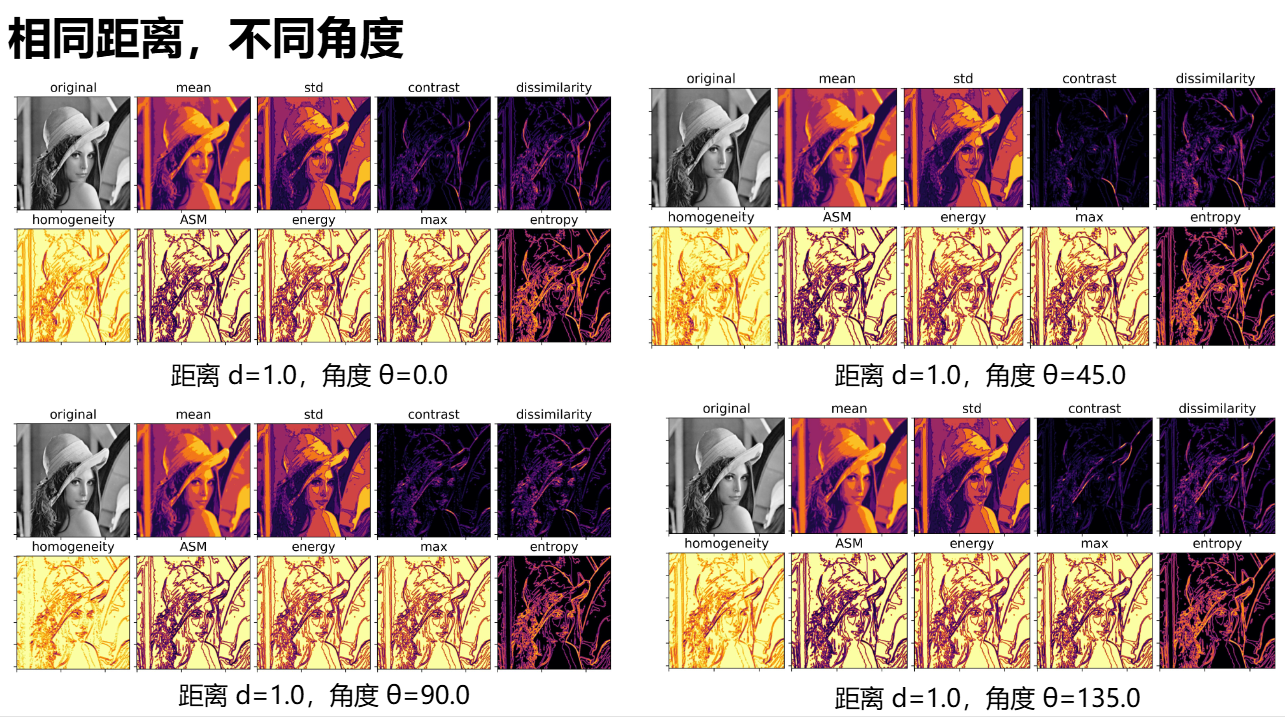
更多的实验:
Gabor特征
简单来说就是一种类似于卷积方法,最后的特征图(这里称响应图),经过一定处理得到特征向量。不同之处在于卷积核的设置。
这里的卷积核被称为Gabor滤波器,这是一种由人眼细胞对光线敏感方式启发得到的算法。
Gabor滤波器数学表达:

其四个参数决定的特征:

处理后得到的响应图求均值和方差,最后将所有的均值和方差拼到一起得到特征向量。
SIFT
技术的要点在于找出一些对于放缩和旋转变化不敏感的点,求这些点的特征方向(用与周围的像素的梯度去求),然后将该点周围的区域划分为多个小块,求每个小块的方向信息(有8个方向),假设是划分为16个小块,就有16 * 8 = 128为特征描述符;主要依靠特征描述符匹配点。而特征方向用于计算旋转的角度。

详情查看知乎文章:https://zhuanlan.zhihu.com/p/1971715281597465025
SUFT
加速过后的SIFT,用到了很多不同的技术,最后也是生成特征向量。



总之比较复杂,我也看不太懂。
ORB
FAST(高速角点检测)
角点:


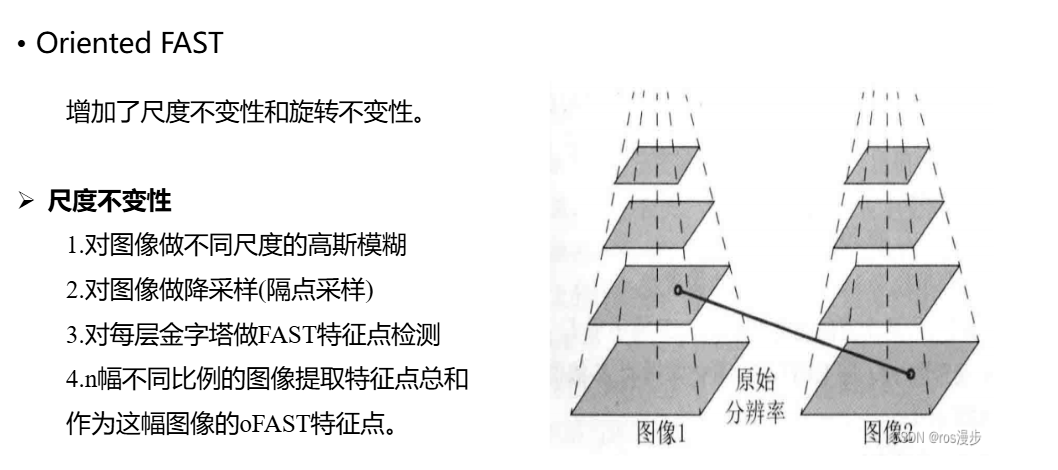
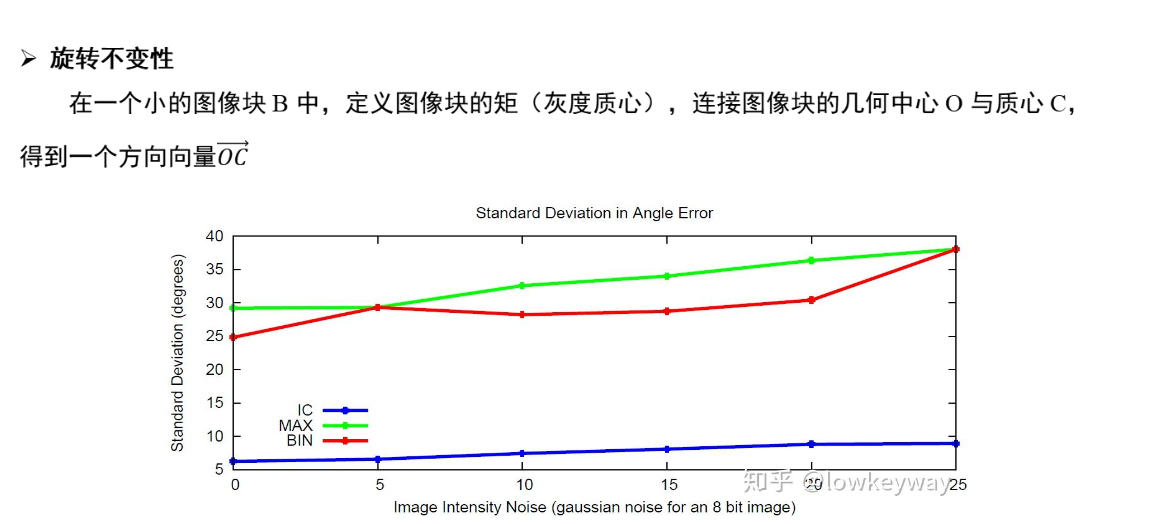
OFAST
对FAST的改进
BRIEF


HOG(方向梯度直方图)
常用于行人检测。
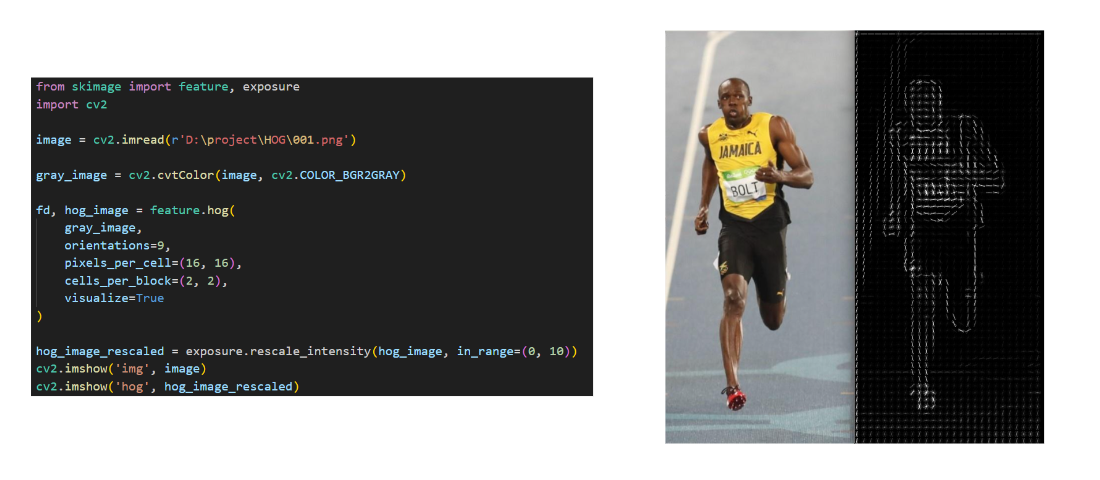
依然是一种求梯度的方法
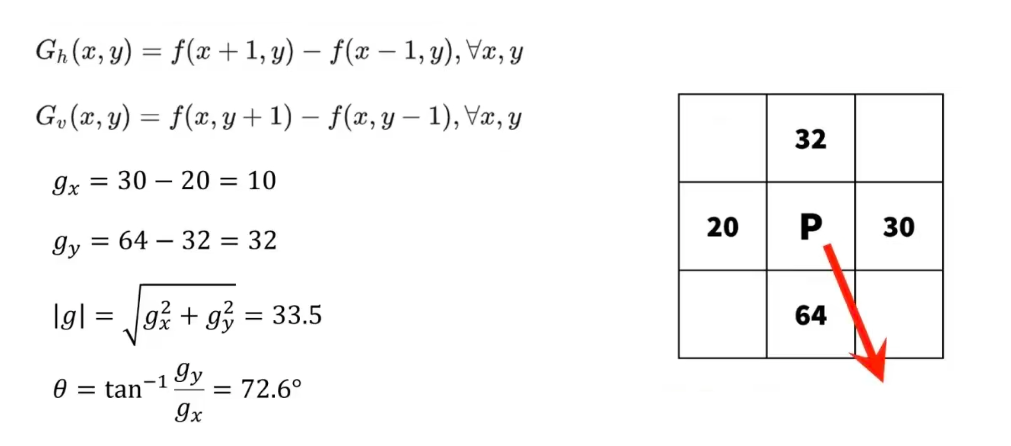
通过求梯度得到梯度的大小和方向
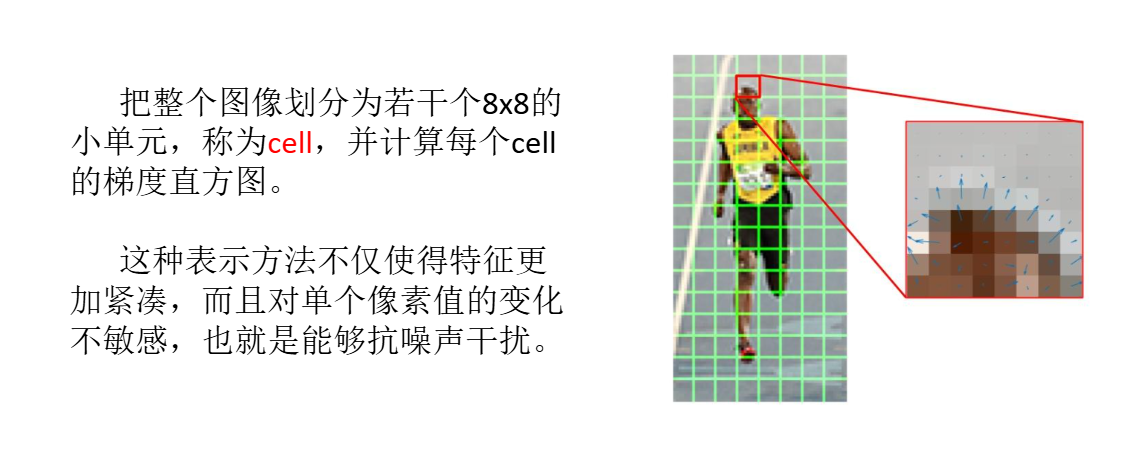
求每个划分区域的梯度然后统计为直方图

然后再划分滑动窗口:

最后拼接成特征向量。
特征编码
将局部特征编码为更加紧凑的全局特征
Bag-of-Words
本质是用词频当作词的特征向量

一个简单的例子,便于理解

VLAD(Vector of Locally Aggregated Descriptors)向量局部聚合描述符

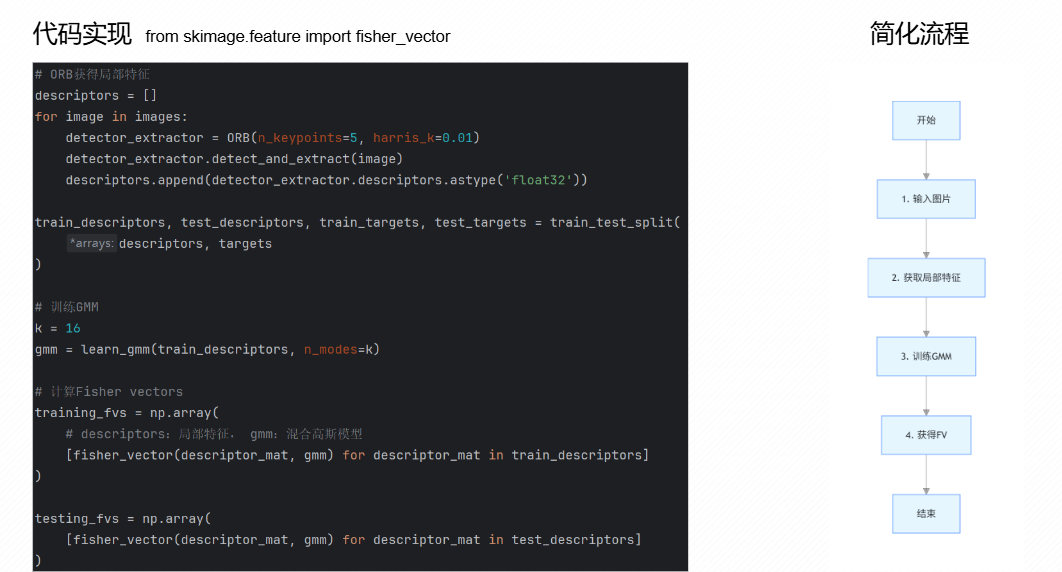
Fisher Vector(FV)是基于概率模型的图像特征聚合技术
是更好的图像特征聚合技术,比VLAD更好

以上是大致步骤,下面是数学方法




Spatial Pyramid Matching(SPM,空间金字塔匹配)


索引
Invert Index(倒排索引)


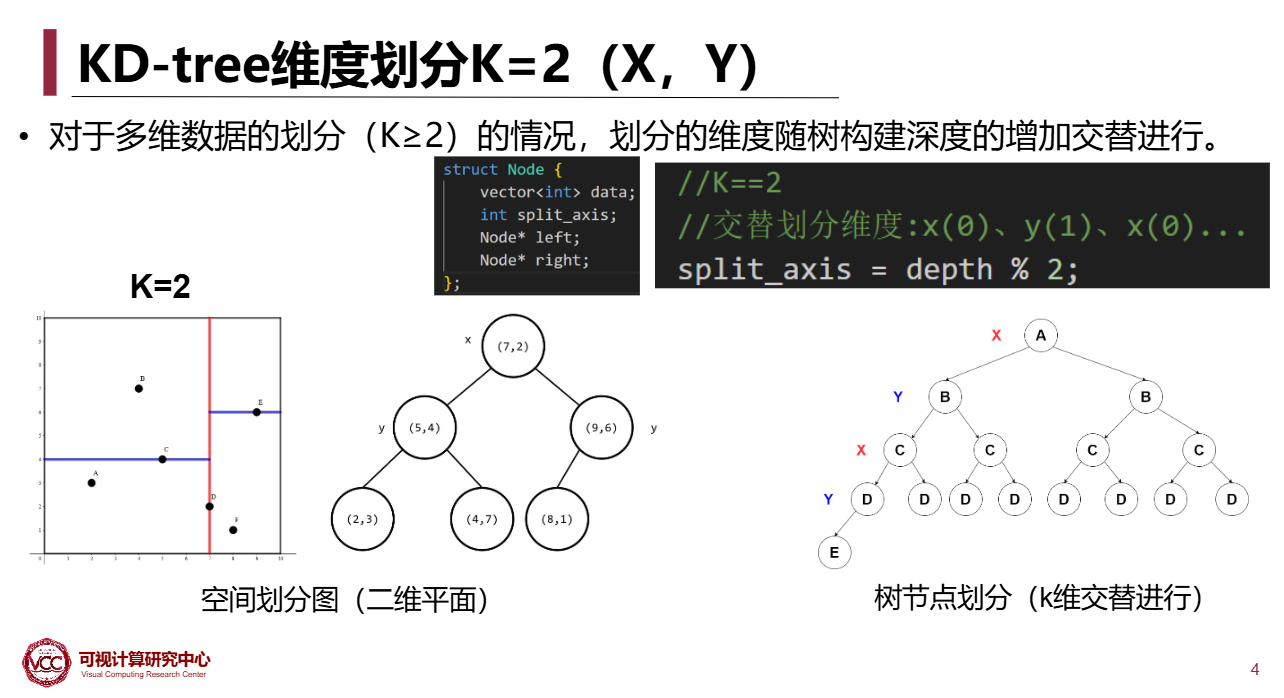
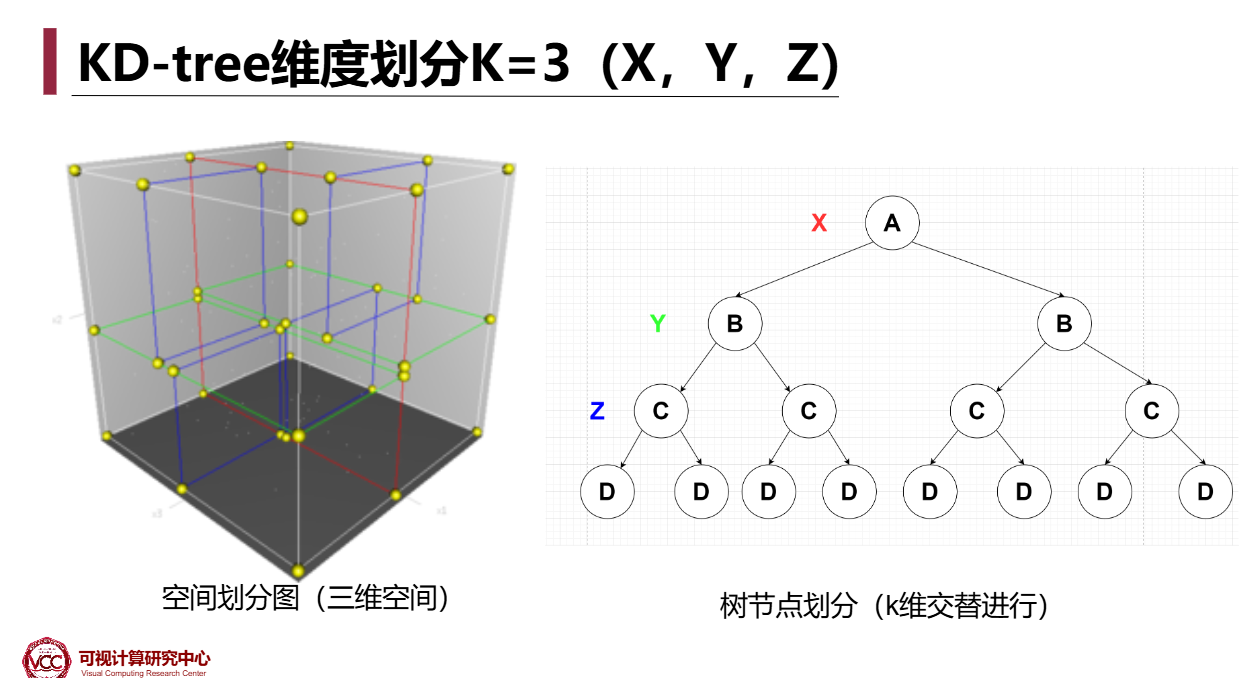
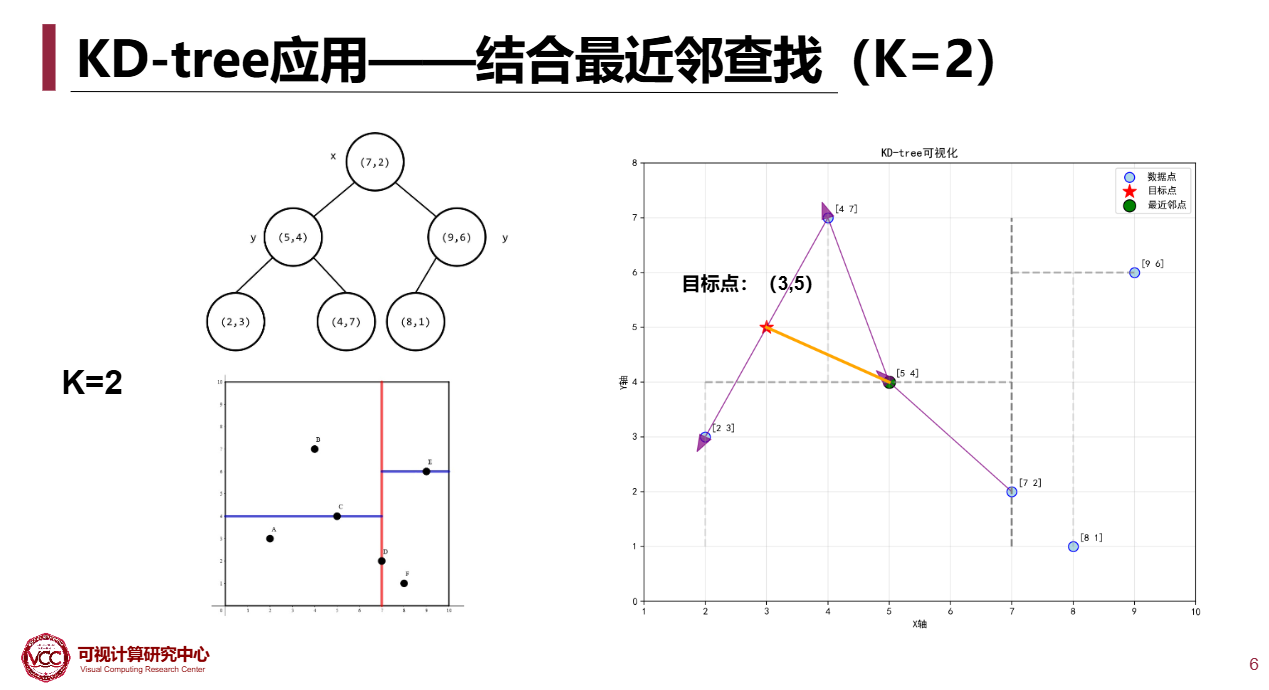
KD-Tree
K维的二叉搜索树

2维时的情况
3维的情况
几何验证
几何验证是通过几何原理、空间约束关系,检验数据(如特征点、匹配对、三维模型)是否符合真实物理空间规律的过程,目的是剔除错误数据、确保结果的准确性。
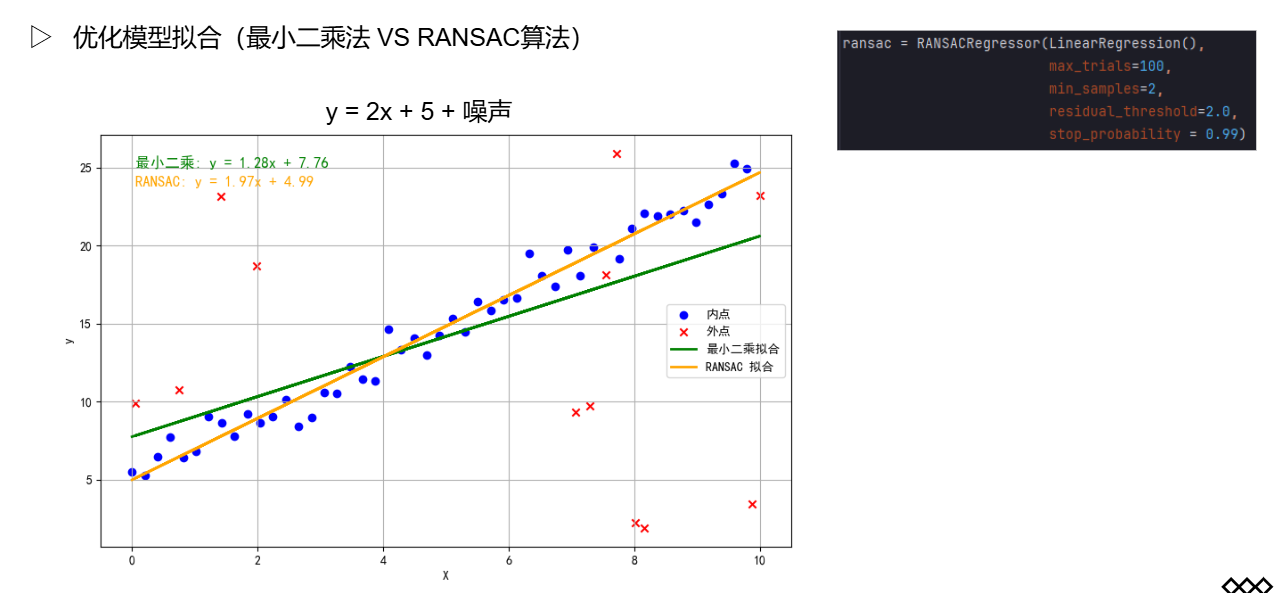
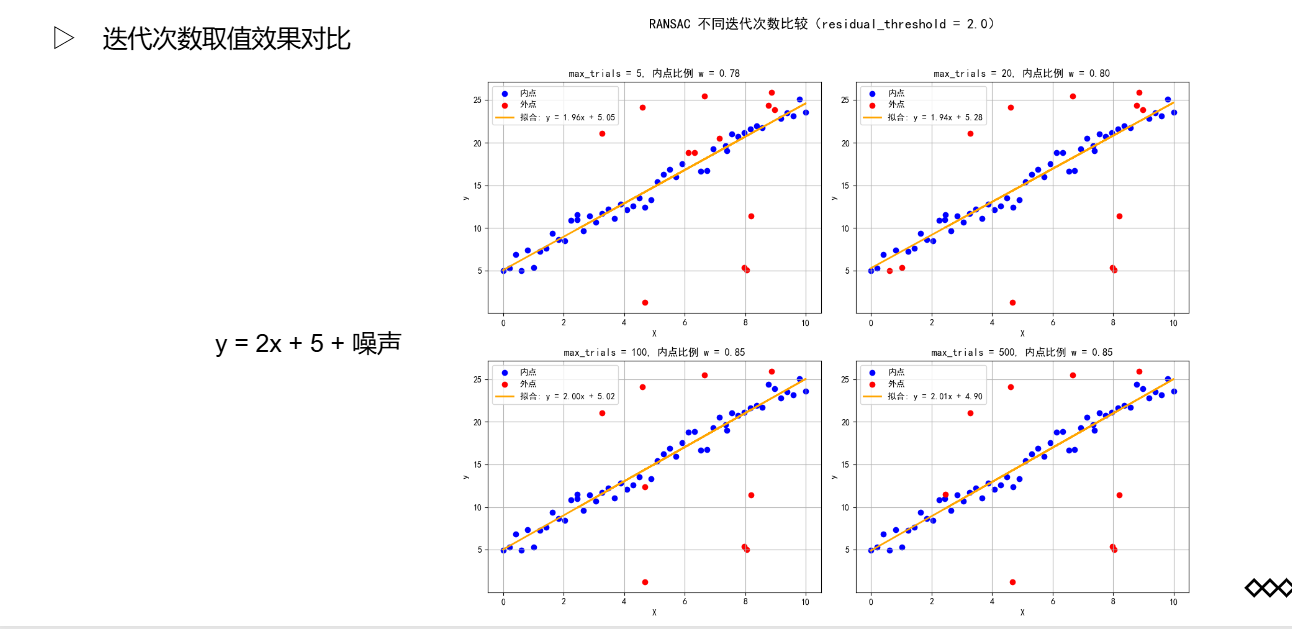
RANSAC算法
随机抽样一致算法(RANdom SAmple Consensus,RANSAC)是一种迭代方法,用于从一组包含异常值的观测数据中估计数学模型的参数,也可以被解释为一种异常值检测方法。


深度学习架构
Siamese Network(孪生网络)
专门用于比较两张图片相似性的网络,学习的特征是两张图的差异性。
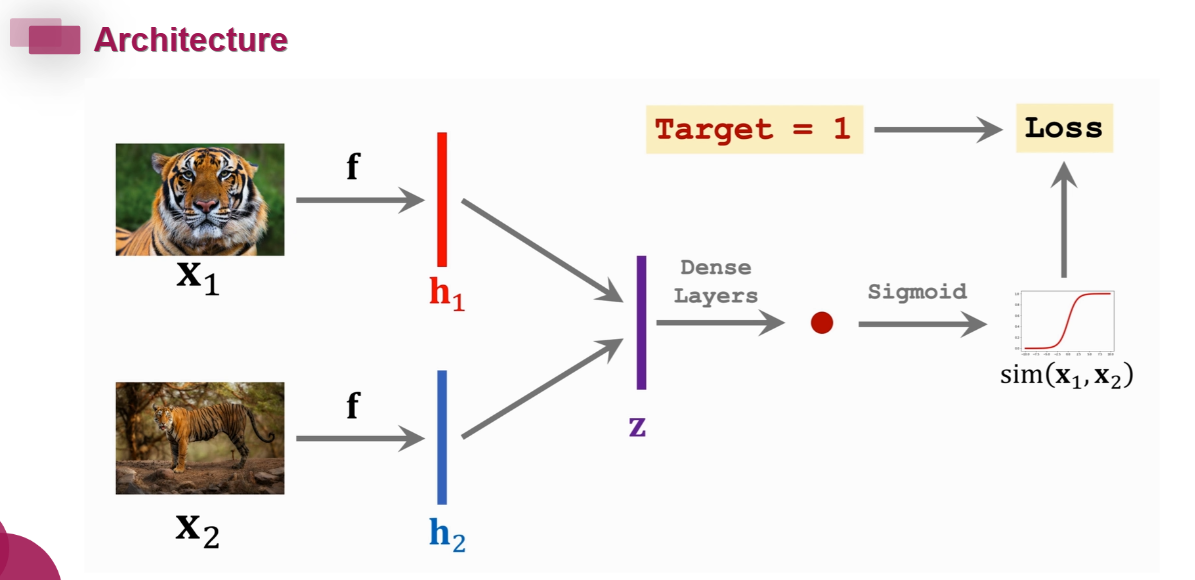
图中的两个f都是一个网络,它将图片变成特征向量(h1, h2),然后学习两个特征向量的差值(z)。
Triplet Loss
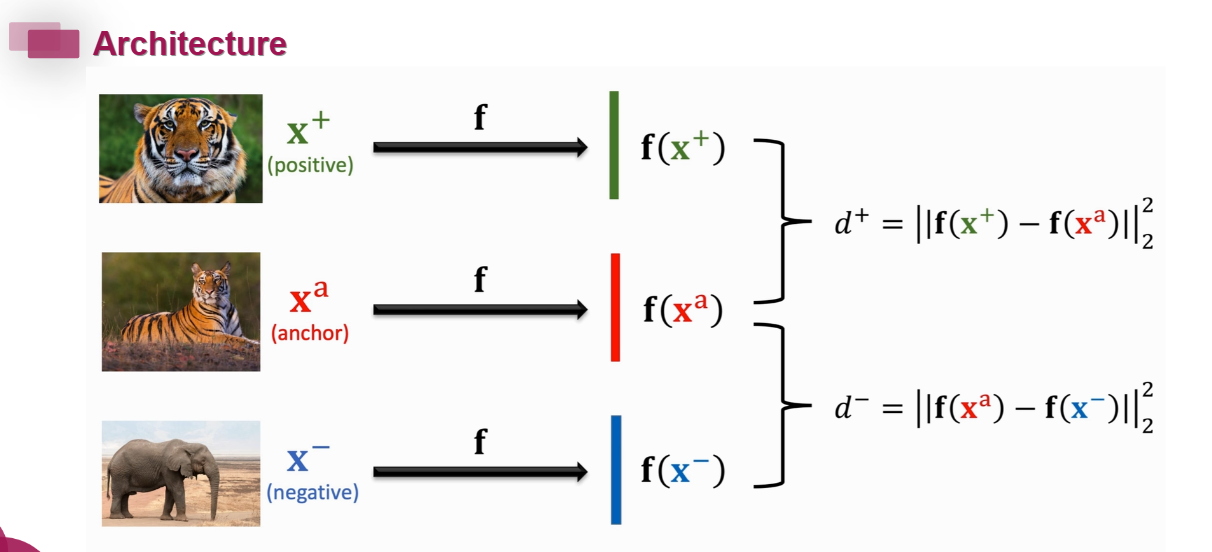
Anchor是锚点的意思,选出一张和它同一类的图片和一张不是同一类的图片。

这里的m是一个超参数,规定了找到锚点的相近图片与不相近图片差异要足够大时才判断网络分辨有效。
Vit(Vision Transformer)
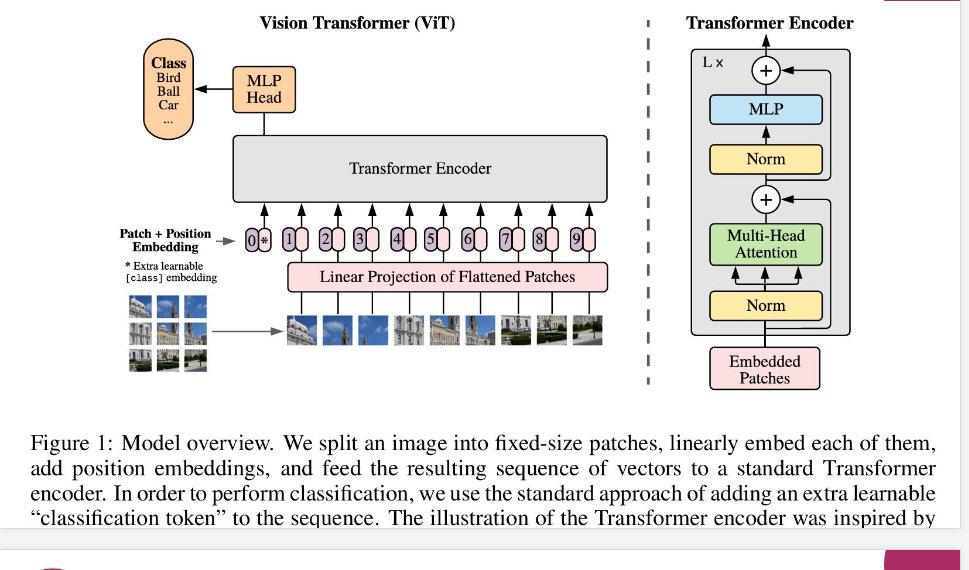
简而言之,将图片分割成小块当成序列输入进transform。
在大规模数据集上比卷积神经网络更有效
CLIP网络
跨模态网络。主要解决图文问题。
关键点:数据集是从互联网找到的图文匹配对。互联网中天然的就有很多图文相关的数据(比如商品图和商品描述)
结构:

DINOv2

度量学习
度量学习旨在学习一个合适的距离(或相似度)度量,让相似样本的距离更小、不相似样本的距离更大,从而提升后续任务效果。
Triplet Loss
一种专门计算相似度的损失函数

Contrastive Loss(对比损失)

ArcFace(Arc Loss / 球面角损失)
是人脸识别领域里程碑式的度量学习损失函数,核心是在特征球面空间中直接优化类别间的角度边界,让不同类别的特征分布更具区分度,大幅提升识别准确率。

特点是利用特征向量夹角的差异。