摘要
本周学习了自然语言处理模型的前置知识和docker在windows及linux系统的安装,自然语言学习的是如何从预训练到transform,词向量的训练和产生、RNN模型。
Abstract
This week, I studied the foundational knowledge of natural language processing models and the installation of Docker on Windows and Linux systems. In natural language learning, I focused on how to go from pre-training to transformers, training and generating word vectors, and RNN models.
1 序列模型
在时间t观察到数据xtx_txt,那么得到T个不独立的随机变量(x1,...,xT)∼p(x)(x_1,...,x_T) \sim p(x)(x1,...,xT)∼p(x)
根据条件概率展开p(a,b)=p(a)p(b∣a)=p(b)p(a∣b)p(a,b)=p(a)p(b|a)=p(b)p(a|b)p(a,b)=p(a)p(b∣a)=p(b)p(a∣b)
p(xt∣x1,...,xt−1)=p(xt∣f(x1,...,xt−1))p(x_t|x_1,...,x_{t-1})=p(x_t|f(x_1,...,x_{t-1}))p(xt∣x1,...,xt−1)=p(xt∣f(x1,...,xt−1))
马尔可夫假设
当前数据只跟过去θ\thetaθ个数据点相关
p(xt∣x1,...,xt−1)=p(xt∣xt−θ,...,xt−1)=p(xt∣f(xt−θ,...,xt−1))p(x_t|x_1,...,x_{t-1})=p(x_t|x_{t-\theta},...,x_{t-1})=p(x_t|f(x_{t-\theta},...,x_{t-1}))p(xt∣x1,...,xt−1)=p(xt∣xt−θ,...,xt−1)=p(xt∣f(xt−θ,...,xt−1))
潜变量hth_tht来表示过去信息ht=f(x1,...,xt−1)h_t=f(x_1,...,x_{t-1})ht=f(x1,...,xt−1)
这样xt=p(xt∣ht)x_t=p(x_t|h_t)xt=p(xt∣ht)
1.1文本预处理
文本预处理是自然语言处理(NLP)中的基础且关键步骤,它将原始的非结构化文本数据转化为适合机器学习模型处理的格式。
文本预处理需要把文本的特殊符号去掉然后分词,把一句话的词都分开。
1、替换特殊符号
python
def load_txt():
with open('../dataset/timemachine.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+',' ',lines).strip().lower() for lines in lines]
content=load_txt()2、分词
分词的代码是李沐老师的课程的,其实可以直接调库nltk进行分词。
python
def tokenize(text,token='word'):
if token=='word':
return [line.split() for line in text]
elif token=='char':
return [list(line) for line in text]
tokens=tokenize(content)1.2词向量
词向量是每个词之间的关系,可以通过点积或者余弦相似度进行标识
a⋅b=∑i=1naibia\cdot b=\sum_{i=1}^n a_ib_ia⋅b=∑i=1naibi
cos(θ)=a⋅b∣a∣⋅∣b∣cos(\theta)=\frac{a\cdot b}{|a|\cdot |b|}cos(θ)=∣a∣⋅∣b∣a⋅b
word2vec
Cbow和Skip-gram的目标都是获得词向量矩阵(Embedings)
1、设置上下文窗口
'we are about to study the idea of deep learning'
设置上下文窗口为2
we、are、to、study中心词about
are、about、study、the中心词to
2、预测目标词
将词转化为onehot编码(1*N),然后通过Cbow模型求embeddings矩阵(N*V),得到词向量(1*V)。
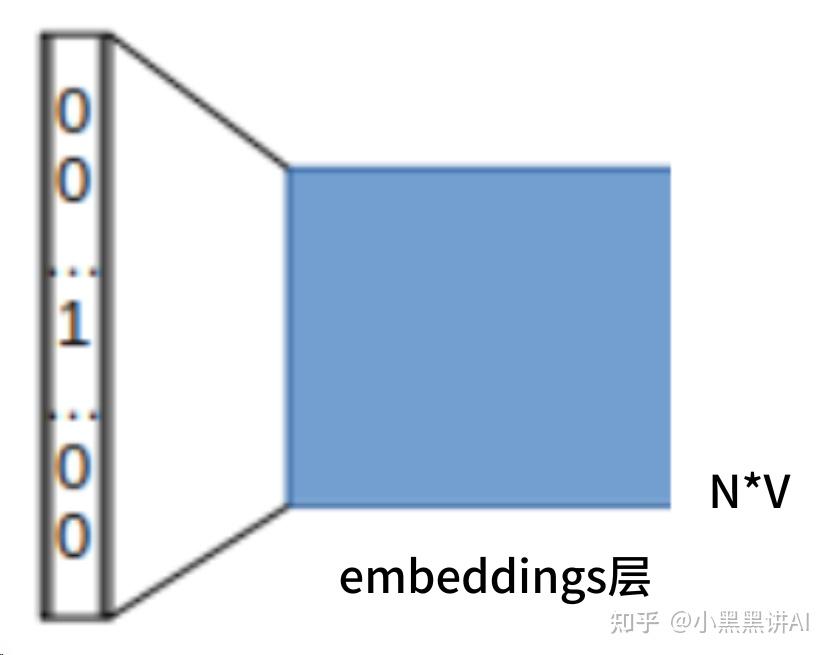
上下文包含多个词语,同时输入embeddings层,每个词语都会转化成一个词向量。

3、线形层
V*N大小的线性层
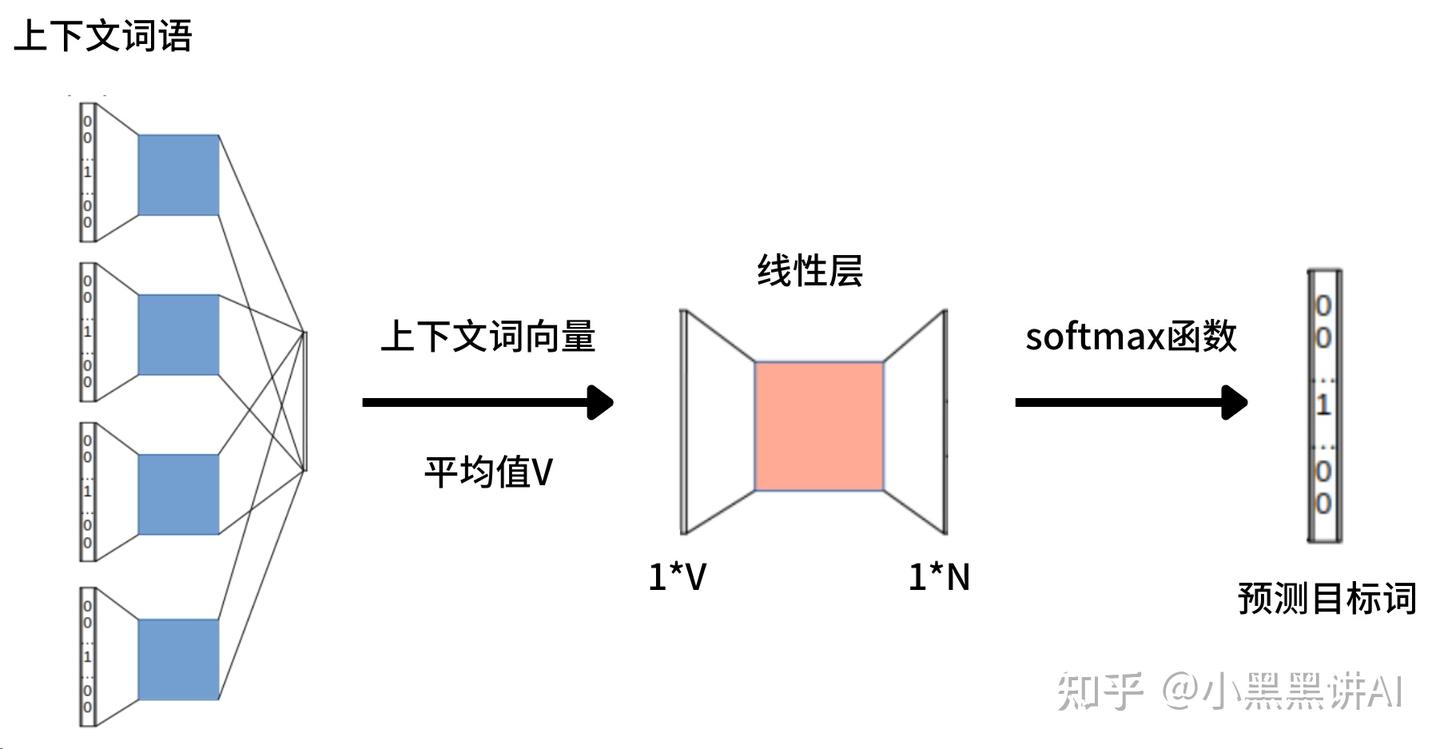
Cbow和Skip-gram模型都是简单的模型,缺点是不能对多义词进行区分。
Cbow模型的重点不是预测的结果,而且训练的过程,对中心词计算损失是为了让Embeddings矩阵更加的合理,每个词最终通过embeddings变成一个词向量,损失是衡量模型有没有捕捉到词与词之间的关系。
python
import numpy as np
from torch import nn
import torch
from torch.optim import SGD
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
text = ['i', 'want', 'to', 'study', 'eat', 'a', 'banana', 'apple']
one_hots = np.eye(len(text))
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# 简化向量的生成
self.embedding = nn.Embedding(8, 4)
self.linear = nn.Linear(4, 8)
def forward(self, x):
# 经过embeddings矩阵的输出
x = self.embedding(x)
v = x.mean(dim=1)
return self.linear(v)
loss_fn = nn.CrossEntropyLoss()
model = Model()
loss_f = loss_fn.to(device)
model = model.to(device)
optimizer = SGD(model.parameters(), lr=0.1)
epochs = 20
for epoch in range(epochs):
for i in range(2, 6):
# 左开右闭
train_index = [i - 2, i - 1, i + 1, i + 2]
train_tensor = torch.tensor(train_index, dtype=torch.long).unsqueeze(0).to(device)
output = model(train_tensor)
loss = loss_fn(output, torch.tensor([i],dtype=torch.long).to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印每次训练,每个词的loss
print(f"epoch:{epoch},loss:{loss.item()}")
test_loss = 0
test_accuracy = 0
with torch.no_grad():
for i in range(2, 6):
train_index = [i - 2, i - 1, i + 1, i + 2]
train_tensor = torch.tensor(train_index, dtype=torch.long).unsqueeze(0).to(device)
output = model(train_tensor)
test_loss += loss_fn(output, torch.tensor([i], dtype=torch.long).to(device)).item()
pred = torch.argmax(output)
test_accuracy += (pred == torch.tensor(i)).sum()
print(f"epoch:{epoch},loss:{test_loss},accuracy:{test_accuracy / 4}")
embedding=model.embedding.weight.cpu().detach().numpy()
outputs=np.matmul(one_hots,embedding)
for output in outputs:
print(output)
'''
[ 0.93484521 -0.85562724 1.32007921 -0.22474325]
[-0.36275959 -0.29074112 1.1880306 -0.17583109]
[-0.33565277 1.7831372 -1.28465486 1.35978901]
[ 0.49673116 0.33520833 -2.08854532 -0.65443164]
[ 1.23739493 -0.38772917 -0.64865047 -1.32997036]
[ 0.6132136 1.30595243 -0.69833374 1.12736475]
[-1.13126886 0.46875766 -1.32841444 -1.22045767]
[ 0.65302128 0.90104347 -0.61300308 -0.92901689]
'''下面注释的部分就是生成的词向量。
1.3 RNN模型
中间插入一个RNN模型,因为在接下来的ELMo模型中有用到RNN模型。
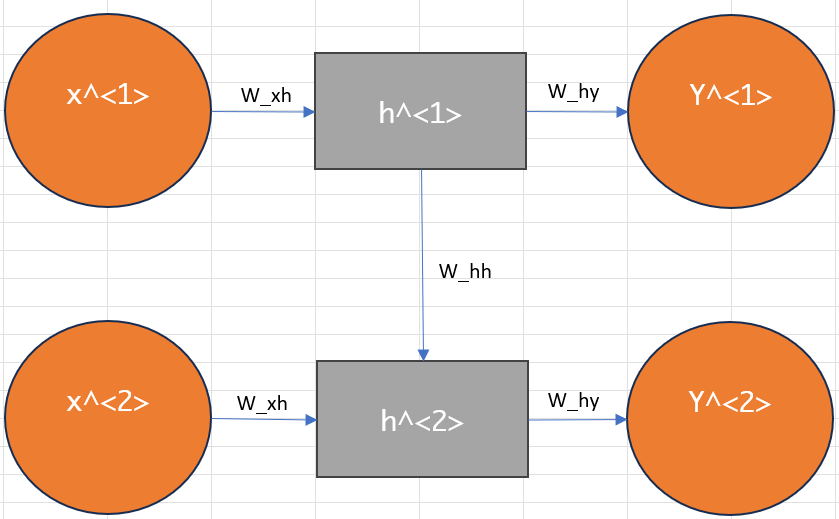
RNN 的工作机制
RNN 在每个时间步 t 执行以下计算:
1、接收当前输入 xtx_txt 和前一时刻的隐藏状态 ht−1h_{t-1}ht−1
2、计算新的隐藏状态 ht=f(Whh⋅ht−1+Wxh⋅xt+b)h_t = f(W_{hh}\cdot h_{t-1} + W_{xh}\cdot x_t + b)ht=f(Whh⋅ht−1+Wxh⋅xt+b)
3、产生输出 yt=g(Why⋅ht+c)y_t = g(W_{hy}·h_t + c)yt=g(Why⋅ht+c)
python
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
torch.manual_seed(42)
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.rnn(x, h0)
out = out[:, -1, :]
out = self.fc(out)
return out
input_size = 10
hidden_size = 20
output_size = 5
num_layers = 2
model = SimpleRNN(input_size, hidden_size, output_size, num_layers)
print(model)
def generate_synthetic_data(seq_length, num_samples, input_size, output_size):
X = torch.randn(num_samples, seq_length, input_size)
Y = torch.zeros(num_samples, output_size)
for i in range(num_samples):
seq_sum = torch.sum(X[i], dim=0)
Y[i] = torch.tanh(seq_sum)[:output_size]
return X, Y
seq_length = 7
num_samples = 100
X_train, Y_train = generate_synthetic_data(seq_length, num_samples, input_size, output_size)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
num_epochs = 100
for epoch in range(num_epochs):
outputs = model(X_train)
loss = criterion(outputs, Y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')以上是一个简单的RNN模型
1.4 ELMo模型
ELMo模型是解决多义词的模型,在训练embeddings的过程中,融入上下文信息到embeddings矩阵中。
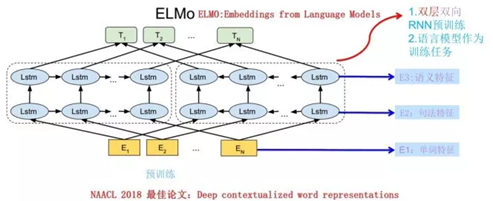
训练模型时,会得到三层与文本有关的信息,TiT_iTi是生成的词向量,然后调整三层embeddings矩阵。
结合句法、语义特征会对不同义的词生成不同的词向量。
2 环境部署
2.1 Windows安装docker
先安装wsl.exe
bash
wsl --install
#设置为wsl2
wsl.exe --set-default-version 2按下 Ctrl + Shift + Esc 打开任务管理器
切换到 性能 选项卡
查看右下角 虚拟化 是否为 已启用
前往https://www.docker.com/products/docker-desktop/下载windows对应安装包
下载完成后,双击进行安装。
安装完成后打开docker.desktop
2.2 Ubuntu安装docker
先下载相关依赖
bash
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get update
sudo apt-get install docker-ce=5:19.03.5~3-0~ubuntu-xenial docker-ce-cli=5:19.03.5~3-0~ubuntu-xenial containerd.io
sudo vim /etc/docker/daemon.json <<EOF
{
"registry-mirrors": [
"https://docker.xuanyuan.me"
]
}
EOF安装docker是为了部署大模型,但是网上的教程都是在本地使用ollama部署模型后再通过docker启动openwebui进行类似chat-gpt的使用方法,觉得好像不对。
总结
本周对文本处理和预训练进行学习,下周将继续完成后续的transform相关知识。