GPT-SoVITS 是一个强大的开源语音克隆和文本转语音(TTS)项目 GitHubLightning AI。它有以下主要特点:
功能:
- 仅需1分钟的语音数据就能训练出高质量的TTS模型 GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)
- 只需提供5秒的语音样本就能体验到80%-95%相似度的语音克隆 OpenVINO™ Blog | OpenVINO Enable Digital Human-TTS (GPT-SoVITs)
- 支持中文、英文、日文、韩文和粤语
特色:
- 零样本语音转换:无需预训练即可进行语音克隆
- 少样本微调:用极少的数据就能获得接近真人的效果
- 跨语言推理:可以处理与训练数据集不同的语言
实用工具: 集成了语音伴奏分离、自动训练集分割、中文ASR和文本标注等工具 GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning),帮助初学者创建训练数据集。
使用便利性:
- 提供了Web界面(WebUI)
- 支持Docker部署
- 有预训练模型可下载使用
GPT-SoVITS 使用指南
一、环境要求
系统要求:
- Windows 10及以上
- Linux(推荐)
- macOS(训练效果较差,建议用CPU)
硬件要求:
- Python 3.10 GPT-SoVITS/docs/cn/README.md at main · RVC-Boss/GPT-SoVITS
- 建议有GPU(CUDA支持)
- 至少8GB内存
二、安装方法
方法1:Windows一键整合包(推荐新手)
方法2:源码安装
# 创建conda环境
conda create -n GPTSoVits python=3.10
conda activate GPTSoVits
# 下载项目
git clone https://github.com/RVC-Boss/GPT-SoVITS
cd GPT-SoVITS
# 安装依赖
bash install.sh --device <CU126|CU128|ROCM|CPU>三、使用流程
快速体验(零样本TTS)
- 启动WebUI :访问 http://127.0.0.1:7860/ GPT-SoVITS/docs/cn/README.md at main · RVC-Boss/GPT-SoVITS
- 选择推理页面 :进入
1-GPT-SoVITS-TTS→1C-推理 - 上传参考音频 :提供3-10秒的参考音频 GPT-SoVITS 本地化部署及使用 详细教程-CSDN博客
- 填写参考文本:输入参考音频对应的文字
- 输入合成文本:写入要生成的语音内容
- 点击"合成语音"
训练自定义模型(推荐方法)
第一步:数据预处理
- 人声分离 :选择 "0a-UVR5人声伴奏分离&去混响去延迟工具",开启UVR5-WebUI GPT-SoVITS-WebUI一键整合包及使用教程,更新至V2版本_学术FUN
- 语音切分 :使用 "0b-语音切分工具" 将音频切成多个小段 XueshuJiangkl
- 语音识别 :选择 "0c-中文批量离线ASR工具" 进行语音转文字 GPT-SoVITS-WebUI一键整合包及使用教程,更新至V2版本_学术FUN
- 文本校对 :使用 "0d-语音文本校对标注工具" 校对识别结果 GPT-SoVITS-WebUI一键整合包及使用教程,更新至V2版本_学术FUN
第二步:格式化数据
- 进入
1A-数据集格式化页面 - 填写实验/模型名(不要使用中文) GPT-SoVITS语音合成模型实践 - 哥不是小萝莉 - 博客园
- 可以选择逐个点击三个按钮,或直接使用"开启一键三连" 手把手教安装部署史上最简单语音克隆AI大模型_gpt-sovits ...
第三步:模型训练
- SoVITS训练 :
- 设置batch_size为显存的一半以下 GPT-SoVITS语音合成模型实践 - 哥不是小萝莉 - 博客园
- SoVITS可以设置较高轮数,训练速度较快 GPT-SoVITS语音合成模型实践 - 哥不是小萝莉 - 博客园
- GPT训练 :
- 建议设置轮数为10,不要超过20 GPT-SoVITS语音合成模型实践 - 哥不是小萝莉 - 博客园
- 注意:两个训练不能同时进行
第四步:模型推理
- 选择 "1C-推理" 子选项卡,配置模型路径 GPT-SoVITS语音合成模型实践 - 哥不是小萝莉 - 博客园
- 点击 "开启TTS推理WEBUI" 按钮打开推理页面 GPT-SoVITS语音合成模型实践 - 哥不是小萝莉 - 博客园
- 输入文本并生成语音
四、使用技巧
音频质量要求:
- 准备3-5分钟尽量干净无噪声、无背景音乐的人声音频 昆仑的山头 >> 使用GPT-SoVITS克隆声音
- 参考音频选择很重要,参考文本的语速和情感会影响合成结果 GPT-SoVITS 本地化部署及使用 详细教程-CSDN博客
文本处理:
- 文字过长时GPT-SoVITS会出现吞字、重复等问题,需要进行文本切分 GPT-SoVITS 本地化部署及使用 详细教程-CSDN博客
- 可使用页面底部的切分工具或手动换行切分
模型选择:
- V2版本:对低音质参考音频合成效果更好,支持五种语言 GPT-SoVITS-WebUI一键整合包及使用教程,更新至V2版本_学术FUN
- V3/V4版本:音色相似度更高,GPT合成更稳定 GPT-SoVITS/docs/cn/README.md at main · RVC-Boss/GPT-SoVITS
五、支持的功能
- 多语言支持:中文、英文、日文、韩文、粤语
- 跨语言合成:训练集、参考音频和目标语言可以不同
- API调用:支持批量处理和程序集成
- 语速控制:可调节合成语音的语速
GPT-SoVITS是目前效果最好的开源语音克隆工具之一,只需1分钟音频就能训练出"一摸一样"的音色 有手就会的GPT-SoVITS小白教程 - 知乎,非常适合个人用户和开发者使用。
训练和推理的话,训练是训练什么?训练出的东西是什么?模型吗?推理是用什么推理?
解析GPT-SoVITS语音合成模型的训练和推理过程
用户想了解GPT-SoVITS中训练和推理的具体概念:
- 训练是训练什么?
- 训练出的东西是什么?
- 推理是用什么推理?
我需要解释清楚:
- 训练的目标:训练语音合成模型
- 训练的输入:音频数据和对应文本
- 训练的输出:模型权重文件
- 推理的过程:使用训练好的模型生成语音
- 推理的输入:文本和参考音频
- 推理的输出:合成的语音
从搜索结果中可以看到相关信息。
基于之前的搜索结果,我来详细解释GPT-SoVITS中训练和推理的概念:
训练部分
训练是训练什么?
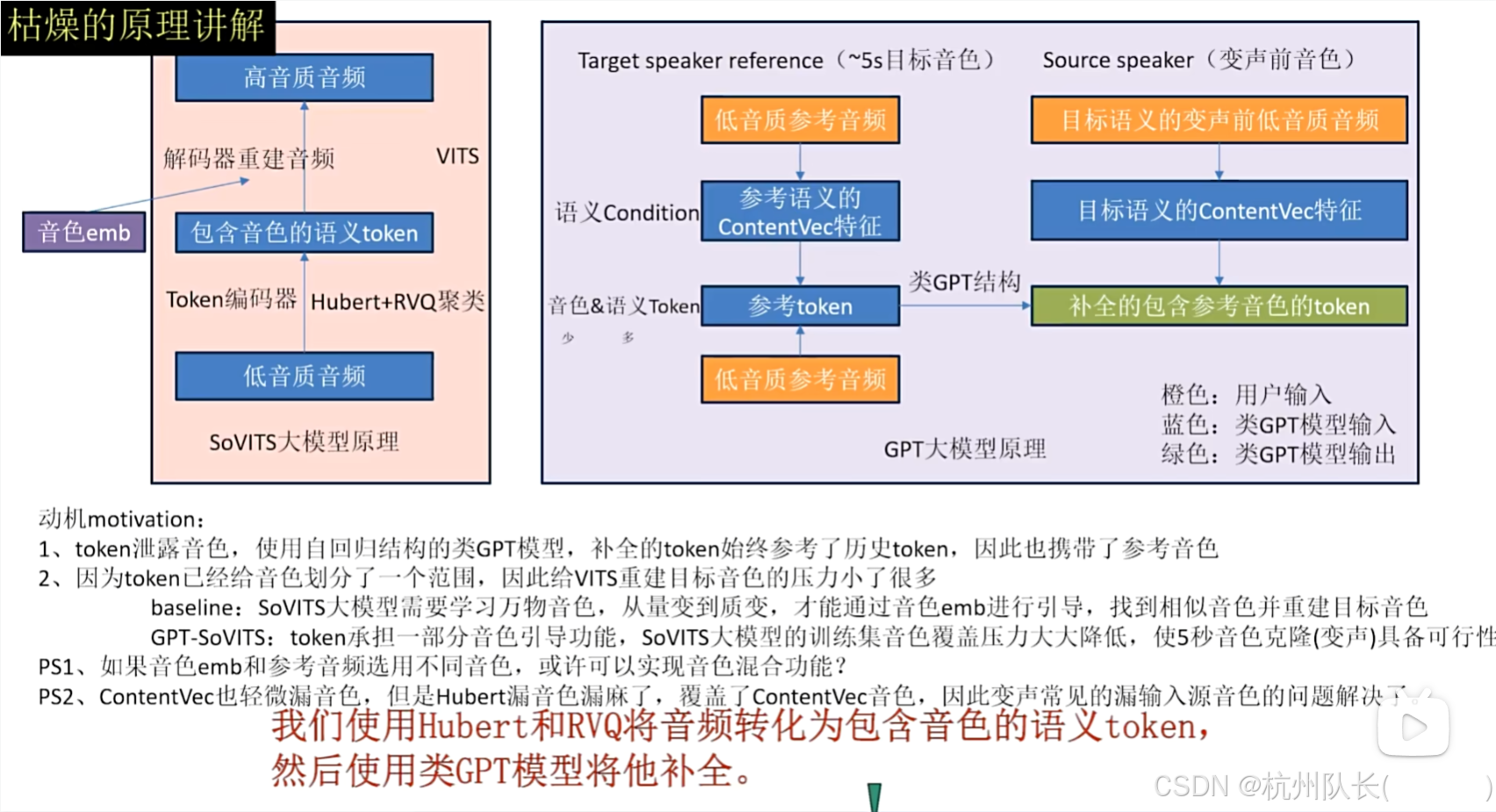
GPT-SoVITS实际上要训练两个独立的模型:
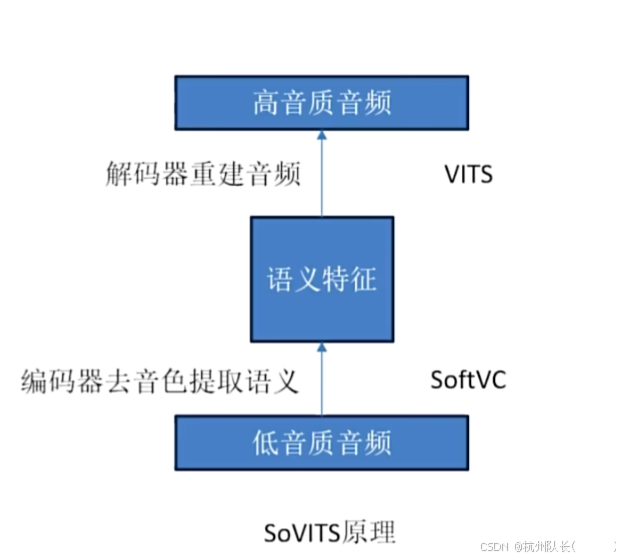
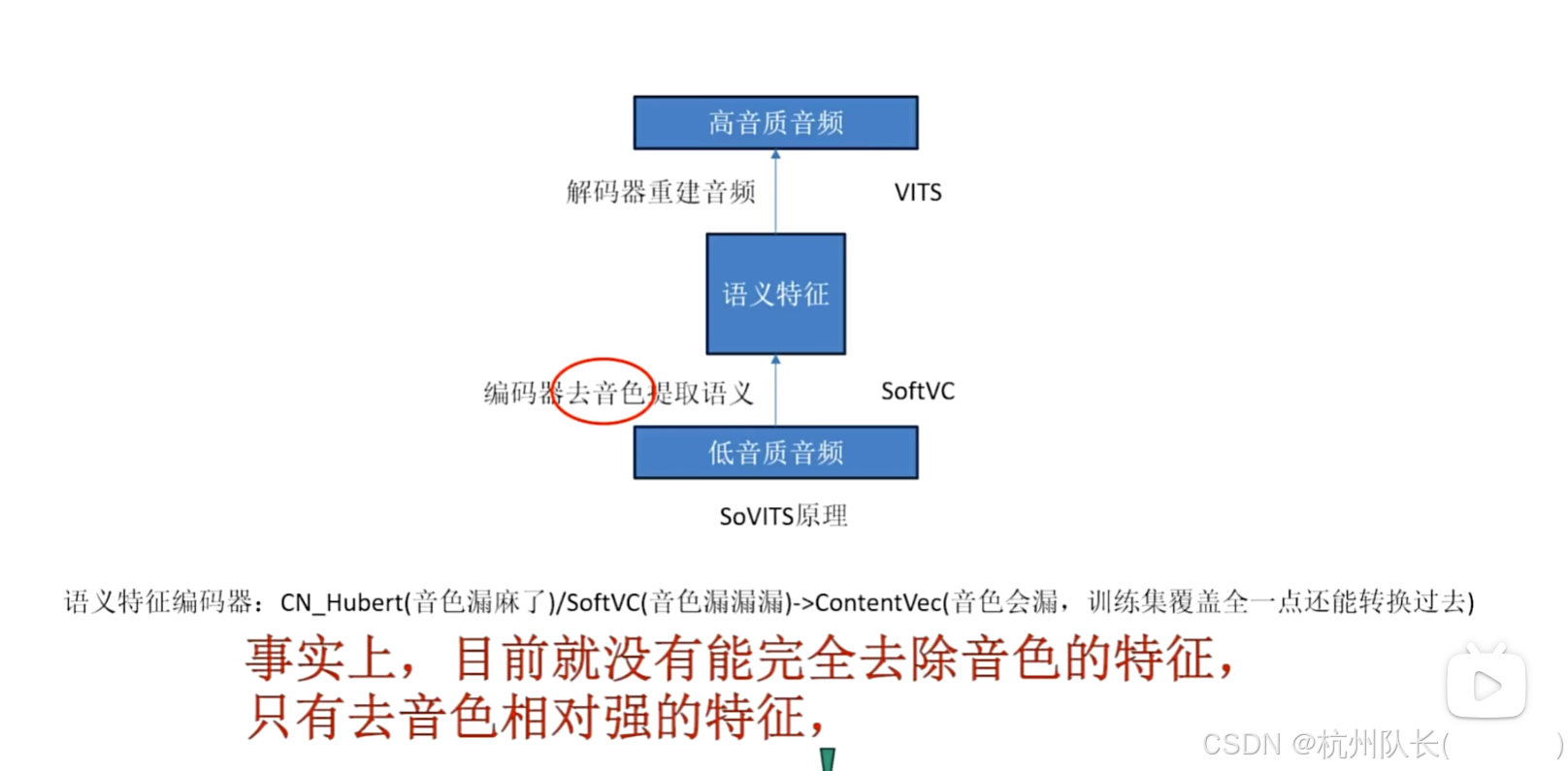
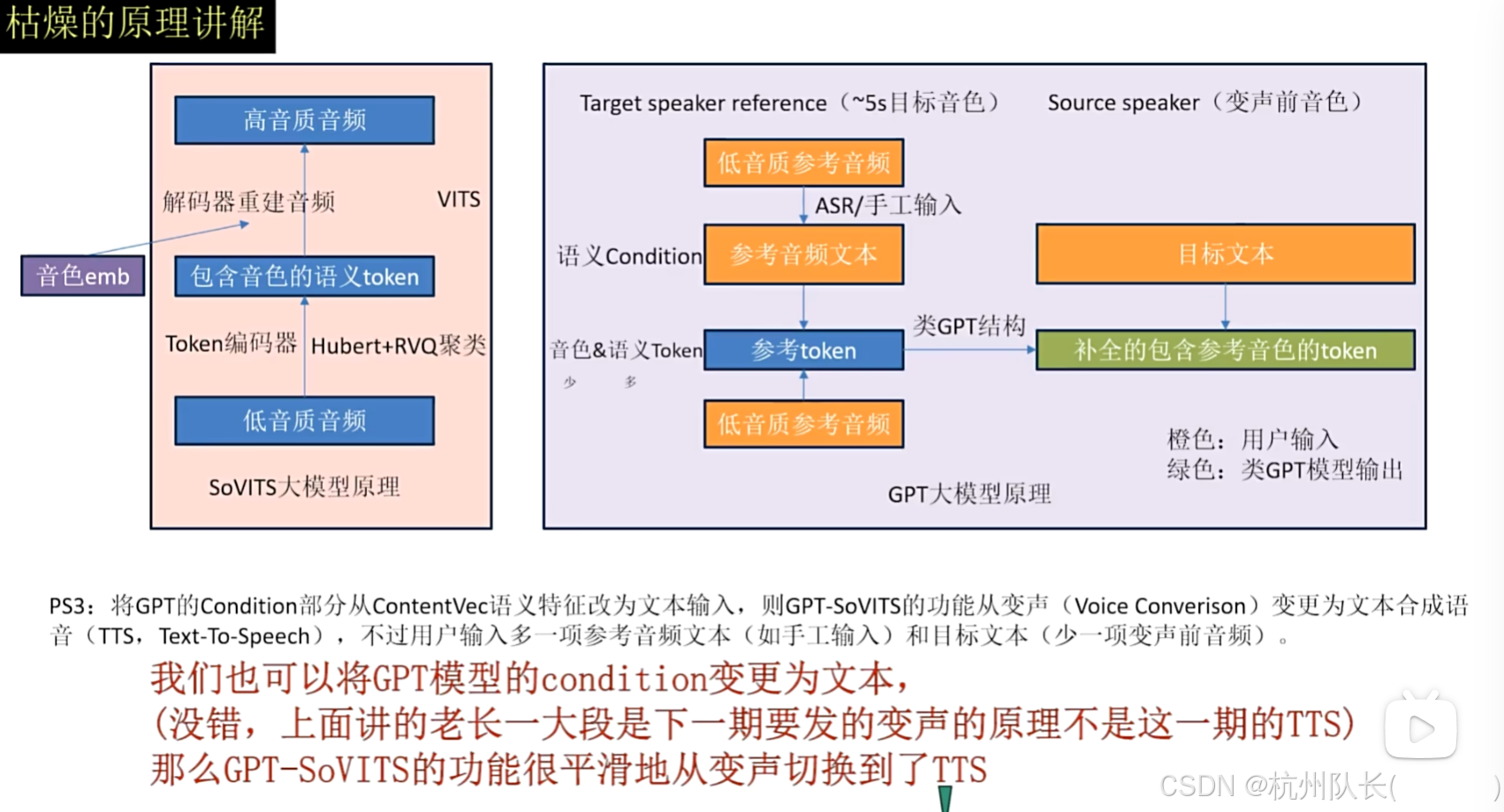
- GPT模型 :负责从文本生成语音编码的过程 GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)
- SoVITS模型 :负责将语音编码转换为实际音频波形 GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)
训练的输入数据是什么?
- 音频文件 :3-5分钟干净无噪声、无背景音乐的人声音频 昆仑的山头 >> 使用GPT-SoVITS克隆声音
- 对应文本:通过ASR(自动语音识别)生成的音频对应的文字标注
- 切分后的音频片段 :将长音频切分成多个小段进行训练 GPT-SoVITS-WebUI一键整合包及使用教程,更新至V2版本_学术FUN
训练出的东西是什么?
训练完成后会生成模型权重文件:
- GPT权重文件 :存储在「GPT_weights」文件夹中 有手就会的GPT-SoVITS小白教程 - 知乎
- SoVITS权重文件 :存储在「SoVITS_weights」文件夹中 有手就会的GPT-SoVITS小白教程 - 知乎
这些权重文件包含了特定说话人的声音特征和语音合成能力。
推理部分
推理是用什么推理?
推理使用的是训练好的模型权重文件:
- 输入 :
- 要合成的文本
- 参考音频(3-10秒)
- 参考音频对应的文本 GPT-SoVITS 本地化部署及使用 详细教程-CSDN博客
- 处理过程 :
- GPT模型分析文本,结合参考音频的声音特征
- 生成中间的语音编码表示
- SoVITS模型将编码转换为最终的音频波形
- 输出 :
- 具有目标说话人声音特征的合成语音
模型的工作原理
GPT部分 :类似GPT的结构,直接由文本生成语音,可以生成很多语气和情绪 OpenVINO™ Blog | OpenVINO Enable Digital Human-TTS (GPT-SoVITs)
SoVITS部分 :是一个端到端的文本转语音合成模型,结合变分推理和对抗学习来生成高质量、自然的语音 OpenVINO™ Blog | OpenVINO Enable Digital Human-TTS (GPT-SoVITs)
零样本 vs 微调模式
- 零样本推理 :
- 直接使用预训练的基础模型
- 只需提 OpenVINO™ Blog | OpenVINO Enable Digital Human-TTS (GPT-SoVITs)供5秒语音样本就能体验到80%-95%相似度的语音克隆
- 效果相对有限
- 微调后推理 :
- 使用自己训练的模型权重
- 提供1分钟语音样本就能获得接近真人的效果 OpenVINO™ Blog | OpenVINO Enable Digital Human-TTS (GPT-SoVITs)
- 效果更好,声音更像目标说话人
简单类比
可以把整个过程类比为:
- 训练 = 教AI学会模仿某个人的说话方式
- 训练结果 = AI的"记忆"(模型权重文件)
- 推理 = AI根据学到的说话方式,把新文字"说"出来
音色相似度更高,需要更少训练数据来逼近目标说话人 GPT-SoVITS/docs/cn/README.md at main · RVC-Boss/GPT-SoVITS,这就是GPT-SoVITS强大的地方。
训练部分
训练是训练什么?
GPT-SoVITS实际上要训练两个独立的模型:
- GPT模型 :负责从文本生成语音编码的过程 GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)
- SoVITS模型 :负责将语音编码转换为实际音频波形 GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)
训练的输入数据是什么?
- 音频文件 :3-5分钟干净无噪声、无背景音乐的人声音频 昆仑的山头 >> 使用GPT-SoVITS克隆声音
- 对应文本:通过ASR(自动语音识别)生成的音频对应的文字标注
- 切分后的音频片段 :将长音频切分成多个小段进行训练 GPT-SoVITS-WebUI一键整合包及使用教程,更新至V2版本_学术FUN
训练出的东西是什么?
训练完成后会生成模型权重文件:
- GPT权重文件 :存储在「GPT_weights」文件夹中 有手就会的GPT-SoVITS小白教程 - 知乎
- SoVITS权重文件 :存储在「SoVITS_weights」文件夹中 有手就会的GPT-SoVITS小白教程 - 知乎
这些权重文件包含了特定说话人的声音特征和语音合成能力。
推理部分
推理是用什么推理?
推理使用的是训练好的模型权重文件:
- 输入 :
- 要合成的文本
- 参考音频(3-10秒)
- 参考音频对应的文本 GPT-SoVITS 本地化部署及使用 详细教程-CSDN博客
- 处理过程 :
- GPT模型分析文本,结合参考音频的声音特征
- 生成中间的语音编码表示
- SoVITS模型将编码转换为最终的音频波形
- 输出 :
- 具有目标说话人声音特征的合成语音
模型的工作原理
GPT部分 :类似GPT的结构,直接由文本生成语音,可以生成很多语气和情绪 OpenVINO™ Blog | OpenVINO Enable Digital Human-TTS (GPT-SoVITs)
SoVITS部分 :是一个端到端的文本转语音合成模型,结合变分推理和对抗学习来生成高质量、自然的语音 OpenVINO™ Blog | OpenVINO Enable Digital Human-TTS (GPT-SoVITs)
零样本 vs 微调模式
- 零样本推理 :
- 直接使用预训练的基础模型
- 只需提 OpenVINO™ Blog | OpenVINO Enable Digital Human-TTS (GPT-SoVITs)供5秒语音样本就能体验到80%-95%相似度的语音克隆
- 效果相对有限
- 微调后推理 :
- 使用自己训练的模型权重
- 提供1分钟语音样本就能获得接近真人的效果 OpenVINO™ Blog | OpenVINO Enable Digital Human-TTS (GPT-SoVITs)
- 效果更好,声音更像目标说话人
简单类比
可以把整个过程类比为:
- 训练 = 教AI学会模仿某个人的说话方式
- 训练结果 = AI的"记忆"(模型权重文件)
- 推理 = AI根据学到的说话方式,把新文字"说"出来
音色相似度更高,需要更少训练数据来逼近目标说话人 GPT-SoVITS/docs/cn/README.md at main · RVC-Boss/GPT-SoVITS,这就是GPT-SoVITS强大的地方。