【强化学习】第十章:连续动作空间强化学习:随机高斯策略、DPG算法
一、本篇在强化学习中的位置
之前我们学的算法,不管是确定性最优策略 还是随机性最优策略 ,其输出都是有限个动作 的最优策略。本篇讲连续动作空间 的强化学习,重点讲两个算法:随机高斯策略 和DPG 。其中,随机高斯策略输出的是连 续动作空间的随机性最优策略 ,DPG是连续动作空间的确定性最优策略 。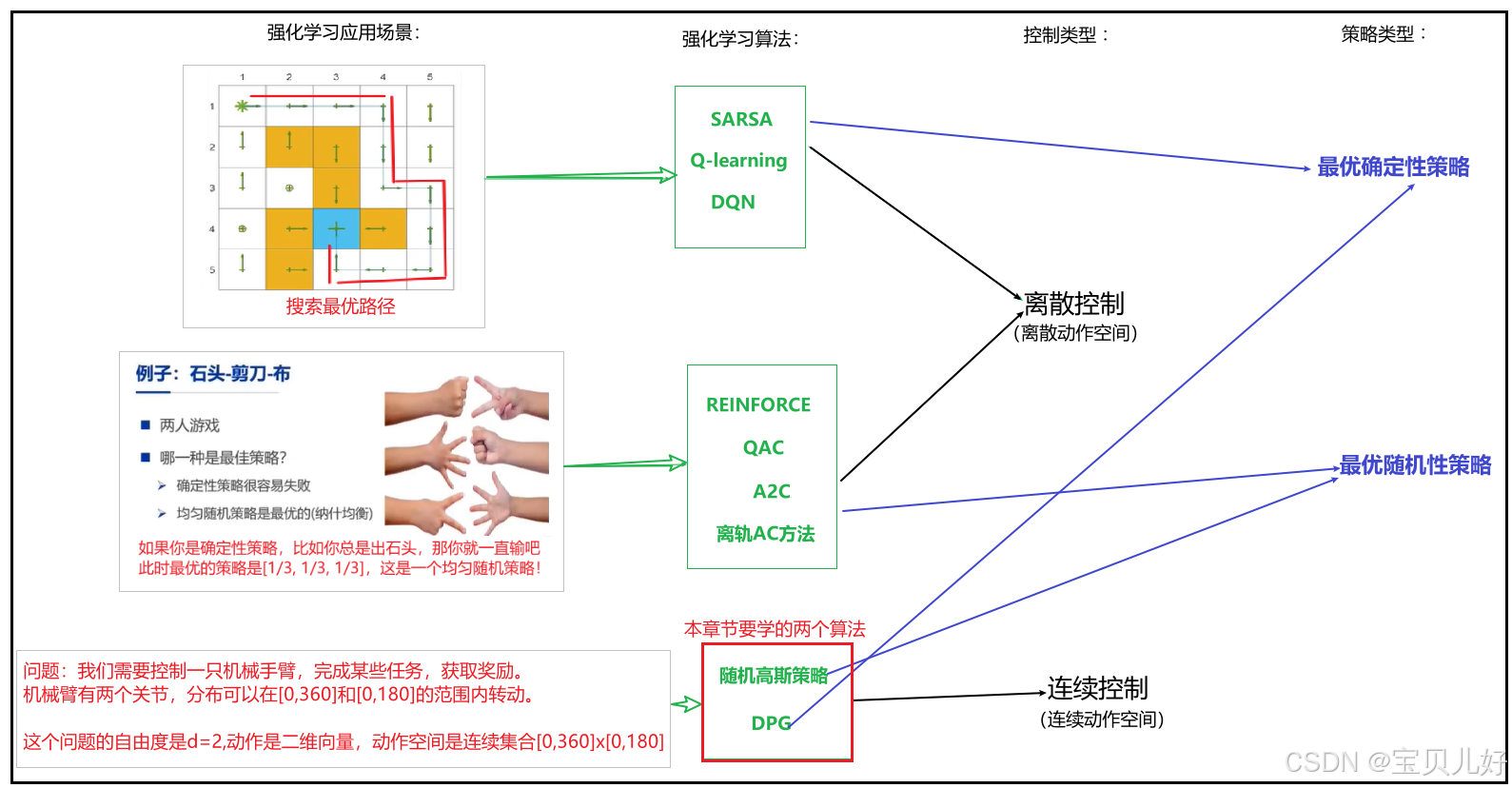
二、随机高斯策略
高斯策略属于强化学习的基于策略优化 的分支,用于解决连续动作空间中的任务,本来是打算写入第八章的,但是在Actor-Critic框架中,使用高斯策略能实现更稳定、更高效的策略优化,彼时AC又没讲,所以思来想去,这部分就只能单独开一个篇章讲解了。 所以,当你对第八、九章节非常熟悉了,本算法就是顺水推舟,理所当然,毫无难度。
随机高斯策略求出的是连续动作空间中的随机性策略,就是有概率的策略,我们可以根据动作的概率去对动作进行抽样,得到连续动作空间中一个最优的确定性动作。
1、策略函数的架构设计 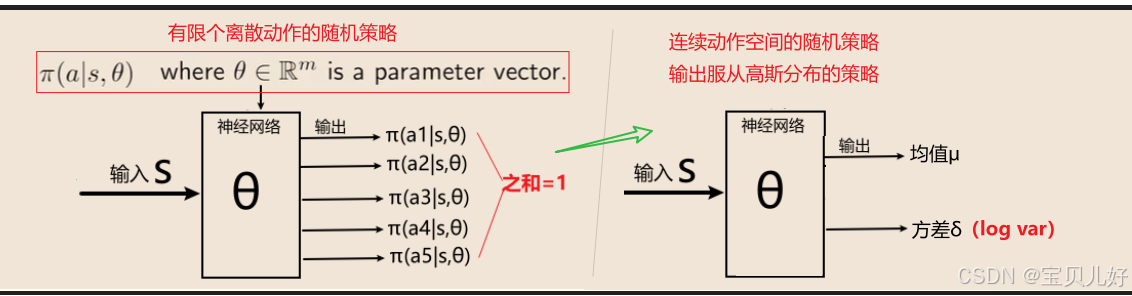 (1)左图的输出是有限个动作的随机策略。本篇章学右图,输出的是某个概率分布的参数,具体到这里就是高斯分布的参数:均值和方差。当然你可以根据你自己的实际情况,你可以学习你自己需要的概型。本篇是高斯概型。
(1)左图的输出是有限个动作的随机策略。本篇章学右图,输出的是某个概率分布的参数,具体到这里就是高斯分布的参数:均值和方差。当然你可以根据你自己的实际情况,你可以学习你自己需要的概型。本篇是高斯概型。
(2)上图的策略函数都是用神经网络来拟合,当然你可以用任何函数拟合,只要效果好,都是可以的,不是只局限于神经网络。这里以神经网络为例。
(3)对于左图,输出有限个动作的随机概率,我们之前是特别强调:神经网络的输出层是要加softmax层 的。
但是对于右图,输出层就不适合 添加任何非线性变换了,直接回归两个数值即可。也就是输出层只要两个神经元即可,一个表示高斯分布的均值μ,一个表示高斯分布的方差δ。
(4)我们一般不直接回归方差δ ,而是回归一个log(var) ,就是方差的自然对数。为啥是log(var),而不直接就是方差δ?因为方差都是大于0的数-->大于0的数,经过log以后,就可正可负-->可正可负正符合神经网络的输出。所以我们把神经网络的输出看作是log(var),比去限制网络的输出范围更加简单方便,需要方差时再变换一下即可。
(5)策略函数输出的是高斯分布的参数:均值和方差。但是我们想得到的是连续动作空间中的一个确定性动作,所以我们只要在这个分布中随机采样一个动作输出即可。
2、从策略函数的数据流角度分析策略梯度
我们上面的策略函数架构是极简的形式,我看有的资料是创建两个网络,一个网络输出均值,一个网络输出方差。其实个人感觉没必要这么麻烦,一个网络直接回归2个值也是可以的。为了节省画图的时间,我就用别人的架构图梳理一下策略函数的数据流: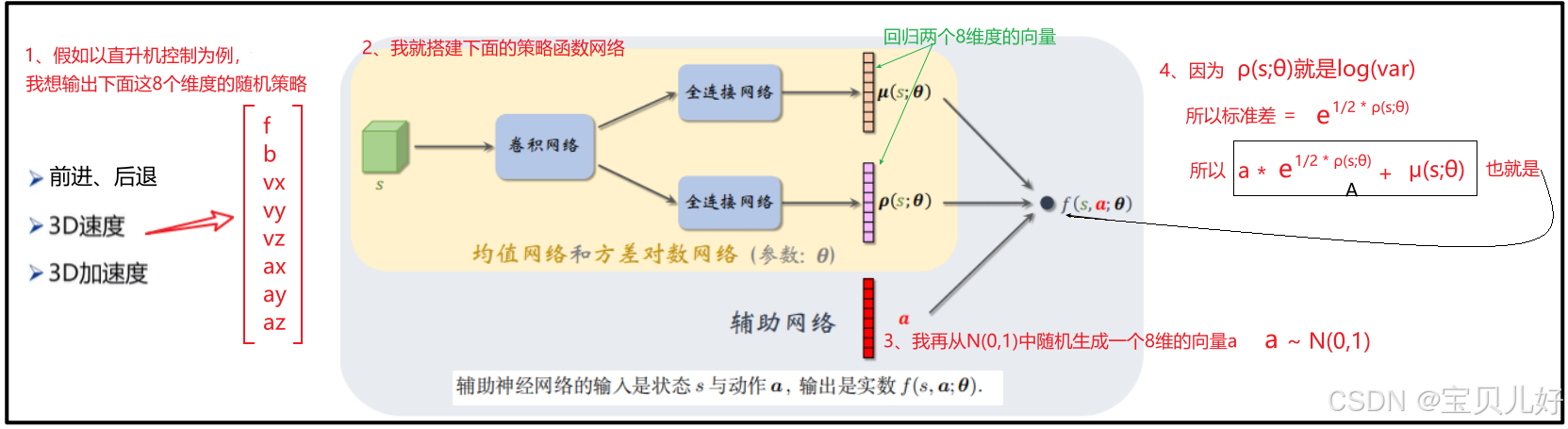 (1)采样公式为:a = μ + σ*ϵ,其中ϵ∼N(0,1)是标准正态噪声。
(1)采样公式为:a = μ + σ*ϵ,其中ϵ∼N(0,1)是标准正态噪声。
(2)策略函数的正向传播是:输入网络状态s,输出8对儿(μ,log(var))。然后从一个标准正态分布中随机采样一个8维的向量,-->每个维度都乘 标准差加均值-->输出连续动作空间中的一个确定性动作f。所以f(s,a,θ)是一个确定性的数值,就是上图的A。
(3)上图3处的操作叫重参数技巧 ,在深度学习生成网络AVE模型中就有这个操作。感兴趣可参考: https://blog.csdn.net/friday1203/article/details/137709966
(4)我们要求策略函数梯度,优化策略函数,那我们就得看数据流是否可以顺利反向传播。从f(s,a,θ)到(μ,log(var))的映射关系就是上图的A处,可导可微,这部分梯度是可以顺利回传的。从(μ,log(var))到s是神经网络,自然更可以顺利回传。可见反向求梯度毫无障碍。
3、策略梯度的计算-->策略函数的优化
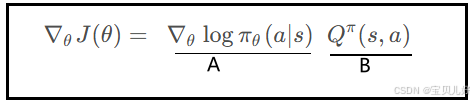
这是我们第八章推导出来的策略梯度公式,由A、B两部分组成:
(1)A部分就是上图中从f->s反向传播的梯度。前面从数据流角度描述了从f->s可以丝滑求导,这个过程可以闭眼交给pytorch即可。
(2)B部分是从策略π 下采集经验数据,从经验数据中学习而来。那策略π是什么呢? 策略π是用来指导行动action,从而生成经验数据的。而从经验数据中学习q(s,a)又有MC方法和TD方法,所以随机高斯策略的实现又分基于REINFORCE的实现方法和基于AC的实现方法:
策略π是用来指导行动action,从而生成经验数据的。而从经验数据中学习q(s,a)又有MC方法和TD方法,所以随机高斯策略的实现又分基于REINFORCE的实现方法和基于AC的实现方法:
4、小结
高斯策略提供了一个可学习、可微、易实现的方式让策略梯度算法在连续动作空间中工作,从而使得policy(在梯度更新下)收敛到最优或近似最优解。严格来说,高斯策略往往收敛于局部最优,但是在很多连续控制任务中,局部最优已经是相当好了。
对八、九章节非常熟悉的同学,这个算法就非常非常简单。唯一的难点(或者说新知识点)是:重参数技巧,以及在重参数操作下,梯度计算的微小变化。也就是从策略网络的输出(均值,log(var))到随机采样,这个映射过程中的梯度问题。想明白后其实特别特别简单,就是高斯分布的映射关系,而高斯分布又是处处可导可微。这点想明白后,这个算法就不攻自破了。
三、DPG算法
DPG,确定性策略梯度,Deterministic Policy Gradient,是最常用的连续控制算法。DPG是求连续动作空间中的确定性策略 ,是直接在状态s和动作a直接建立映射关系 的算法。此后我们还会学到在此算法的基础上改进的DDPG、TD3模型,这些算法都是解决动作空间连续的问题,并且求出的都是连续动作空间的确定性策略。
DPG来自David Silver在ICML2014年发表的论文Deterministic Policy Gradient Algorithms。这个论文的很大一个贡献在于,在这个论文之前大家都觉得环境模型无关的确定性策略是不存在的,而David Silver等通过严密的数学推导证明了DPG的存在。根据DPG论文的证明,当概率策略的方差趋近于0的时候,就是确定性策略。
1、DPG的网络架构
DPG是Actor-Critic框架下的算法,所以它至少有两个子网络:一个策略网络(演员Actor)、一个价值网络(评委Critic)。具体网络架构如下: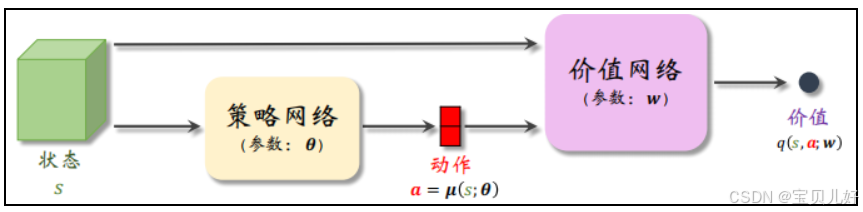 策略网络(Actor):用μ(s,θ) 表示,输入是状态s,输出是动作a,网络参数是θ。
策略网络(Actor):用μ(s,θ) 表示,输入是状态s,输出是动作a,网络参数是θ。
价值网络(Critic):用q(s,a,ω)表示,输入是状态s和动作a,输出是动作价值值(一个实数),网络参数是ω。
下面对这个两个网络展开详细说一下。
(1)策略网络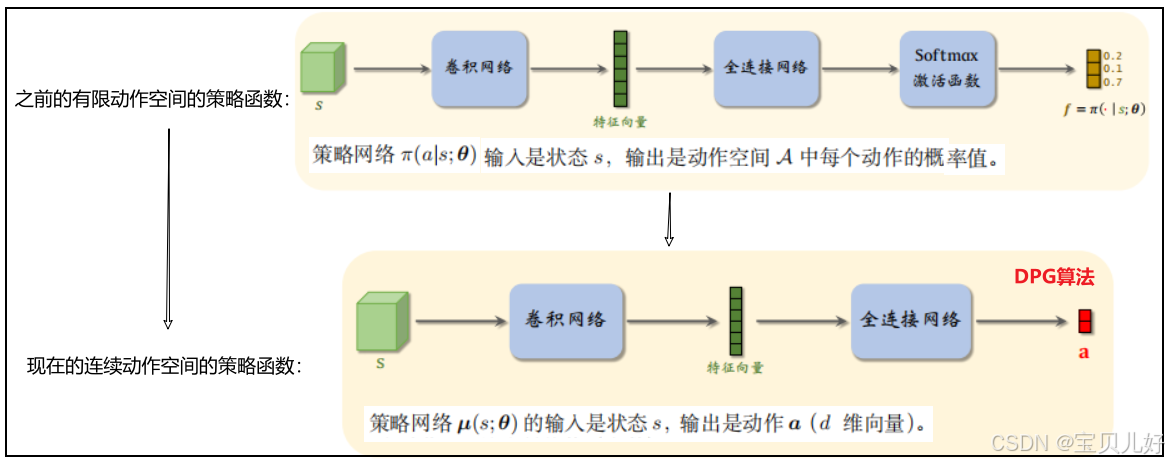 可见,策略网络μ是直接建立了从s到a的映射。μ is a mapping from S to A.
可见,策略网络μ是直接建立了从s到a的映射。μ is a mapping from S to A.
动作a直接就是一个确定性动作。比如我们要控制一个机械手臂,完成某个任务,获取奖励。机械臂有两个关节,分别可以在0,360和0,180的范围内转动,也就是这个动作是一个自由度为d=2的二维向量,动作空间是连续集合0,360x0,180。那这个例子对应到策略网络的输出a就是一个二维向量。
(2)价值网络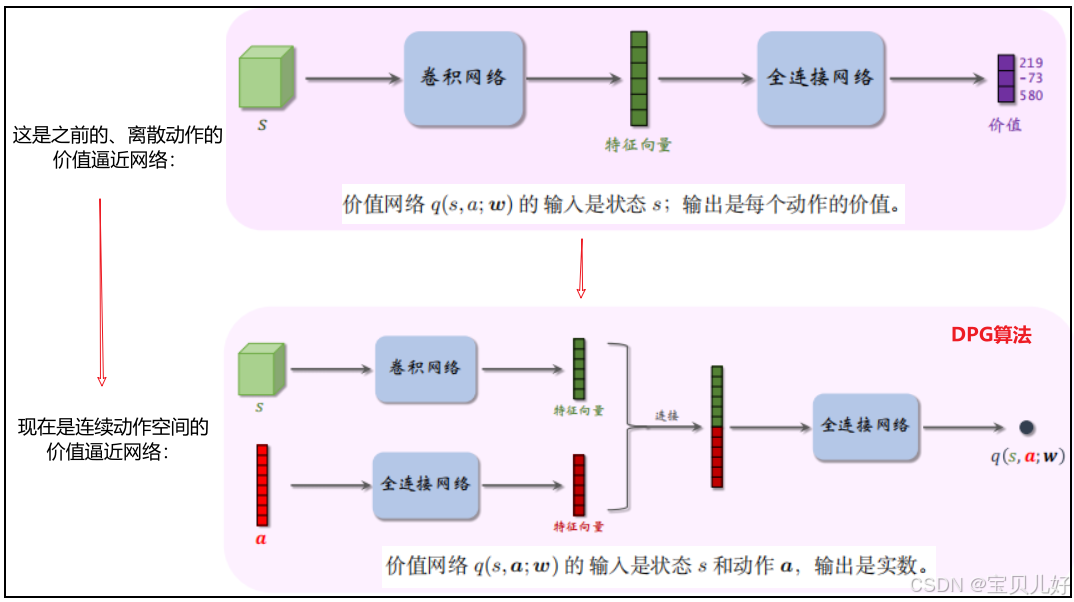 价值网络是对动作价值函数Qπ(s,a)的近似。连续动作空间和离散动作空间在网络架构的形式上也是不同的。
价值网络是对动作价值函数Qπ(s,a)的近似。连续动作空间和离散动作空间在网络架构的形式上也是不同的。
2、计算DPG的策略梯度-->优化策略网络
计算策略梯度,我们首先要弄清楚DPG网络的数据流: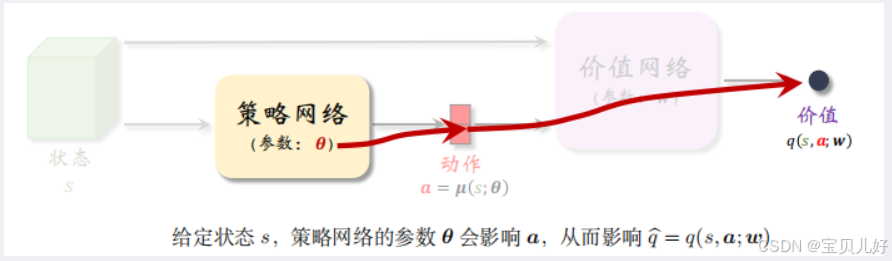 数据流的正向传播:给定状态s,策略网络会输出动作a=μ(s,θ)--> 动作a + s 输入价值网络,价值网络输出动作价值q(s,a,w)。
数据流的正向传播:给定状态s,策略网络会输出动作a=μ(s,θ)--> 动作a + s 输入价值网络,价值网络输出动作价值q(s,a,w)。
我们把q(s,a,w)看作是对动作a的打分,我们希望价值网络对a的打分越高越好。所以我们训练策略网络的目标就是:改进θ,使得q最大。
此时数据流反向传播求策略梯度 就是:
策略函数的梯度求出来以后,就用梯度值来更新策略网络:
3、训练DPG网络
由于策略网络是直接输出确定性的动作a,所以我们是无法获取 动作a所属的策略π,也就是策略π是无法表示或者是无法知道的。所以DPG算法是一个离轨算法。the deterministic policy gradient method is off-policy.
离轨的意思就是收集经验数据和更新策略是分开做的。所以我们训练DPG网络前,要先整理手头上已经获取的经验数据。如何整理?经验回放(Experience replay)!我们在第七章讲DQN时详细讲过了,不懂的小伙伴回看第七章。这里简单说一下: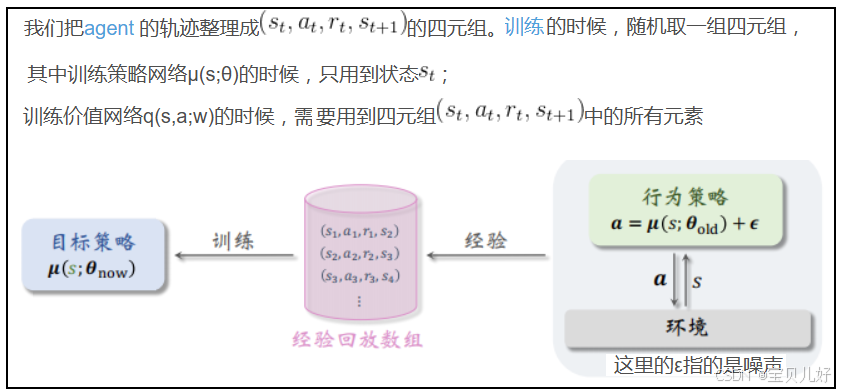
经验数据整理完毕后,按照下面的训练流程,训练策略网络和价值网络:
4、DPG伪代码  DPG基本上就是这么多细节。重点有四:
DPG基本上就是这么多细节。重点有四:
一是,策略函数的网络架构设计,输出层是直接输出动作。
二是,策略函数的梯度值是从价值函数q开始回传的。所以从a到q这部分的梯度(价值函数的梯度)可以看作是调整策略函数梯度的步长。
三是,DPG的训练过程。DPG是一个离轨算法,所以经验数据要整理成回放数组。
四是,由于动作空间是连续的,所以DPG的动作价值学习只能用基于TD的方法来估计动作价值,也所以DPG也只能是基于AC框架来实现。
说明:本篇两个算法让我写得非常非常简单,没有晦涩的数学推导。我只是想说,其实它们就是这么简单,如果你有疑问有看不懂的地方,回看七八九三章,所有的原理都在这三章中。