刚传完节前会有更新,DeepSeek 傍晚就甩出 DeepSeek-V3.2-Exp ------ 这次直接把长文本推理成本砍掉四分之三。
该版本是一个引入了 DeepSeek Sparse Attention(一种稀疏注意力机制)的实验性(Experimental)版本,主要针对长文本的训练和推理效率进行了探索性的优化和验证。
说白了,本次升级能力提升还在其次,但"提速降本"肯定拉满。
提速:稀疏注意力机制
传统的注意力机制是逐字逐句,通读全文,记住每个字与其他字的关系。
DSA稀疏注意力则是先看目录(全局关键token ),再仔细阅读重点部分(局部窗口),跳过无关内容。
这样 AI 在面对长文本时,可以大幅提升处理性能。
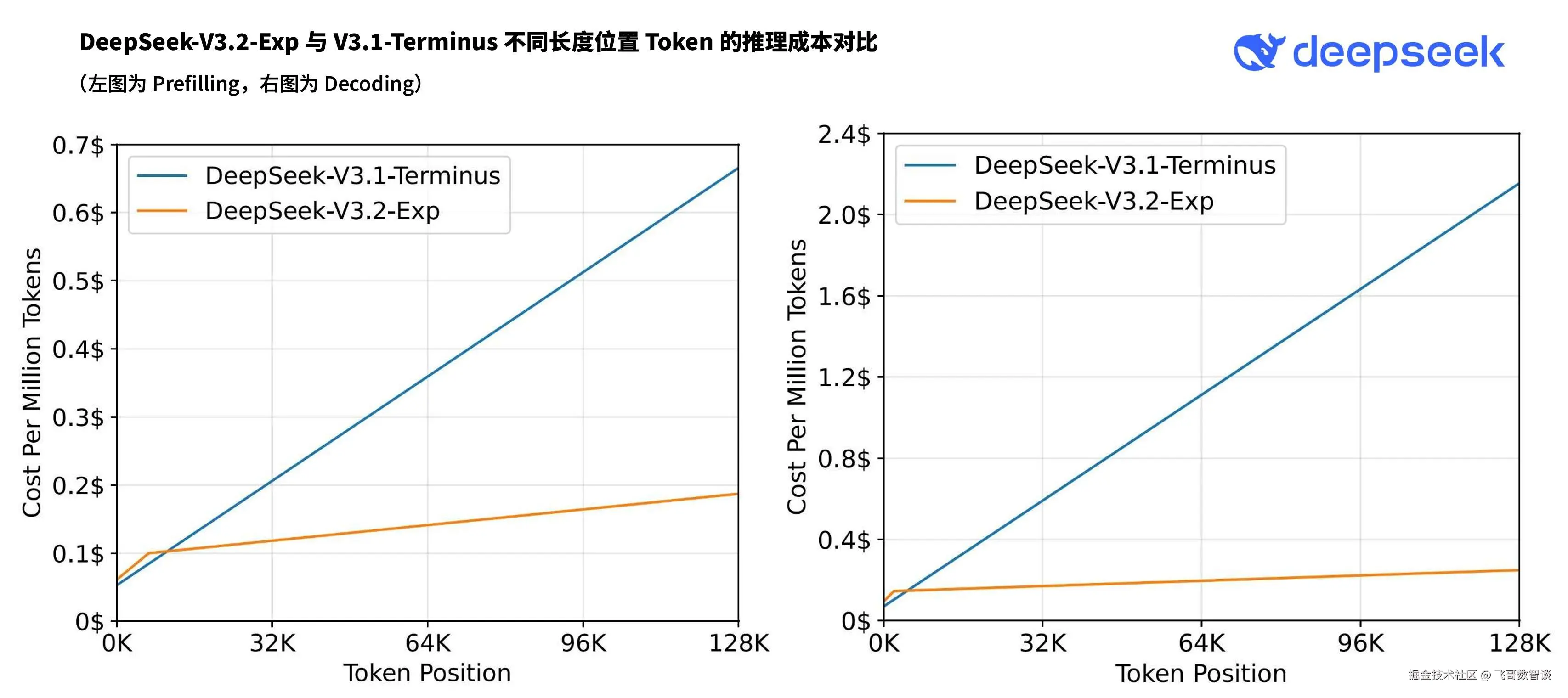
降本:费用减少3/4
由于新的架构升级,算力成本大幅降低,官方 API 价格直接跳水。

单张图可能不太直观,我们拿 V3.1 和 V3.2 直接对比下。
| 计费项 | V3.1 | V3.2 | 降幅 |
|---|---|---|---|
| 输入(缓存命中) | 0.5元 | 0.2元 | 60% |
| 输入(未命中) | 4元 | 2元 | 50% |
| 输出 | 12元 | 3元 | 75% |
| 典型场景成本 | 100万输入+50万输出≈10元 | 100万输入+50万输出≈2.5元 | 75% |
结语
现在 DeepSeek 的所有环境都已经更新为 V3.2-Exp,虽然新版本已经在公开评测集上得到了验证,但大家使用的时候依然要谨慎。
好在,这次 DeepSeek 提供了旧版本接口的回滚 API,只需要把 API 改为如下接口即可。
ini
base_url="https://api.deepseek.com/v3.1_terminus_expires_on_20251015"注意:该接口仅保留到北京时间 2025 年 10 月 15 日 23:59。
如果你的场景正好需要长文本处理,那就趁假期赶紧试试吧~