一:数据库
1;DML语句
sql
一次插入多条数据
INSERT INTO student(`name`,age,gender) VALUES('小张77',23,'男'),('小王',22,'男');
-- 修改数据
UPDATE student SET age=age+1,name='zhangsan' WHERE id=7;
---查询数据
select 字段列表 FROM 表明列表 where 条件列表 group by 分组字段列表 Having 分组后条件列表
Order by 排序字段列表
设置别名:select 字段1 AS 别名 FROM 表名
去除重复记录: select distinct 字段列表 FROM 表名
聚合函数:count;max;min avg sum; select 聚合函数(字段列表) from 表名2;where和having的区别
where是分组之前进行过滤,不满足where条件不参与分组;而having是对分组之后对结果进行过滤,where不能对聚合函数进行判断,而having可以。
例子:查询年龄小于45的员工,并根据工作地址进行分组,获取员工数量大于等于3的工作地址。
sql
select workaddress count(*) from emp where age<45 group by workaddress having workaddress>=33;函数
字符串函数:
concat(s1,s2,s3,s4) 字符串拼接,将s1s2s3s4拼接成一个字符串
trim(str)去掉字符串头部和尾部的空格
lower(str) 将字符串str全部转为小写
upper(str) 将字符串str全部转为大写
substring(str,start,len) :返回从字符串从start位置其的len个长度的字符串。
数值函数
cell(x)向上取整,floor(x) 向下取整
Round(x,y):求参数的四舍五入的值,保留y位小数。
聚合函数
sum max avg min max
日期函数
curdate() 返回当前日期
curtime()返回当前时间
datediff(date1,date2)返回起始时间date1和结束时间之间的天数
流程函数
IF(value,t, f )如果value为true返回t,否则返回f
4;多表查询
内连接:查询两张表交集的部分
select 字段列表 from 表1 inner join 表2 on 连接条件
左外连接
select 字段列表 from 表1 left join 表2 on 条件
自连接
聚合查询:合并两个或多个select语句的结果,使用union完全相同的行将会被合并,使用union all 可以避免。
子查询:常见的操作符
in:在指定集合范围内。
not in:不在指定的集合范围内。
any :子查询返回的列表中有任意一个满足即可
all:子查询返回的列表的所有值都必须满足。
例子:
查询所有比财务部人员工资高的信息
select * from emp where salary >all (select salary from emp where dept_id=(select id from dept where name = '财务部')
5:事务
1,定义:是一组操作的集合,它是一个不可分割的工作单位,要么同时成功,要么同时失败。开启事务:start transaction;提交事务 commit;回滚事务 roll back。
2,事务的四大特性
原子性:事务中的所有操作要么执行,要么不执行。靠undo log逻辑日志
一致性:事务执行的结果必须是数据库从一个一致性状态到另一个一致性状态。
隔离性:一个事务的执行不能被其他事务干扰。
持久性 :一旦事务提交,它对数据库的改变是永久性的。靠redo log 日志
3,并发事务产生的问题
脏读:一个事务读到另一个事务还没提交的数据。
不可重复读:一个事务先后读取同一条记录但两次读取的数据不同。
幻读:一个事务按照条件查询数据时,没有对应的数据行,但在插入数据时,又发现这行数据已经存在,好像出现了幻影。
4,事务隔离级别
读未提交;
读已提交RC
可重复读RR
串行化
6,存储引擎
1:定义:存储引擎就是存储数据,建立索引,更新查询数据等技术的实现方式,存储引擎是基于表的。
2:InnoDB:批量插入相对较慢,支持事务,锁行,
MyisAM:批量插入速度块,不支持事务,
7.MVCC(难点)
1:MVCC多版本控制器,做到了有读写冲突的时候也能不加锁。非阻塞的读取数据,它的实现原理主要依赖数据行中记录的三个隐式字段(最近修改事务ID,回滚指针,隐藏主键),undo日志,ReadView 来实现的。
8,视图,存储过程,触发器
视图是基于SQL语句的结果集的虚拟表,不存储实际数据,只是保存了查询定义。
sql-- 创建视图 CREATE VIEW view_name AS SELECT column1, column2, ... FROM table_name WHERE condition; -- 使用视图 SELECT * FROM view_name;存储过程:一组预编译的SQL语句集合,可以接受参数、执行复杂逻辑。
sqlDELIMITER // CREATE PROCEDURE procedure_name(IN param1 INT, OUT result INT) BEGIN -- 业务逻辑 SELECT COUNT(*) INTO result FROM table WHERE condition; END // DELIMITER ; -- 调用存储过程 CALL procedure_name(123, @output); SELECT @output;触发器:在特定数据库事件(INSERT/UPDATE/DELETE)发生时自动执行的存储过程。
sqlCREATE TRIGGER trigger_name {BEFORE | AFTER} {INSERT | UPDATE | DELETE} ON table_name FOR EACH ROW BEGIN -- 触发逻辑 END;
9:索引
1:索引的数据结构分类
B+树索引:最常见的索引。
哈希索引:底层是用哈希实现的,只有精确匹配索引列的查询才有效,不支持范围查询。
空间索引
全文索引
2:索引的分类:从大类来看分为 聚簇索引 和 非聚簇索引;主键索引:针对于表中主键创建的索引,只能有一个。
唯一索引:避免同一个表中某数据列中的值重复。可以有多个。
常规索引
复合索引:在工作中使用比较频繁的索引。
3:在InnoDB中根据索引的存储形式分为聚集索引和非聚集索引。聚集索引:将数据存储与索引存储放在一起,索引结构的叶子节点保存了行数据,必须有且只有一个。
非聚集索引:将数据的存储与索引分开存储,索引结构的叶子节点关联的是对应的主键,可以存在多个。
4:聚簇索引的选取规则如果存在主键索引,主键索引就是聚簇索引,如果不存在就选用唯一索引作为聚簇索引;如果还没有,则InnoDB会自动生成一个rowid作为隐藏的聚簇索引,
5:索引的语法
sql-- 创建普通索引 CREATE INDEX idx_age ON users (age); -- 创建唯一索引 CREATE UNIQUE INDEX idx_unique_email ON users (email); -- 创建复合索引 CREATE INDEX idx_name_age ON users (username, age);
6:索引的使用
最左匹配原则:复合索引,查询从索引的最左列开始,并且不跳过索引中的列,跳过索引将会失效。
前缀索引:当字段类型为字符串时,此时可以只将字符串的一部分前缀建立索引。
索引失效的情景1:没有遵循最左匹配原则
2:不要在索引上做任何操作(计算 函数 类型转换)会导致索引失效
3:对于字符串类型不加引号,索引会失效
4:如果仅仅是尾部模糊匹配索引不会失效,如果是头部模糊匹配,索引失效。
5:用or连接的条件,如果or前面的条件中的列有索引,而后面的列中没有索引,那么涉及到的索引不会被用到。
6:尽量使用覆盖索引,减少select*的使用。
SQL性能分析1:慢查询日志:记录了所有执行时间超过指定参数的所有SQL语句的日志,
开启慢日志查询开关:slow_query_log=1
2:profile详情:show profiles 能够在做SQL优化时帮助我们了解时间都耗费在哪里去了,
3:explain执行计划:获取mysql如何执行select语句的信息包括在select语句执行过程中表如何连接和连接顺序。
语法:EXPLAIN select 字段列表 FROM 表名 where 条件
explain各字段的含义:
id:select 查询的序列号,表示查询中执行 select 子句或者是操作表的顺序。
select_type:表示 select 的类型。
type:表示连接类型,性能由好到差的连接类型:NULL;const;eq_ref,ref,range,index,all。
possible_key:显示可能应用在这张表上的索引,一个或多个。
key:实际使用的索引
filtered:表示返回结果的行数占需读取行数的百分比,值越大越好。
二:redis
Redis的各种思想跟机组Cache和操作系统对进程的管理非常类似!
一:看到你的简历上写了你的项目里面用到了redis,为啥用redis?
因为传统的关系型数据库如Mysql,已经不能适用所有的场景,比如秒杀的库存扣减,APP首页的访问流量高峰等,都很容易把数据库打崩,所以引入了缓存中间件,redis。
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库;跟机组内存中的cache很相似。
集群:复制模式,每个机器做同一件事分布式:每台机器分工合作,做的不是同一件事。
二、Redis数据类型
字符串类型String
哈希类型hash
列表类型
集合类型
有序集合类型
三:Redis的使用
1:下载软件
2:Spring-data-redis:提供了通过简单配置访问redis服务,对redis底层开发包jedis进行了高度封装,RedisTemplate类提供了redis各种操作。
redisTemplate.opsForValue().set("name", "gao1");
redisTemplate.opsForList().rightPush("nameList1", "刘备");
redisTemplate.opsForHash().put("nameHash", "c", "八戒");
四、Redis常见问题
1:缓存穿透:恶意请求或者频繁查询一个不存在的数据,导致每次请求都要访问数据库。
**解决:**缓存空对象,并设置合适的过期时间。
2:缓存击穿:在高并发的情况下,一个热点数据的缓存过期或被删除,恰好有大量的请求同时访问该数据,导致无法从缓存中获取数据,从而直接访问数据库。
解决:互斥锁;单机环境用synchronized,集群环境则使用分布式锁(redis的setnx,Redisson)
3:缓存雪崩:在同一时段大量的缓存Key同时失效或者Redis服务宕机,导致大量请求到达数据库。(与缓存击穿的区别,雪崩是很多key,击穿是某一个key缓存)
解决:合理设置缓存过期时间,给不同的key的·TTL添加随机值;建立redis集群
缓存预热:缓存预热是指在系统启动或高峰期之前,提前将一些热点数据加载到缓存中,以减少后续请求对数据库的访问压力,提高系统的性能和响应速度
五、缓存击穿问题解决
分布式环境下解决:使用 Redisson 会更加合适。
1:引入依赖;配置文件
//1、获取一把锁,只要锁的名字一样,就是同一把锁 RLock lock = redissonClient.getLock("my-lock"); //2、加锁 阻塞式等待(没有获得锁的线程都要等待)。默认加的锁都是30s,lockWatchdogTimeout = 30 * 1000 【看门狗默认时间】 lock.lock(); //1)、锁的自动续期,如果业务超长,运行期间自动续期,不用担心业务时间长,锁自动过期被删掉 //只要占锁成功,就会启动一个定时任务【重新给锁设置过期时间,新的过期时间就是看门狗的默认时间】,每隔10秒都会自动的再次续期,续成30秒 // internalLockLeaseTime 【看门狗时间】 / 3, 10s //2)、加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,锁默认会在30s内自动过期,不会产生死锁问题 try { System.out.println("加锁成功,执行业务..." + Thread.currentThread().getId()); try { TimeUnit.SECONDS.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); } } finally { //3、解锁 假设解锁代码没有运行,Redisson会不会出现死锁 System.out.println("释放锁..." + Thread.currentThread().getId()); lock.unlock(); } return "hello"; }
六、redis与数据库不一致问题
失效模式:修改数据库后,删除缓存后面再重新建立缓存。
双写模式:修改数据库后,修改缓存。
七、SpringCache简化缓存开发
springcache提供了一些核心概念和注解来管理缓存。
Cache Manager :是一个缓存的抽象接口。
Cache:基本操作单元,定义了常见的缓存操作,例如get,put,evict(删除)
缓存注解:
@Cacheable:触发将数据放入缓存的操作。
@CacheEvict:触发将数据从缓存删除的操作。失效模式
@CachePut:不影响方法执行更新缓存。双写模式。
// value:分组,区分不同模块的缓存 //@Cacheable(value = "product", key = "'selectById:' + #id") @Cacheable(value = "product", key = "#root.methodName + ':' + #id") @Override public Product selectById(Long id) { return productMapper.selectById(id); } //加锁解决缓存击穿问题:sync = true //@Cacheable(value = "product", key = "'selectById'") //多个参数这种方式用","分割就不用字符串拼接了, key = "{#root.methodName, #id, #name}" @Cacheable(value = "product", key = "#root.methodName + ':' + #id", sync = true) @Override public Product selectById(Long id) { return productMapper.selectById(id); } //@CacheEvict(value = "product", allEntries = true) //删除分区中所有数据 @CacheEvict(value = "product", key = "'selectById:' + #product.id") @Override public void update(Product product) { productMapper.updateById(product); }
八、Redis持久化机制
1:RDB:Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。
简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
2:AOF:Append Only File(追加文件)
Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件(不记录读命令)。
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF
AOF重写
比如我们有个计数的服务,有很多自增的操作,比如有一个key自增到1个亿,对AOF文件来说就是一亿次incr。AOF重写就只用记1条记录。
九、Redis过期数据删除策略
惰性删除
只会在取出key的时候才对数据进行过期检查,如果过期,我们就删掉它,反之返回该key。
优点 :对CPU友好,只会在使用该key时才会进行过期检查,对于很多用不到的key不用浪费时间进行过期检查
缺点 :对内存不友好,如果一个key已经过期,但是一直没有使用,那么该key就会一直存在内存中,内存永远不会释放
定期删除
每隔一段时间抽取一批 key进行检查,删除里面过期的key。
优点:可以通过限制删除操作执行的时长和频率来减少删除操作对 CPU 的影响。也能有效释放过期键占用的内存。
缺点:难以确定删除操作执行的时长和频率。
Redis的过期删除策略:惰性删除 + 定期删除两种策略进行配合使用
十、Redis数据淘汰策略(和操作系统的进程管理类似)
当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
Redis支持8种不同策略来选择要删除的key:
noeviction:当内存不足时,Redis 不会淘汰任何数据,而是直接返回错误信息。这是默认的淘汰策略。
allkeys-lru: 对全体key,基于LRU算法进行淘汰
allkeys-lfu: 对全体key,基于LFU算法进行淘汰
allkeys-random:对全体key ,随机进行淘汰。
volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
volatile-lfu: 对设置了TTL的key,基于LFU算法进行淘汰
volatile-random:对设置了TTL的key ,随机进行淘汰。
volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
三:java基础
java值传递与引用传递
值传递:
值传递是指在方法调用时,传递的是实际参数的一个副本。无论在方法内部对这个副本如何修改,都不会影响到方法外部的实际参数,这种方式常用于传递基本数据类型,(int,float,boolean等)
值传递的特点
方法接受的是参数的一个副本,而不是参数本身
方法内部对参数的修改不会影响到方法外部的实际参数。
引用传递:
引用传递是指在方法调用时,传递的是参数的引用(内存地址),因此方法接收到的是实际参数的引用,任何对引用的修改都会直接影响到实际参数。这种方式常用于传递对象和数组。
然而,java中,不存在真正的引用传递,java总是以值传递的方式进行参数传递,但对于对象而言,传递的是对象引用的副本,由于引用的副本指向的是同一个对象,因此方法内部的修改会影响到外部对象的状态。
Java中参数传递的实际机制
Java中的参数传递机制被称为"值传递"。具体来说:
基本数据类型:当传递基本数据类型时,传递的是值的副本。因此,方法内部对参数的修改不会影响外部变量。
对象:当传递对象时,传递的是对象引用的副本。由于引用副本指向同一个对象,因此方法内部对对象的修改会影响外部的对象。
基本数据类型的值传递
public class Test {
public static void main(String[] args) {
int num = 10;
modifyPrimitive(num);
System.out.println("Value of num after method call: " + num); // 输出: 10
}
static void modifyPrimitive(int x) {
x = 20; // 修改副本,不影响原始变量
}
}对象引用的值传递
public class Test {
public static void main(String[] args) {
Person person = new Person("Alice");
modifyObject(person);
System.out.println("Name after method call: " + person.getName()); // 输出: Bob
}
static void modifyObject(Person p) {
p.setName("Bob"); // 修改对象属性,影响外部对象
}
}修改对象引用本身的副本
public class Test {
public static void main(String[] args) {
Person person = new Person("Alice");
modifyReference(person);
System.out.println("Name after method call: " + person.getName()); // 输出: Alice
}
static void modifyReference(Person p) {
p = new Person("Charlie"); // 修改引用本身,不影响外部的引用
}
}Static静态代码块
案例一:
public class Person {
// 静态代码块:在类加载时候执行静态代码块,只会执行一次
static {
System.out.println("Person.static initializer");
}
// 实例初始化块,每次调用构造方法之前首先调用实例初始化块
{
System.out.println("Person.instance initializer");
}
public Person() {
System.out.println("Person.Person");
}
}
public void test1() {
Person person1 = new Person();
Person person2 = new Person();
}Person.static initializer
Person.instance initializer
Person.Person
Person.instance initializer
Person.Person
案例二:
public class Test{
static int cnt = 6;
static{
cnt += 9;
}
public static void main(String[] args){
System.out.println("cnt =" + cnt);
}
static{
cnt /= 3;
};
}cnt的值是 A
A、cnt=5
B、cnt=2
C、cnt=3
D、cnt=6
静态初始化块,静态变量这两个是属于同一级别的,是按代码写得顺序执行的!
public class StaticDemo{
static {
cnt = 6;
}
static int cnt = 100;
public static void main(String[] args) {
System.out.println("cnt = " + cnt);
// 最后输出是50,
// 按顺序执行就是cnt=6--->cnt=100---->cnt = 100/2 = 50.
}
static {
cnt /= 2;
}
}问题:为什么cnt变量的声明放在了后面不报错?JVM加载流程
执行静态变量、静态代码块之前,首先扫描类里面所有的静态变量赋值为默认值cnt=0;
静态初始化块,静态变量赋值这两个是属于同一级别的,是按代码写得顺序执行的!
案例三
(1)父类静态成员和静态初始化块,按在代码中出现的顺序依次执行。 clinit
(2)子类静态成员和静态初始化块,按在代码中出现的顺序依次执行。 clinit
(3)父类实例成员和实例初始化块,按在代码中出现的顺序依次执行。 init
(4)执行父类构造方法。init
(5)子类实例成员和实例初始化块,按在代码中出现的顺序依次执行。init
(6)执行子类构造方法。init
public class Person {
private static User1 user1 = new User1();
private User2 user2 = new User2();
// 静态代码块:在类加载时候执行静态代码块,只会执行一次
static {
System.out.println("Person.static initializer");
}
// 实例初始化块,每次调用构造方法之前首先调用实例初始化块
{
System.out.println("Person.instance initializer");
}
public Person() {
System.out.println("Person.Person");
}
}
public class Student extends Person{
private static User3 user3 = new User3();
private User4 user4 = new User4();
static {
System.out.println("Student.static initializer");
}
{
System.out.println("Student.instance initializer");
}
public Student() {
super();
System.out.println("Student.Student");
}
}User1.User1
Person.static initializer
User3.User3
Student.static initializer
User2.User2
Person.instance initializer
Person.Person
User4.User4
Student.instance initializer
Student.Student
finally代码块
必须执行的代码块,不管是否发生异常,即使发生outofmemoryerror也会执行,通常用于执行善后处理工作。
如果finally代码块没有执行,那么有三种情况:
1:没有进入try代码块
2:进入try代码块,但是代码运行中出现了死循环或者死锁的情况。
3:进入try代码块,但是执行了System.exit()操作。
注意,finally代码块是在return表达式运行后执行的,此时return的结果已经暂存起来,待finally代码块执行结束后再将之前暂存的结果返回。
public static void main(String[] args) {
int result = finallyNotWork();
System.out.println(result);// 10001
}
public static int finallyNotWork() {
int temp = 10000;
try {
throw new Exception();
} catch (Exception e) {
return ++temp;
} finally {
temp = 99990;
}
}finally代码块的职责不在于对变量进行赋值等操作,而是清理资源、释放连接、关闭管道流等操作。
相对在finally代码块中赋值,更加危险的做法是在finally块中使用return操作,这样的代码会使返回值变得非常不可控,警示代码如下:
public class TryCatchFinally {
static int x = 1;
static int y = 10;
static int z = 100;
public static void main(String[] args) {
int value = finallyReturn();
System.out.println("value=" + value);
System.out.println("x=" + x);
System.out.println("y=" + y);
System.out.println("z=" + z);
}
private static int finallyReturn() {
try {
// ...
return ++x;
} catch (Exception e) {
return ++y;
} finally {
return ++z;
}
}
}执行结果如下:
value=101
x=2
y=10
z=101
以上执行结果说明:
- 最后return动作是由finally代码块中的return ++z完成的,所以方法返回的结果是101。
- 语句return ++x中的++x被成功的执行,所以运行结果是x=2。
- 如果有异常抛出,那么运行结果将会是y=11,而x=1。
finally代码块中使用return语句,使返回值的判断变得复杂,所以避免返回值不可控,我们不要在finally代码块中使用return语句。
Class Test{
public static String output="";
public static void foo(int i){
try{
if(i==1){
throw new Exception();
}
output+="1";
} catch(Exception e){
output+="2";
return;
} finally{
output+="3";
}
output+="4";
}
public static void main(String args[]){
foo(0);
System.out.println(output);//134
foo(1);
System.out.println(output);//13423
}
}运算符&与&&,|与||的区别
&与 | 即是逻辑运算符也是位运算符,而&&与||只能是逻辑运算符
&&是逻辑与运算符,||是逻辑或运算符。都是逻辑运算,两边只能是bool类型
| 与& 既可以进行逻辑运算,又可以进行位运算,两边既可以是bool类型,又可以是数值类型。
if(a&&b)如果a为fasle,整个表达式就为false,不在计算b的值
if(a&b)如果a为fasle,整个表达式就为fasle,但还有计算b的值。
java 8种基本数据类型

String类中常用方法==和equals区别
==:如果作用于基本数据类型的变量,则直接比较存储的值是否相等。
如果作用于引用数据类型,则比较的是所指向的对象的地址是否相等。
equals:
equals只有引用数据类型有这个方法,默认继承自Object类,它的作用也是判断两个对象是否相等,但是他一般有两种使用情况:
情况1:类没有覆盖equals()方法,则是使用从父类继承的equals方法,使用==比较是否相等。
public boolean equals(Object obj) {
return (this == obj);
}
情况2:类重写了 equals()方法,一般我们都重写 equals()方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| String a = new String("ab"); // a 为一个引用 String b = new String("ab"); // b 为另一个引用 , 对象的内容一样 String aa = "ab"; // 放在常量池中 String bb = "ab"; // 从常量池中查找 System.out .println(aa == bb);// true System.out .println(a == b);// false System.out .println(a.equals(b));// true |String 中的 equals 方法是被重写过的,因为 Object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
介绍一下Object类里面的方法 getClass()、equals()、toString()
Object类是所以类的直接或间接父类。
getClass():得到对象的实际类型,一般用来比较两个对象是否同一个类的对象。
toString():返回对象的字符串表示形式,默认情况下返回对象的类名加上对象的哈希码。
int和Integer区别
int 是基本数据类型,Interger 是 int 的封装类
int 默认值为 0 ,而Interger 默认值为 null
什么是包装数据类型,装箱和拆箱 Integer i = 3; int num = i;//i.intValue()
Java是纯面向对象语言,int、double都是基本数据类型。
包装数据类型是对基本数据类型的封装
int Integer
char Character
double Double
long Long
short Short
boolean Boolean
byte Byte
float Float
装箱:把基本的数据类型转换成对应的包装类型.Integer.valueOf(1)
Integer i = 1;自动装箱,实际上在编译时会调用Integer.valueOf()方法来装箱
拆箱:就是把包装类型转换为基本数据类型.基本数据类型 名称 = 对应的包装类型。
Integer i = 1;
int j = i;//自动拆箱//int j = i.intValue();手动拆箱
自动拆箱:实际上会在编译调用intValue
integer缓存机制(cache)
该类的作用是将数值等于-128-127(默认)区间的Integer实例缓存到cache数组中。通过valueOf()方法很明显发现,当再次创建值在-128-127区间的Integer实例时,会复用缓存中的实例,也就是直接指向缓存中的Integer实例。注意,这里的创建不包括用new创建,new创建对象不会复用缓存实例hort
Byte、Long、Sho'r't、Character都具有缓存机制。
Integer缓冲区
BigDecimal、数据库decimal
this和super区别:this、super、this()、super()
- this:代表当前类的对象 this.id=id
- super:代表父类对象
- this():调用当前类的构造方法
- super():调用父类构造方法
final、finally、finalize() (Java的垃圾回收机制回收这个对象的时候会首先调用finalize()方法)
final关键字:用于修饰类、方法、变量、对象。
final变量:这个变量就不能被修改,就是常量 public static final double PI = 3.1415;
final类:这个类就不能被继承
final方法:这个方法就不能被重写
finally关键字:异常处理机制中的一部分,用于定义try-catch-finally块中的finally块
不论是否发生异常,finally中的代码都会执行
主要用于释放资源,关闭连接等必须确保执行的操作。
finalize():是一个对象的方法,定义在Object类中。
在垃圾回收器将对象回收之前调用,可以重写finalize方法,在其中编写对象在被回收前需要进行的清理操作,如释放资源等。
String、StringBuffrer和StringBuilder的区别 (先答相同点,再答不通点)
相同点:都是finall类,都不能被继承
不同点:1:String类是不可变类,底层使用了一个不可变的字符数组,一旦创建就无法改变其内容,对于每次修改操作,都会创建一个新的字符串对象;StringBuffer和StringBuilder类都是可变的,可以直接在原始对象上进行修改而不创建新的对象,
2:String类是线程安全的,因为它的不可变性保证了多个线程同时访问一个字符串对象时的安全性;StringBuffer是线程安全的,它的方法进行了同步处理;StringBuilder是非线程安全的。
String为啥不可变
对象的不可变性是指对象本身的属性或者数据不会改变。
String不可变不是因为字符数组被final关键字修饰,真正不变的原因是还被private修饰,并且String没有提供任何修改字符数组的方法
接口和抽象类区别(相同点,不同点)
相同点
都是用于实现多态性的机制。
都不能被实例化,只能被子类继承或实现。
都可以包含抽象方法,需要由子类提供具体的实现
接口使用关键字interface来定义,抽象类使用关键字abstract来定义。
接口使用implements关键字定义其具体实现,抽象类使用extends关键字实现继承。
接口的实现类可以有多个,抽象类的子类只能继承一个抽象类。
接口中属性的访问控制符只能是public,抽象类中的属性访问控制符无限制。
面向对象特征:封装、抽象、继承、多态
Java 多态(Polymorphism)是面向对象编程的一项核心概念,它允许对象以多种形式出现。
多态性在Java中有两个主要的表现形式:
- 编译时多态(也称为静态多态)
- 运行时多态(也称为动态多态)
编译时多态是通过方法重载(Method Overloading)实现的。这意味着在同一个类中可以定义多个方法,这些方法具有相同的名字但参数列表不同。编译器在编译时根据参数列表来决定调用哪个具体的方法。
这里大家只要知道多态还有编译时多态这种形式就可以,重点还是运行时多态。
多态存在的三个必要条件:
- 继承
- 重写
- 父类引用指向子类对象 Cal cal = new Add();
构造方法不能被重写,但是可以被重载
重载和重写区别?
重载(Overload):发生在同一个类中,方法名必须相同,参数类型、个数、顺序不同,跟方法返回值和访问修饰符没有关系。
父类中定义的方法子类不满意,子类重新定义这个方法,最典型的重写就是toString()
重写只发生在可见的实例方法中:
1:静态方法、私有方法不存在重写。
重写必须满足:两同两小一大
java和c++的区别
java和c++都是面向对象的语言,都支持封装,继承,多态但是java不提供指针来直接访问内存,java的类是单继承的,c++支持多重继承;java有自动内存管理垃圾回收机制不需要程序员手动释放内存。
Java中创建对象有几种方式
1:使用new关键字:最常见的方式。
2:反射使用Class.newInstance:通过Class类的newlnstance创建对象。
3:使用Clone:通过clone()方法创建一个对象的副本。
4:使用反序列化:通过将对象转换为字节流并保存到文件或传输到网络,然后在从字节流中重新创建对象。需要对象实现Serializable
5:
什么是深拷贝和浅拷贝、引用拷贝
浅拷贝:如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址。因此如果其中一个对象改变了这个地址,就会影响到另一个对象。
深拷贝:属性是基本类型拷贝基本类型的值,属性是引用类型,创建一个新的对象并复制其内容,因此一个对象改变不会影响到另一个对象。
IO流分类
IO流的分类:
根据处理的数据类型不同可分为:字节流,字符流。
根据数据的流向不同可分为:输入流,输出流。
**字节流:以字节为单位进行读取和写入操作,适合处理二进制数据或者文本文件,字节流类通常以inputstream,outputstream结尾,**对于处理文本文件可能需要做字符编码转换。
字符流:以字符为单位进行读取和写入操作,适合处理文本数据,字符流会自动处理字符编码转换,避免乱码问题,字符流类通常以reader,writer结尾。
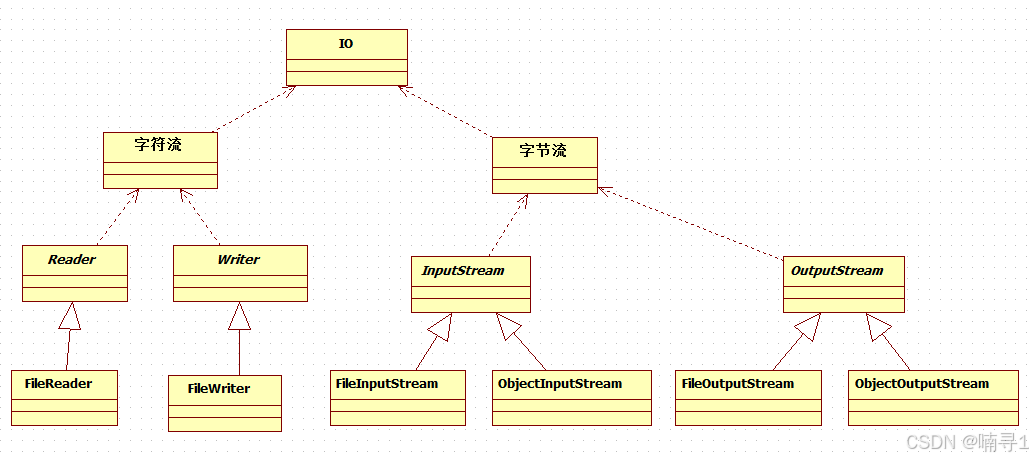
异常的继承体系、常见运行时异常
反射的概念理解:简单地说,在运行时动态的获取、操作和修改类或对象的属性,方法,构造函数等信息的能力,而不需要在编译时预先知道类的具体信息。
反射获得字节码对象的三种方式
public void testClass() throws ClassNotFoundException {
// 1.Class.forName(类路径)
Class clazz1 = Class.forName("com.situ.day15.Student");
// 2.类型.class
Class clazz2 = Student.class;
// 3.对象.getClass()
Student student = new Student();
Class clazz3 = student.getClass();
System.out.println(clazz1 == clazz2);//true
System.out.println(clazz1 == clazz3);//true
}反射使用步骤
- 获取想要操作的类的Class对象,这是反射的核心,通过Class对象我们可以任意调用类的方法。
- 调用 Class 类中的方法,既就是反射的使用阶段。
- 使用反射 API 来操作这些信息。
应用场景:1:JDBC的数据库连接中的加载驱动
2:SPring通过XML配置文件模式装载Bean,
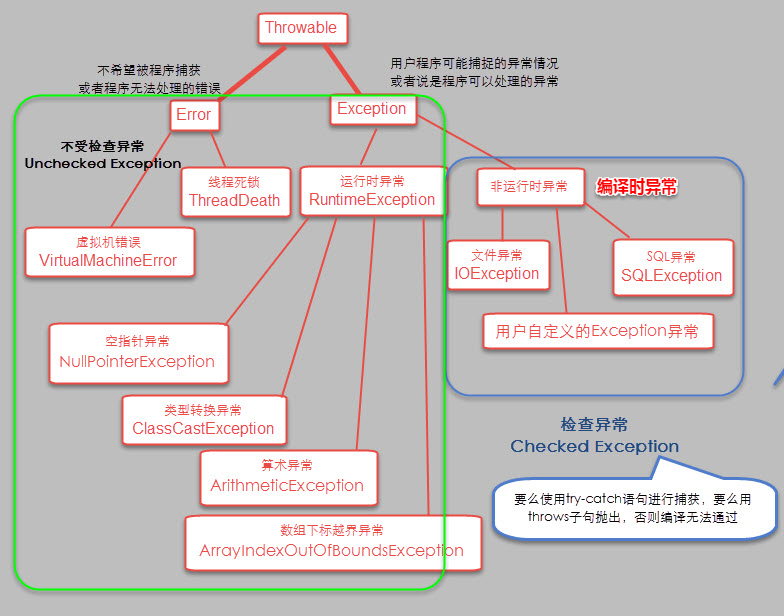
jdk8新特性1:Lambda表达式:它是函数式编程思想的一个重要体现。让我们不用关注是什么对象,而是更关注我们对数据进行了什么操作。
//Lambda表达式语法:<函数式接口><变量名>=(参数1,参数2)->{方法体};2:函数式接口:如果一个接口只有一个抽象方法,则该接口称之为函数式接口,函数式接口可以使用Lambda表达式,它会被匹配到这个抽象方法上。@Functionallnterface 注解检测接口是否复合函数式接口。
3:Stream流:Java8的Stream使用的是函数式编程模式,如同它的名字一样,它可以被用来对集合或数组进行链状流式的操作。
Stream操作步骤
1、 创建流 :
一个数据源(如:集合、数组),获取一个流
单列集合: 集合对象.stream()
数组:Arrays.stream(数组)或者使用Stream.of来创建
双列集合:转换成单列集合后再创建
2、中间操作:
一个中间操作链,对数据源的数据进行处理
filter、map、distinct、sorted、limit、skip、flatMap
3、终结操作
一旦执行终止操作,就执行中间操作链,并产生结果。之后,不会再被使用
forEach、count、max、min、collect、reduce
创建流
1、单列集合: 集合对象.stream()
Java8 中的Collection 接口被扩展,提供了两个获取流的方法:
ldefault Stream stream() : 返回一个顺序流
ldefault Stream parallelStream() : 返回一个并行流
ListStudent> students = getStudents();
StreamStudent> stream = students.stream();
2、双列集合:转换成单列集合后再创建
MapString, String> map = new HashMap<>();
map.put("cn", "中国");
map.put("us", "美国");
StreamMap.EntryString, String>> stream = map.entrySet().stream();
3、数组:Arrays.stream(数组)或者使用Stream.of来创建
Integer\[\] array = {1, 2, 3, 4};
Stream stream = Arrays.stream(array);
StreamInteger> stream = Stream.of(array);
中间操作
1.filter
对流中的元素进行条件过滤,符合过滤条件的才能继续留在流中。
打印所有姓名长度大于1的学生的姓名
@Test public void test2() { List<Student> students = getStudents(); students.stream() .filter(student -> student.getName().length() > 1) .forEach(student -> System.out.println(student.getName())); }2.map
对流中的元素进行计算或转换。 map的参数是实现Function这个函数式接口,返回值是一个stream流。
3.distinct
可以去除流中的重复元素
distinct方法是依赖Object的equals方法来判断是否是相同对象的。所以需要注意重写equals方法。
@Test public void test4() { List<Student> students = getStudents(); students.stream() .distinct() .forEach(student -> System.out.println(student.getName())); }4.sorted
可以对流中的元素进行排序。
注意:如果调用空参的sorted()方法,需要流中的元素是实现了Comparable。
对流中的元素按照年龄进行降序排序,并且要求不能有重复的元素
@Test public void test5() { List<Student> students = getStudents(); students.stream() .distinct() .sorted() .forEach(student -> System.out.println(student.getAge())); students.stream() .distinct() .sorted((o1, o2) -> o2.getAge() - o1.getAge()) .forEach(student -> System.out.println(student.getAge())); }5.limit
可以设置流的最大长度,超出的部分将被抛弃。
对流中的元素按照年龄进行降序排序,并且要求不能有重复的元素,然后打印其中年龄最大的两个学生的姓名。
@Test public void test6() { List<Student> students = getStudents(); students.stream() .distinct() .sorted() .limit(2) .forEach(student -> System.out.println(student.getName())); }6.skip
跳过流中的前n个元素,返回剩下的元素
按照年龄降序排序排列,打印除了年龄最大的学生外的其他学生,要求不能有重复元素。
@Test public void test7() { List<Student> students = getStudents(); students.stream() .distinct() .sorted() .skip(1) .forEach(student -> System.out.println(student.getName())); }7.flatMap
map只能把一个对象转换成另一个对象来作为流中的元素。而flatMap可以把一个对象转换成多个对象作为流中的元素。
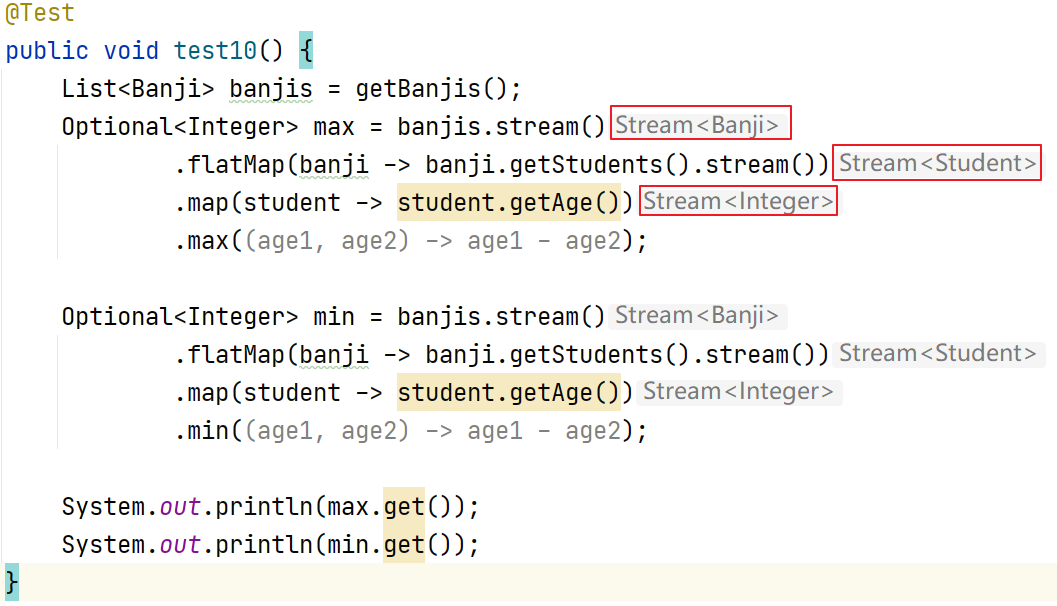
打印所有班级下面学生的名字。要求对重复的元素进行去重。
@Test public void test45() { List<Banji> banjis = getBanjis(); banjis.stream() .flatMap(new Function<Banji, Stream<? extends Student>>() { @Override public Stream<? extends Student> apply(Banji banji) { return banji.getStudents().stream(); } }) .distinct() .map(student -> student.getName()) .forEach(name -> System.out.println(name)); banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .distinct() .map(student -> student.getName()) .forEach(name -> System.out.println(name)); }5.终结操作
1.forEach
对流中的元素进行遍历操作,我们通过传入的参数去指定对遍历到的元素进行什么具体操作。
2.count
可以用来获取当前流中元素的个数。
打印这些班级的所出学生的数目,注意删除重复元素。
@Test public void test9() { List<Banji> banjis = getBanjis(); long count = banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .distinct() .count(); System.out.println(count); }3.max&min
可以用来或者流中的最值。
分别获取这些班级下的所有学生的年龄最大和最小分别打印。
4.anyMatch
查找与匹配
可以用来判断是否有任意符合匹配条件的元素,结果为boolean类型。
allMatch
可以用来判断是否都符合匹配条件,结果为boolean类型。如果都符合结果为true,否则结果为false。
noneMatch
可以判断流中的元素是否都不符合匹配条件。如果都不符合结果为true,否则结果为false
findAny
获取流中的任意一个元素。该方法没有办法保证获取的一定是流中的第一个元素。
findFirst
获取流中的第一个元素。
@Test public void test45() { List<Banji> banjis = getBanjis(); //anyMatch 判断是否有年龄在18以上的学生 boolean flag1 = banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .anyMatch(student -> student.getAge() > 18); System.out.println(flag1); //allMatch 判断是否所有的学生都是成年人 boolean flag2 = banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .allMatch(student -> student.getAge() >= 18); System.out.println(flag2); //noneMatch 判断学生是否都没有超过20岁的 boolean flag3 = banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .noneMatch(student -> student.getAge() > 20); System.out.println(flag3); //findAny 获取任意一个年龄大于18的学生,如果存在就输出他的名字 Optional<Student> optionalStudent1 = banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .filter(student -> student.getAge() > 18) .findAny(); optionalStudent1.ifPresent(student -> System.out.println(student.getName())); //findFirst 获取一个年龄最小的学生,并输出他的姓名 Optional<Student> optionalStudent2 = banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .sorted((o1, o2) -> o1.getAge() - o2.getAge()) .findFirst(); optionalStudent2.ifPresent(student -> System.out.println(student.getName())); }5.reduce归约
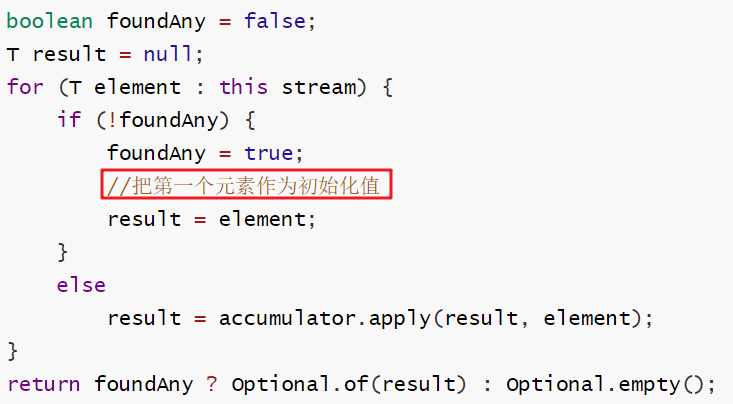
可以将流中元素反复结合起来,得到一个值
备注:map 和reduce 的连接通常称为map-reduce 模式,因Google 用它来进行网络搜索而出名。
1、传递初始值
T reduce(T identity, BinaryOperator accumulator);
2、不传递初始值,把第一个元素作为初始化值
Optional reduce(BinaryOperator accumulator);
@Test public void test99() { //可以将流中元素反复结合起来,得到一个值 int[] array = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; int sum = 0; for (int i : array) { sum += i; } System.out.println(sum); //T reduce(T identity, BinaryOperator<T> accumulator); //计算1-10的和 List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); Integer sum1 = list.stream().reduce(0, new BinaryOperator<Integer>() { @Override public Integer apply(Integer a, Integer b) { return Integer.sum(a, b); } }); Integer sum2 = list.stream().reduce(0, (a, b) -> Integer.sum(a, b)); Integer sum3 = list.stream().reduce(0, Integer::sum); System.out.println("sum1: " + sum1); System.out.println("sum2: " + sum2); System.out.println("sum3: " + sum3); //Optional<T> reduce(BinaryOperator<T> accumulator); //计算所有学生年龄总和 List<Banji> banjis = getBanjis(); Optional<Integer> sumOptional1 = banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .map(student -> student.getAge()) .reduce(new BinaryOperator<Integer>() { @Override public Integer apply(Integer a, Integer b) { return a + b; } }); Optional<Integer> sumOptional2 = banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .map(student -> student.getAge()) //.reduce((a, b) -> a + b); .reduce(Integer::sum); System.out.println(sumOptional1.get()); System.out.println(sumOptional2.get()); }6.collect收集
把当前流转换成一个集合。
获取一个存放所有学生名字的List和Set集合。
public void test11() { List<Banji> banjis = getBanjis(); List<String> nameList = banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .map(student -> student.getName()) .collect(Collectors.toList()); System.out.println(nameList); Set<String> nameSet = banjis.stream() .flatMap(banji -> banji.getStudents().stream()) .map(student -> student.getName()) .collect(Collectors.toSet()); System.out.println(nameSet); }获取一个Map集合,map的key为班级名,value为List
Map<String, List<Student>> map1 = banjis.stream() .distinct() .collect(Collectors.toMap(new Function<Banji, String>() { @Override public String apply(Banji banji) { return banji.getName(); } }, new Function<Banji, List<Student>>() { @Override public List<Student> apply(Banji banji) { return banji.getStudents(); } })); Map<String, List<Student>> map2 = banjis.stream() .distinct() .collect(Collectors.toMap(banji -> banji.getName(), banji -> banji.getStudents())); System.out.println(map1); System.out.println(map2);


四:JavaWeb
JSP的9大内置对象
request:代表客户端发起的 HTTP 请求,提供了访问请求参数、表单数据和 HTTP 头部信息的方法。二:JSP、servlet
response:代表服务器对客户端的响应,提供了控制响应的方法,例如设置响应头、发送响应内容等。
pageContext:代表当前 JSP 页面的上下文,提供了访问其他内置对象的方法,如获取 request、session、application 对象等。
session:代表用户会话,提供了在用户会话间存储和检索数据的方法,可以跨多个页面使用。
application:代表整个 Web 应用程序的上下文,提供了在应用程序范围内存储和检索数据的方法,可以在不同用户间共享。
out:代表输出流,可以通过它向客户端发送响应内容。
config:代表当前 JSP 页面的配置信息,提供了访问部署描述符(web.xml)中的配置参数的方法。
page:代表当前 JSP 页面本身,可以用于调用其他 JSP 页面或 Java 类的方法。
exception:代表 JSP 页面抛出的异常,可用于处理页面运行时错误。
转发和重定向区别
转发:一般查询了数据之后,转发到一个jsp页面进行展示
req.setAttribute("list", list);
req.getRequestDispatcher("student_list.jsp").forward(req, resp);
重定向:一般添加、删除、修改之后重定向到查找所有
resp.sendRedirect("/student");
重定向的状态码是302,重定向的地址最终是由浏览器发送这个请求
get和post区别
- 采用URL请求路径传输参数,参数拼接在URL后面
- 参数传输过程中隐私性较差,直接在URL后面
- 路径可以容纳的数据有限,只能传递少量参数
- form表单请求默认就是get
post
- 采用实体内容传参数
- 参数在传输过程中不可见,隐私性好
- 实体内容专门用来传输数据,大小没有限制
- 使用:在form上加method="post"
Servlet的生命周期方法、分别什么时候调用、调用多少次
- init方法:initial 创建完servlet对象时候调用。只调用1次。
- service:每次浏览器发出请求时候调用这个方法。调用n次。
- destory:销毁servlet对象的时候调用。停止服务器或者重新部署web应用时候会销毁servlet对象。只调用1次。
Cookie和Session的区别
Cookie:数据存储在浏览器客户端本地,减少服务器端的存储的压力,安全性不好,客户端可以清除cookie
Session:将数据存储到服务器端,安全性相对好,增加服务器的压力
JSP四大作用域(四个域对象)
四个域对象:
Request、ServletContext、Session、PageContext 都可以通过setAttribute("key", value) getAttribute("key")存取数据
什么是域对象?
Request、Session、ServletContext这三个都是域对象,域对象就是存储数据的区域(其实就是服务器中一块内存区域) ,
所有的域对象都有这三个方法:
- request.setAttribute("list", list);
- request.getAttribute("list");
- request.removeAttribute("list");
范围:ServletContext>Session>Request>PageContext
使用原则:小的范围能完成功能就放到小的里面。