
大家好,我是费益洲。上一篇文章Docker 网络详解:(一)Linux 网络虚拟化技术主要介绍了 Docker 网络用到的一些 Linux 网络虚拟化技术,本文将使用这些技术,逐步搭建一个模拟 Docker 桥接网络模式的虚拟网络环境,并对这个网络环境的连通性进行测试。本文较长,请同志们耐心观看~ ☕
💡 接下来,我们将使用 Network Namespace、veth pair、Linux Bridge 构建网络环境。试验过程中,除了系统自带的工具外,还需要使用brctl以及tcpdump等工具,请大家自行安装。另外,Linux Bridge br0 的创建过程已经在上篇文章中完成,本文不再赘述
1. Bridge 连接 veth
1️⃣ 创建并配置 veth pair
bash
[root@master01 ~]# ip link add veth0-A type veth peer name veth1-A
[root@master01 ~]# ip addr add 10.10.10.1/24 dev veth0-A
[root@master01 ~]# ip addr add 10.10.10.2/24 dev veth1-A
[root@master01 ~]# ip link set veth0-A up
[root@master01 ~]# ip link set veth1-A up查看此时的设备信息,可以看到,Linux Bridge 和 veth pair 都已经就绪:
bash
[root@master01 ~]# ip a
...
1013: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 6a:4c:b2:05:c2:e0 brd ff:ff:ff:ff:ff:ff
inet6 fe80::684c:b2ff:fe05:c2e0/64 scope link
valid_lft forever preferred_lft forever
1018: veth1-A@veth0-A: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ce:96:37:51:3a:6d brd ff:ff:ff:ff:ff:ff
inet 10.10.10.2/24 scope global veth1-A
valid_lft forever preferred_lft forever
inet6 fe80::cc96:37ff:fe51:3a6d/64 scope link
valid_lft forever preferred_lft forever
1019: veth0-A@veth1-A: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether d6:a7:d4:7c:14:34 brd ff:ff:ff:ff:ff:ff
inet 10.10.10.1/24 scope global veth0-A
valid_lft forever preferred_lft forever
inet6 fe80::d4a7:d4ff:fe7c:1434/64 scope link
valid_lft forever preferred_lft forever2️⃣ 修改内核参数
需要注意的是,此时的 veth0-A 和 veth1-A 在 Linux 内核的角度看是两个独立的网络设备,此时为这两个虚拟网卡配置了同网段的 ip,那么理论上是能够连通的,我们使用 ping 命令进行测试:
bash
[root@master01 ~]# ping -c 1 -I veth0-A 10.10.10.2
PING 10.10.10.2 (10.10.10.2) from 10.10.10.1 veth0-A: 56(84) bytes of data.
--- 10.10.10.2 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
bash
[root@master01 ~]# ping -c 1 -I veth1-A 10.10.10.1
PING 10.10.10.1 (10.10.10.1) from 10.10.10.2 veth1-A: 56(84) bytes of data.
--- 10.10.10.1 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms💣 此时发现网络不通,这并不是配置的问题,而是Linux 系统默认的安全设置可能会阻止 veth pair 接口间的通信,需要调整两个关键的内核参数:
-
accept_local: 允许接口接收源自本机的数据包
bash[root@master01 ~]# echo 1 > /proc/sys/net/ipv4/conf/veth0-A/accept_local [root@master01 ~]# echo 1 > /proc/sys/net/ipv4/conf/veth1-A/accept_local -
rp_filter(反向路径过滤): 关闭反向路径校验,防止系统丢弃那些源地址不是本机已知路由的数据包
bash[root@master01 ~]# echo 0 > /proc/sys/net/ipv4/conf/veth0-A/rp_filter [root@master01 ~]# echo 0 > /proc/sys/net/ipv4/conf/veth1-A/rp_filter [root@master01 ~]# echo 0 > /proc/sys/net/ipv4/conf/all/rp_filte
⚠️ 需要注意的是这些修改是临时的,重启后会失效。如需永久生效,需将配置写入/etc/sysctl.conf或/etc/sysctl.d/目录下的文件,然后执行sysctl -p重新加载
此时再使用 ping 命令进行测试,就会发现,数据包可以顺利传输:
bash
[root@master01 ~]# ping -c 1 -I veth0-A 10.10.10.2
PING 10.10.10.2 (10.10.10.2) from 10.10.10.1 veth0-A: 56(84) bytes of data.
64 bytes from 10.10.10.2: icmp_seq=1 ttl=64 time=0.035 ms
--- 10.10.10.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.035/0.035/0.035/0.000 ms
bash
[root@master01 ~]# ping -c 1 -I veth1-A 10.10.10.1
PING 10.10.10.1 (10.10.10.1) from 10.10.10.2 veth1-A: 56(84) bytes of data.
64 bytes from 10.10.10.1: icmp_seq=1 ttl=64 time=0.063 ms
--- 10.10.10.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.063/0.063/0.063/0.000 ms此时的网络拓扑如下所示:
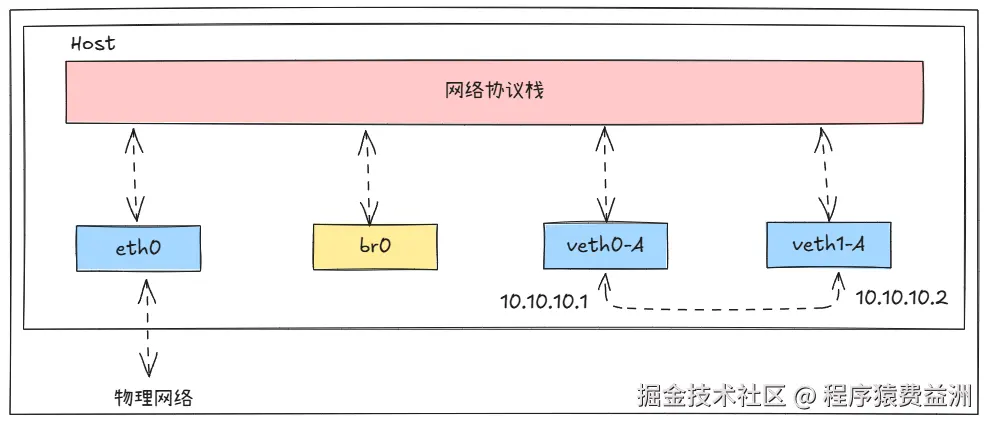
3️⃣ 将 veth0-A 连接到 br0
bash
[root@master01 ~]# ip link set dev veth0-A master br0此时,再次查看 br0 的信息:
bash
[root@master01 ~]# brctl show
bridge name bridge id STP enabled interfaces
br0 8000.d6a7d47c1434 no veth0-A上述输出表明了该网桥的 ID 是 8000.d6a7d47c1434(优先级 32768,MAC 地址 d6:a7:d4:7c:14:34),当前有一个名为 veth0-A 的虚拟以太网设备连接到了这个网桥上。
此时再查看网络设备信息:
bash
[root@master01 ~]# ip a
...
1013: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether d6:a7:d4:7c:14:34 brd ff:ff:ff:ff:ff:ff
inet6 fe80::684c:b2ff:fe05:c2e0/64 scope link
valid_lft forever preferred_lft forever
1018: veth1-A@veth0-A: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ce:96:37:51:3a:6d brd ff:ff:ff:ff:ff:ff
inet 10.10.10.2/24 scope global veth1-A
valid_lft forever preferred_lft forever
inet6 fe80::cc96:37ff:fe51:3a6d/64 scope link
valid_lft forever preferred_lft forever
1019: veth0-A@veth1-A: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP group default qlen 1000
link/ether d6:a7:d4:7c:14:34 brd ff:ff:ff:ff:ff:ff
inet 10.10.10.1/24 scope global veth0-A
valid_lft forever preferred_lft forever
inet6 fe80::d4a7:d4ff:fe7c:1434/64 scope link
valid_lft forever preferred_lft forever⚠️ 从上述信息可以看出,br0 的 MAC 地址从最开始的6a:4c:b2:05:c2:e0变为了和 veth0-A 一致的 MAC 地址ee:1e:71:74:71:44。这是 Linux Bridge 的一个特性。简单来说,Linux bridge 会自动学习并采用其连接设备中某个 MAC 地址作为自己的 MAC 地址,这通常是为了网络通信的效率和正确性。
br0 的 MAC 地址变成了 veth0-A 的 MAC 地址,这就相当于 Linux Bridge 在 veth0-A 和协议栈之间做了一次拦截,将 veth0-A 要转发给协议栈的数据拦截下来,全部转发给 br0。同时,由于 veth pair 的特性,br0 依旧还能向 veth0-A 发送数据。
💣 这里会有一个很有意思的现象,在刚刚将 veth0-A 连接到 br0 时,此时使用 ping 命令测试网络连通性如下所示:
bash
[root@master01 ~]# ping -c 1 -I veth0-A 10.10.10.2
PING 10.10.10.2 (10.10.10.2) from 10.10.10.1 veth0-A: 56(84) bytes of data.
64 bytes from 10.10.10.2: icmp_seq=1 ttl=64 time=0.027 ms
--- 10.10.10.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.027/0.027/0.027/0.000 ms
bash
[root@master01 ~]# ping -c 1 -I veth1-A 10.10.10.1
PING 10.10.10.1 (10.10.10.1) from 10.10.10.2 veth1-A: 56(84) bytes of data.
--- 10.10.10.1 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0msveth0-A 可以 ping 通 veth1-A,但是 veth1-A 无法 ping 通 veth0-A,但是!!!!过了一会后,互相都 ping 不通了:
bash
[root@master01 ~]# ping -c 1 -I veth0-A 10.10.10.2
PING 10.10.10.2 (10.10.10.2) from 10.10.10.1 veth0-A: 56(84) bytes of data.
--- 10.10.10.2 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
bash
[root@master01 ~]# ping -c 1 -I veth1-A 10.10.10.1
PING 10.10.10.1 (10.10.10.1) from 10.10.10.2 veth1-A: 56(84) bytes of data.
--- 10.10.10.1 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms造成这一特殊现象的元凶就是:ARP 缓存。此时为了同时们不和我一样犯迷糊,推荐使用命令刷新下 ARP 缓存再进行试验:
bash
[root@master01 ~]# ip neighbor flush dev veth0-A
[root@master01 ~]# ip neighbor flush dev veth1-AWhy?
为什么 veth0-A 在连接到 br0 后,veth pair 之间就无法互相 ping 通呢?我们使用 tcpdump 抓包来分析这个过程,我们从 veth0-A ping veth1-A,同时抓取 veth1-A 上的报文:
bash
[root@master01 ~]# ping -c 1 -I veth0-A 10.10.10.2
PING 10.10.10.2 (10.10.10.2) from 10.10.10.1 veth0-A: 56(84) bytes of data.
--- 10.10.10.2 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms相关报文如下:
bash
[root@master01 ~]# tcpdump -n -i veth1-A
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on veth1-A, link-type EN10MB (Ethernet), snapshot length 262144 bytes
16:36:51.813040 ARP, Request who-has 10.10.10.2 tell 10.10.10.1, length 28
16:36:51.813045 ARP, Reply 10.10.10.2 is-at ce:96:37:51:3a:6d, length 28
...由于 veth0-A 的 ARP 缓存中没有 veth1-A 的 MAC 地址,所以 ping 之前先发 ARP 请求。而从 veth1-A 抓取到的报文中可以看出,veth1-A 收到了 ARP 请求,并进行了应答。
相同的操作,再次抓取 veth0-A 的报文:
bash
[root@master01 ~]# tcpdump -n -i veth0-A
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on veth0-A, link-type EN10MB (Ethernet), snapshot length 262144 bytes
17:06:23.550541 ARP, Request who-has 10.10.10.2 tell 10.10.10.1, length 28
17:06:23.550547 ARP, Reply 10.10.10.2 is-at ce:96:37:51:3a:6d, length 28如上所示,veth0-A 的数据包都发出去了,而且也收到了响应。
相同的操作,再抓取 br0 上的报文:
bash
[root@master01 ~]# tcpdump -n -i br0
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on br0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
17:09:19.677063 ARP, Reply 10.10.10.2 is-at ce:96:37:51:3a:6d, length 28
17:09:20.725222 ARP, Reply 10.10.10.2 is-at ce:96:37:51:3a:6d, length 28通过分析以上报文可以得出,veth pair 之间包的请求和应答都没有问题,问题就出在 veth0-A 收到应答包后没有给协议栈,而是给了 br0。由于协议栈得不到 veth1-A 的 MAC 地址,继而导致了通信失败。此时的网络拓扑如下所示:
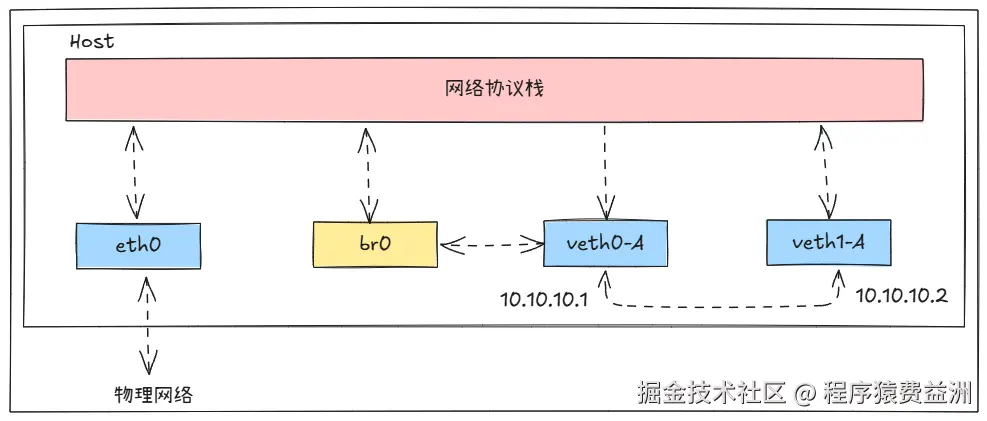
4️⃣ 将 IP 赋给 Linux Bridge
通过上面的试验可以看出,给 veth0-A 配置 IP 没有意义。因为 veth0-A 连接到 br0 后,会对报文数据做拦截,导致协议栈将数据包传给 veth0-A 后,veth0-A 无法将回程报文返回给协议栈。这里我们把 veth0-A 的 IP 地址重新配置给 br0:
bash
[root@master01 ~]# ip addr del 10.10.10.1/24 dev veth0-A
[root@master01 ~]# ip addr add 10.10.10.1/24 dev br0重新分配后,设备信息如下所示:
bash
1013: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether d6:a7:d4:7c:14:34 brd ff:ff:ff:ff:ff:ff
inet 10.10.10.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::684c:b2ff:fe05:c2e0/64 scope link
valid_lft forever preferred_lft forever
1018: veth1-A@veth0-A: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ce:96:37:51:3a:6d brd ff:ff:ff:ff:ff:ff
inet 10.10.10.2/24 scope global veth1-A
valid_lft forever preferred_lft forever
inet6 fe80::cc96:37ff:fe51:3a6d/64 scope link
valid_lft forever preferred_lft forever
1019: veth0-A@veth1-A: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP group default qlen 1000
link/ether d6:a7:d4:7c:14:34 brd ff:ff:ff:ff:ff:ff
inet6 fe80::d4a7:d4ff:fe7c:1434/64 scope link
valid_lft forever preferred_lft forever此时,通过 br0 ping veth1-A,就能成功收到 ICMP 的回程报文了:
bash
[root@master01 ~]# ping -c 1 -I br0 10.10.10.2
PING 10.10.10.2 (10.10.10.2) from 10.10.10.1 br0: 56(84) bytes of data.
64 bytes from 10.10.10.2: icmp_seq=1 ttl=64 time=0.050 ms
--- 10.10.10.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.050/0.050/0.050/0.000 ms🔍 将 veth0-A 的 IP 重置配置给 br0,相当于去掉了 veth0-A 和协议栈之间的联系,此时 veth0-A 就相当于一根连接 br0 和 veth1-A 的网线。(此时所说的去掉了 veth0-A 和协议栈之间的联系,只是因为 veth0-A 没有 IP 了,协议栈在路由的时候不会将数据包发给 veth0-A)。这里还需要注意宿主机中和 br0 相关的一条 route 信息,这条路由信息是在为 br0 配置好 IP 且启动该 br0 后,才生成的一条信息:
bash
[root@master01 ~]# ip route
...
10.10.10.0/24 dev br0 proto kernel scope link src 10.10.10.1
...🥇 重要说明:
-
Linux Bridge 本质上是一个二层(数据链路层)虚拟网络设备,像一个虚拟的交换机。它的核心功能是在连接的设备(如虚拟机、容器或其他网络接口)之间基于 MAC 地址学习和转发数据帧。路由(Routing)则是三层(网络层)的概念
-
当我们给 Bridge 分配了 IP 地址后,系统增加的那条直连路由的意义在于告诉系统:发往这个 IP 网段的数据包,请从 br0 这个接口出去。这样,连接到 br0 的其他设备(如容器或虚拟机)才能与主机通过 IP 进行通信
-
如果你希望连接到 Bridge 的设备(如容器或虚拟机)能够访问外部网络(如互联网),除了设置路由外,通常还需要在主机上配置 IP 转发和 iptables NAT 规则 (例如 iptables -t nat -A POSTROUTING -s {网段} -j MASQUERADE)
此时的网络拓扑如下所示:
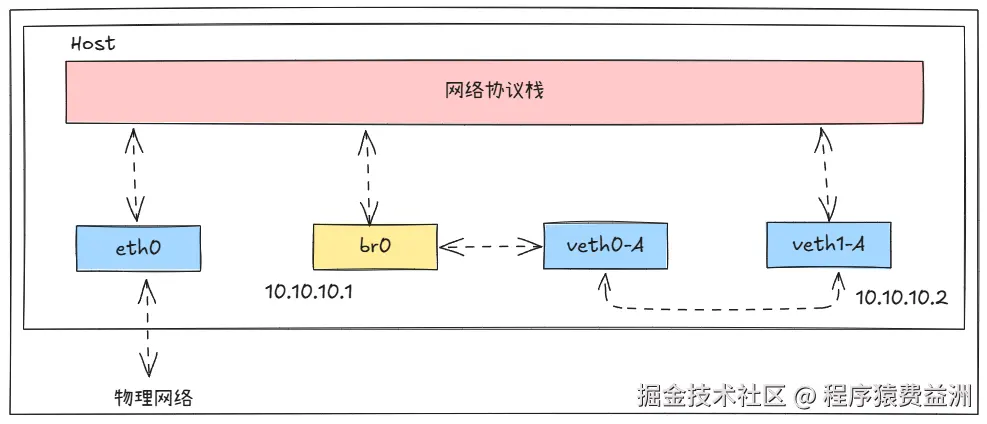
2. 多个 Network Namespace 互联
在 Linux Bridge 和单个 veth pair 联通的前提下,现在试验通过两对 veth pair 和 Linux Bridge 将两个 Network Namespace 联通起来,构建一个复杂的二层网络。
1️⃣ 创建 Network Namespace
bash
[root@master01 ~]# ip netns add A
[root@master01 ~]# ip netns add B2️⃣ 创建 veth pair
bash
[root@master01 ~]# ip link add vethA type veth peer name vethA-br
[root@master01 ~]# ip link add vethB type veth peer name vethB-br
bash
[root@master01 ~]# ip a
...
1024: vethA-br@vethA: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether e6:53:c8:f2:7f:25 brd ff:ff:ff:ff:ff:ff
1025: vethA@vethA-br: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether ee:ae:59:96:3c:74 brd ff:ff:ff:ff:ff:ff
1026: vethB-br@vethB: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether de:c0:72:84:ce:56 brd ff:ff:ff:ff:ff:ff
1027: vethB@vethB-br: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether be:f4:68:82:d2:82 brd ff:ff:ff:ff:ff:ff3️⃣ 将 veth pair 的一端放入对应的 Network Namespace 中
bash
[root@master01 ~]# ip link set vethA netns A
[root@master01 ~]# ip link set vethB netns B
bash
[root@master01 ~]# ip netns exec A ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
1025: vethA@if1024: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ee:ae:59:96:3c:74 brd ff:ff:ff:ff:ff:ff link-netnsid 0
bash
[root@master01 ~]# ip netns exec B ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
1027: vethB@if1026: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether be:f4:68:82:d2:82 brd ff:ff:ff:ff:ff:ff link-netnsid 04️⃣ 将 veth pair 的另一端连接到网桥 br0
bash
[root@master01 ~]# ip link set vethA-br master br0
[root@master01 ~]# ip link set vethB-br master br0
bash
[root@master01 ~]# ip a
...
1013: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether d6:a7:d4:7c:14:34 brd ff:ff:ff:ff:ff:ff
inet 10.10.10.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::684c:b2ff:fe05:c2e0/64 scope link
valid_lft forever preferred_lft forever
1024: vethA-br@if1025: <BROADCAST,MULTICAST> mtu 1500 qdisc noop master br0 state DOWN group default qlen 1000
link/ether e6:53:c8:f2:7f:25 brd ff:ff:ff:ff:ff:ff link-netns A
1026: vethB-br@if1027: <BROADCAST,MULTICAST> mtu 1500 qdisc noop master br0 state DOWN group default qlen 1000
link/ether de:c0:72:84:ce:56 brd ff:ff:ff:ff:ff:ff link-netns B5️⃣ 设置 veth 的 ip 并启动
Network Namespace A
bash
[root@master01 ~]# ip link set vethA-br up
[root@master01 ~]# ip netns exec A bash
[root@master01 ~]# ip addr add 10.10.10.4/24 dev vethA
[root@master01 ~]# ip link set lo up
[root@master01 ~]# ip link set vethA up
[root@master01 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
1025: vethA@if1024: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ee:ae:59:96:3c:74 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.10.10.4/24 scope global vethA
valid_lft forever preferred_lft forever
inet6 fe80::ecae:59ff:fe96:3c74/64 scope link
valid_lft forever preferred_lft forever
[root@master01 ~]# exit
exitNetwork Namespace B
bash
[root@master01 ~]# ip link set vethB-br up
[root@master01 ~]# ip netns exec B bash
[root@master01 ~]# ip addr add 10.10.10.5/24 dev vethB
[root@master01 ~]# ip link set lo up
[root@master01 ~]# ip link set vethB up
[root@master01 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
1027: vethB@if1026: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether be:f4:68:82:d2:82 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.10.10.5/24 scope global vethB
valid_lft forever preferred_lft forever
inet6 fe80::bcf4:68ff:fe82:d282/64 scope link
valid_lft forever preferred_lft forever
[root@master01 ~]# exit
exit6️⃣ 测试网络联通
此时,理论上来说,Network Namespace A 和 B 是能够联通的,但是测试结果:
Network Namespace A ping 10.10.10.5
bash
[root@master01 ~]# ip netns exec A bash
[root@master01 ~]# ping -c 1 10.10.10.5
PING 10.10.10.5 (10.10.10.5) 56(84) bytes of data.
From 10.10.10.4 icmp_seq=1 Destination Host Unreachable
--- 10.10.10.5 ping statistics ---
1 packets transmitted, 0 received, +1 errors, 100% packet loss, time 0ms
[root@master01 ~]# exit
exitNetwork Namespace B ping 10.10.10.4
bash
[root@master01 ~]# ip netns exec B bash
[root@master01 ~]# ping -c 1 10.10.10.4
PING 10.10.10.4 (10.10.10.4) 56(84) bytes of data.
From 10.10.10.5 icmp_seq=1 Destination Host Unreachable
--- 10.10.10.4 ping statistics ---
1 packets transmitted, 0 received, +1 errors, 100% packet loss, time 0ms
[root@master01 ~]# exit
exit7️⃣ 修改内核参数
💣 经过测试发现,网络并不想期望中的那样互通。导致这个问题的原因就是 Linux 内核的一个参数/proc/sys/net/bridge/bridge-nf-call-iptables导致的。这个内核参数决定了通过 Linux 网桥的流量是否要经过主机上配置的 iptables 规则(特别是 FORWARD 链)进行处理。当/proc/sys/net/bridge/bridge-nf-call-iptables为1时,br_netfilter 内核模块会使原本在网桥上转发的二层流量被"注入"到三层的 netfilter(iptables)框架中 处理。这使得桥接流量会经过 iptables 的 FORWARD 链(以及 PREROUTING、POSTROUTING 等链),从而应用相应的防火墙或 NAT 规则
查看内核参数:
bash
[root@master01 ~]# cat /proc/sys/net/bridge/bridge-nf-call-iptables
1此时已经开启了流量转发,所以需要为 br0 配置一条 iptables 转发规则。如果未开启,则可以忽略此步骤。
8️⃣ 增加 iptables 转发规则
bash
[root@master01 ~]# iptables -A FORWARD -i br0 -o br0 -j ACCEPT
[root@master01 ~]# iptables-save > /etc/sysconfig/iptables9️⃣ 再次测试网络连通性
Network Namespace A ping 10.10.10.5
bash
[root@master01 ~]# ip netns exec A bash
[root@master01 ~]# ping -c 1 10.10.10.5
PING 10.10.10.5 (10.10.10.5) 56(84) bytes of data.
64 bytes from 10.10.10.5: icmp_seq=1 ttl=64 time=0.068 ms
--- 10.10.10.5 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.068/0.068/0.068/0.000 ms
[root@master01 ~]# exit
exitNetwork Namespace B ping 10.10.10.4
bash
[root@master01 ~]# ip netns exec B bash
[root@master01 ~]# ping -c 1 10.10.10.4
PING 10.10.10.4 (10.10.10.4) 56(84) bytes of data.
64 bytes from 10.10.10.4: icmp_seq=1 ttl=64 time=0.045 ms
--- 10.10.10.4 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.045/0.045/0.045/0.000 ms
[root@master01 ~]# exit
exit此时的网络拓扑如下所示:
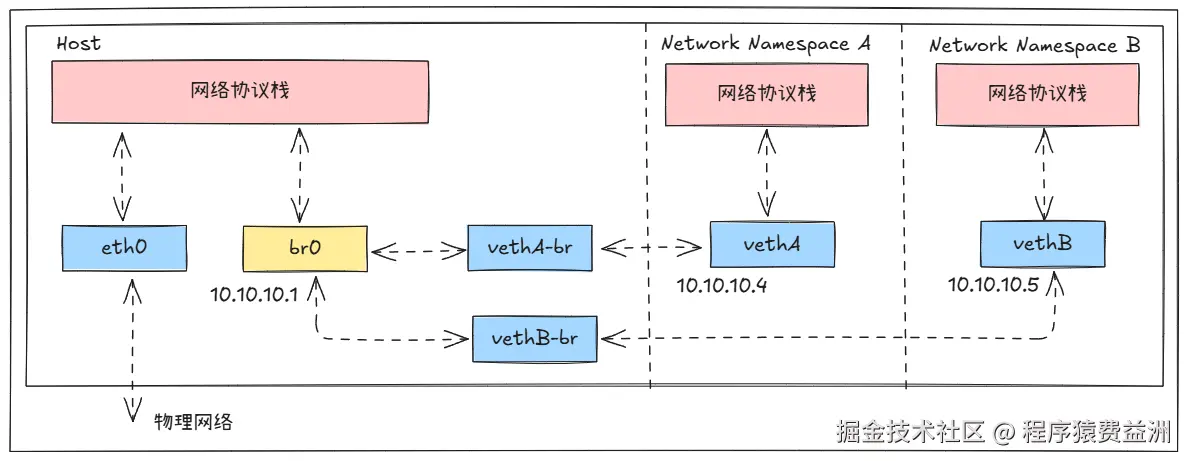
3. 宿主机访问 Network Namespace
由于为 br0 分配 IP 并启动后,在 route 表里生成的路由信息。使得宿主机可以直接联通 Netns,使用 ping 测试联通性,从宿主机分别 ping A、B 两个 Network Namespace:
bash
[root@master01 ~]# ping -c 1 10.10.10.4
PING 10.10.10.4 (10.10.10.4) 56(84) bytes of data.
64 bytes from 10.10.10.4: icmp_seq=1 ttl=64 time=0.071 ms
--- 10.10.10.4 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.071/0.071/0.071/0.000 ms
bash
[root@master01 ~]# ping -c 1 10.10.10.5
PING 10.10.10.5 (10.10.10.5) 56(84) bytes of data.
64 bytes from 10.10.10.5: icmp_seq=1 ttl=64 time=0.081 ms
--- 10.10.10.5 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.081/0.081/0.081/0.000 ms4. Network Namespace 访问宿主机
现在从 Network Namespace 中访问宿主机 IP,会发现网络不可达:
bash
[root@master01 ~]# ip netns exec A ping 172.16.200.18
ping: connect: Network is unreachable
bash
[root@master01 ~]# ip netns exec B ping 172.16.200.18
ping: connect: Network is unreachable这是因为在 Network Namespace A、B 中,还需要配置路由,才能把网络包从 Network Namespace 转发出来,现在 Network Namespace 中的路由信息如下:
bash
[root@master01 ~]# ip netns exec A ip route show
10.10.10.0/24 dev vethA proto kernel scope link src 10.10.10.4
bash
[root@master01 ~]# ip netns exec B ip route show
10.10.10.0/24 dev vethB proto kernel scope link src 10.10.10.5现在 Network Namespace 中都只有一条路由信息:所有发送到 10.10.10.0/24 这个网段的数据包,都可以直接通过 vethA、vethB 这个接口送达,无需经过任何网关(路由器)。这是一条数据包入口的路由,还需要配置一条数据包出口路由:
bash
[root@master01 ~]# ip netns exec A ip route add default via 10.10.10.1 dev vethA
[root@master01 ~]# ip netns exec B ip route add default via 10.10.10.1 dev vethB现在 Network Namespace 中的路由信息如下:
bash
[root@master01 ~]# ip netns exec A ip route show
default via 10.10.10.1 dev vethA
10.10.10.0/24 dev vethA proto kernel scope link src 10.10.10.4
bash
[root@master01 ~]# ip netns exec B ip route show
default via 10.10.10.1 dev vethB
10.10.10.0/24 dev vethB proto kernel scope link src 10.10.10.5可以看到,此时非 10.10.10.0/24 网段的数据都会走默认规则,也就是发送给网关 10.10.10.1。此时再次测试从 Network Namespace 到宿主机的网络联通性,就会发现网络已联通:
bash
[root@master01 ~]# ip netns exec A ping -c 1 172.16.200.18
PING 172.16.200.18 (172.16.200.18) 56(84) bytes of data.
64 bytes from 172.16.200.18: icmp_seq=1 ttl=64 time=0.054 ms
--- 172.16.200.18 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.054/0.054/0.054/0.000 ms
bash
[root@master01 ~]# ip netns exec B ping -c 1 172.16.200.18
PING 172.16.200.18 (172.16.200.18) 56(84) bytes of data.
64 bytes from 172.16.200.18: icmp_seq=1 ttl=64 time=0.050 ms
--- 172.16.200.18 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.050/0.050/0.050/0.000 ms5. Network Namespace 访问外网
现在从 Network Namespace 已经能够访问宿主机了,但是访问外网就会发现,网络不通:
bash
[root@master01 ~]# ip netns exec A ping -c 1 192.168.252.3
PING 192.168.252.3 (192.168.252.3) 56(84) bytes of data.
--- 192.168.252.3 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
bash
[root@master01 ~]# ip netns exec B ping -c 1 192.168.252.3
PING 192.168.252.3 (192.168.252.3) 56(84) bytes of data.
--- 192.168.252.3 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms💡 这里使用宿主机的 DNS 服务器作为"外网",如果 Network Namespace 能够访问 DNS 服务器,则说明 Network Namespace 的数据包已经有宿主机转发出去了。同志们次数可以替换为自己机器的 DNS 服务器地址,请注意甄别(一般环境可以使用 114.114.114.114)。
这需要配置 iptables 规则,并配置宿主机内核参数,才能把网络数据包转发出去。
1️⃣ 检查内核参数 IP forwarding 是否开启,如未开启,则手动开启:
bash
[root@master01 ~]# echo 1 > /proc/sys/net/ipv4/conf/all/forwarding2️⃣ 确认 iptables FORWARD 的缺省策略是否为 ACCEPT,如果缺省策略为 DROP,则需要手动修改为 ACCEPT:
查看 iptables FORWARD 的缺省策略
bash
[root@master01 ~]# iptables -t filter -L FORWARD
Chain FORWARD (policy DROP)
target prot opt source destination手动设置为 ACCEPT
bash
[root@master01 ~]# iptables -t filter -P FORWARD ACCEPT3️⃣ 配置 SNAP 规则
bash
[root@master01 ~]# iptables -t nat -A POSTROUTING -s 10.10.10.0/24 ! -o br0 -j MASQUERADE此时再次从 Network Namespace 访问外网,就会发现已经可以访问到外网了:
bash
[root@master01 ~]# ip netns exec A ping -c 1 192.168.252.3
PING 192.168.252.3 (192.168.252.3) 56(84) bytes of data.
64 bytes from 192.168.252.3: icmp_seq=1 ttl=124 time=0.469 ms
--- 192.168.252.3 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.469/0.469/0.469/0.000 ms
bash
[root@master01 ~]# ip netns exec B ping -c 1 192.168.252.3
PING 192.168.252.3 (192.168.252.3) 56(84) bytes of data.
64 bytes from 192.168.252.3: icmp_seq=1 ttl=124 time=0.485 ms
--- 192.168.252.3 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.485/0.485/0.485/0.000 ms