如何训练一个chatGPT from zero to hero,主要来源是Karpathy 大神的视频
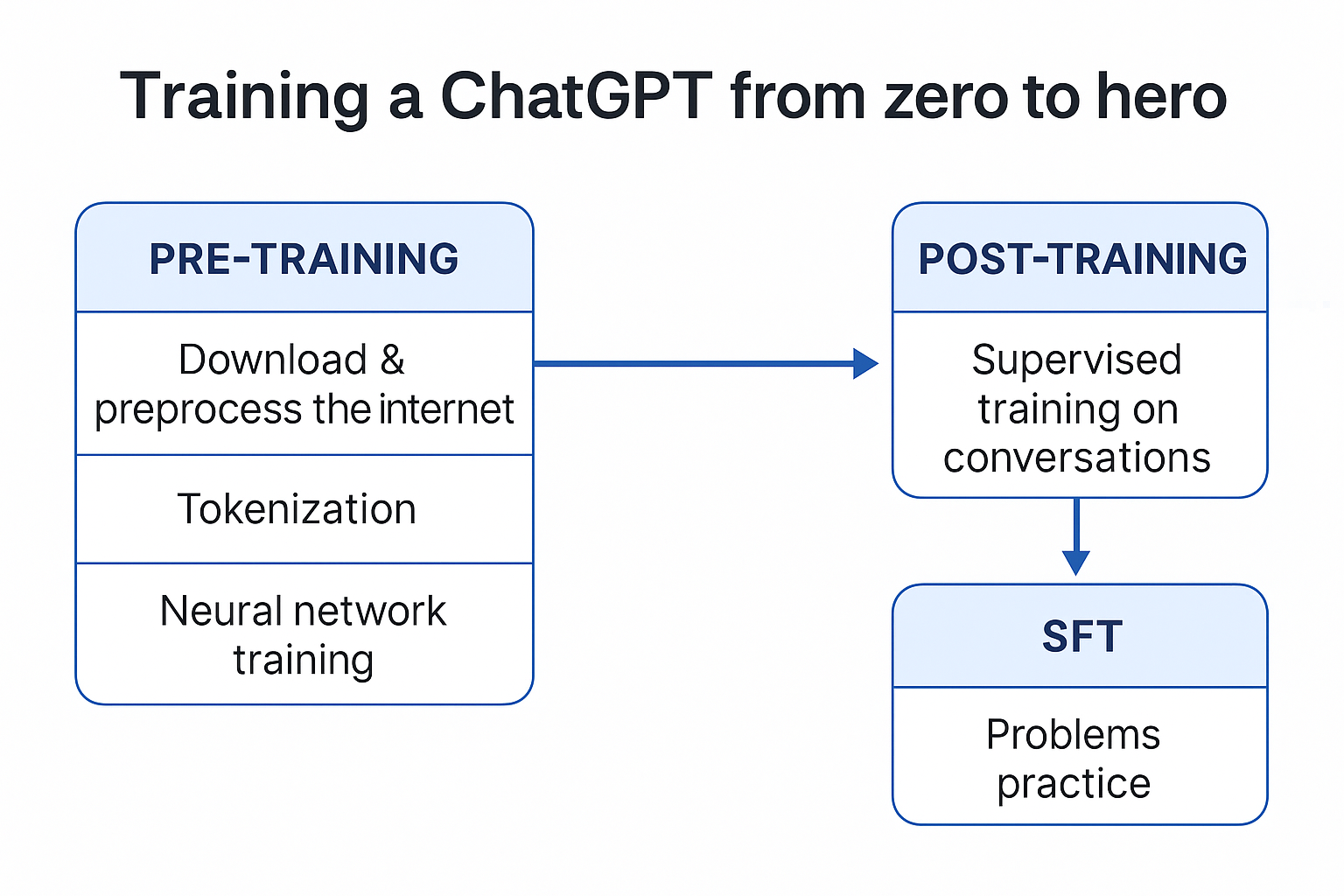
一、预训练 (Pretraining)
Unsupervised Training --- 让模型"学会说话"
Step 1: Download and preprocessing the internet 下载并清洗互联网数据
- 从开放语料抓取:Common Crawl、Wikipedia、Books、GitHub、StackExchange、ArXiv
- 去重、过滤低质量和有害内容
- 保证语料领域、语言分布均衡
现代大模型的预训练通常使用 10~15 万亿 tokens 的数据,覆盖多领域文本。
Step 2: Tokenization
Transform the raw data into unique IDs sequences
把原始文本转成唯一的 token ID 序列
- 编码算法 / Algorithm :Byte Pair Encoding (BPE)
高频连续出现的 bytes 对重新组合成 token - 示例 / Example :
playing→play+ing - 工具 / Tool :在线分词工具
模型看到的是 token 而不是字母,因此它对拼写和数字敏感度低,容易数错。
Step 3: Neural network training
-
Give you an intuition of the process of training
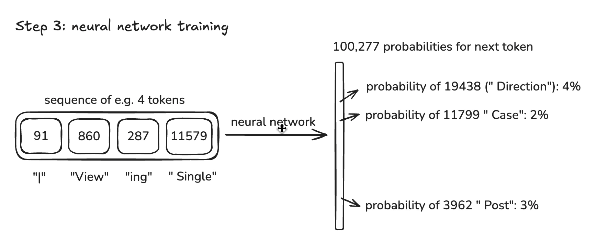
Take a window of tokens → predict the next token
取一个 token 窗口,让模型预测下一个 token
-
Model structure
Transformer Decoder 堆叠,包含多层自注意力和前馈网络
可视化参考:LLM Visualization
-
训练目标 / Objective
最小化交叉熵损失 (Cross-Entropy Loss),优化下一个 token 的概率分布
Demo: Reproducing OpenAI's GPT-2
推荐入门用 nanoGPT 复现小型 GPT-2 模型,几百行代码即可跑通。
二、后训练 (Post-training)
Supervised Training --- 让模型"学会对话"
-
Make some conversations
收集高质量对话语料,让模型学会对话风格 -
Encoding conversations
用特殊 token 表示角色切换:<|im_start|>user
What is 2+2?
<|im_end|>
<|im_start|>assistant
4
<|im_end|>
Hallucinations 幻觉问题
- What is & Why it is?
Hallucination = 模型编造不存在的事实,只因它按概率预测最可能的下一个词 - How to solve it?
-
Allow the model to say "I don't know"
-
设计事实一致性训练:给模型真假陈述,强制学会拒绝编造
-
更好的方案:让模型调用工具,如搜索、数据库,得到事实后再回答
<Search_START>who is Orson Kovacs?<Search_END>
→ 将搜索结果插入上下文,让模型更新回答
RLHF (Reinforcement Learning with Human Feedback)
通过人类反馈或奖励模型对回答排序,用 PPO/DPO 调整参数,让模型更符合人类偏好
目标:有用 Helpful + 无害 Harmless + 诚实 Truthful
三、SFT(Supervised Fine-tuning)
Problems Practice --- 让模型"刷题
- 收集特定任务的数据集:数学题、逻辑推理、代码挑战
- 从简单到复杂,逐步训练(Curriculum Learning)
- 可结合 Chain-of-Thought 提示,提升推理稳定性
效果:显著提升模型在数学、推理、专业考试上的表现
四 Demo 资源推荐
- 复现 GPT-2 : Andrej Karpathy 的 nanoGPT
小规模 GPT 预训练示例,几百行代码就能跑通 - RLHF 实践 : trl (HuggingFace)
提供 PPO/DPO 的实现,能直接用来做偏好优化 - 开源大模型 : Llama 3 / Qwen
可在已有权重上做 SFT 或 RLHF,成本更低
References:
1. Karpathy 大神讲解