在配置ETL流程时,当我们遇到一些有增长规律的重复性任务,我们需要为每一张表配置一个组件,重复拉取配置相同的组件步骤使得任务变得繁杂,我们可以使用自增量组件+动态库表输入/输出组件结合的方式实现一个动态输入/输出组件就可以输入或输出多张表。
一、动态读取表
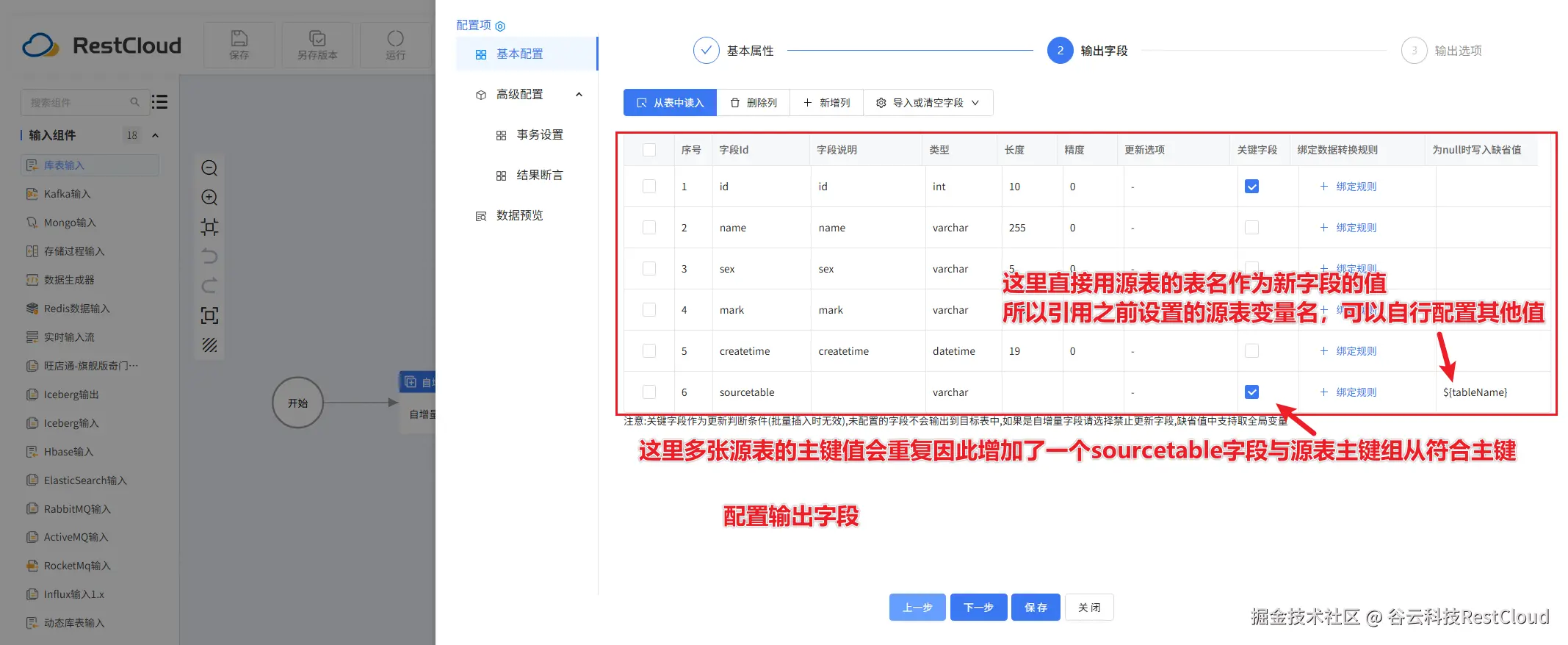
这里有一个场景,有多张相同表结构的表,他们的表名呈规律变化,比如是字符串+数字的形式,table1到table100,要把他们全部合并同步到一张大表里面,大表的表结构在源表的基础上增加一个字段,字段值记录该行数据的来源也就是从哪张源表同步到这张大表。
正常的情况是源表有多少张表就拉取多少个库表输入组件,指定源表是哪一张,并把它同步到目标表去。但这种方式就需要拉取100个库表输入,而这100个库表输入的配置也仅仅是表名不一样而已。这种情况我们就可以使用动态库表输入组件去简化配置:

设计一个这样的流程:
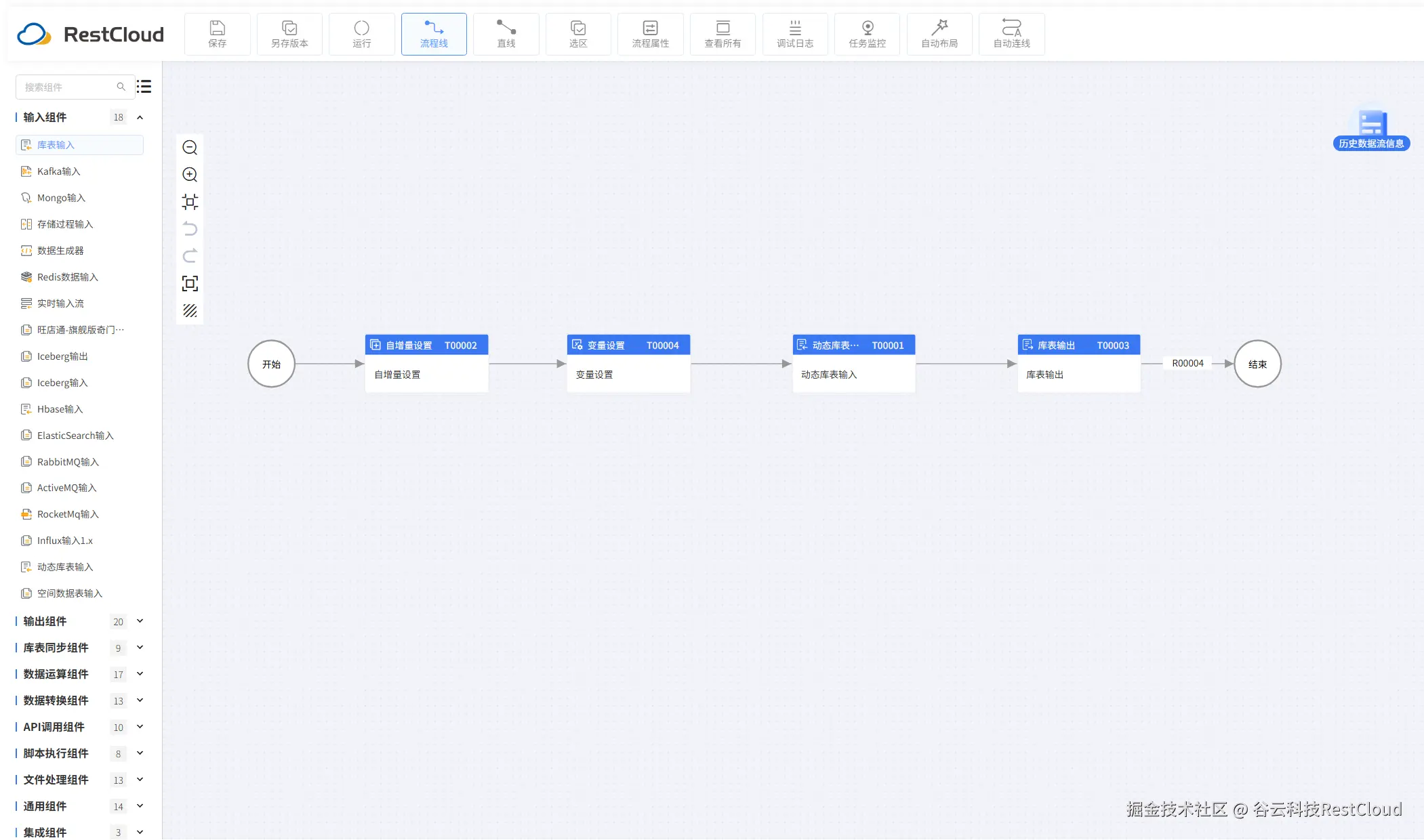
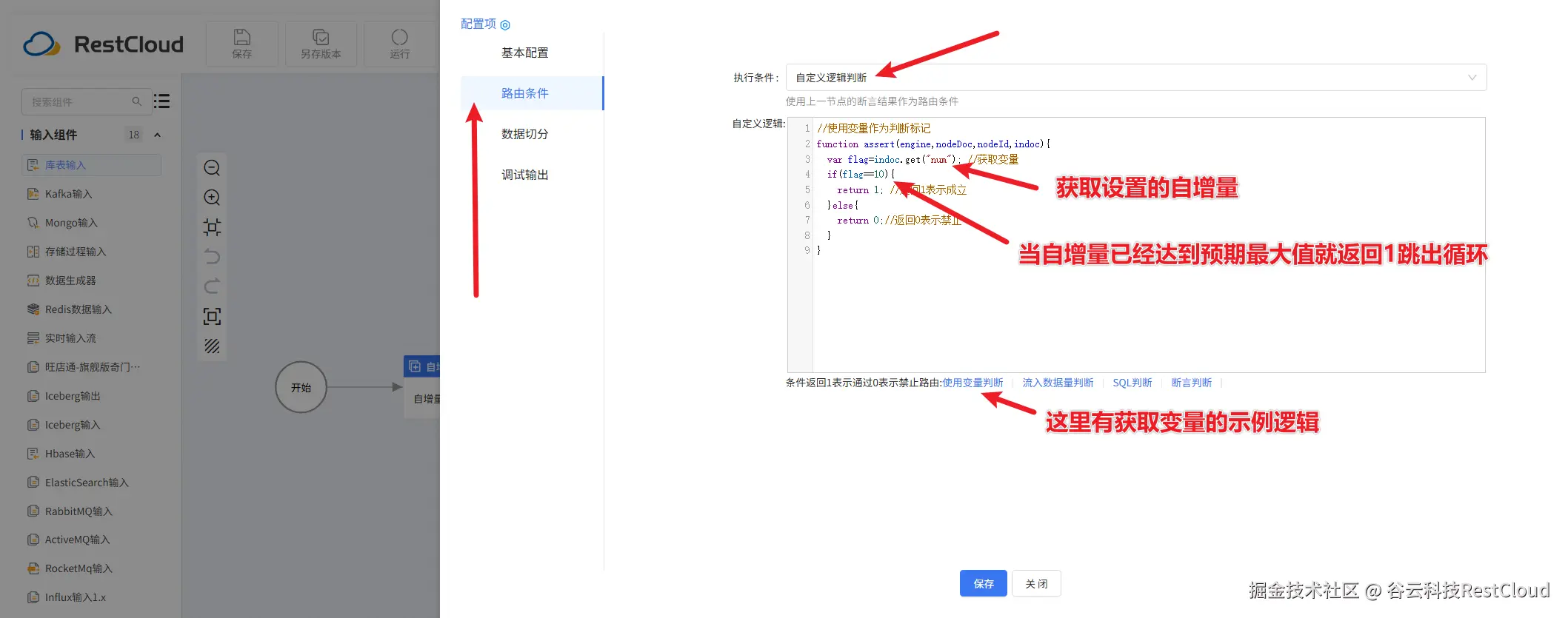
自增量组件配置:
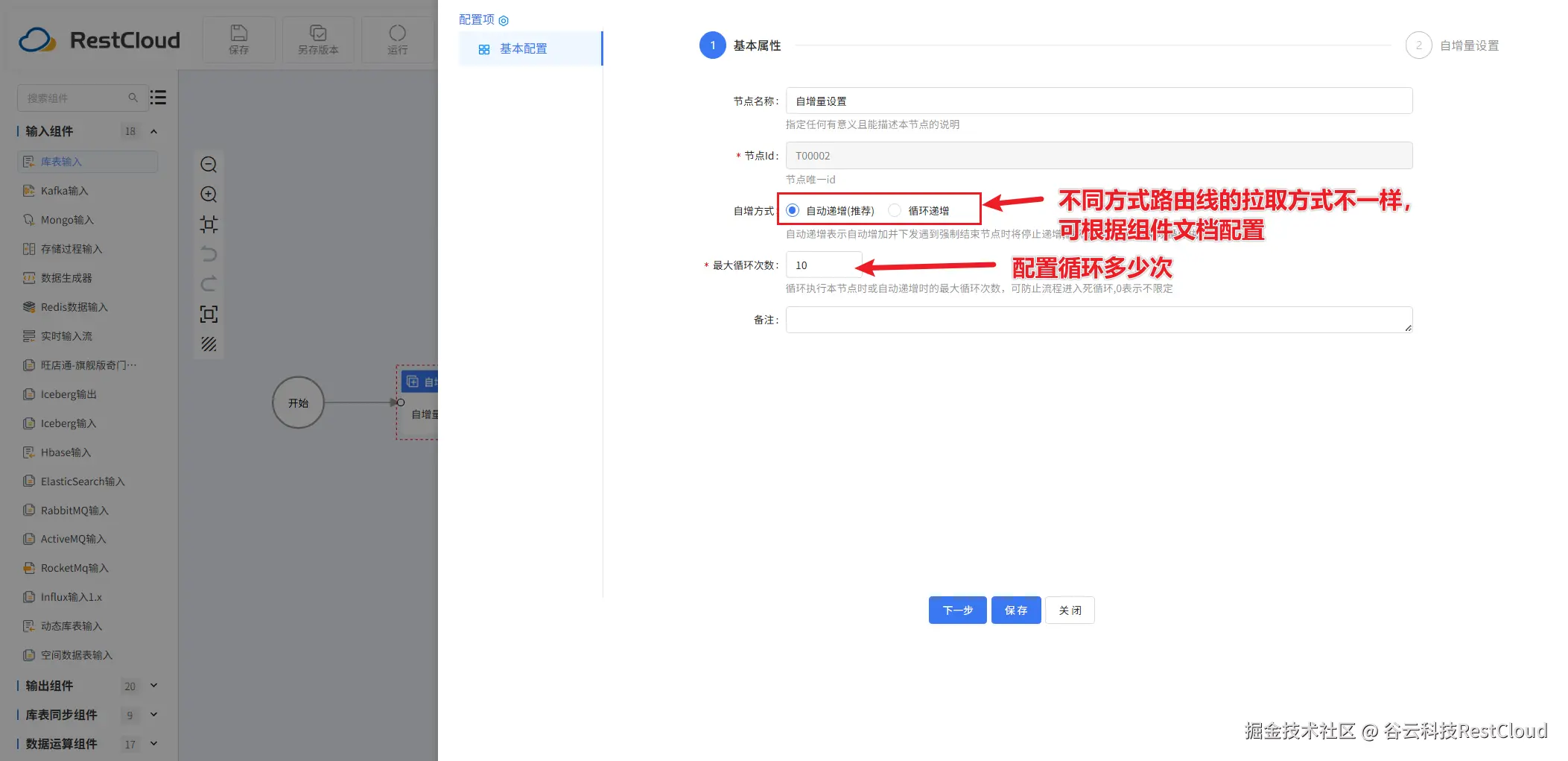
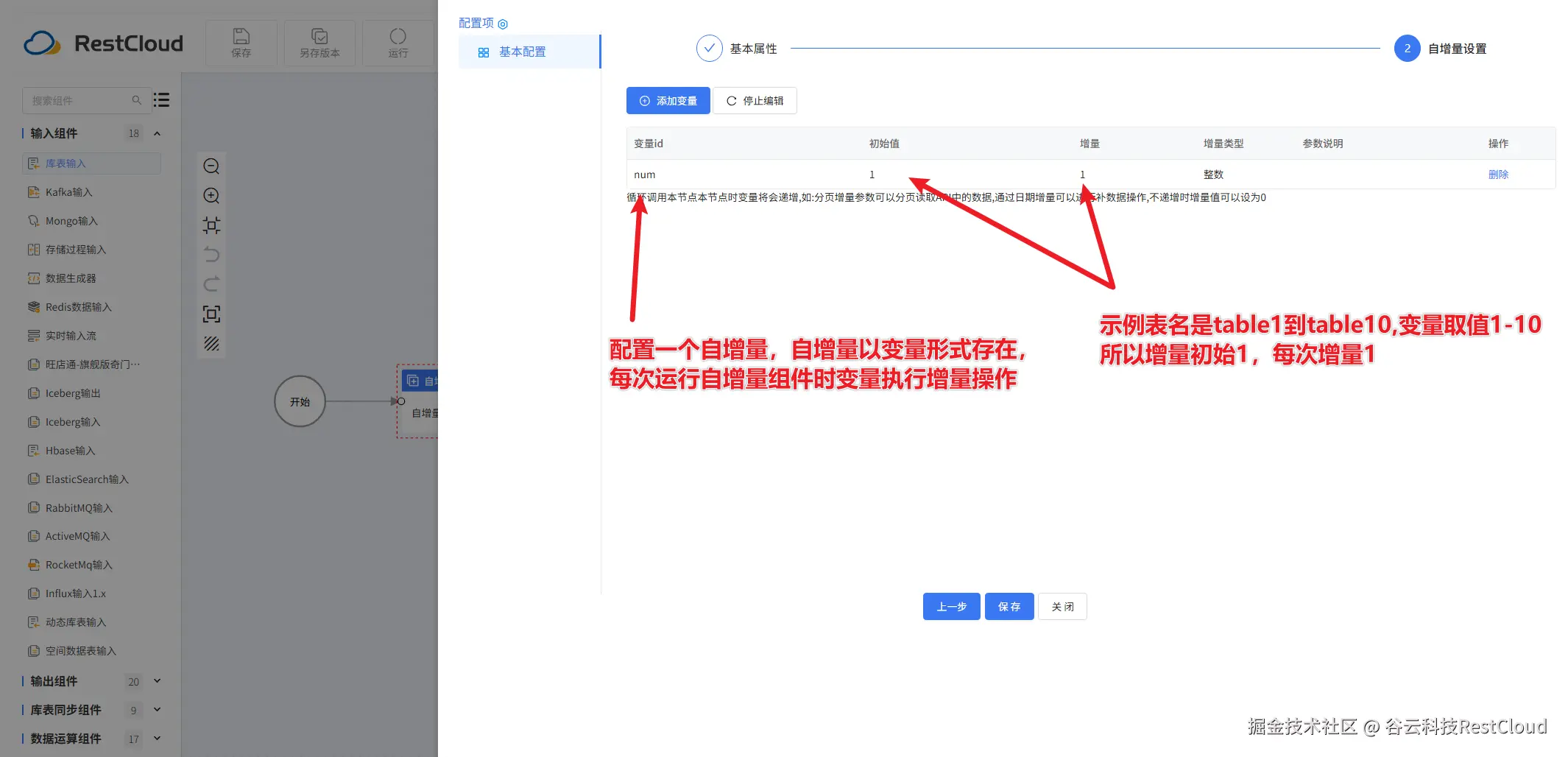
变量组件配置:
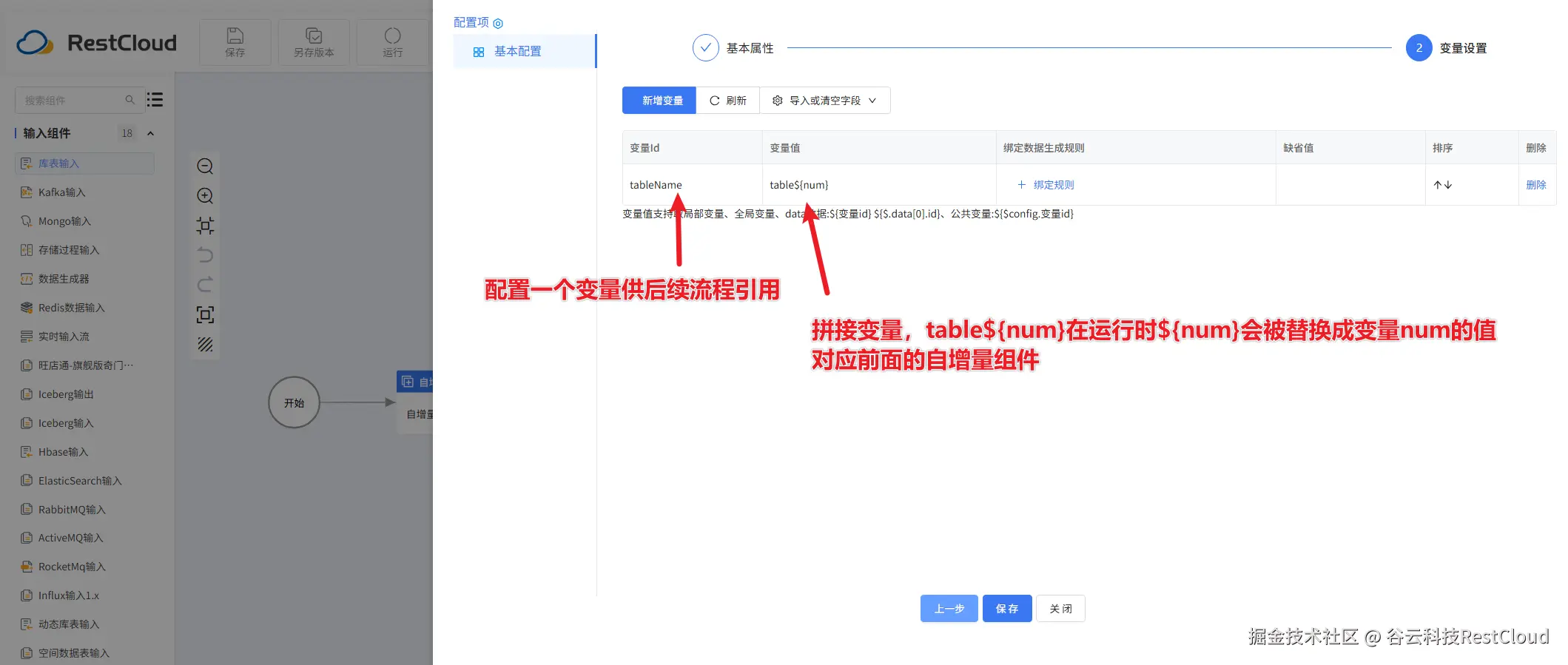
动态库表输入组件配置:
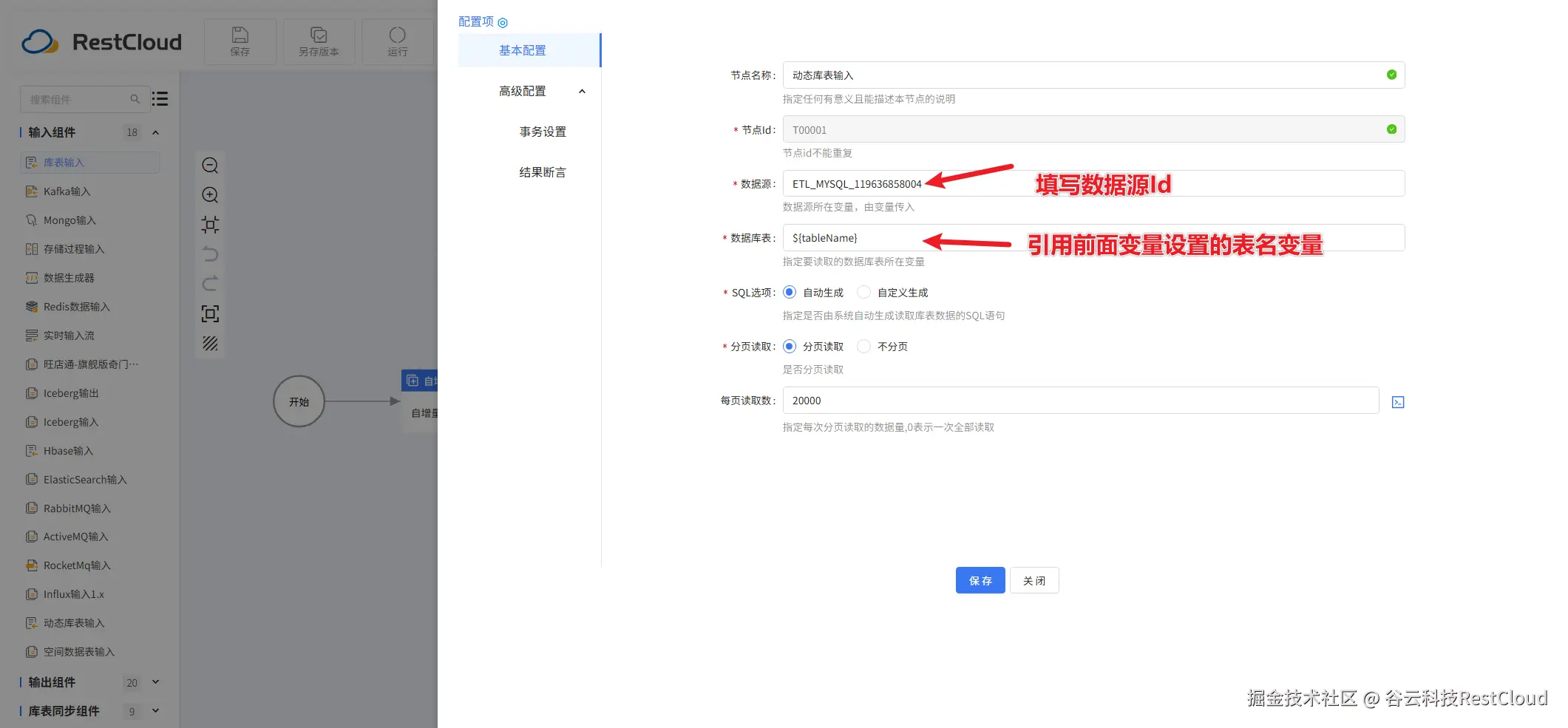
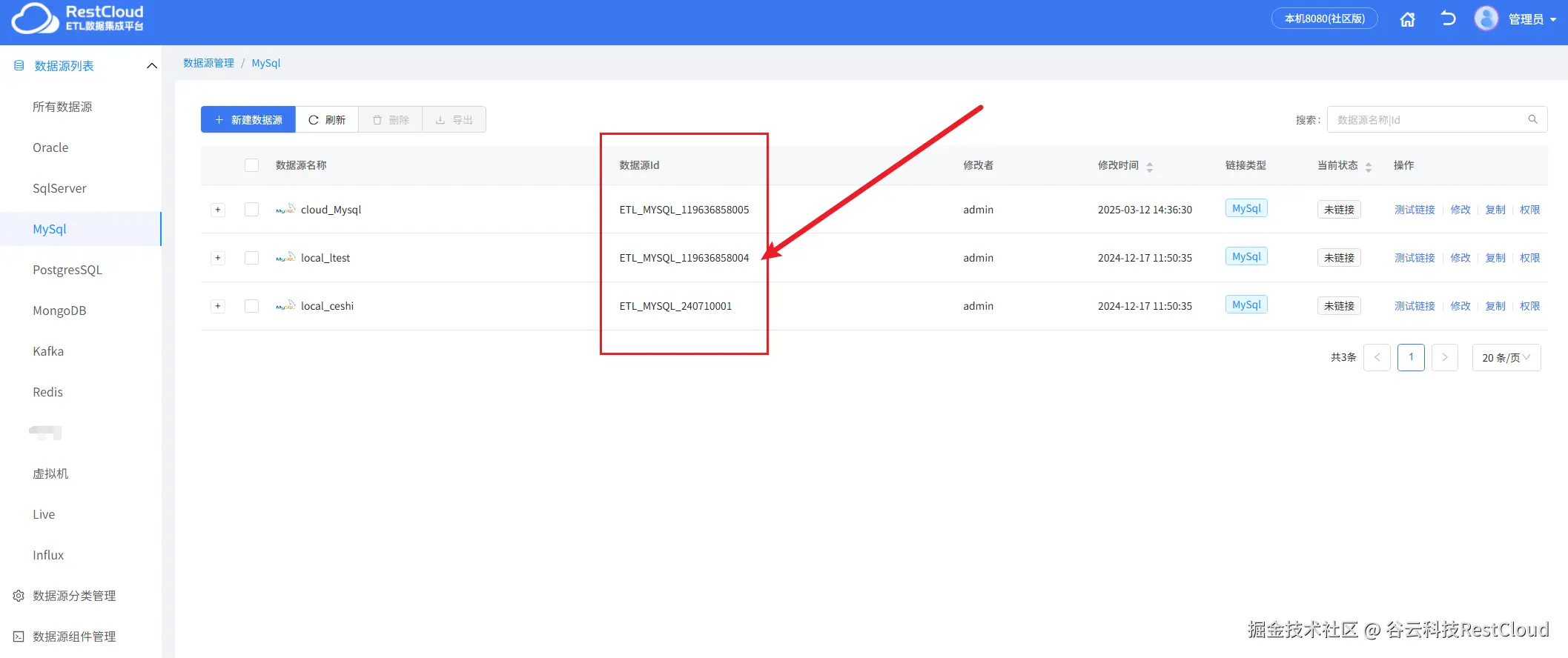
数据源这里填写平台配置的数据源链接的数据源Id.
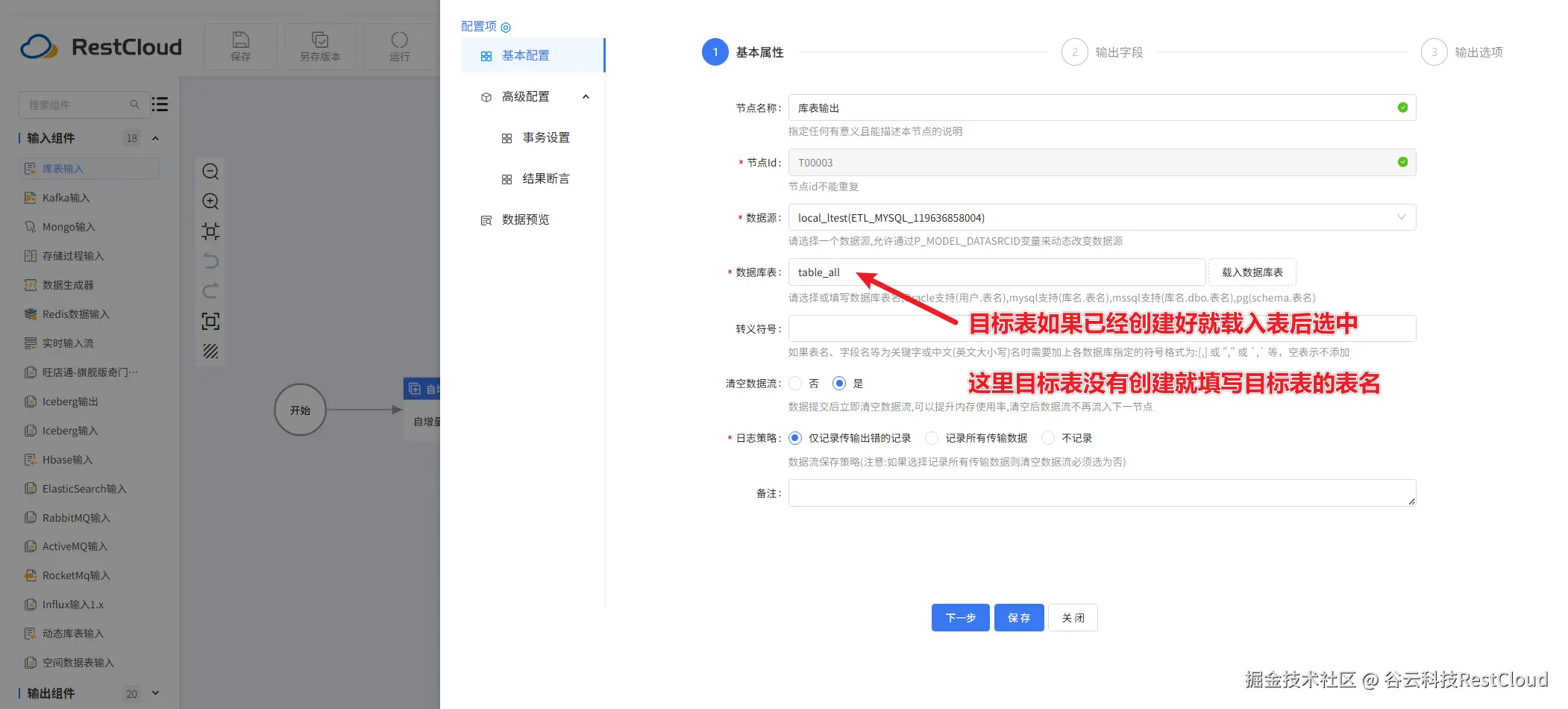
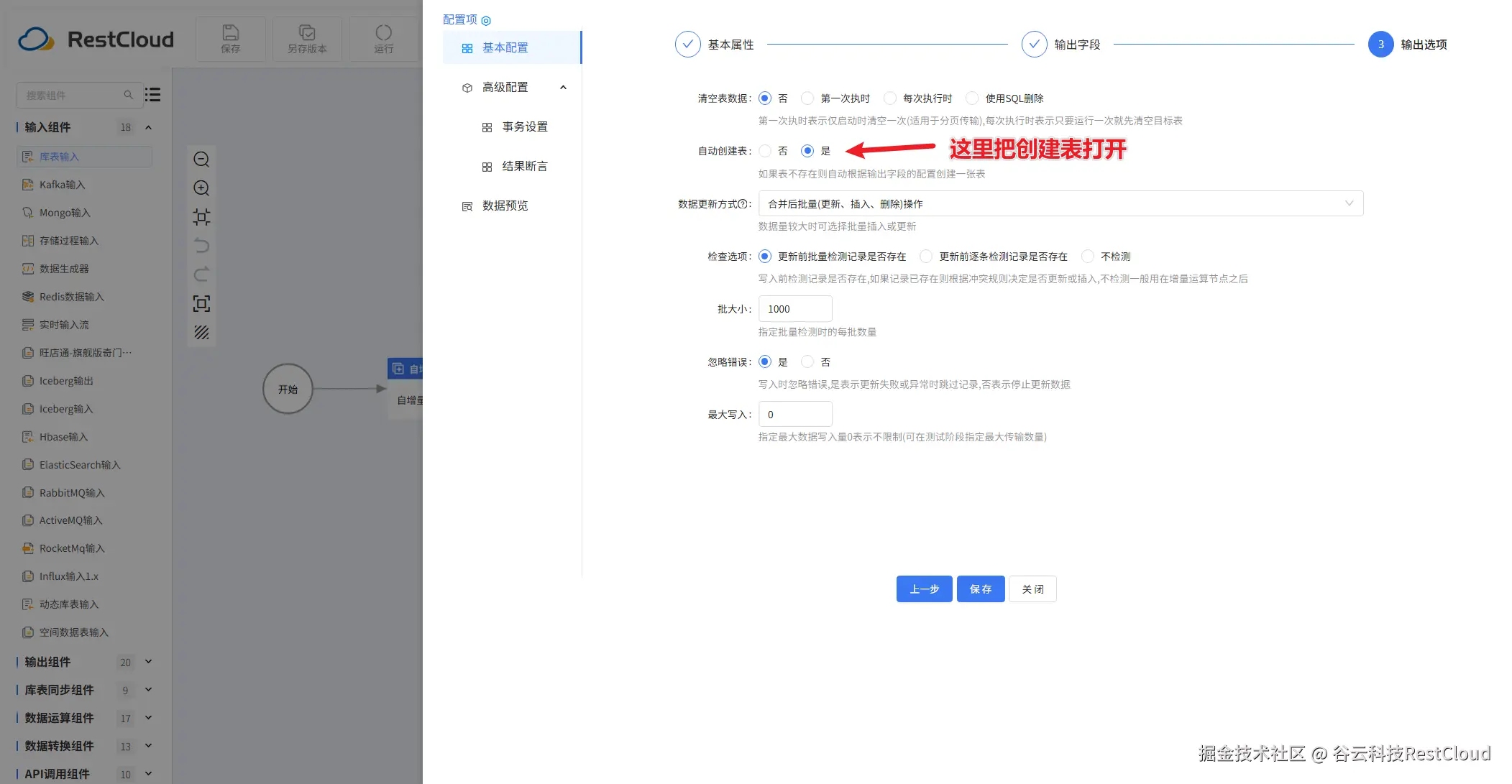
库表输出:
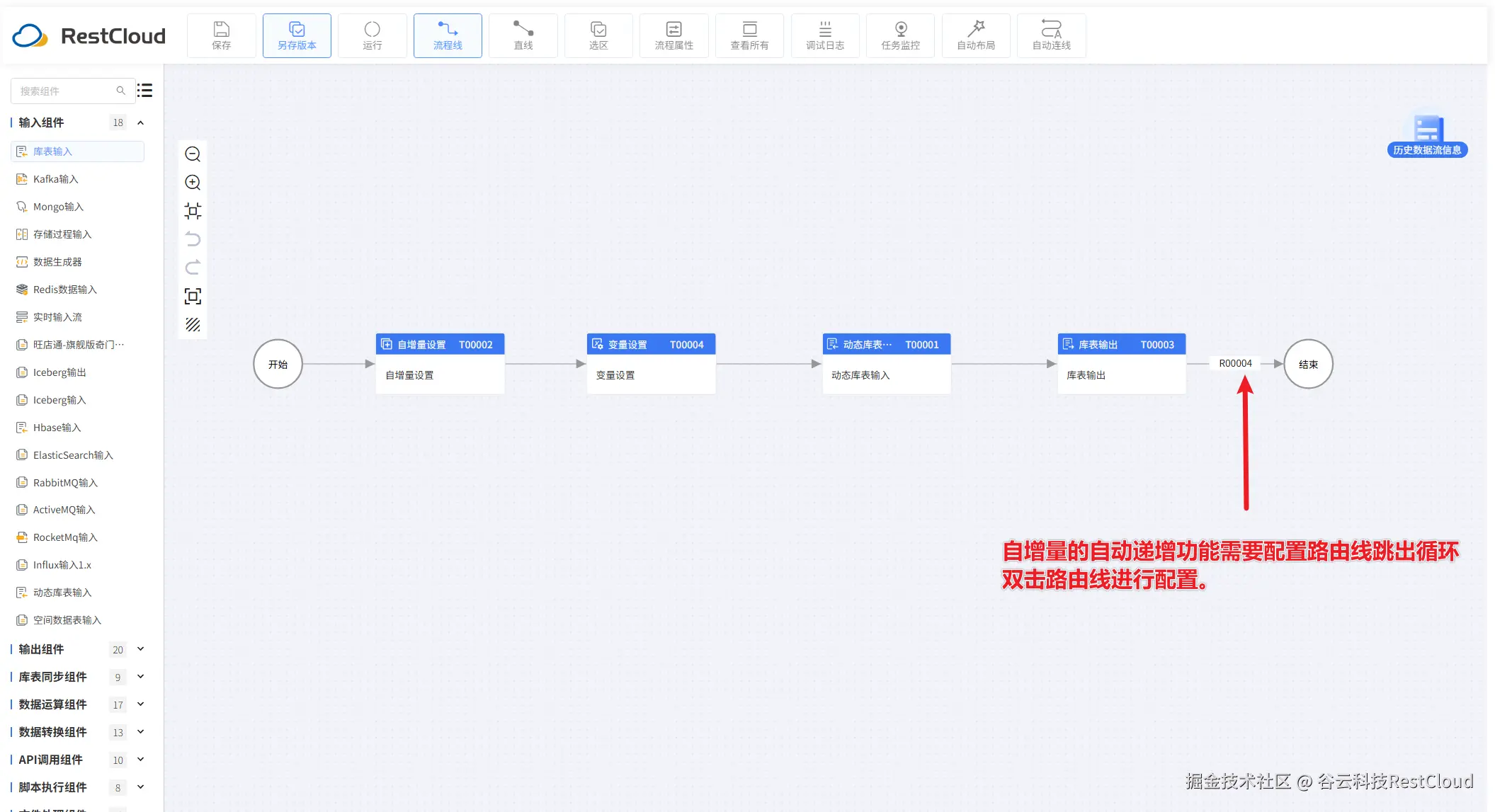
运行流程:
流程正常运行。
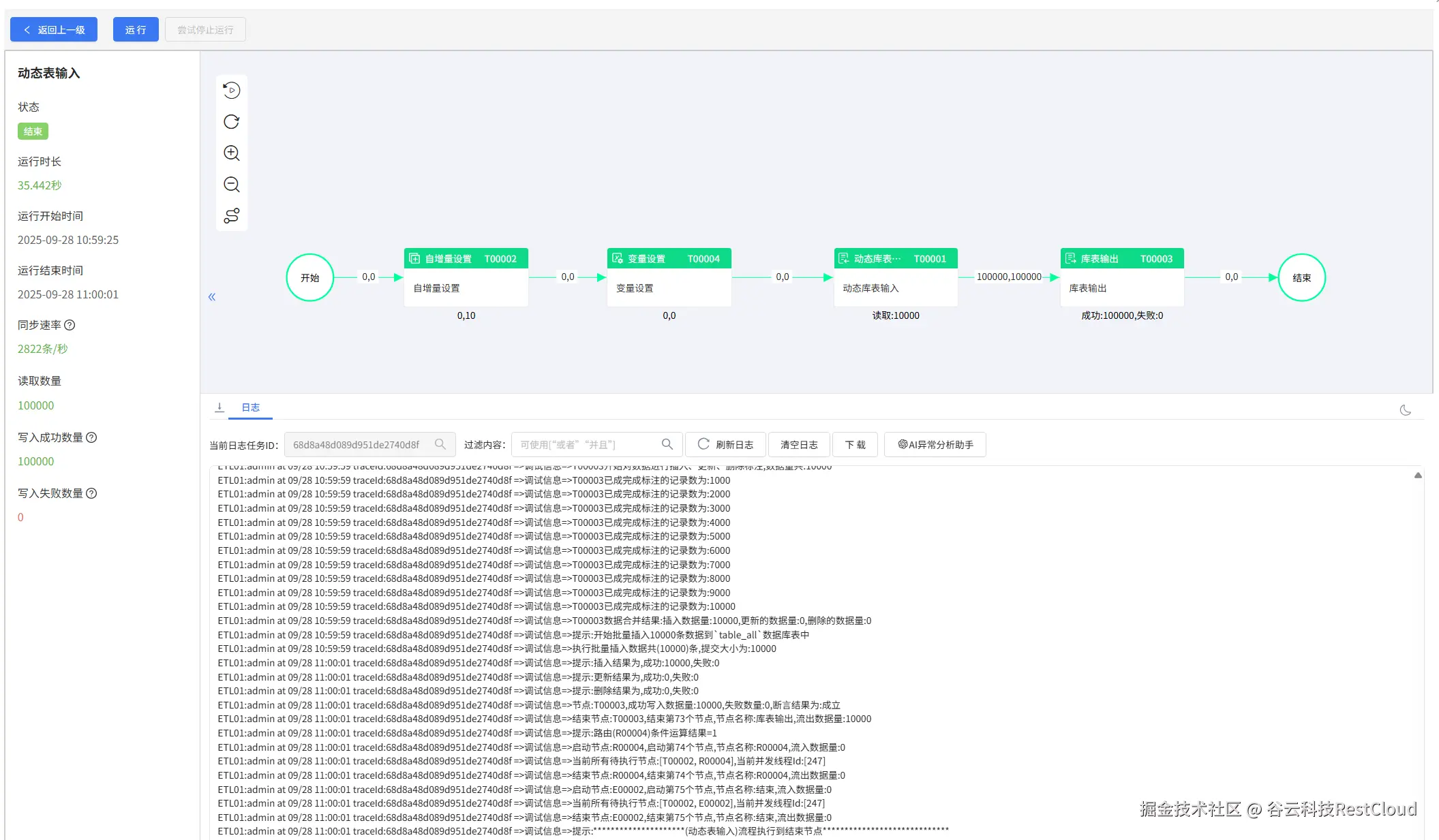
检查目标表:
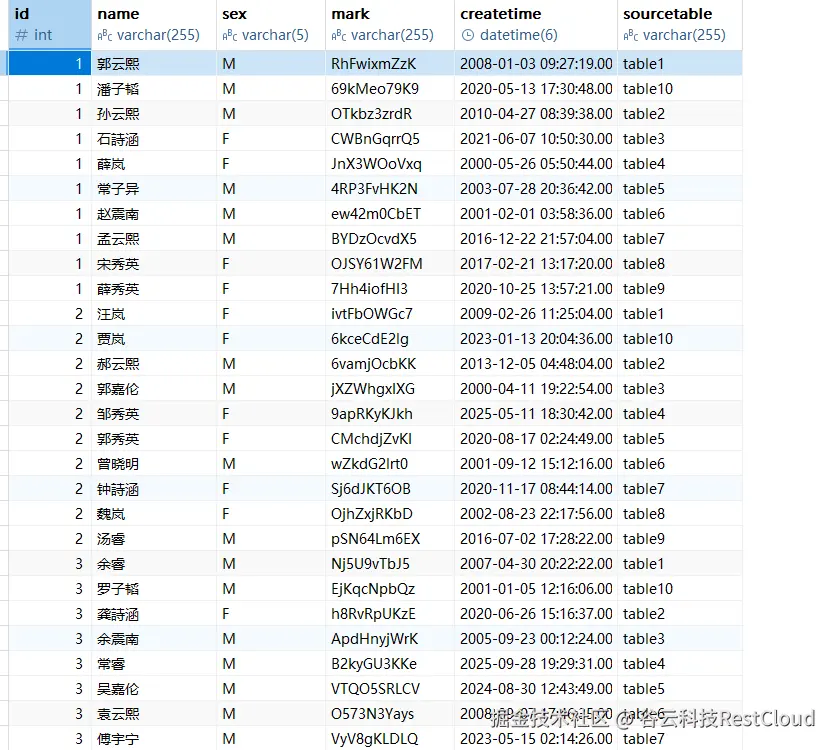
数据正常整合过来。
二、动态输出表
数据库服务器压力大的情况下经常有分库分表的场景,有一张大表,需要根据某个维度比如年份去进行表拆分,通常的方式也是根据年份去拉取数据,然后拉取库表输出去输出一个子表,而这种情况下维度越大子表就越多,比如1990到2020要拆31个表,这种情况我们就可以使用动态库表输出去简化流程。
要将一张表按年份去拆分成多个表我们可以设置这样一个流程:
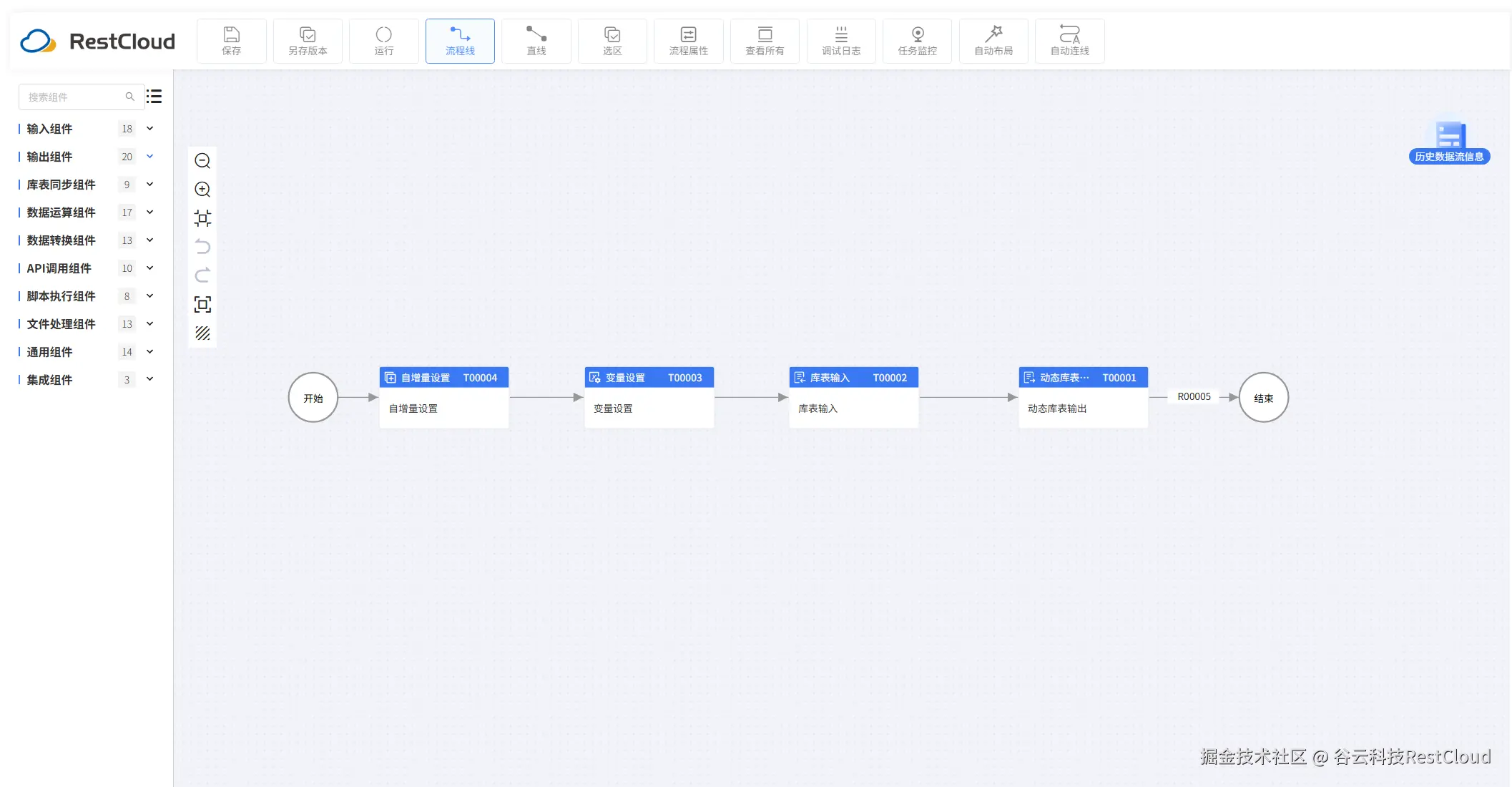
自增量组件配置:
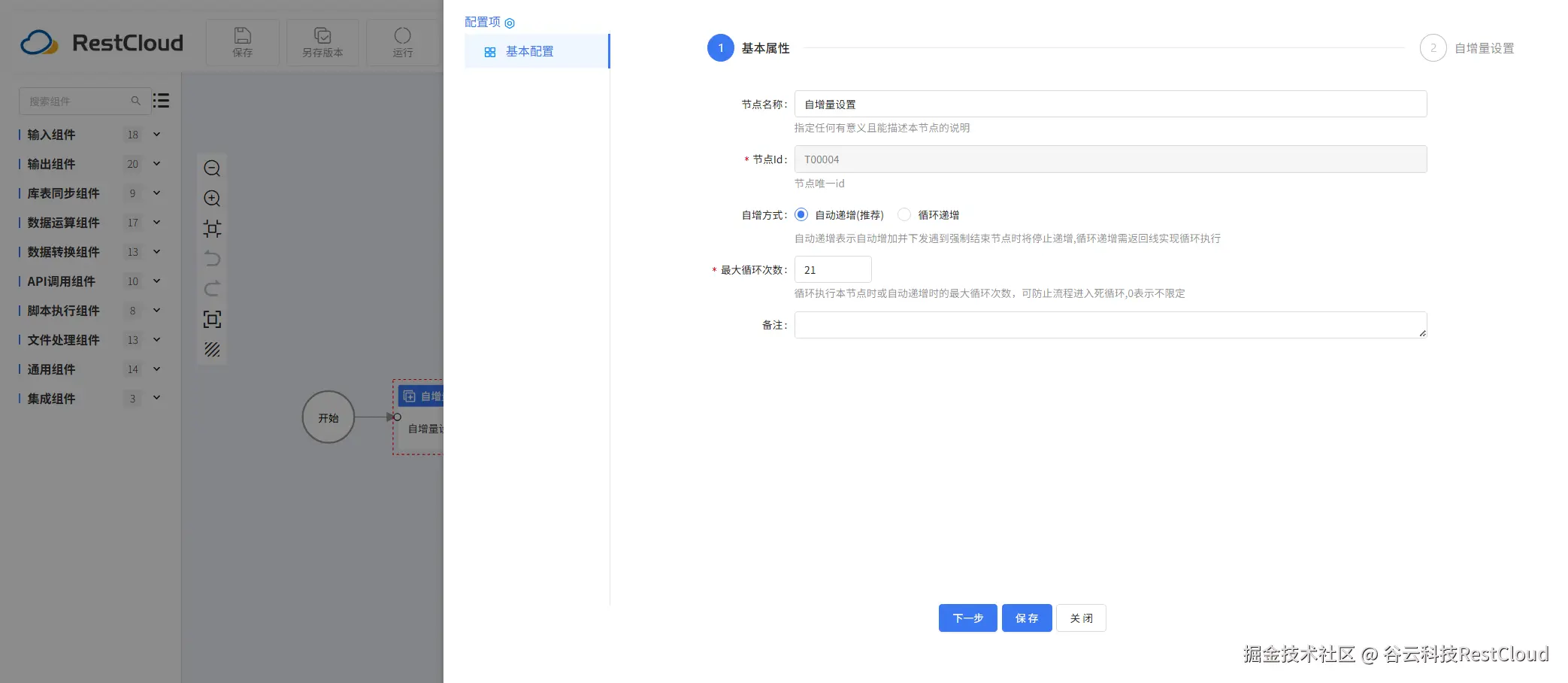
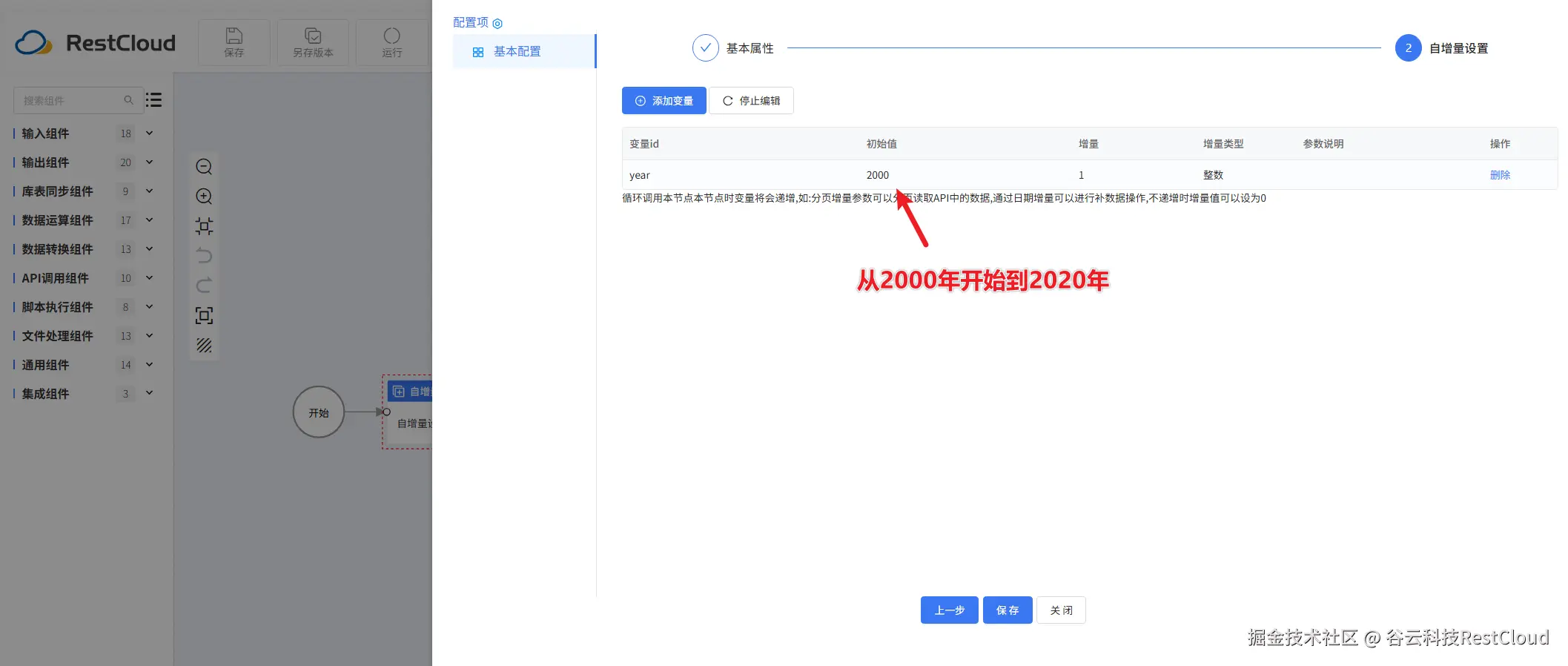
接下来先配置库表输入:
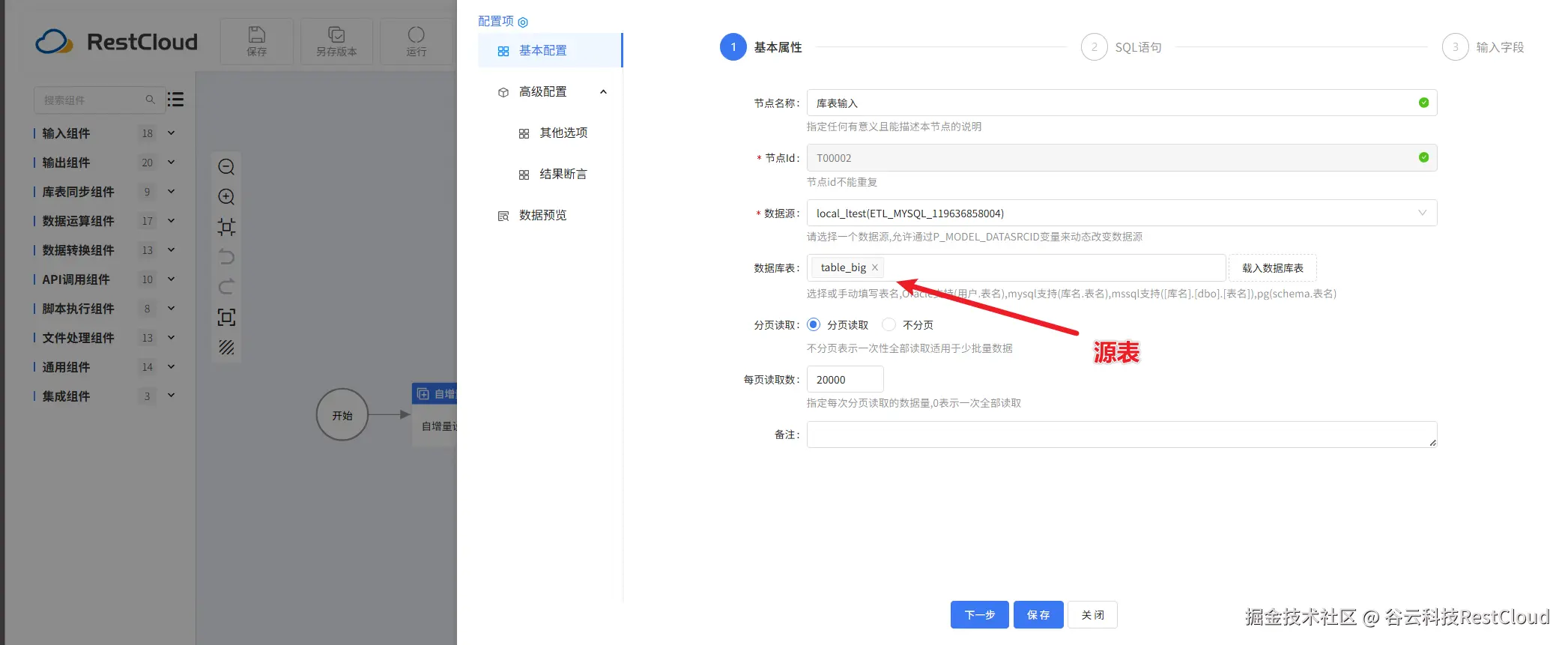
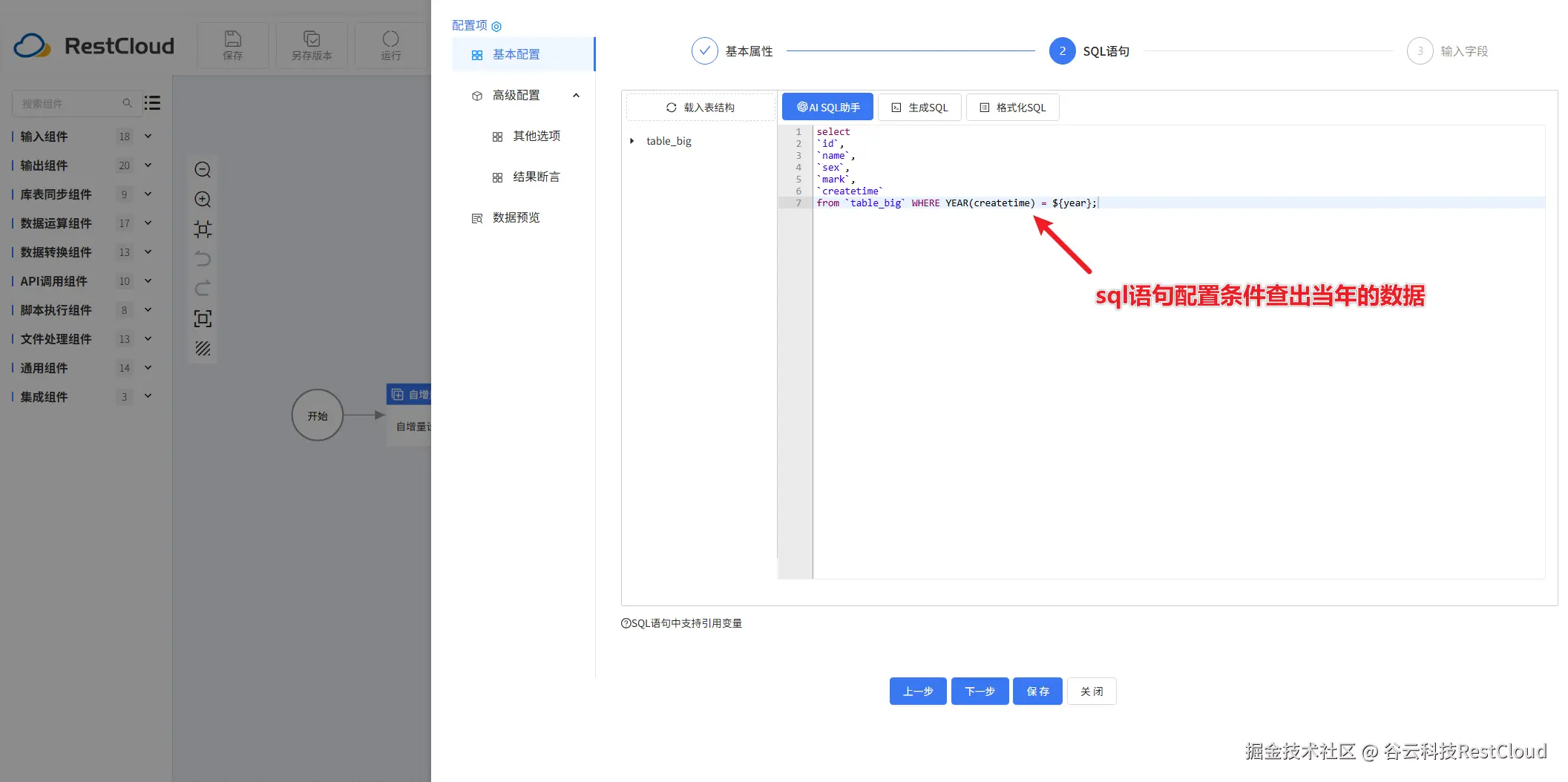
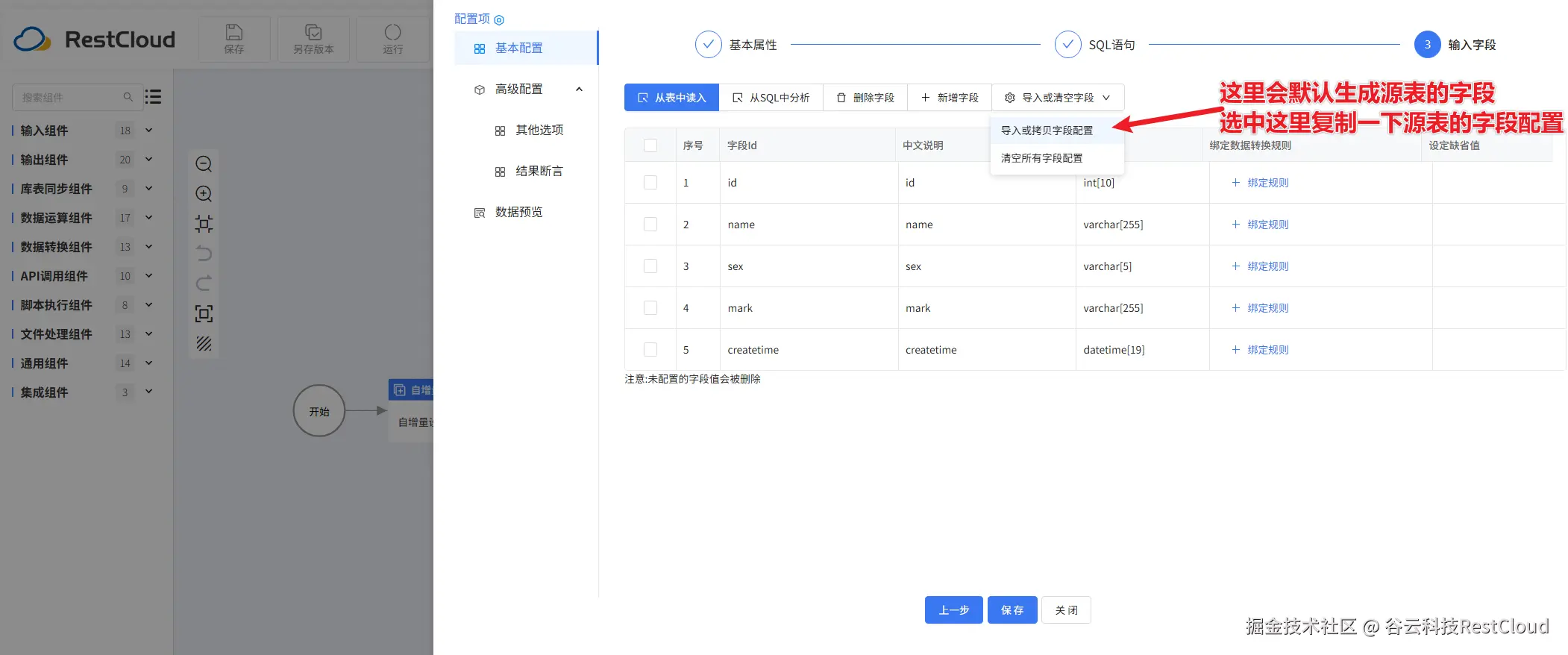
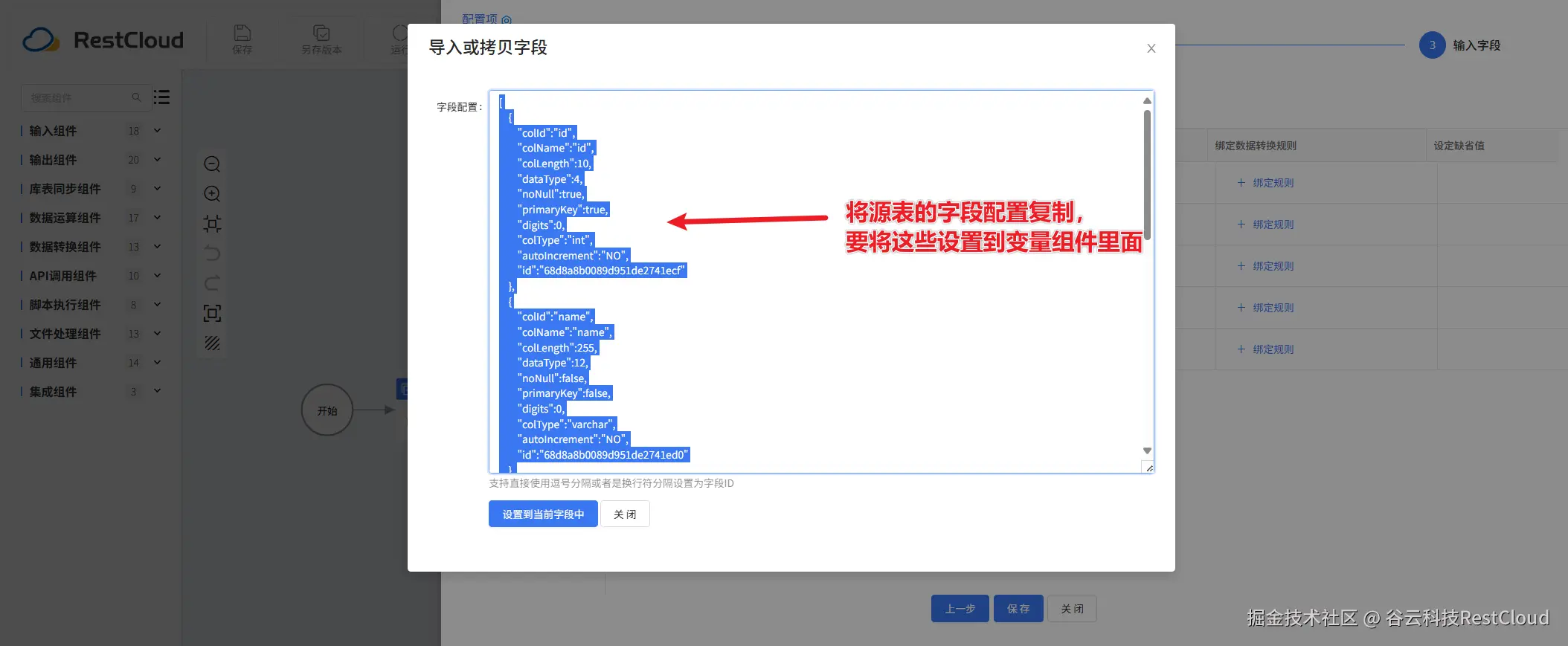
变量组件配置:
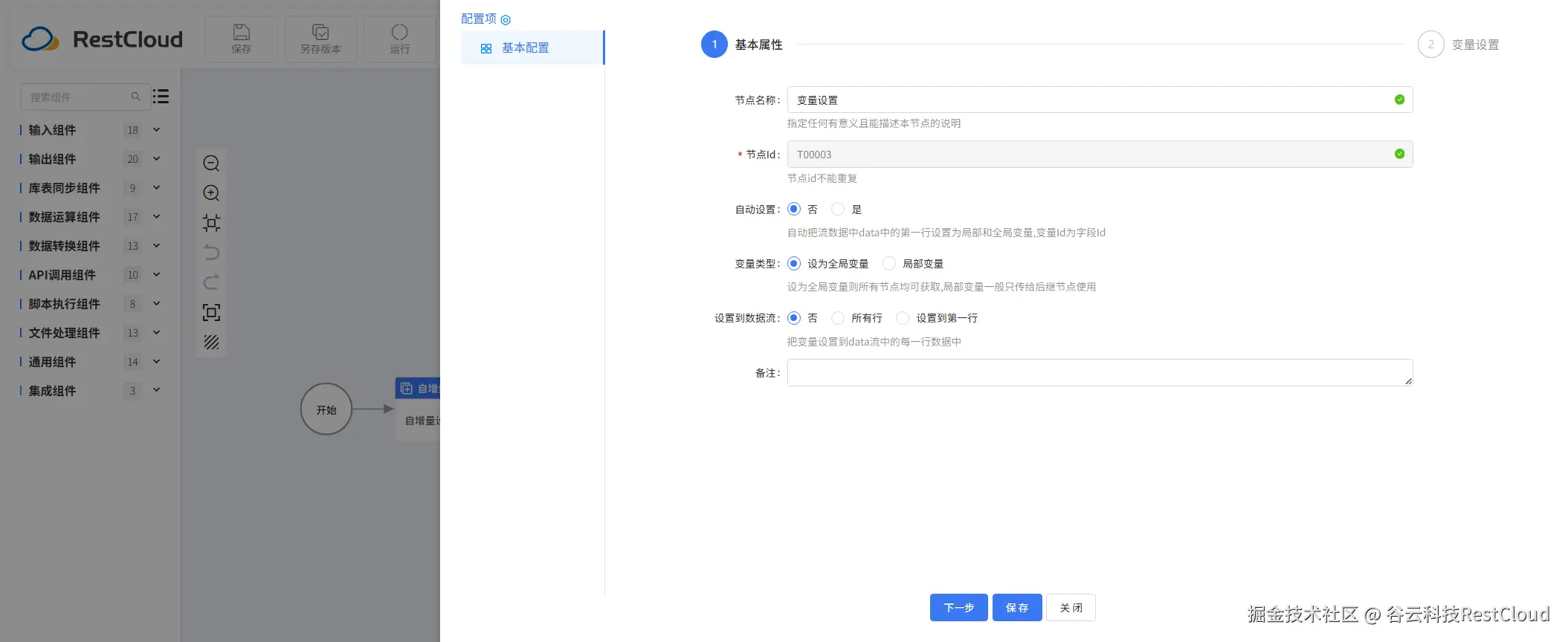
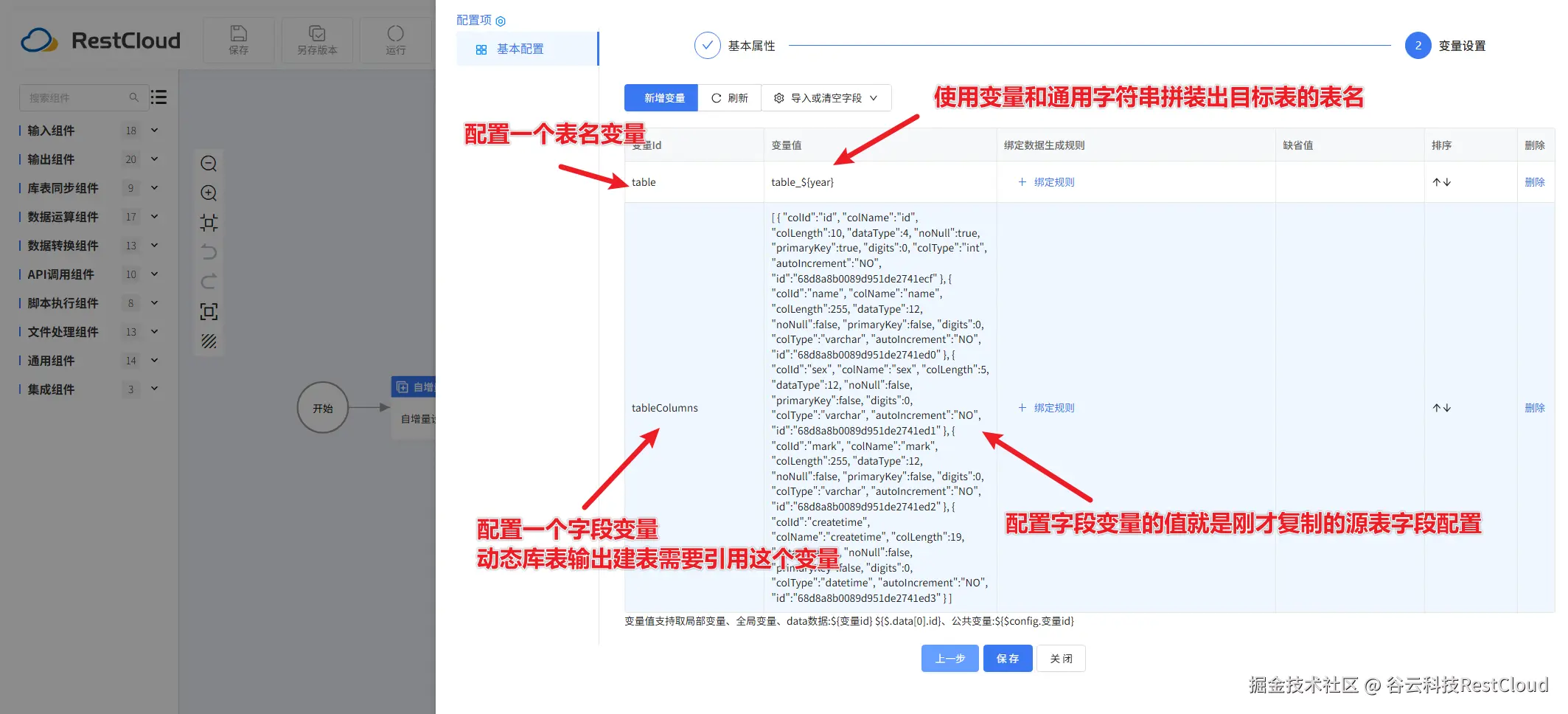
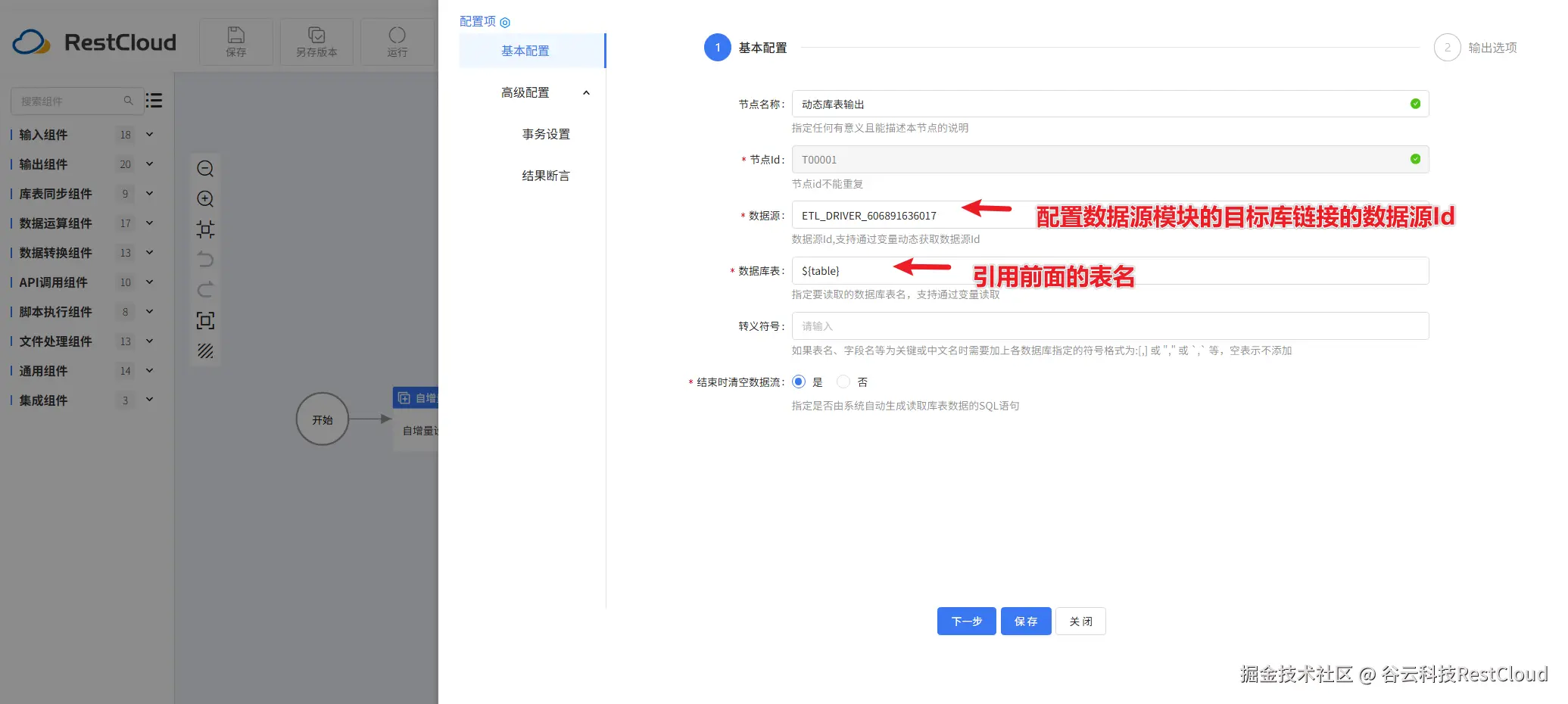
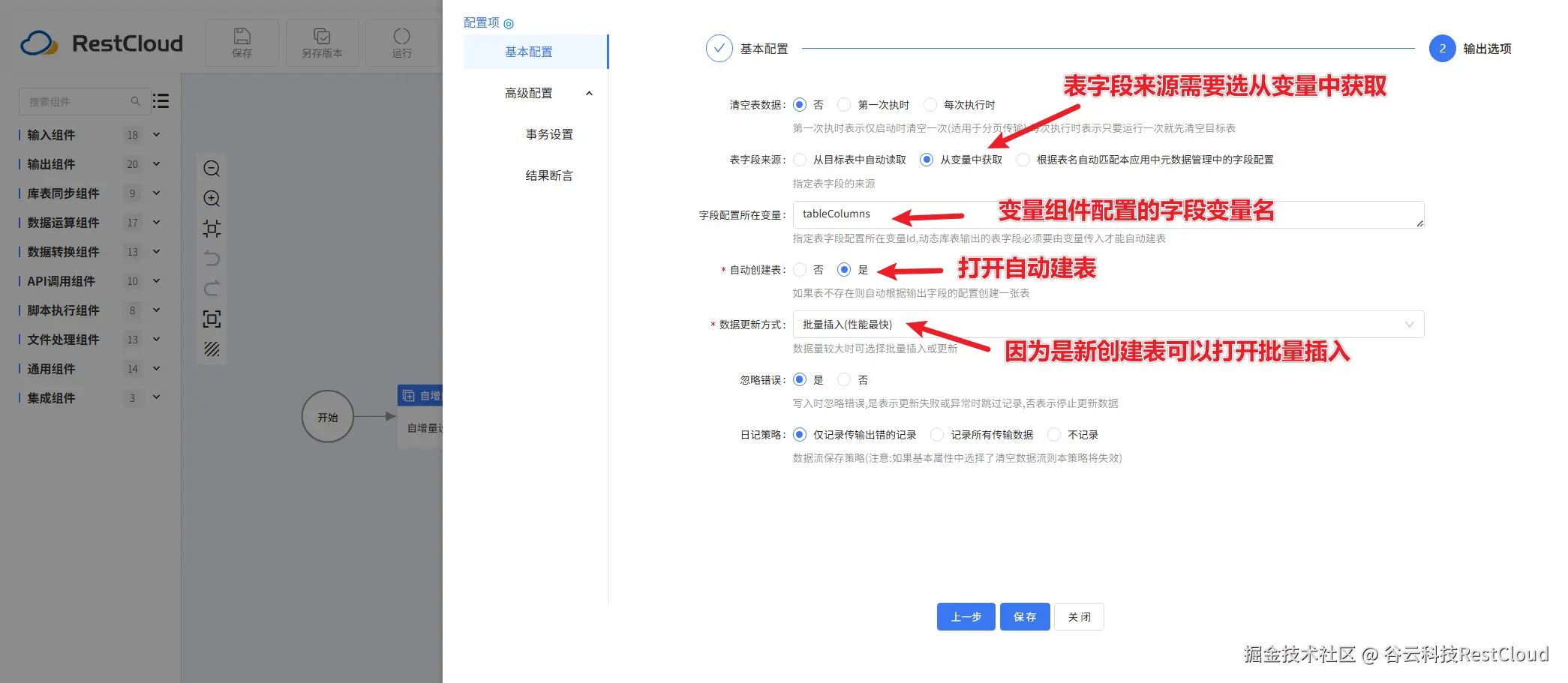
运行流程:
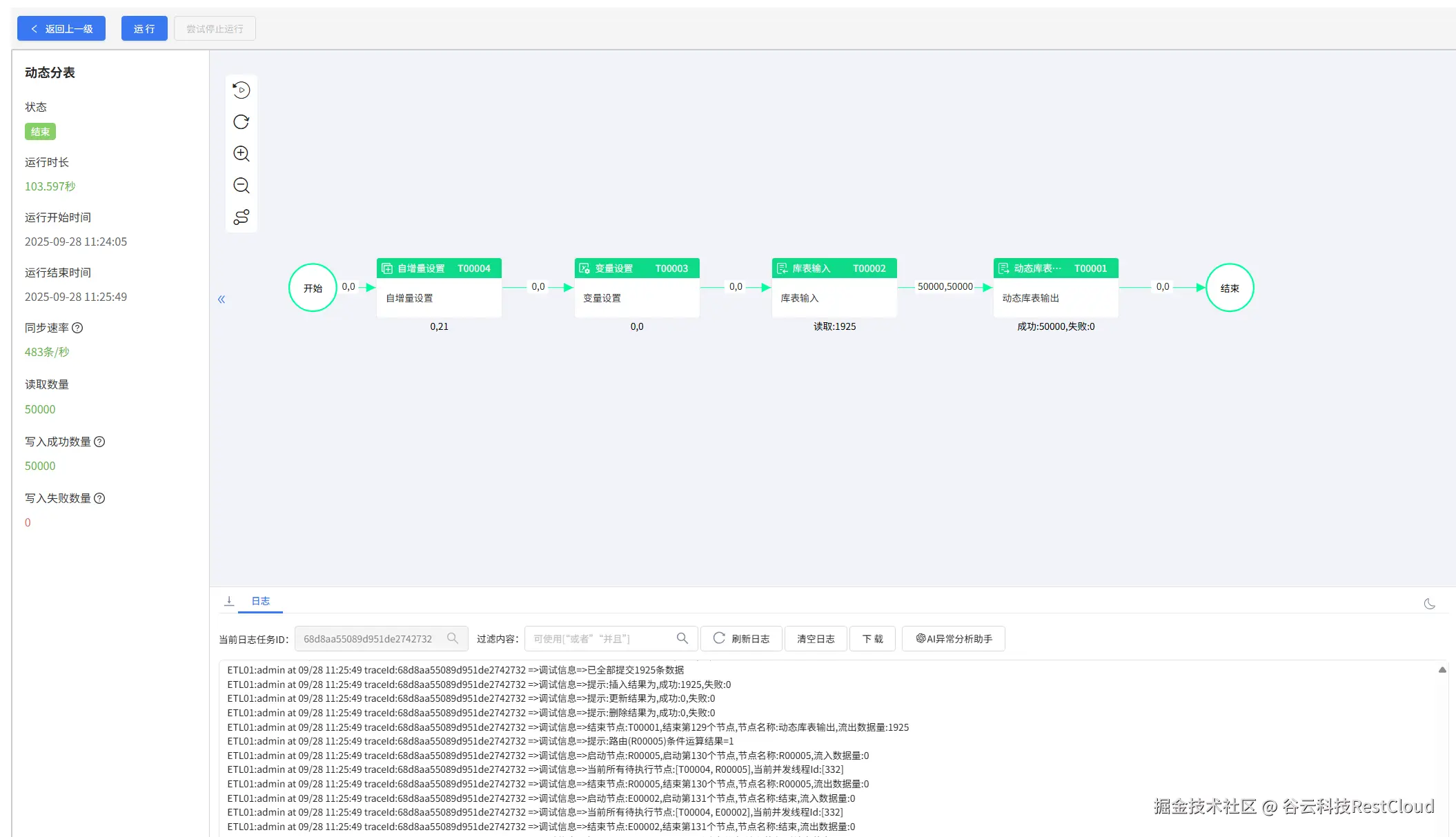
自动建表成功:
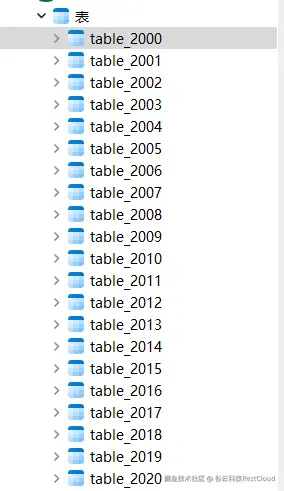
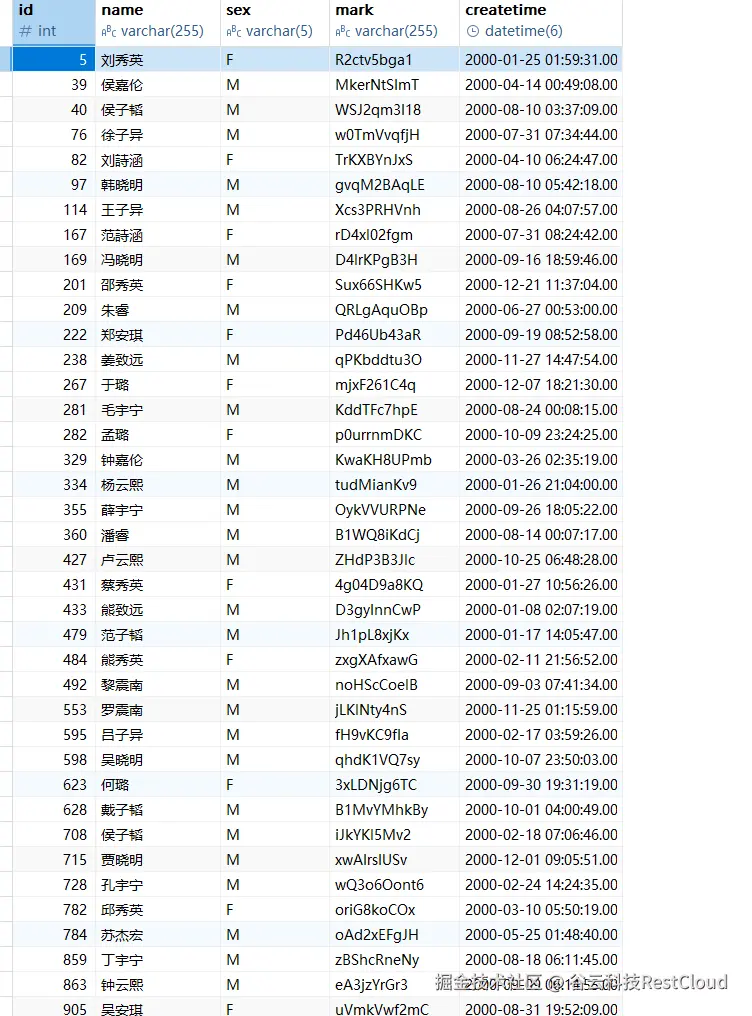
检查每张目标表的数据没有问题
三、最后
本文介绍了两种ETL参数化技巧,核心在于利用自增量组件生成序列,通过变量组件动态拼接表名,最终由动态库表输入/输出组件执行批量操作:
动态读表:将多张规律命名的源表合并到一张目标表,避免为每张源表重复配置输入组件。
动态写表:将一张大表按维度拆分成多张子表,避免为每张目标表重复配置输出组件。
这种方法显著减少了ETL任务的组件数量,提升了配置效率与可维护性,特别适用于处理规律性强的批量化表操作。