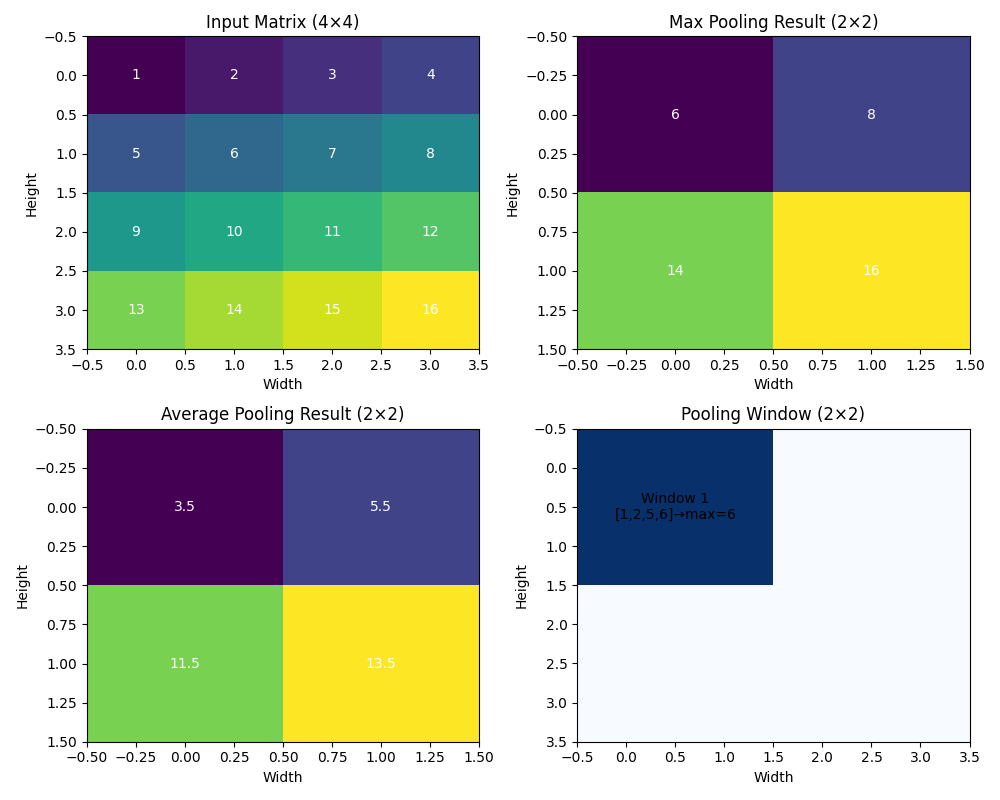
池化(Pooling)是深度学习中的一种重要操作,主要用于降低特征图的空间维度 (高度和宽度),同时保留最重要的特征信息。池化操作通过减少参数数量和计算量来防止过拟合,并提高模型的平移不变性。
与卷积层不同,池化层没有可学习的参数,只有超参数如核大小、步长和填充。
池化操作通常应用于卷积神经网络(CNN)中,跟在卷积层之后,用于逐步减少空间分辨率,同时增加通道深度。常见的池化类型包括最大池化(Max Pooling) 和平均池化(Average Pooling)。
一、池化介绍
1.1 结构
池化层的结构相对简单,主要由以下几个组件构成:
池化窗口(Pooling Window)
- 功能:在输入特征图上滑动的固定大小窗口
- 形状:通常为正方形(如2×2、3×3)或矩形
- 移动方式:按照指定的步长在特征图上滑动
池化操作类型
-
最大池化(Max Pooling)
- 从窗口区域内选择最大值作为输出
- 保留最显著的特征,如边缘、角点等
-
平均池化(Average Pooling)
- 计算窗口区域内所有值的平均值作为输出
- 提供更平滑的特征表示
-
全局池化(Global Pooling)
- 对整个特征图进行池化,每个通道输出一个值
- 常用于分类任务的最后一层
1.2 参数
- kernel_size:池化窗口的大小,类型为整数或元组(如2或(2,2)),默认值通常为2,决定每次池化操作覆盖的区域大小。
- stride:池化窗口的移动步长,类型为整数或元组,默认值通常等于kernel_size(非重叠池化),控制输出特征图的尺寸缩减程度。
- padding:输入边界填充,类型为整数、元组或字符串('valid'、'same'),默认值为0('valid',无填充),控制输出特征图的尺寸。
- dilation:池化窗口元素间距,类型为整数或元组,默认值为1(连续窗口),用于创建稀疏的池化窗口。
1.3 输入输出维度
- 输入数据维度 :
池化层的输入通常来自卷积层的输出,形状为:
(batch_size, channels, height, width) - 输出数据维度 :
(batch_size, channels, new_height, new_width)
重要特性 :池化操作是逐通道独立进行的,因此输出通道数与输入通道数保持不变。
输出尺寸计算公式
通用公式 :
Hout=⌊Hin+2×paddingh−dilationh×(kernel_sizeh−1)−1strideh+1⌋H_{out} = \left\lfloor \frac{H_{in} + 2 \times \text{padding}_h - \text{dilation}_h \times (\text{kernel\_size}_h - 1) - 1}{\text{stride}_h} + 1 \right\rfloorHout=⌊stridehHin+2×paddingh−dilationh×(kernel_sizeh−1)−1+1⌋
Wout=⌊Win+2×paddingw−dilationw×(kernel_sizew−1)−1stridew+1⌋W_{out} = \left\lfloor \frac{W_{in} + 2 \times \text{padding}_w - \text{dilation}_w \times (\text{kernel\_size}_w - 1) - 1}{\text{stride}_w} + 1 \right\rfloorWout=⌊stridewWin+2×paddingw−dilationw×(kernel_sizew−1)−1+1⌋
常见情况:
-
标准池化 (kernel_size=2, stride=2, padding=0):
Hout=⌊Hin2⌋H_{out} = \left\lfloor \frac{H_{in}}{2} \right\rfloorHout=⌊2Hin⌋
Wout=⌊Win2⌋W_{out} = \left\lfloor \frac{W_{in}}{2} \right\rfloorWout=⌊2Win⌋ -
重叠池化 (kernel_size=3, stride=2, padding=1):
Hout=⌊Hin+2−22⌋=⌊Hin2⌋H_{out} = \left\lfloor \frac{H_{in} + 2 - 2}{2} \right\rfloor = \left\lfloor \frac{H_{in}}{2} \right\rfloorHout=⌊2Hin+2−2⌋=⌊2Hin⌋
Wout=⌊Win2⌋W_{out} = \left\lfloor \frac{W_{in}}{2} \right\rfloorWout=⌊2Win⌋ -
保持尺寸池化 (padding='same', stride=1):
Hout=HinH_{out} = H_{in}Hout=Hin
Wout=WinW_{out} = W_{in}Wout=Win
python
import torch
import torch.nn as nn
# 输入数据:批次大小=4, 通道数=32, 高=28, 宽=28
input_tensor = torch.randn(4, 32, 28, 28)
# 最大池化:2×2窗口,步长2
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
output = max_pool(input_tensor)
print(f"输入形状: {input_tensor.shape}") # torch.Size([4, 32, 28, 28])
print(f"输出形状: {output.shape}") # torch.Size([4, 32, 14, 14])
# 平均池化:3×3窗口,步长1,填充1(保持尺寸)
avg_pool = nn.AvgPool2d(kernel_size=3, stride=1, padding=1)
output_same = avg_pool(input_tensor)
print(f"保持尺寸输出: {output_same.shape}") # torch.Size([4, 32, 28, 28])
python
输入形状: torch.Size([4, 32, 28, 28])
输出形状: torch.Size([4, 32, 14, 14])
保持尺寸输出: torch.Size([4, 32, 28, 28])1.4 计算过程
最大池化计算过程
数学表达式 :
Output(i,j,c)=maxm=0kh−1maxn=0kw−1Input(i×sh+m,j×sw+n,c)\text{Output}(i, j, c) = \max_{m=0}^{k_h-1} \max_{n=0}^{k_w-1} \text{Input}(i \times s_h + m, j \times s_w + n, c)Output(i,j,c)=m=0maxkh−1n=0maxkw−1Input(i×sh+m,j×sw+n,c)
具体步骤:
- 窗口滑动:池化窗口在输入特征图上按指定步长滑动
- 区域选择:对于每个窗口位置,选择对应的输入区域
- 最大值计算:在窗口区域内找到最大值
- 输出赋值:将最大值赋给输出特征图的对应位置
平均池化计算过程
数学表达式 :
Output(i,j,c)=1kh×kw∑m=0kh−1∑n=0kw−1Input(i×sh+m,j×sw+n,c)\text{Output}(i, j, c) = \frac{1}{k_h \times k_w} \sum_{m=0}^{k_h-1} \sum_{n=0}^{k_w-1} \text{Input}(i \times s_h + m, j \times s_w + n, c)Output(i,j,c)=kh×kw1m=0∑kh−1n=0∑kw−1Input(i×sh+m,j×sw+n,c)
具体步骤:
- 窗口滑动:与最大池化相同
- 区域选择:选择对应的输入区域
- 平均值计算:计算窗口区域内所有值的平均值
- 输出赋值 :将平均值赋给输出特征图的对应位置
二、代码示例
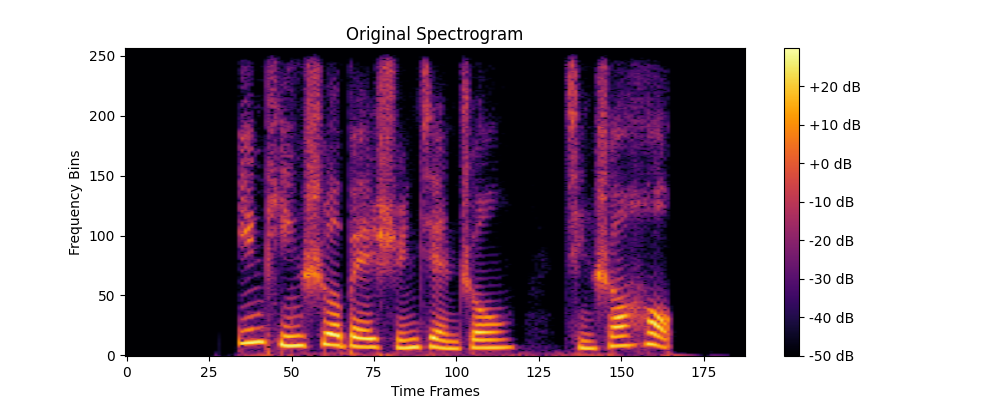
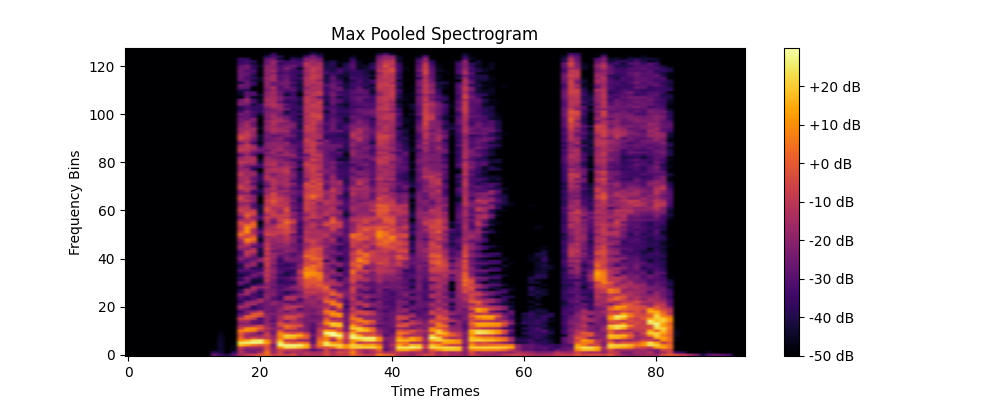
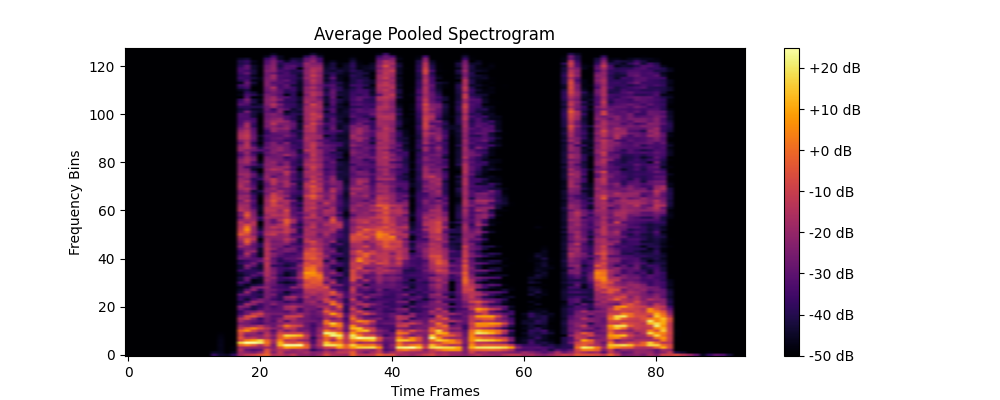
通过池化处理一段音频频谱,打印每层的输出形状、参数形状,并可视化特征图。
python
import torch
import matplotlib.pyplot as plt
import librosa
import numpy as np
# 1. 读取音频文件并处理
file_path = 'test.wav'
waveform, sample_rate = librosa.load(file_path, sr=16000, mono=True)
# 选取 3 秒的数据
start_sample = int(1.5 * sample_rate)
end_sample = int(4.5 * sample_rate)
audio_segment = waveform[start_sample:end_sample]
# 2. 转换为频谱
n_fft = 512
hop_length = 256
spectrogram = librosa.stft(audio_segment, n_fft=n_fft, hop_length=hop_length)
spectrogram_db = librosa.amplitude_to_db(np.abs(spectrogram))
# 将频谱转换为 PyTorch 张量并调整形状
spectrogram_tensor = torch.tensor(spectrogram_db, dtype=torch.float32).unsqueeze(0).unsqueeze(
0) # (1, 1, height, width)
# 打印原始频谱的维度
print(f"Original spectrogram shape: {spectrogram_tensor.shape}")
# 3. 应用最大池化
max_pool = torch.nn.MaxPool2d(kernel_size=(2, 2), stride=2)
max_pooled_output = max_pool(spectrogram_tensor)
# 打印最大池化后的输出形状
print(f"Output shape after Max Pooling: {max_pooled_output.shape}")
# 4. 应用平均池化
avg_pool = torch.nn.AvgPool2d(kernel_size=(2, 2), stride=2)
avg_pooled_output = avg_pool(spectrogram_tensor)
# 打印平均池化后的输出形状
print(f"Output shape after Average Pooling: {avg_pooled_output.shape}")
# 5. 可视化原始频谱
plt.figure(figsize=(10, 4))
plt.imshow(spectrogram_db, aspect='auto', origin='lower', cmap='inferno')
plt.title("Original Spectrogram")
plt.xlabel("Time Frames")
plt.ylabel("Frequency Bins")
plt.colorbar(format='%+2.0f dB')
# 6. 可视化最大池化后的特征图
plt.figure(figsize=(10, 4))
plt.imshow(max_pooled_output[0, 0, :, :].detach().numpy(), aspect='auto', origin='lower', cmap='inferno')
plt.title("Max Pooled Spectrogram")
plt.xlabel("Time Frames")
plt.ylabel("Frequency Bins")
plt.colorbar(format='%+2.0f dB')
# 7. 可视化平均池化后的特征图
plt.figure(figsize=(10, 4))
plt.imshow(avg_pooled_output[0, 0, :, :].detach().numpy(), aspect='auto', origin='lower', cmap='inferno')
plt.title("Average Pooled Spectrogram")
plt.xlabel("Time Frames")
plt.ylabel("Frequency Bins")
plt.colorbar(format='%+2.0f dB')
plt.show()
python
Original spectrogram shape: torch.Size([1, 1, 257, 188])
Output shape after Max Pooling: torch.Size([1, 1, 128, 94])
Output shape after Average Pooling: torch.Size([1, 1, 128, 94])