10. Spring AI + RAG
@toc
RAG
检索增强生成(Retrieval-augmented Generation)
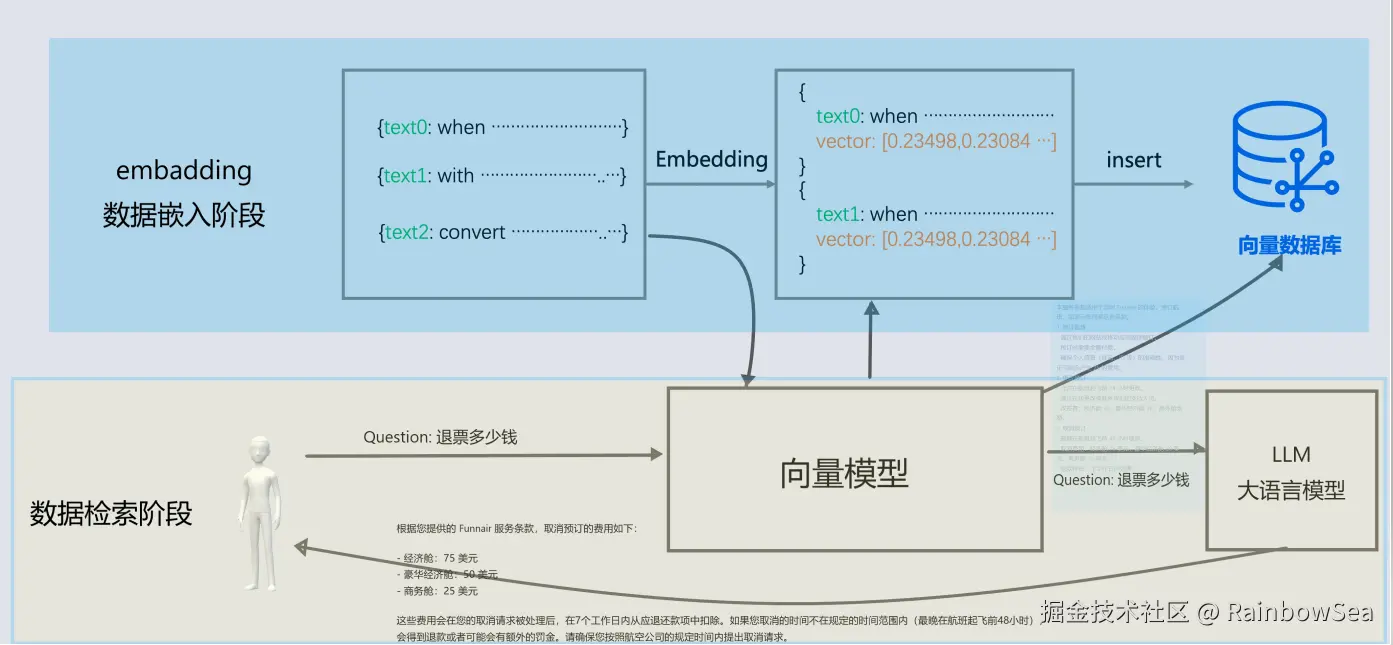
对于基础大模型来说, 他只具备通用信息,他的参数都是拿公网进行训练,并且有一定的时间延迟, 无法得知一些具体业务数据和实时数据, 这些数据往往在各种文件中(比如txt、word、html、数据库...)
虽然function-call、SystemMessage可以用来解决一部分问题
但是它只能少量,并且针对的场景不一样
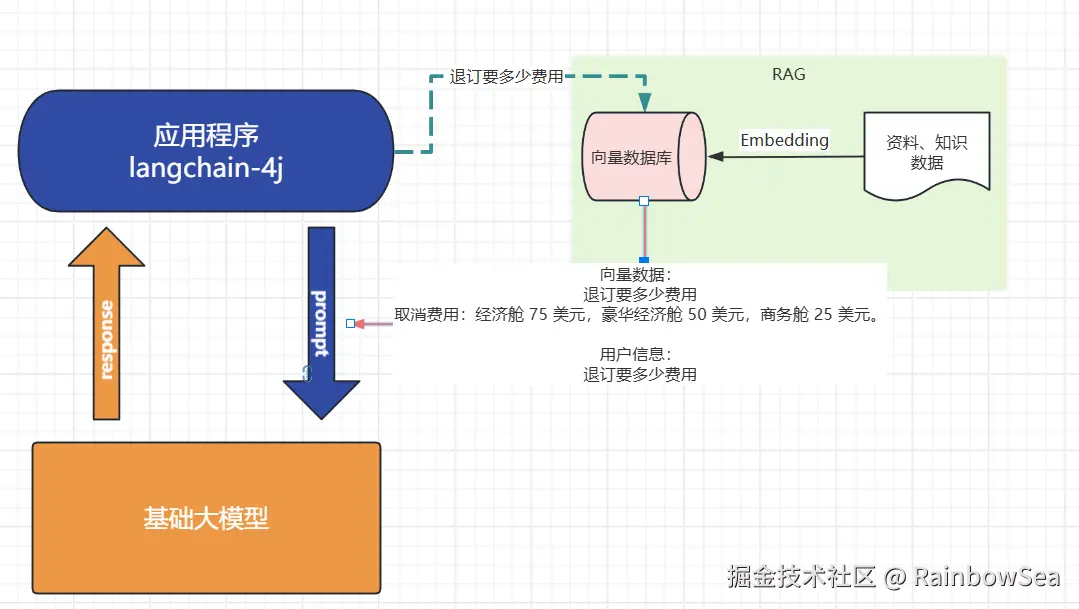
如果你要提供大量的业务领域信息, 就需要给他外接一个知识库:
比如
- 我问他退订要多少费用
- 这些资料可能都由产品或者需求编写在了文档中:
- 所以需要现在需求信息存到向量数据库(这个过程叫Embedding, 涉及到文档读取、分词、向量化存入)
- 去向量数据库中查询"退订费用相关信息"
- 将查询到的数据和对话信息再请求大模型
- 此时会响应退订需要多少费用
概念
向量:
向量通常用来做相似性搜索,比如语义的一维向量,可以表示词语或短语的语义相似性。例如,"你好"、"hello"和"见到你很高兴"可以通过一维向量来表示它们的语义接近程度。

然而,对于更复杂的对象,比如小狗,无法仅通过一个维度来进行相似性搜索。这时,我们需要提取多个特征,如颜色、大小、品种等,将每个特征表示为向量的一个维度,从而形成一个多维向量。例如,一只棕色的小型泰迪犬可以表示为一个多维向量 棕色, 小型, 泰迪犬。
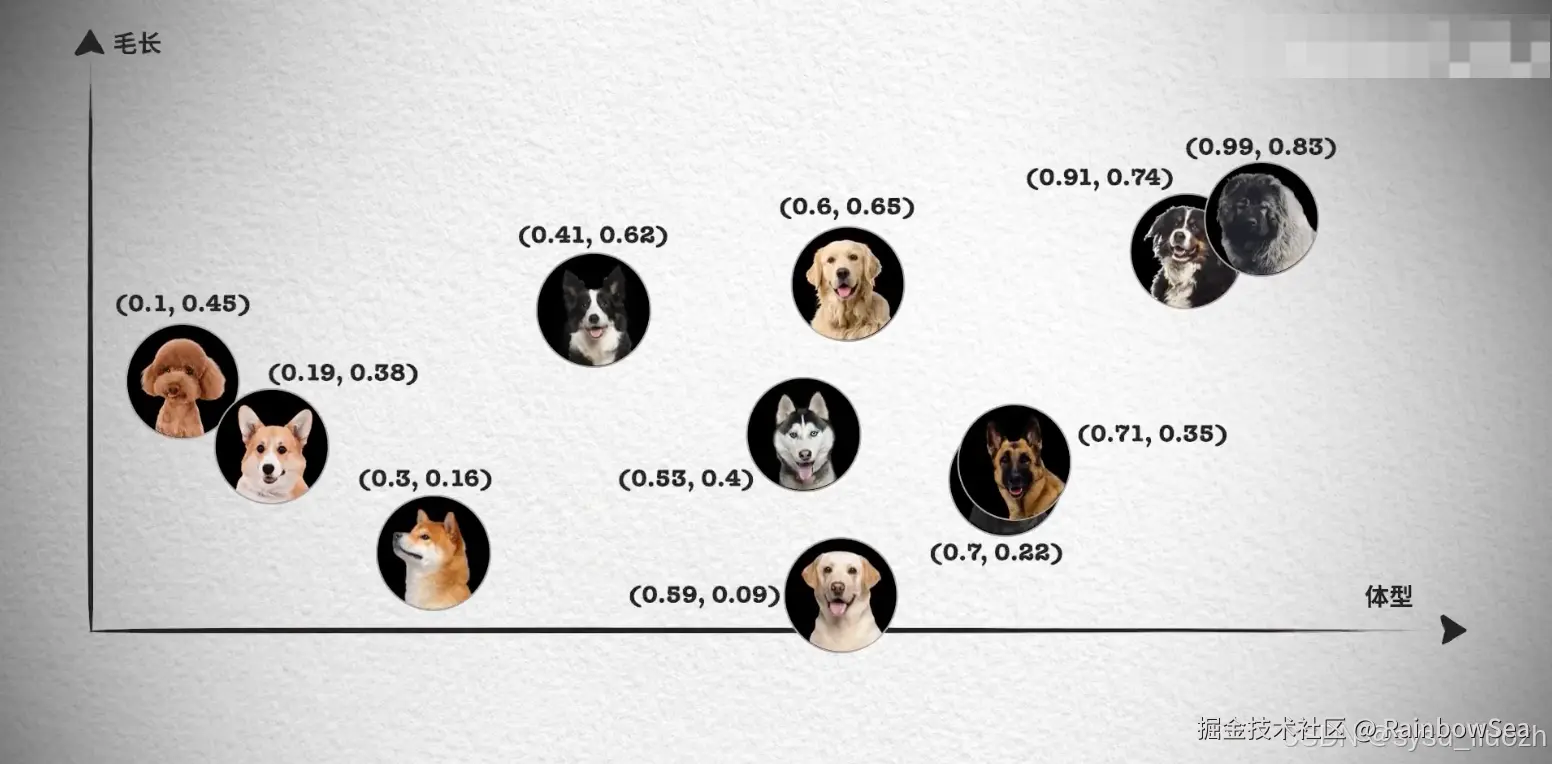
如果需要检索见过更加精准, 我们肯定还需要更多维度的向量, 组成更多维度的空间,在多维向量空间中,相似性检索变得更加复杂。我们需要使用一些算法,如余弦相似度或欧几里得距离,来计算向量之间的相似性。向量数据库会帮我实现。
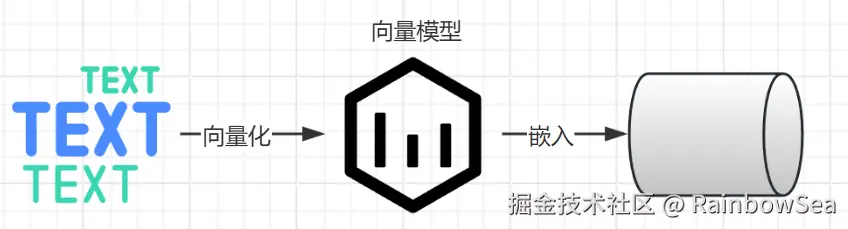
文本向量化
通过向量模型即可向量化, 这里我们学到了一种新的模型, 叫"向量模型" 专门用来做文本向量化的。
大语言模型不能做向量化, 所以需要单独找一个向量模型
- deepseek不支持向量模型
- 阿里百炼有大量向量模型
- 默认模型DashScopeEmbeddingProperties#DEFAULT_EMBEDDING_MODEL="text-embedding-v1"
properties
spring.ai.dashscope.embedding.options.model= text-embedding-v4- ollama有大量向量模型, 自己拉取
以ollama为例:
properties
spring.ai.ollama.embedding.model= nomic-embed-text
java
@SpringBootTest
public class EmbaddingTest {
@Test
public void testEmbadding(@Autowired OllamaEmbeddingModel ollamaEmbeddingModel) {
// .embed() 转换为向量模型
float[] embedded = ollamaEmbeddingModel.embed("我叫徐庶");
System.out.println(embedded.length);
System.out.println(Arrays.toString(embedded));
}
}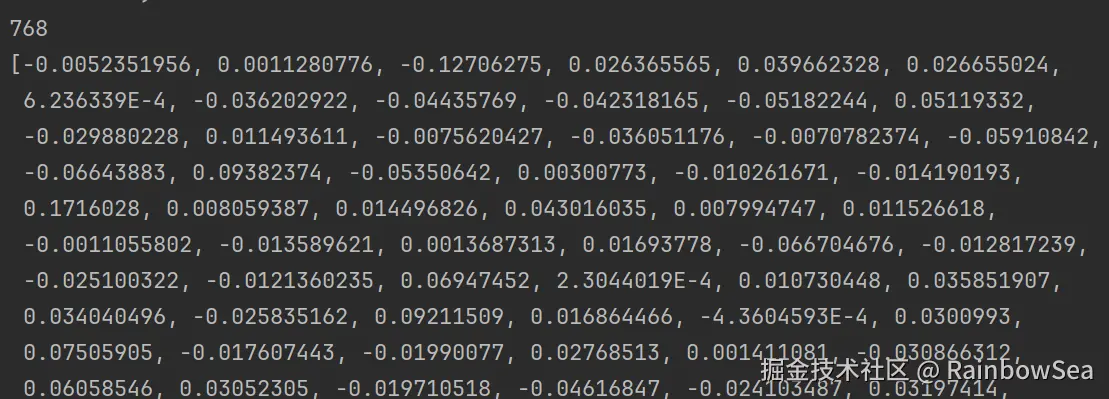
从结果可以知道"我叫徐庶"这句话经过OllamaEmbeddingModel向量化之后得到的一个长度为768的float数组。注意,768是向量模型nomic-embed-text-v1.5固定的,不会随着句子长度而变化,不同的向量模型提供了不同的维度。
那么,我们通过这种向量模型得到一句话对应的向量有什么作用呢?非常有用,因为我们可以基于向量来判断两句话之间的相似度,举个例子:
查询跟秋田犬类似的狗, 在向量数据库中根据每个狗的特点进行多维向量, 你会发现秋田犬的向量数值和柴犬的向量数值最接近, 就可以查到类似的狗。 (当然我这里只是举例,让你对向量数据库有一个印象)
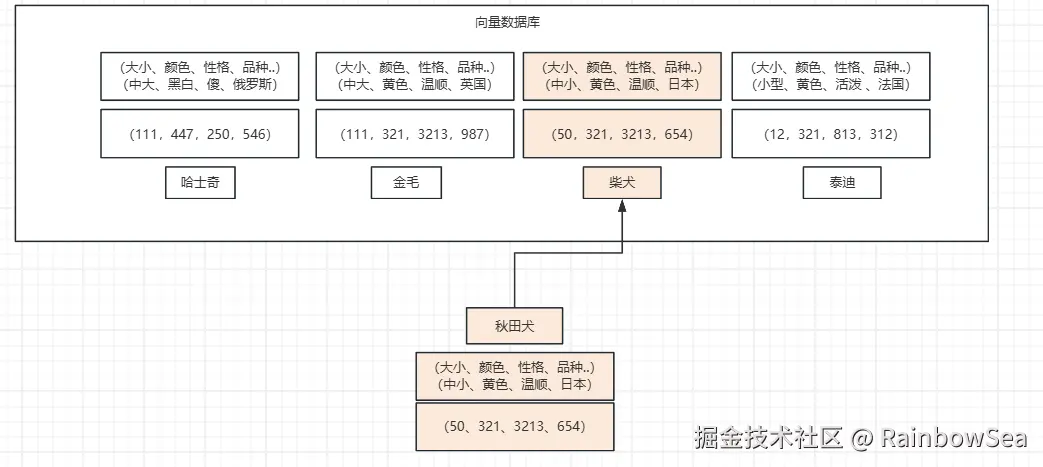
- 向量模型的本质目标,就是把语义相似的内容用"相近"的向量表示,把"不相关"内容尽量拉远。
- 所以好的向量模型能够更好的识别语义, 进行向量化.
向量数据库
对于向量模型生成出来的向量,我们可以持久化到向量数据库,并且能利用向量数据库来计算两个向量之间的相似度,或者根据一个向量查找跟这个向量最相似的向量。
在SpringAi中,VectorStore 表示向量数据库,目前支持的向量数据库有
-
Azure Vector Search- TheAzurevector store.
-
Apache Cassandra- TheApache Cassandravector store.
-
Chroma Vector Store- TheChromavector store.
-
Elasticsearch Vector Store - The Elasticsearch vector store. 可以"以向量+关键词"方式做混合检索。深度优化更多针对文本,不是专门"向量搜索引擎"。向量存储和检索容量有限制,查询延迟高于 Milvus。
-
GemFire Vector Store- TheGemFirevector store.
-
MariaDB Vector Store- TheMariaDBvector store.
-
Milvus Vector Store - The Milvus vector store.
-
MongoDB Atlas Vector Store- TheMongoDB Atlasvector store.
-
Neo4j Vector Store - The Neo4j vector store.可以结合结构化图谱查询与向量检索, 大规模嵌入检索(如千万---亿级高维向量)性能明显落后于 Milvus
-
OpenSearch Vector Store- TheOpenSearchvector store.
-
Oracle Vector Store- TheOracle Databasevector store.
-
PgVector Store- ThePostgreSQL/PGVectorvector store.
-
Pinecone Vector Store-PineConevector store.
-
Qdrant Vector Store-Qdrantvector store.
-
Redis Vector Store - The Redis vector store. 低门槛实现小规模向量检索。对于高维大规模向量(如几百万到上亿条),性能和存储效率不如专用向量库。
-
SAP Hana Vector Store- TheSAP HANAvector store.
-
Typesense Vector Store- TheTypesensevector store.
-
Weaviate Vector Store- TheWeaviatevector store.
-
SimpleVectorStore - A simple implementation of persistent vector storage, good for educational purposes.
其中有我们熟悉的几个数据库都可以用来存储向量,比如Elasticsearch、MongoDb、Neo4j、Pgsql、Redis。
视频中我会讲解2种:
- SimpleVectorStore教学版向量数据库
- Milvus Vector StoreMilvus(国产团队)、文档友好、社区国内活跃、性能最佳、市场占用率大。 实战中使用的向量数据库.
匹配检索
在这个示例中, 我分别存储了预订航班和取消预订2段说明到向量数据库中 然后通过"退票要多少钱" 进行查询
代码执行结果为:
OllamaEmbedding结果
java
@Bean
public VectorStore vectorStore(OllamaEmbeddingModel embeddingModel) {
// 绑定一个向量大模型,进行将数据信息向量化
SimpleVectorStore.SimpleVectorStoreBuilder builder = SimpleVectorStore.builder(embeddingModel);
return builder.build();
}SearchRequest
可以利用searchRequest设置检索请求:
- query 代表要检索的内容
- topK 设置检索结果的前N条
- 通常我们查询所有结果查出来, 因为查询结果最终要发给大模型, 查询过多的结果会:
*- 过多的token意味着更长延迟, 更多的费用, 并且过多上下文会超限;
-
- 研究表明过多的内容会降低 LLM 的*召回性能*;
- 通常我们查询所有结果查出来, 因为查询结果最终要发给大模型, 查询过多的结果会:
- similarityThreshold 设置相似度阈值, 可以通关设置分数限制召回内容相似度. 从而过滤掉废料。 (中文语料要适当降低分数) , 所以应遵循**始终以"业务召回效果"为主,而不是追求网上常说的高分阈值。
java
@BeforeEach
public void init( @Autowired
VectorStore vectorStore) {
// 1. 声明内容文档
Document doc = Document.builder()
.text("""
预订航班:
- 通过我们的网站或移动应用程序预订。
- 预订时需要全额付款。
- 确保个人信息(姓名、ID 等)的准确性,因为更正可能会产生 25 的费用。
""")
.build();
Document doc2 = Document.builder()
.text("""
取消预订:
- 最晚在航班起飞前 48 小时取消。
- 取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。
- 退款将在 7 个工作日内处理。
""")
.build();
// 2. 将文本进行向量化,并且存入向量数据库(无需再手动向量化)
vectorStore.add(Arrays.asList(doc,doc2));
}
@Test
void similaritySearchTest(
@Autowired
VectorStore vectorStore) {
// 3. 相似性查询
SearchRequest searchRequest = SearchRequest
.builder().query("预定航班")
.topK(5) // 查询几个
.similarityThreshold(0.3) // 过滤相似度 0.3 的内容,才返回
.build();
List<Document> results = vectorStore.similaritySearch(searchRequest);
// 4.输出
System.out.println(results);
}可以看到明显阿里的向量模型归类的更加准确,Ollama的向量模型查出来后结果并不正确。 所以为了你的准确性,请选择性能更好的向量模型。 想要更快更相似的搜索,用好的向量数据库。
接入ChatClient
- 依赖
json
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>- 代码
java
@Bean
public VectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
SimpleVectorStore.SimpleVectorStoreBuilder builder = SimpleVectorStore.builder(embeddingModel);
return builder.build();
}- 测试
实际你会发现, 最核心的是通过拦截器:QuestionAnswerAdvisor . 你应该能猜到底层肯定会通过拦截对话将相似内容发给大模型。 可以结合SimpleLoggerAdvisor 查看日志内容.
java
@SpringBootTest
public class SimpleVectorStoreTest {
@BeforeEach
public void init( @Autowired
VectorStore vectorStore) {
// 1. 声明内容文档
Document doc = Document.builder()
.text("""
预订航班:
- 通过我们的网站或移动应用程序预订。
- 预订时需要全额付款。
- 确保个人信息(姓名、ID 等)的准确性,因为更正可能会产生 25 的费用。
""")
.build();
Document doc2 = Document.builder()
.text("""
取消预订:
- 最晚在航班起飞前 48 小时取消。
- 取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。
- 退款将在 7 个工作日内处理。
""")
.build();
// 2. 将文本进行向量化,并且存入向量数据库(无需再手动向量化)
vectorStore.add(Arrays.asList(doc,doc2));
}
@Test
void chatRagTest(
@Autowired
VectorStore vectorStore,
@Autowired DashScopeChatModel chatModel
) {
ChatClient chatClient = ChatClient.builder(chatModel)
.build();
String message="退费需要多少费用?";
String content = chatClient.prompt().user(message)
// 通过 advisors 查询向量数据库,进行过滤
.advisors(
new SimpleLoggerAdvisor(),
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(
SearchRequest
.builder().query(message)
.topK(5)
.similarityThreshold(0.3)
.build())
.build()
).call().content();
System.out.println(content);
}
}RetrievalAugmentationAdvisor
- 查询空时扩展策略 :
java
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(PromptTemplate.builder().template("用户查询位于知识库之外。礼貌地告知用户您无法回答").build())
.build())- 查询检索器
- 检索提示词重写
java
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(dashScopeChatModel))
.targetSearchSystem("航空票务助手")
.build())翻译重写
java
.queryTransformers(TranslationQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(dashScopeChatModel))
.targetLanguage("中文")
.build())-
后置处理器:需要文档后处理和重排序
-
实现复杂的 RAG 流水线
java
@Test
public void testRag3(@Autowired VectorStore vectorStore,
@Autowired DashScopeChatModel dashScopeChatModel) {
chatClient = ChatClient.builder(dashScopeChatModel)
.defaultAdvisors(SimpleLoggerAdvisor.builder().build())
.build();
// 增强多
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
// 查 = QuestionAnswerAdvisor
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
// 检索为空时,返回提示
/*.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(PromptTemplate.builder().template("用户查询位于知识库之外。礼貌地告知用户您无法回答").build())
.build())*/
// 相似性查询内容转换
/*.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(dashScopeChatModel))
.targetSearchSystem("航空票务助手")
.build())*/
// 检索后文档监控、操作
/*.documentPostProcessors((query, documents) -> {
System.out.println("Original query: " + query.text());
System.out.println("Retrieved documents: " + documents.size());
return documents;
})*/
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user("退一张票大概要多少费用?希望别扣太多啊")
.call()
.content();
System.out.println(answer);
}
@TestConfiguration
static class TestConfig {
@Bean
public VectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
}最后:
"在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。"
