文章目录
- 1.引言
- [2.List 类型核心命令](#2.List 类型核心命令)
-
- [2.1 插入命令:lpush /rpush/lpushx /rpushx](#2.1 插入命令:lpush /rpush/lpushx /rpushx)
-
- [2.1.1 lpush](#2.1.1 lpush)
- [2.1.2 rpush](#2.1.2 rpush)
- [2.1.3 lpushx](#2.1.3 lpushx)
- [2.1.4 rpushx](#2.1.4 rpushx)
- [2.2 删除命令](#2.2 删除命令)
-
- [2.2.1 lpop](#2.2.1 lpop)
- [2.2.2 rpop](#2.2.2 rpop)
- [2.2.3 blpop /brpop](#2.2.3 blpop /brpop)
- [2.3 查询命令](#2.3 查询命令)
-
- [2.3.1 lrange](#2.3.1 lrange)
- [2.3.2 lindex](#2.3.2 lindex)
- [2.3.3 llen](#2.3.3 llen)
- [2.4 修改与删除指定元素命令](#2.4 修改与删除指定元素命令)
-
- [2.4.1 linsert](#2.4.1 linsert)
- [2.4.2 lset](#2.4.2 lset)
- [2.4.3 lrem](#2.4.3 lrem)
- [2.4.4 ltrim](#2.4.4 ltrim)
- [3.List 类型的底层编码](#3.List 类型的底层编码)
- 4.应用场景
-
- [4.1 有序数据存储](#4.1 有序数据存储)
- [4.2 分布式消息队列](#4.2 分布式消息队列)
- [4.3 分页](#4.3 分页)
-
- [4.3.1 基础实现:基于lrange的分页](#4.3.1 基础实现:基于lrange的分页)
- [4.3.2 核心优化:解决 "中间页查询低效" 问题](#4.3.2 核心优化:解决 “中间页查询低效” 问题)
- [4.3.3 额外优化:减少网络请求次数](#4.3.3 额外优化:减少网络请求次数)
- [4.4 业务视角](#4.4 业务视角)
- 5.小结
1.引言
在 Redis 的常用数据类型中,List(列表)是兼顾 "有序性" 与 "灵活性" 的代表 ------ 它既可以像数组一样按下标访问元素,也能像双端队列一样高效地从两端插入 / 删除数据,甚至能模拟栈、消息队列等经典数据结构。本文将从 List 的核心特性出发,系统拆解其命令体系、底层编码优化逻辑,以及在实际业务中的典型应用场景,帮助你掌握 "如何用 List 解决分布式系统中的有序数据存储与交互问题"。
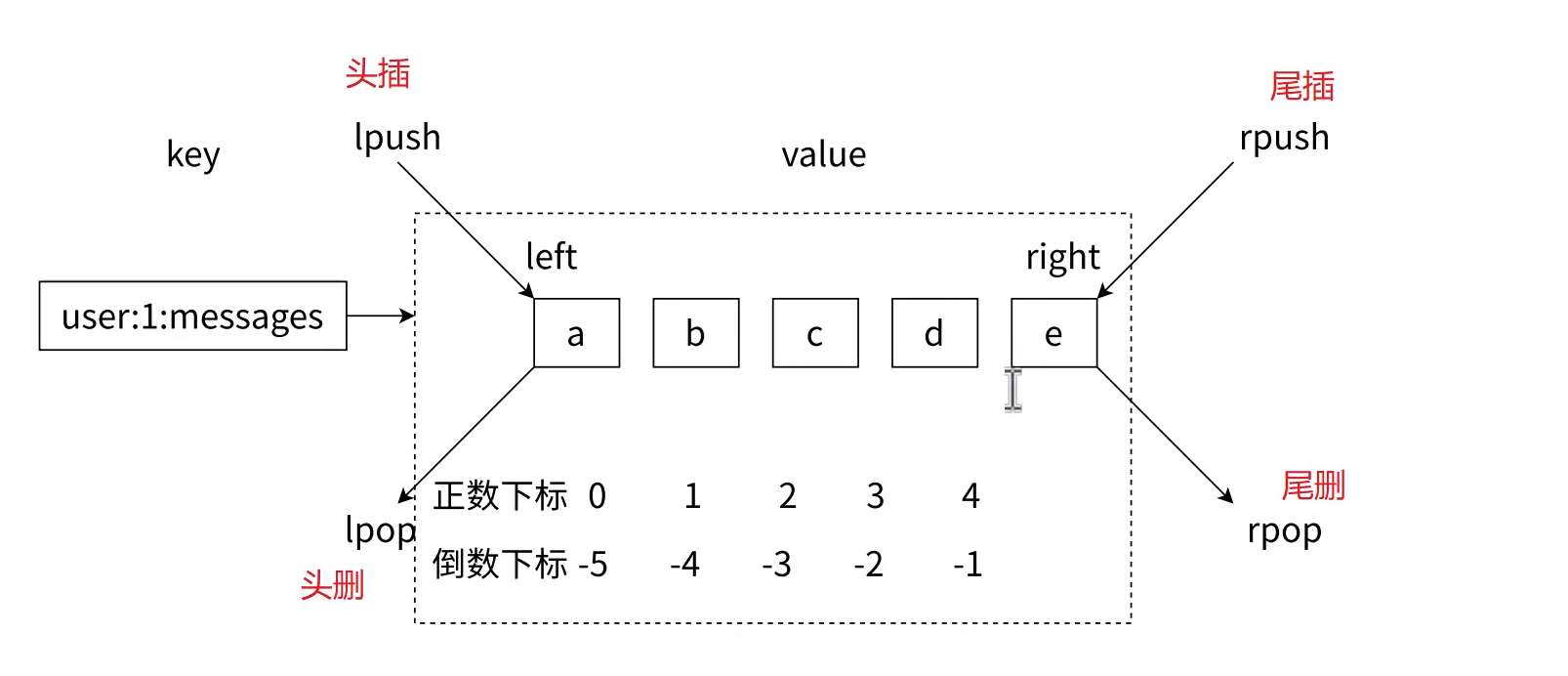
2.List 类型核心命令
2.1 插入命令:lpush /rpush/lpushx /rpushx
2.1.1 lpush
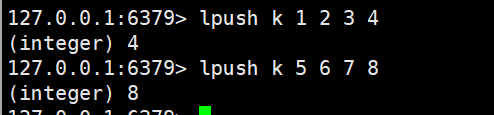
lpush key element [element ...]
- 功能:从列表头部(左侧) 插入 1 个或多个元素;若 Key 不存在,会先创建空列表再插入。
- 时间复杂度:O (1)
- 返回值:插入元素后,列表的总长度。
2.1.2 rpush
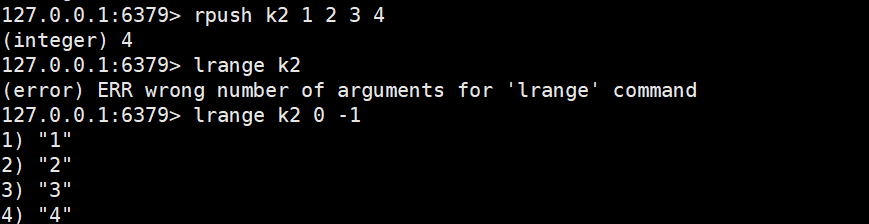
rpush key element [element ...]
- 功能:从列表尾部(右侧) 插入 1 个或多个元素;若 Key 不存在,会先创建空列表再插入。
- 时间复杂度:O(1)。
- 返回值:插入元素后,列表的总长度。
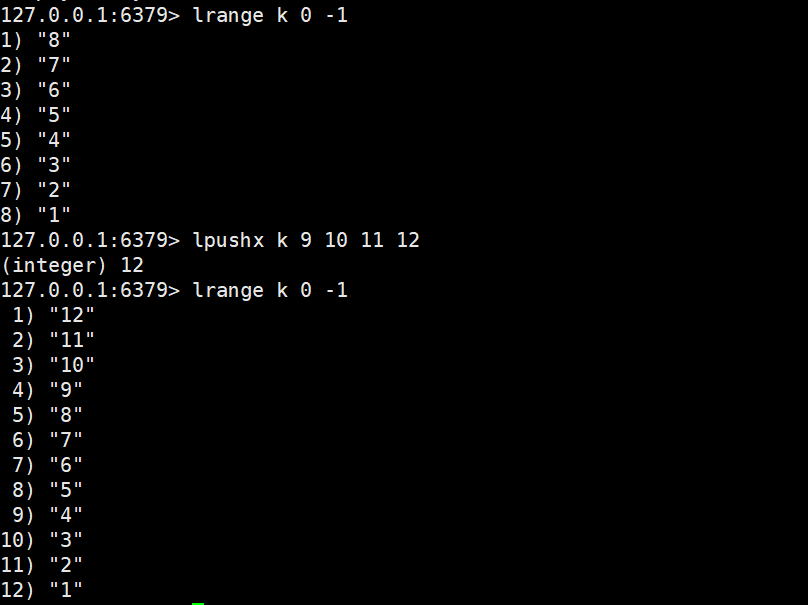
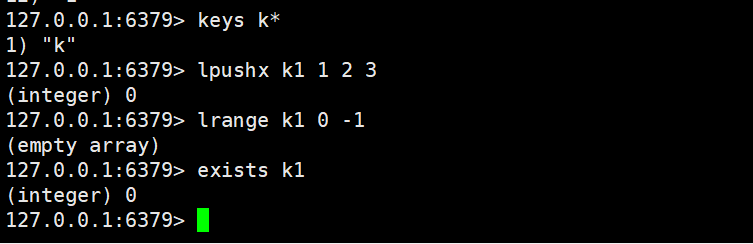
2.1.3 lpushx
lpushx key element [element ...]
- 功能:仅当 Key已存在时,从列表头部插入 1 个或多个元素;若 Key 不存在,不执行任何操作。
- 时间复杂度:O(1)。
- 返回值:插入元素后列表的总长度(Key 不存在时返回 0)。
2.1.4 rpushx
rpushx key element [element ...]
- 功能:仅当 Key已存在时,从列表尾部插入 1 个或多个元素;若 Key 不存在,不执行任何操作。
- 时间复杂度:O(1)。
- 返回值:插入元素后列表的总长度(Key 不存在时返回 0)。
2.2 删除命令
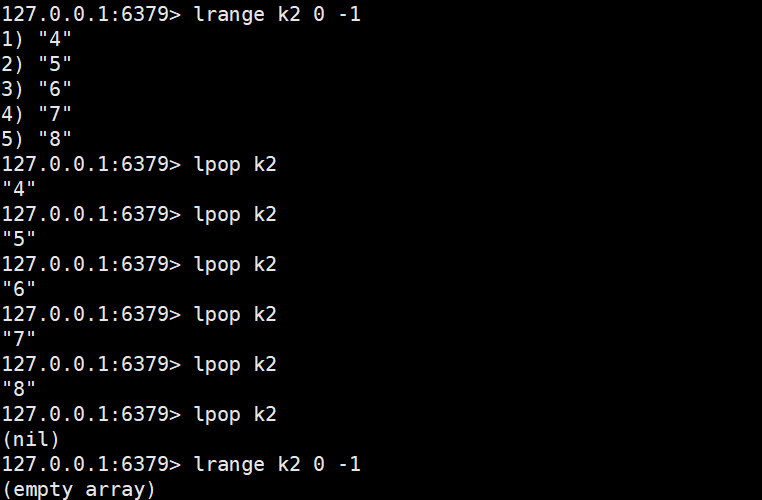
2.2.1 lpop
lpop key [count]
- 功能:从列表头部移除 1 个或count个元素;若 Key 不存在或列表为空,返回nil。
- 时间复杂度:O (1)
- 返回值:移除的元素(移除 1 个时返回单个值,移除多个时返回元素列表)。
2.2.2 rpop
rpop key [count]
- 功能:从列表尾部移除 1 个或count个元素;若 Key 不存在或列表为空,返回nil。
- 时间复杂度:O(1)。
- 返回值:移除的元素(移除 1 个时返回单个值,移除多个时返回元素列表)。
redis中的list是一个双端队列,从两头插入删除都是非常高效的O(1)
搭配使用lpush(rpush) rpop(lpop)就是一个队列
搭配使用lpush(rpush) lpop(rpop)就是一个栈
2.2.3 blpop /brpop
blpop key [key ...] timeout
- 功能:阻塞式从 "第一个非空列表" 的头部移除元素:
- 若传入多个 Key,按顺序检查每个 Key 对应的列表,找到第一个非空列表并移除头部元素;
- 若所有列表均为空,阻塞等待timeout秒(timeout=0表示永久阻塞),超时后返回nil。
- 时间复杂度:O(1)。
- 返回值:数组形式,第一个元素是 "移除元素所在的 Key",第二个元素是 "移除的元素"(超时返回nil)。
阻塞队列:
1)如果队列为空,尝试出队列--》阻塞 。 队列不空--》不阻塞
2)如果队列为满,尝试入队列--》阻塞。 队列不满--》不阻塞
1)blpop/brpop可以设置阻塞时间,超时也会停止阻塞。
2)命令也可以同时监听多个key,从左向右遍历,一旦有一个key对应的列表中可以弹出元素,命令立刻返回。
3)多个客户端同时执行pop,则最先执行的客户端得到弹出的元素

对一个空队列操作:
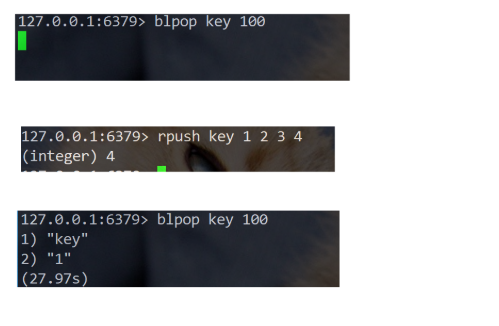
先阻塞在那,开另一个客户端对指定队列插入元素,结束阻塞并弹出。
对多个key进行操作:
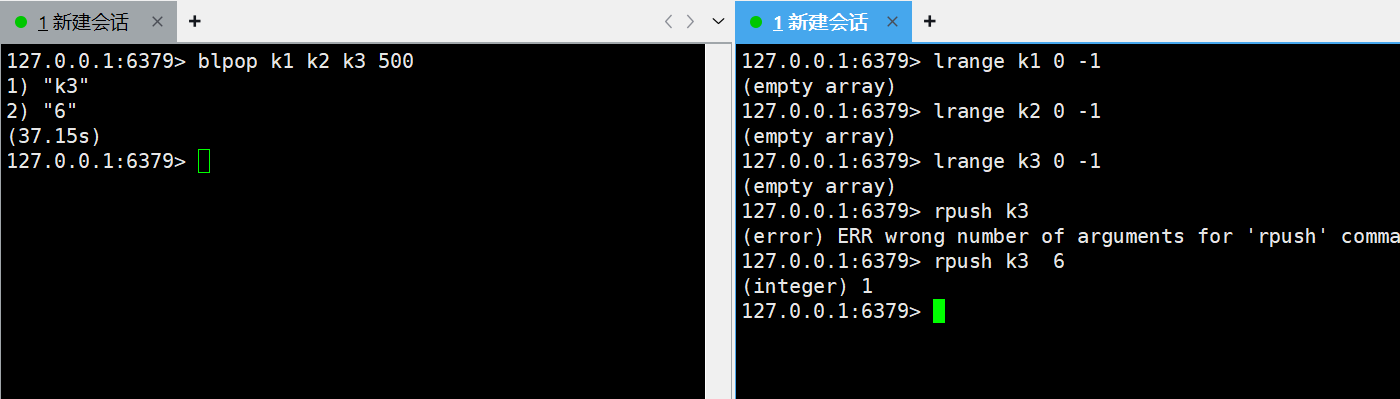
brpop与blpop同理
2.3 查询命令
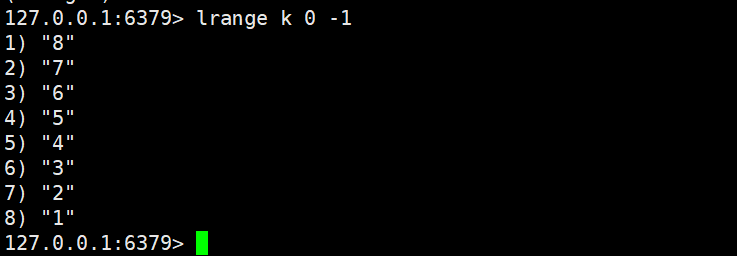
2.3.1 lrange
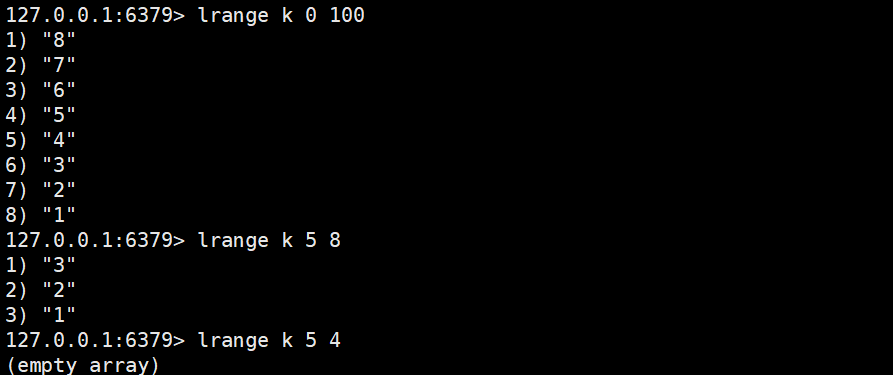
lrange key start end
- 功能:获取列表中start, end区间的所有元素(闭区间,支持负数下标:-1表示最后一个元素,-2表示倒数第二个,以此类推)。
- 时间复杂度:O (N)(N 为区间内元素的个数,而非列表总长度)。
- 返回值:区间内的元素列表(空列表或 Key 不存在时返回空列表)。
- 关键特性:容错性强,若start或end超出列表范围,会自动调整为有效区间(如列表长度为 5,end=10会自动改为end=4)。
2.3.2 lindex
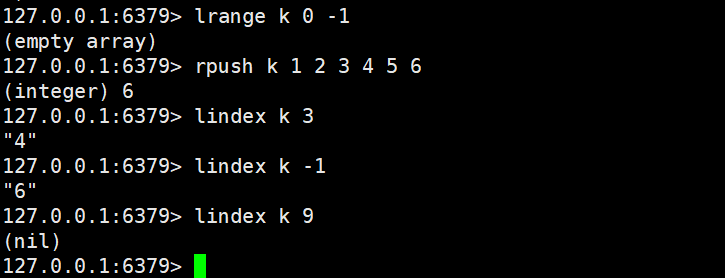
lindex key index
- 功能:获取列表中指定下标的单个元素(下标从 0 开始,负数表示倒数)。
- 时间复杂度:O (N)(N 为 "从列表头部 / 尾部到目标下标的距离",列表越长,中间元素查询越慢)。
- 返回值:指定下标的元素(下标非法或 Key 不存在时返回nil)
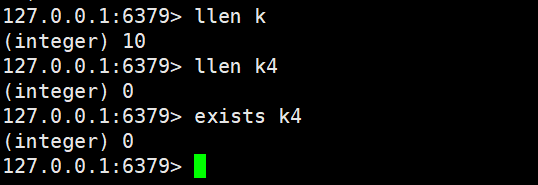
2.3.3 llen
llen key
- 功能:获取列表的元素总长度。
- 时间复杂度:O (1)
- 返回值:列表的元素个数(Key 不存在时返回 0)。
2.4 修改与删除指定元素命令
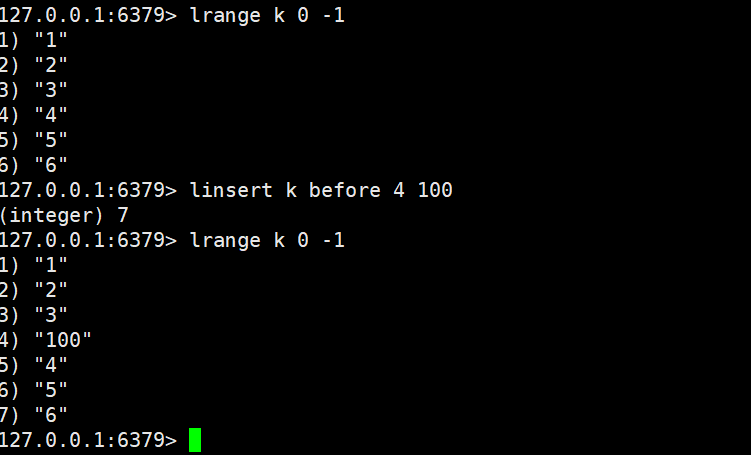
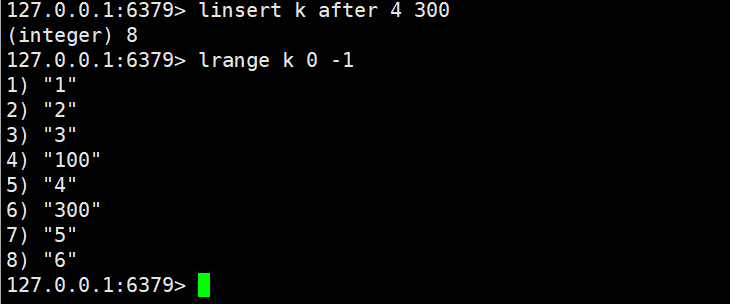
2.4.1 linsert
linsert key BEFORE|AFTER pivot element
- 功能:在列表中 "第一个匹配pivot的元素" 的前面(BEFORE) 或后面(AFTER) 插入element;若列表中无pivot元素,不执行任何操作。
- 时间复杂度:O (N)
- 返回值:插入元素后列表的总长度(无pivot时返回-1,Key 不存在时返回0)。
2.4.2 lset
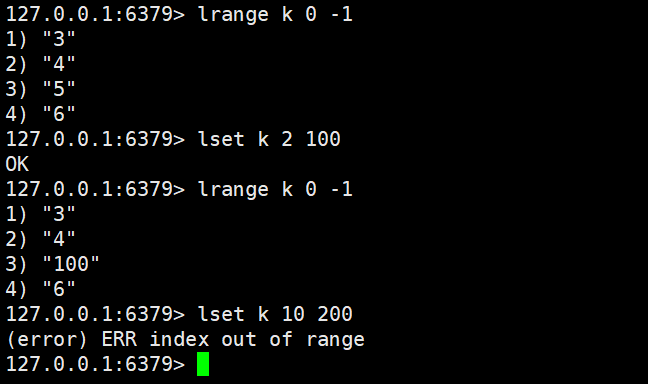
lset key index element
- 功能:将列表中指定下标的元素修改为element;若 Key 不存在或下标非法(超出列表长度),直接报错。
- 时间复杂度:O (N)
- 返回值:修改成功返回OK,失败返回错误信息。
- 注意:与lindex的区别 ------lindex下标非法返回nil,lset下标非法会报错。
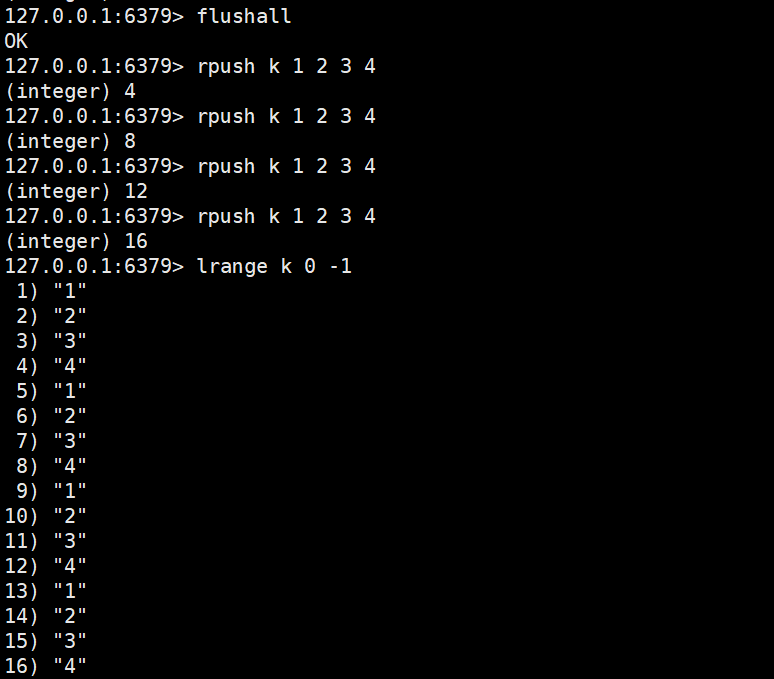
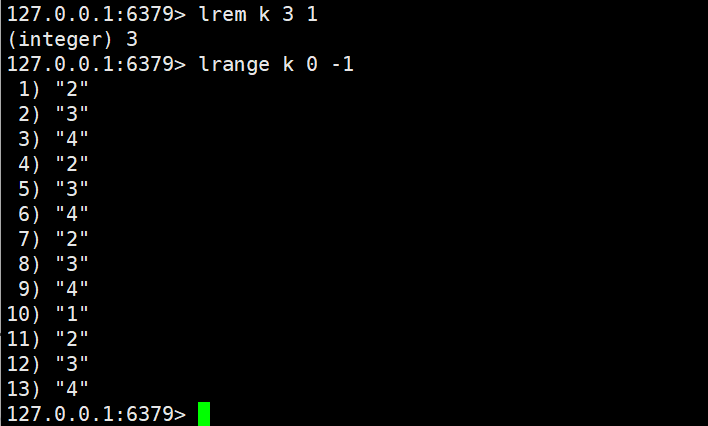
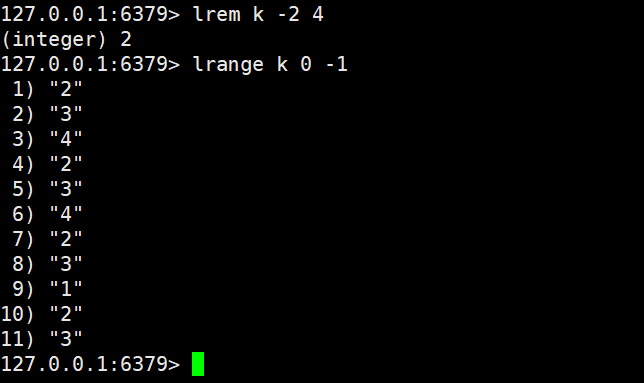
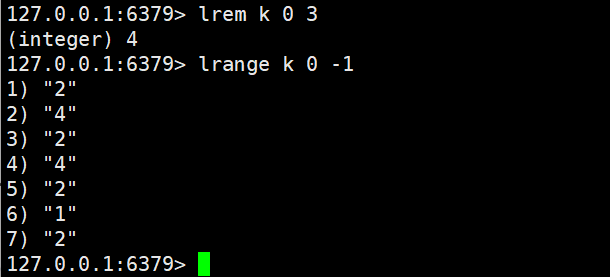
2.4.3 lrem
lrem key count element
- 功能:删除列表中 "值等于element" 的元素,删除数量由count决定:
- count > 0:从列表头部到尾部删除count个匹配元素;
- count < 0:从列表尾部到头部删除count的绝对值个匹配元素;
- count = 0:删除列表中所有值等于element的元素。
- 时间复杂度:O (N+M)(N 为列表总长度,M 为删除的元素个数,需遍历列表匹配元素)。
- 返回值:实际删除的元素总个数(Key 不存在或无匹配元素时返回 0)。
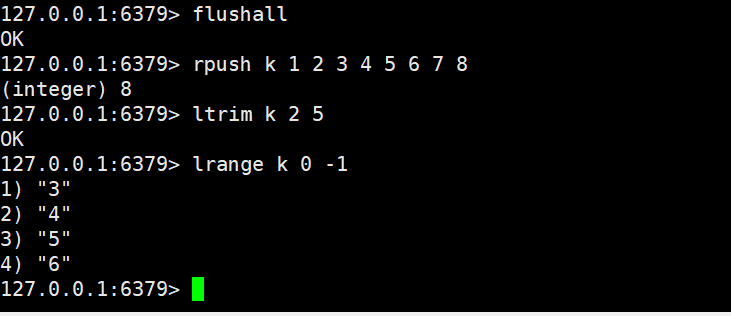
2.4.4 ltrim
ltrim key start end
- 功能:保留列表中start, end区间的元素,删除区间外的所有元素(闭区间,支持负数下标);若 Key 不存在,不执行任何操作。
- 时间复杂度:O (N)(N 为删除的元素个数,需遍历并移除区间外元素)。
- 返回值:操作成功返回OK。
3.List 类型的底层编码
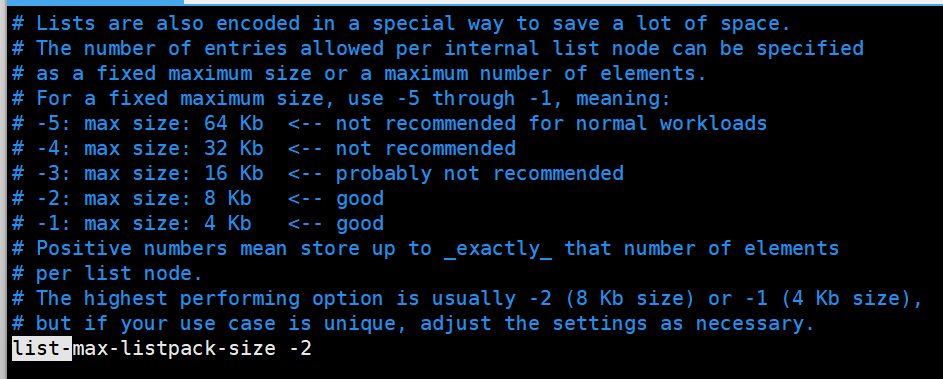
Redis 3.2 版本前,List 的底层编码是 "ziplist(压缩列表)" 和 "linkedlist(双向链表)" 的切换;3.2 版本后,统一为quicklist(快速列表) ------ 这是 "双向链表 + 压缩列表" 的混合结构,兼顾了内存效率与操作性能。

每个压缩列表控制大小,不要太大

4.应用场景
4.1 有序数据存储
适用于需要 "按插入顺序存储多个元素" 且 "频繁访问两端数据" 的场景,如用户浏览历史、商品评价列表、系统操作日志等 ------ 这类场景的核心诉求是 "保留顺序 + 快速增删 + 按需截取"。
redis如何组织要通过实际情况决定
4.2 分布式消息队列
List 的lpush(生产者写入)+brpop(消费者阻塞读取)组合,是实现 "轻量级分布式消息队列" 的经典方案,适用于低延迟、低并发的消息传递场景(如订单状态通知、用户注册成功后发送欢迎短信)。
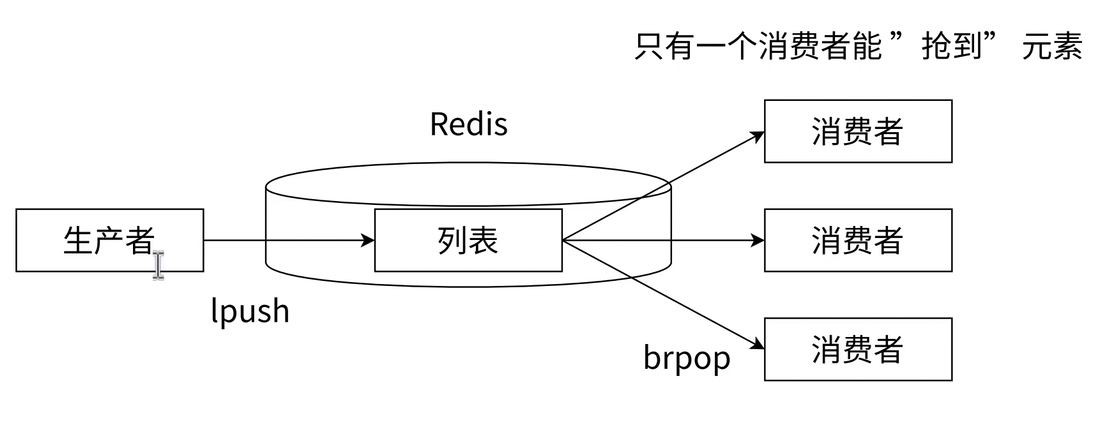
谁先执行brpop命令,先拿到元素
这样的设定,就能构成一个 "轮询" 式的效果。
按执行命令的顺序依次获取元素,如果一个消费者想多次消费,再次执行的命令排在前面已有的命令之后,达到轮流获取(轮询)的效果。
分频道的消息队列
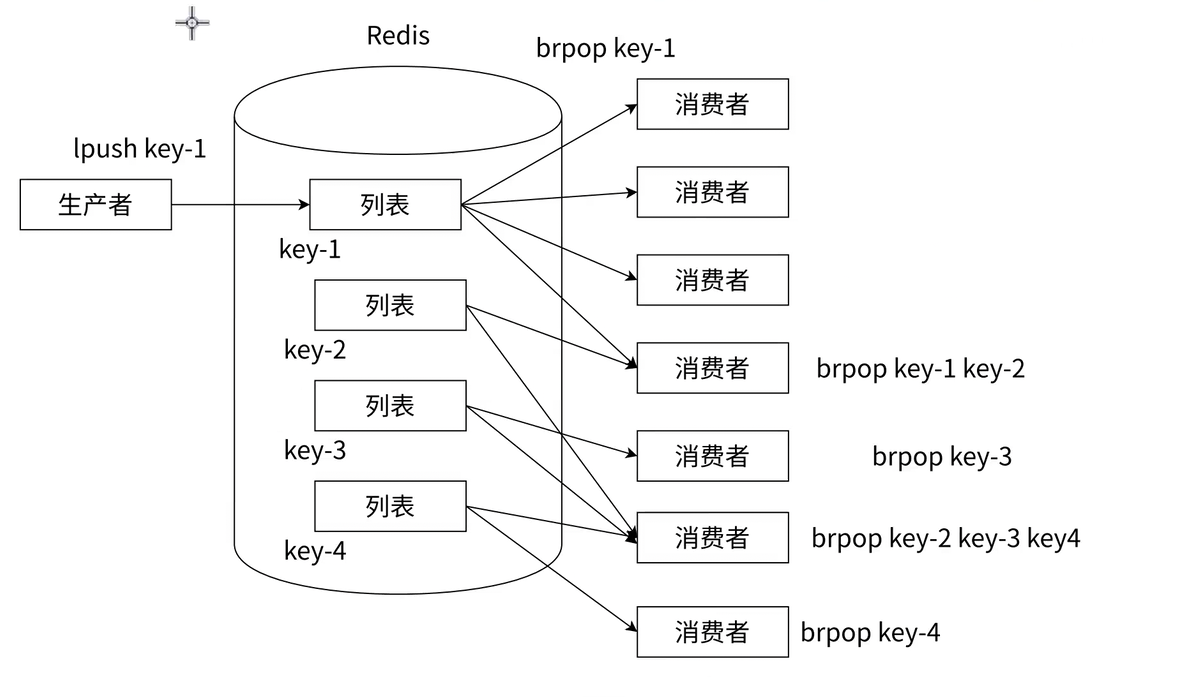
当业务场景中存在多种消息类型(如电商平台的 "订单消息""库存消息""物流消息"),若所有消息都放入一个 List,会导致 "消息混杂、处理效率低、某类消息异常影响全局"。此时可通过 "分频道" 优化 ------ 为每种消息类型创建独立的 List,实现 "消息隔离、解耦业务"。
比如在抖音上刷视频:
通过一个频道,来传输视频数据
另一个频道,传输弹幕
另一个频道,传输 评论 数据
...
搞成多个频道,就可以在某种数据发送问题的时候,不会对其他数据造成影响(解耦合)
4.3 分页
当 List 中存储的元素数量过大(如微博用户发表的 1 万条文章),无法一次性在前端展示,需实现 "分页加载"------ 用户点击 "下一页" 时,加载对应页的内容。List 的lrange命令可直接支持分页,但需注意优化 "中间页查询效率"。
4.3.1 基础实现:基于lrange的分页
假设每页展示 10 条文章,分页逻辑如下:
- 第 1 页(首页):调用lrange user:articles:10086 0 9------ 获取列表第 0 到 9 个元素(最新的 10
条文章); - 第 2 页:调用lrange user:articles:10086 10 19------ 获取第 10 到 19 个元素;
- 第 N 页:调用lrange user:articles:10086 (N-1)10 N10-1------ 按公式计算区间。
同时,调用llen user:articles:10086获取总元素个数,计算总页数。
4.3.2 核心优化:解决 "中间页查询低效" 问题
List 的底层是链表结构,lrange查询中间页(如第 500 页)时,需从列表头部遍历到第 4990 个元素,时间复杂度为 O (N),随着页数增加,查询速度会明显变慢。针对这一问题,可采用 "列表拆分" 优化 ------ 将大列表拆分为多个小列表,降低单列表长度。
以 "存储 1 万条文章" 为例,优化方案如下:
- 拆分小列表:按 "每页 10 条" 的粒度,将 1 万条文章拆分为 1000 个小列表,命名规则为user:articles:10086:page:1(第 1 页,存储前 10条)、user:articles:10086:page:2(第 2 页,存储 11-20条)、 user:articles:10086:page:1000(第 1000 页,存储 9991-10000 条);
- 分页查询:用户访问第 500 页时,直接调用lrange user:articles:10086:page:500 0 9------ 无需遍历大列表,直接查询对应小列表,时间复杂度降至 O (1);
- 新增文章处理:用户发表新文章时,调用lpush user:articles:10086:page:1 新文章ID------ 插入第 1
页小列表;若第 1 页元素超过 10 条(如第 1 页已有 10 条,插入后变为 11 条),则将第 1 页的最后 1 条元素移到第 2页的头部(rpop user:articles:10086:page:1 + lpush user:articles:10086:page:2 元素ID),确保每个小列表不超过 10 条。
4.3.3 额外优化:减少网络请求次数
基础分页中,查询 "某页文章详情" 时,需先调用lrange获取该页的文章 ID 列表,再循环调用hgetall 文章ID获取每个文章的标题、内容等详情 ------ 若每页 10 条文章,需 1 次lrange+10 次hgetall,共 11 次网络请求,效率较低。
可通过Redis Pipeline(流水线/管道) 优化:将 "1 次lrange+10 次hgetall" 的 11 次请求合并为 1 次请求发送给 Redis,Redis 批量处理后一次性返回结果,大幅减少网络通信次数(从 11 次降至 1 次),提升查询效率。
4.4 业务视角
| List 核心特性 | 对应的业务诉求 | 典型场景 |
|---|---|---|
| 两端插入 / 删除高效(O (1)) | 高频增删、需保留顺序(先进先出 / 先进后出) | 消息队列、浏览历史、栈 |
| 支持阻塞读取(brpop/blpop) | 避免轮询空列表、降低资源浪费 | 消费者监听消息队列 |
| 支持区间截取(ltrim/lrange) | 需保留最新 N 条数据、分页展示 | 操作日志、分页文章 |
| 元素可重复 | 允许存储相同内容的多条数据 | 重复消息通知、多次浏览记录 |
5.小结
Redis List 类型的核心价值在于 "有序性 + 灵活性"------ 它既满足了 "按插入顺序存储" 的基础需求,又通过双端操作、阻塞读取等特性,适配了消息队列、分页等复杂场景,是分布式系统中 "有序数据交互" 的重要工具。
使用 List 类型时,需牢记三个关键建议:
- 优先操作两端:尽量用lpush/rpush(插入)、lpop/rpop(删除)等两端操作(O (1)),避免lindex/linsert等中间操作(O (N)),减少性能损耗;
- 合理拆分大列表:当列表元素超过 1 万条时,采用 "小列表拆分" 优化,避免lrange查询中间页效率低的问题;
- 消息队列需兜底:用 List 实现消息队列时,必须添加 "备份队列" 或 "消息重试" 逻辑,避免消息丢失,同时监控队列长度,防止内存溢出。