1. 初识 MySQL
MySQL 是一个客户端服务器结构的程序。
MySQL 的服务器是主体,提供数据管理服务,硬盘存储。
MySQL 是一个关系型数据库。关系二字首先特指一种由行和列组成的二维表格,这样的表格在 MySQL 中称为 table。table 中的每一行称为一条记录(record),表示一个具体的实体;每一列称为一个字段(field),描述一个实体某项具体的特征,每一列都定义了严格的数据类型。
关系又指表与表之间的关系,这种关系在 MySQL 中主要通过主键(Primary Key)和外键(Foreign Key)来维护。
关系型数据库是严格模式化的,这意味着在存入数据之前,必须先定义好表的 "蓝图"。这包括,表名、字段名、字段的数据类型、约束等等。
2. 数据类型
MySQL 数据类型主要分为三大类:数值、字符串、日期时间。
2.1 常用数值类型
|---------------|--------------------------------------------------------------------------------------|----|------------|
| 类型 | 描述 | 字节 | 应用场景 |
| tinyint | 整数类型,表示范围 255 | 1 | 标志位,年龄 |
| int | 整数类型,表示范围 42 亿 | 4 | 商品库存,文章浏览量 |
| bigint | 整数类型,表示范围极大 | 8 | 自增主键,分布式 |
| decimal(M, D) | 定点数,底层以字符串形式存储数字。 M 是总位数,D 是小数点后的位数。 例如 DECIMAL(10, 2) 可以存储最高 99999999.99 的数值。 | | 与金额有关的场景 |
注意:
-
对于整数类型,可以使用 unsigned 关键字表示无符号数,允许存储的正数范围扩大一倍。
-
整数类型按需使用,不要盲目选 bigint。更小的数据类型意味着,当数据库进行排序、分组、创建临时表或在内存中缓存数据时,更多的记录可以被放入内存缓冲池中,提高缓存命中率。
2.2 常用字符串类型
char(size) 定长字符串。
varchar(size) 变长字符串,即磁盘空间并不是立即分配,而是动态扩容的。
注意:
-
size 表示最多存储多少个字符,而不是字节。这表示 "123java你好" 这个字符串,只需要设置 size 为 9 就可以存放下。
-
创建数据库始终使用
utf8mb4字符集,这是现代应用的默认选择,因为它支持最广泛的字符,包括表情符号,避免乱码。其中的字符占用 1 - 4 个字节(英文数字 1 字节,汉字 3 字节,表情符号 4 字节)。 -
varchar 需要使用额外的 1 到 2 个字节来维护字符串长度。如果 size <= 255,只需要 1 个字节来存储长度值。如果 size > 255,则需要 2 个字节来存储长度值。因此 255 这个数字成为非常常见的字符串字段长度定义值,但它也并不是适用于任何场景。
比如,当我们需要储存 URL 时,2048 是一个常见的安全值,这是基于很多浏览器对 URL 长度的限制。
又比如,当我们存储由 bcrypt 等算法生成的固定长度哈希值,使用定长字符串 char 则是非常清晰和正确的设计。
2.3 常用日期时间类型
一般使用 datetime 类型。阿里开发规约强制要求表必备三字段:id,create_time,update_time。其中 id 为 bigint,create_time 和 update_time 均为 datetime。
3. 基础 CRUD
3.1 create
sql
-- 指定列插入
-- id 是自增的,created_at 设置了默认值(如 CURRENT_TIMESTAMP),所以可以自动生成
INSERT INTO users (username, email, age)
VALUES ('zhangsan', 'zhangsan@email.com', 25);
-- 一次性插入多条记录,效率更高
INSERT INTO users (username, email, age)
VALUES
('lisi', 'lisi@email.com', 30),
('wangwu', 'wangwu@email.com', 28);3.2 select
sql
-- 基础查询语法
SELECT column1, column2, ...
FROM table_name
[WHERE condition]
[ORDER BY column_name [ASC|DESC]]
[LIMIT number];
-- ---------------------------------------------------
-- where 条件查询
-- from 前限制列,from 后限制行
-- 实际开发中应避免使用 * ,这会增加解析成本
-- 查询年龄等于 25 的用户名和邮箱
SELECT username, email FROM users WHERE age = 25;
-- 查询年龄大于 25 的用户
SELECT * FROM users WHERE age > 25;
-- 查询年龄大于 25 且邮箱包含 '@email.com' 的用户
-- % 为模糊匹配,_ 为精确匹配
SELECT * FROM users
WHERE age > 25 AND email LIKE '%@email.com%';
-- 查询年龄在 20 到 30 之间的用户
SELECT * FROM users WHERE age BETWEEN 20 AND 30;
-- 查找年龄为 25, 30, 或 35 的用户
SELECT * FROM users WHERE age IN (25, 30, 35);
-- 等价于使用多个 OR
SELECT * FROM users WHERE age = 25 OR age = 30 OR age = 35;
-- 查找年龄不是 25 或 30 的用户
SELECT * FROM users WHERE age NOT IN (25, 30);
-- 查找(年龄大于25且是VIP)或者(注册时间在2023年之前)的用户
-- 注意使用括号来明确优先级
SELECT * FROM users
WHERE (age > 25 AND user_type = 'vip')
OR (created_at < '2023-01-01');
-- ---------------------------------------------------
-- 使用别名简化表名(多表查询时使用)
SELECT u.username, u.email
FROM users AS u
WHERE u.age > 25;
-- ---------------------------------------------------
-- 排序
-- 按年龄升序排序(默认,从小到大)
SELECT * FROM users ORDER BY age;
-- 按年龄降序排序
SELECT * FROM users ORDER BY age DESC;
-- 按年龄降序排,年龄相同的再按用户名升序排
SELECT * FROM users ORDER BY age DESC, username ASC;
-- ---------------------------------------------------
-- 限制返回数量
-- 只返回前 5 条记录
SELECT * FROM users LIMIT 5;
-- 分页查询:从第 10 条记录开始(偏移量10),返回之后的 5 条记录
-- 常用于实现分页功能:LIMIT (page_number - 1) * page_size, page_size
SELECT * FROM users LIMIT 10, 5;
-- ---------------------------------------------------
-- 聚合查询
-- 聚合函数进行的是行和行之间的运算
-- 按用户所在城市分组,计算每个城市的用户平均年龄
SELECT city_id, AVG(age) FROM users GROUP BY city_id;
-- 查找在中国用户数量超过 100 人的城市
SELECT city_id, COUNT(*) AS user_count
FROM users
WHERE country = 'China' -- 在聚合前过滤掉非中国的记录
GROUP BY city_id
HAVING user_count > 100; -- 在聚合后过滤掉用户数量小于 100 的城市
-- 执行顺序为:WHERE -> GROUP BY 分组进行聚合 -> 聚合 -> HAVING
-- 注意:当 SELECT 后只有聚合函数时,查询的是整个结果集的聚合值,
-- 服务器返回一个值,此时不能也不应该使用 GROUP BY。
-- 当 SELECT 后同时包含聚合函数和普通字段时,必须使用 GROUP BY,
-- 并且 GROUP BY 子句必须包含所有那些未被聚合的普通字段。
-- 其他聚合函数:MAX()、MIN()、SUM()3.3 update
sql
-- 将用户 'lisi' 的邮箱和年龄都更新
UPDATE users
SET email = 'new_lisi@email.com', age = 31
WHERE username = 'lisi';3.4 delete
sql
-- 删除名为 'wangwu' 的用户
DELETE FROM users WHERE username = 'wangwu';
-- 更常见的做法是使用逻辑删除(Soft Delete),
-- 即通过一个 is_deleted 字段标记记录为已删除状态,而不是物理删除。
UPDATE users SET is_deleted = 1 WHERE username = 'wangwu';4. 约束
4.1 primary key
强制该字段的唯一性和非空性。每个表都应有一个主键,用于定位唯一的一条元素,阿里开发规约强制每个表都需存在一个自增主键的 id 字段。
sql
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY, -- id 是主键,自增
username VARCHAR(50) NOT NULL
);4.2 foreign key
确保一个表中的数据必须指向另一个表中存在的记录,从而维护参照完整性。
sql
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
amount DECIMAL(10, 2),
-- 定义外键:users 表的 id 字段约束了当前表的 user_id 字段
FOREIGN KEY (user_id) REFERENCES users(id)
ON DELETE CASCADE -- 可选的参照动作:当 users 中的用户被删除,此用户的订单也会被自动删除
-- ON UPDATE CASCADE -- 当 users 中的 id 更新,此处的 user_id 也会同步更新
);references 表示引用自,即必须出自。每次执行对 orders 表中的 users_id 列的插入操作,都会触发对 users 表中的 id 列的查询,检查该值是否存在。因此外键约束会带来一些性能开销。现在的表设计中,为了减少数据库对外键的检查,通常避免设置外键,将校验工作在应用程序中完成。
4.3 unique
保证该字段或字段组合的值,在表中唯一。
sql
-- 方式一: 字段声明时定义
CREATE TABLE `user` (
`email` VARCHAR(255) UNIQUE
);
-- 方式二: 单独定义约束
CREATE TABLE `user` (
`email` VARCHAR(255),
UNIQUE KEY `uk_email` (`email`)
);
-- 复合唯一索引
CREATE TABLE `user_activities` (
`activity_id` INT UNSIGNED NOT NULL,
`user_id` INT UNSIGNED NOT NULL,
UNIQUE INDEX `unique_activity_user` (`activity_id`, `user_id`)
-- 确保同一个用户不能多次参加同一个活动
);4.4 not null
强制该字段不能存储 null ,插入或更新时,必须为该字段提供一个值。这是保证数据质量最基本、最常用的约束。
sql
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(200) NOT NULL, -- 产品名不能为空
price DECIMAL(10, 2) NOT NULL -- 价格不能为空
);4.5 check
定义一个条件,字段值必须满足这个条件才能被写入。是 MySQL 8.0+ 实现的约束,在老版本中,由于不支持,开发者通常在应用层实现同样的逻辑。
sql
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(100),
salary DECIMAL(10, 2) CHECK (salary > 0), -- 薪水必须大于0
gender CHAR(1) CHECK (gender IN ('M', 'F')) -- 性别只能是 M 或 F
);
-- 也可以定义表级的 CHECK 约束
CREATE TABLE orders (
id INT PRIMARY KEY,
amount DECIMAL(10, 2),
discount DECIMAL(10, 2),
CHECK (amount >= discount) -- 折扣不能大于金额
);4.6 default
当插入新记录时,如果没有为该字段指定值,数据库会自动使用默认值。
sql
CREATE TABLE articles (
id INT PRIMARY KEY,
title VARCHAR(200) NOT NULL,
content TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 默认值为当前时间
views INT DEFAULT 0, -- 默认值为0
is_published BOOLEAN DEFAULT FALSE -- 默认值为 false
);4.7 AUTO_INCREMENT
自增操作,常搭配 primary key 来使用,此时无需手动指定主键值,而是由数据库服务器来分配,从 1 开始依次递增。
AUTO_INCREMENT 并不是标准 MySQL 约束,本质上是引入了一个全局变量,来保存整个列中的最大值,后续分配都是根据这个最大值。
sql
CREATE TABLE categories (
id INT AUTO_INCREMENT PRIMARY KEY, -- 自增主键
name VARCHAR(100) NOT NULL
);5. 多表查询 JOIN
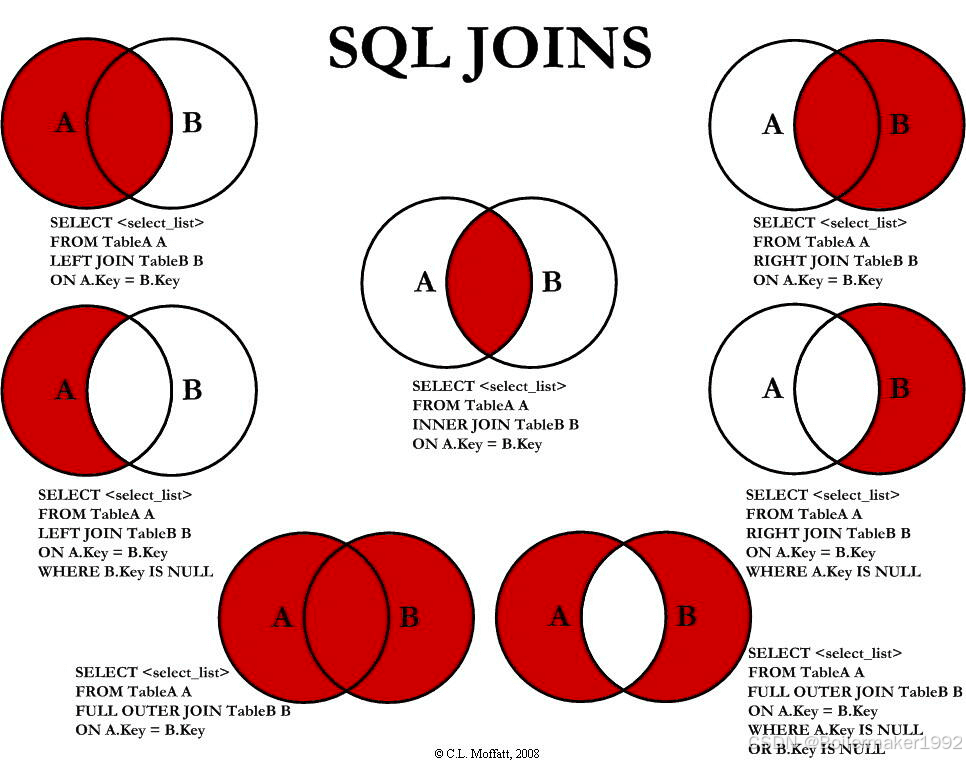
5.1 内连接
两张表进行笛卡尔积,通过这种方式进行行与行之间的比较。设 A 表的行数为 n1,列数为 m1;B 表的行数为 n2,列数为 m2,两表进行笛卡尔积后,会在内存中生成一个行数为 n1 * n2,列数为 m1 + m2 的临时表用于比较。
sql
-- 查询所有下了订单的用户信息
SELECT users.name, orders.order_id, orders.amount
FROM users
INNER JOIN orders ON users.id = orders.user_id;5.2 左外连接
以左侧表为基准,保证左侧表的每行数据都会出现在临时结果中,如果右侧表没有对应数据,则记 null。
sql
-- 查询所有用户及其订单信息,包括没有下过订单的用户
SELECT users.name, orders.order_id, orders.amount
FROM users
LEFT JOIN orders ON users.id = orders.user_id;6. 合并查询
使用 UNION 或 UNION ALL 操作符将多个 SELECT 语句的结果集合并为一个结果集。
如,用户表按地区分成了 users_beijing, users_shanghai, users_guangzhou。现在想找出所有 VIP 用户。
sql
SELECT user_id, user_name FROM users_beijing WHERE is_vip = 1
UNION ALL
SELECT user_id, user_name FROM users_shanghai WHERE is_vip = 1
UNION ALL
SELECT user_id, user_name FROM users_guangzhou WHERE is_vip = 1;合并查询规定:每个 SELECT 语句的列数必须相同。对应位置的列的数据类型必须兼容。最终结果集的列名来自第一个 SELECT 语句。
UNION 会自动去除重复的行,但这个去重开销是比较大的,优先选择 UNION ALL。