这是苍何的第 438 篇原创!
大家好,我是苍何。
太卷了啊。兄弟们。
字节又发布了最新的豆包视觉推理模型,叫 Doubao-Seed-1.6-vision/250815。
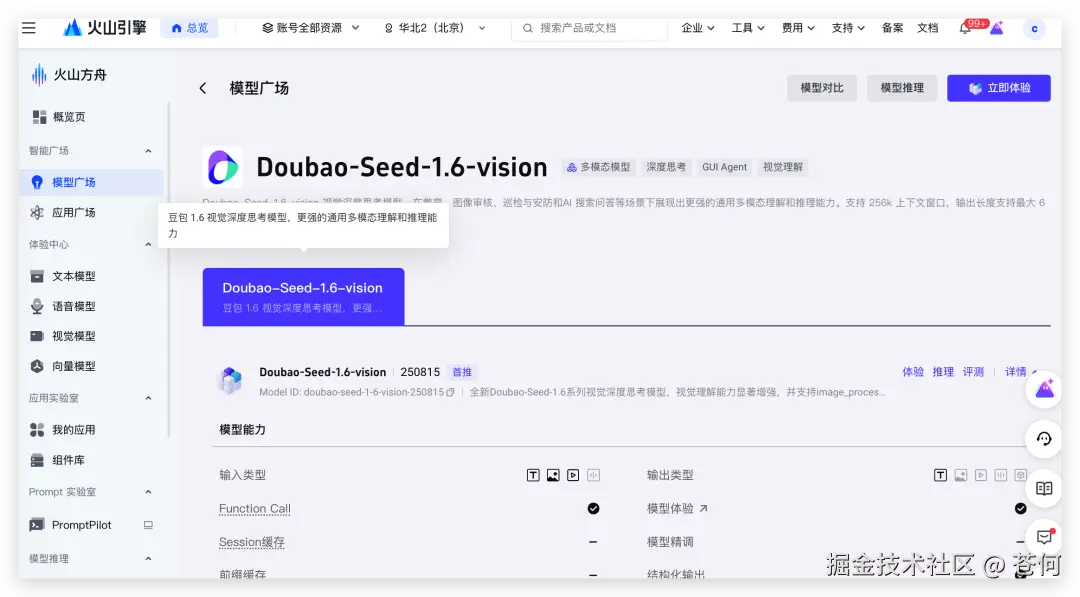
现在火山引擎的模型广场就可以直接看到。
我也进行了深度参与测试,在视觉理解能力上提升很大。
为了方便测试,我接入了 API,并 vibe 了一个测试工具。
代码和使用教程也在 GitHub 上开源了。
在放测试 case 之前,稍微介绍下这个视觉推理模型吧。
Doubao-Seed-1.6-vision 是全新升级的多模态大模型,适用于视频理解、Grounding、GUI Agent等高复杂度的场景,支持 256k 上下文窗口,输出长度支持最大 64k tokens。
最为亮眼的地方在于基于 Responses API 全新支持 image process build-in tools 能力。
也就是最思考推理时能自动调用图像处理工具。目前内置四种图像处理工具,分别是:grounding&crop、point&draw_line、zoom、rotate。
下面来看下几个 case,感受下它的能力吧。
图像旋转
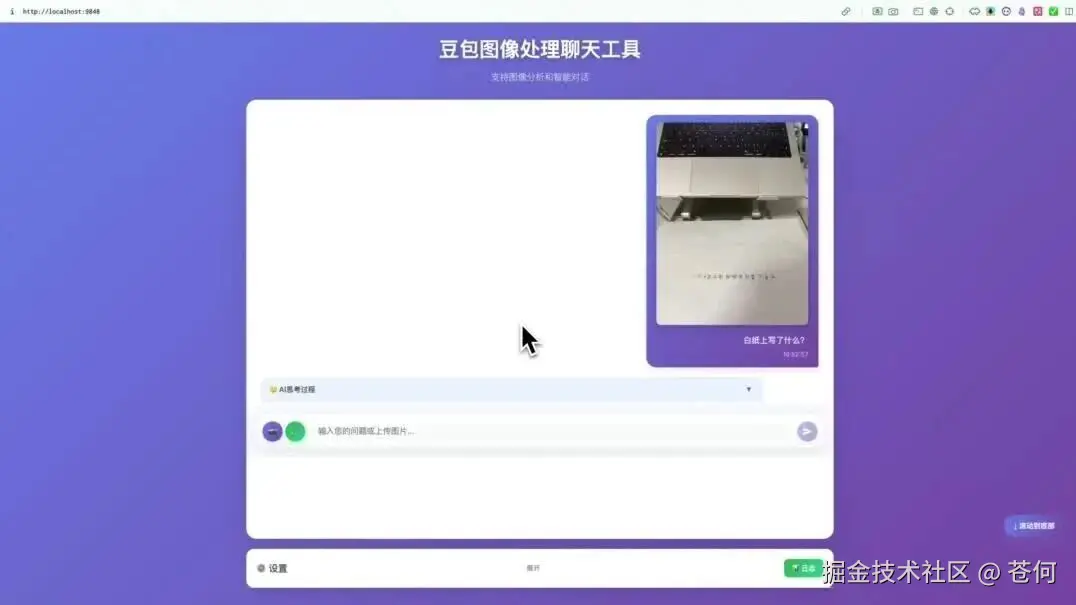
把这个图像丢给 Doubao-Seed-1.6-vision,配合上提示词:
白纸上写了什么?

可以看到,它会思考过程中推理并调用工具rotate自动旋转图片然后做识别。
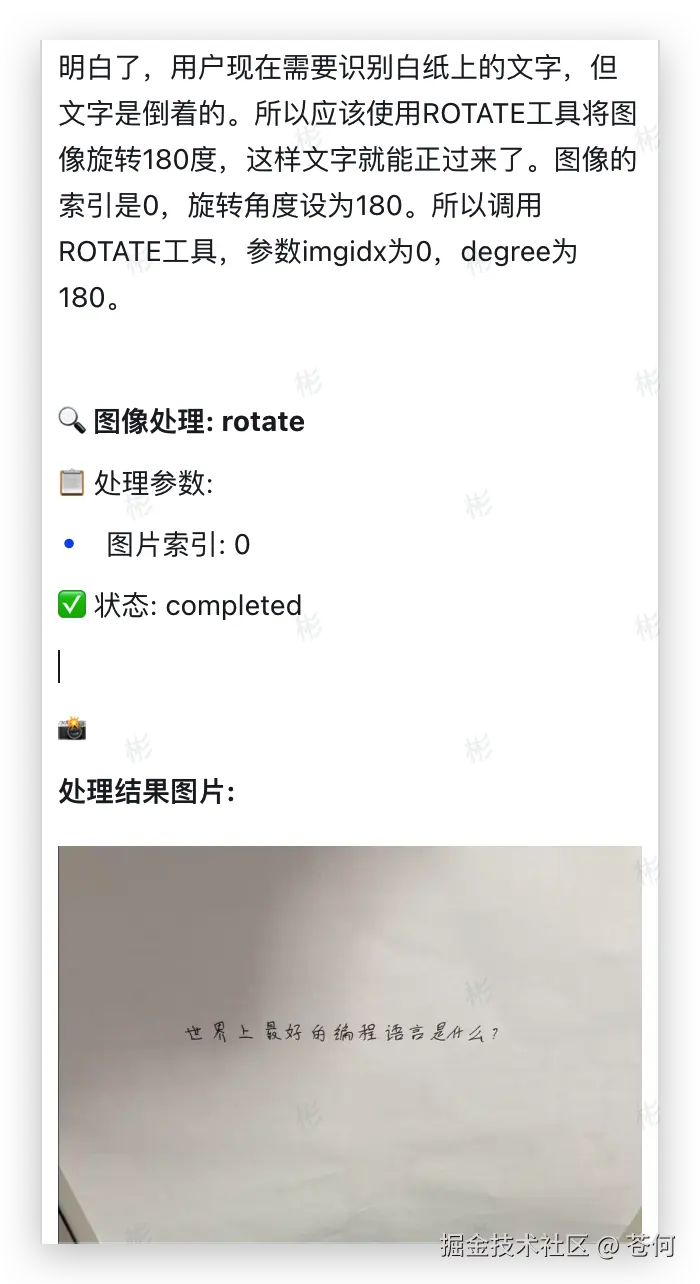
我录了个视频,展示了模型的思考和工具调用全链路。
同样另外一个图像旋转的 case 是用它做书籍识别:
这是我的原始图片:

提示词:桌子上放了什么书?
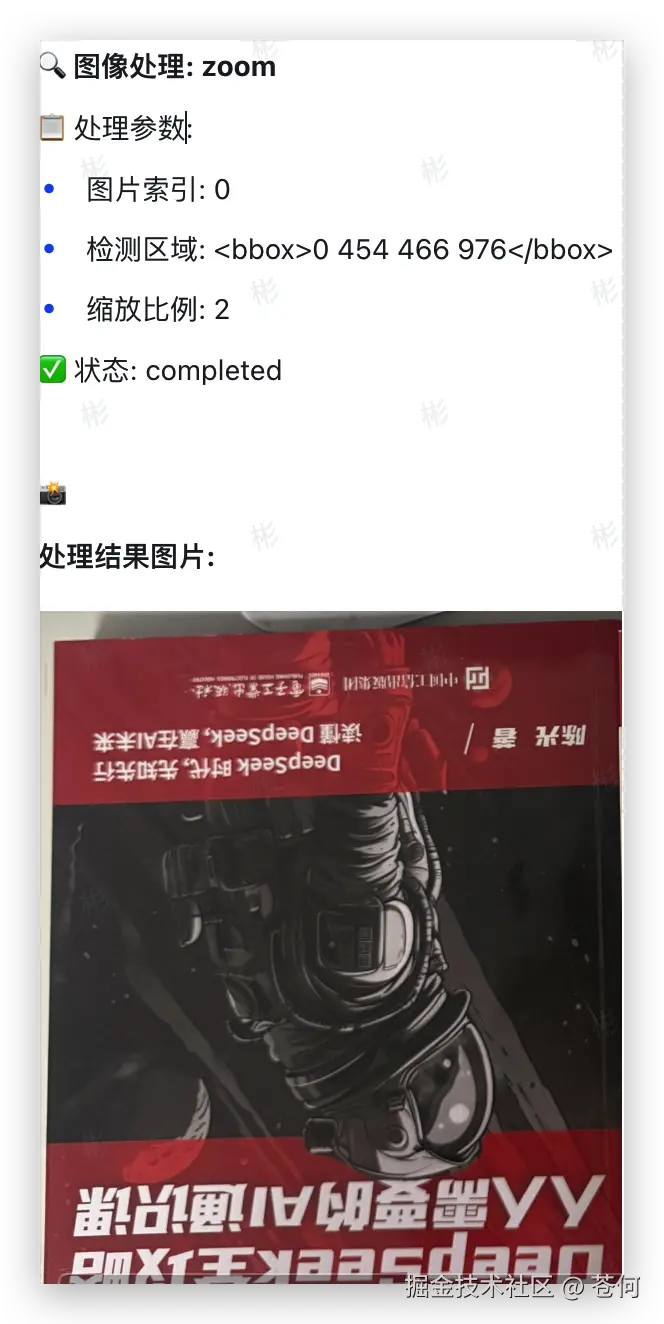
模型先调用zoom工具放大细节:
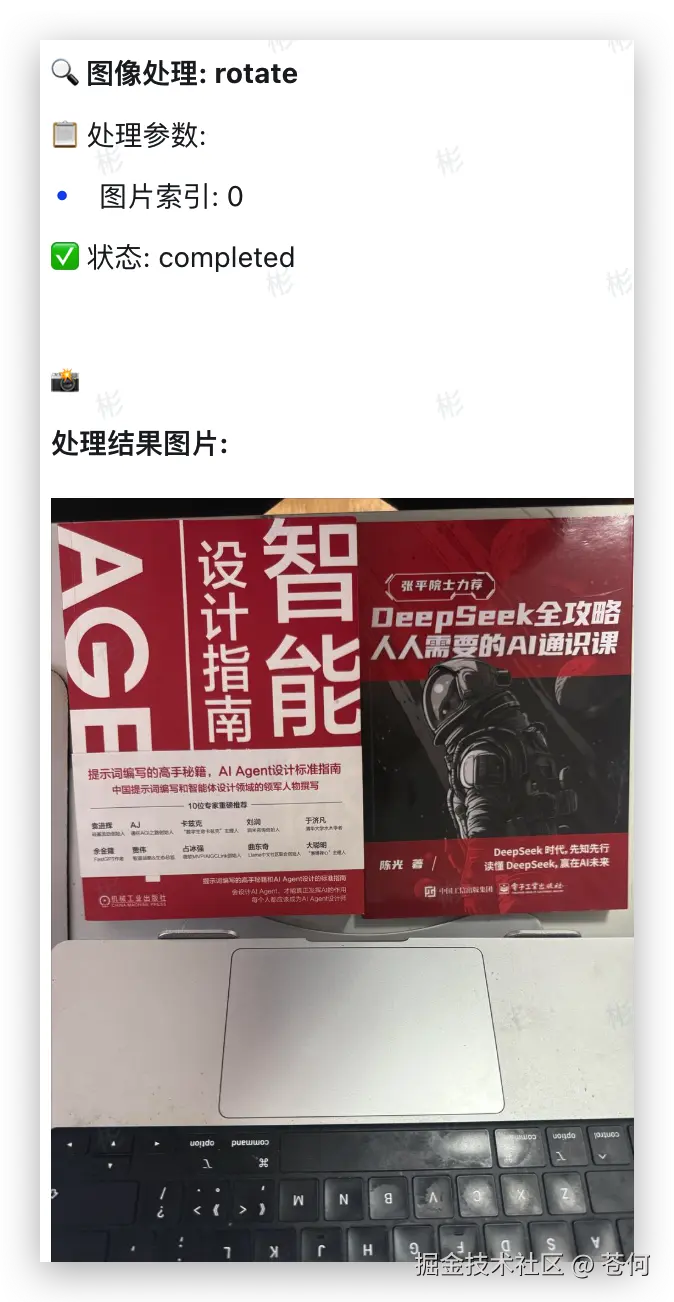
然后调用rotate工具进行图像旋转:
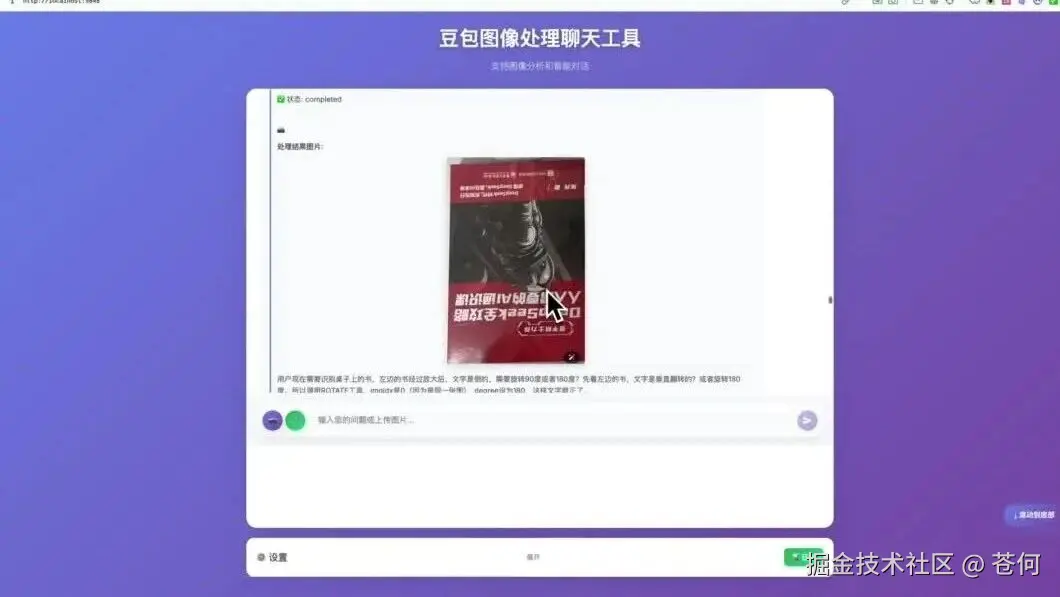
最后推理分析得出结论:

我也录了个全程的视频,大家可以感受一下。
超市找人
这张超市里的图片(素材来自网络),我想让它帮我找下穿绿色上衣的人。

模型会自动调用 zoom 工具放大细节,然后用 point 工具进行标记。
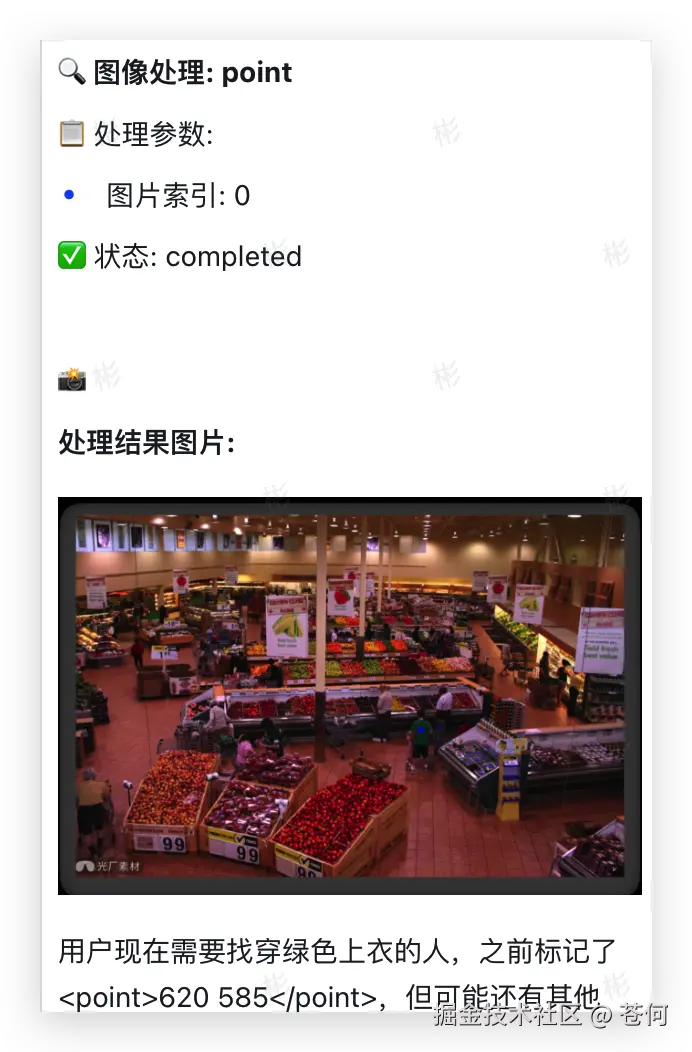
最后精准找到我们需要找的人并做标记,同样全流程视频如下:

清明上河图找人
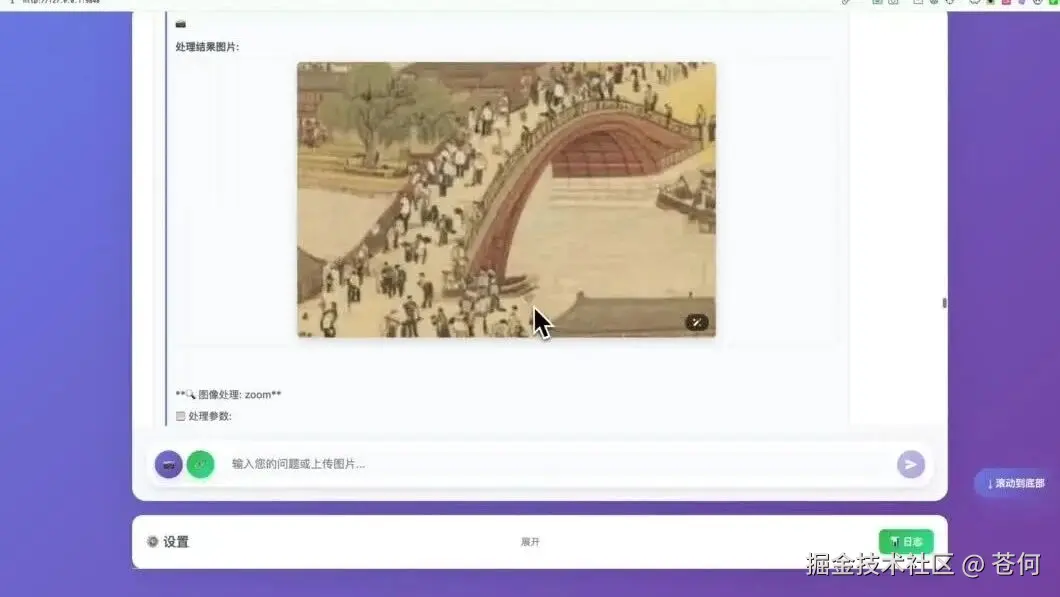
来个非常有挑战的,我们知道清明上河图上有非常多人物,姿势动作各异,要想让大模型在清明上河图上精确找人,还是非常有难度的。

提示词:在这幅《清明上河图》的局部里,帮我找到正在激烈争吵的两个人,并用线连接他们,表示他们正在对话。
本身图片就稍微模糊,要是人来找,估计也得废个半天。
豆包 Doubao-Seed-1.6-vision 先是自动调用zoom工具来进行放大细节
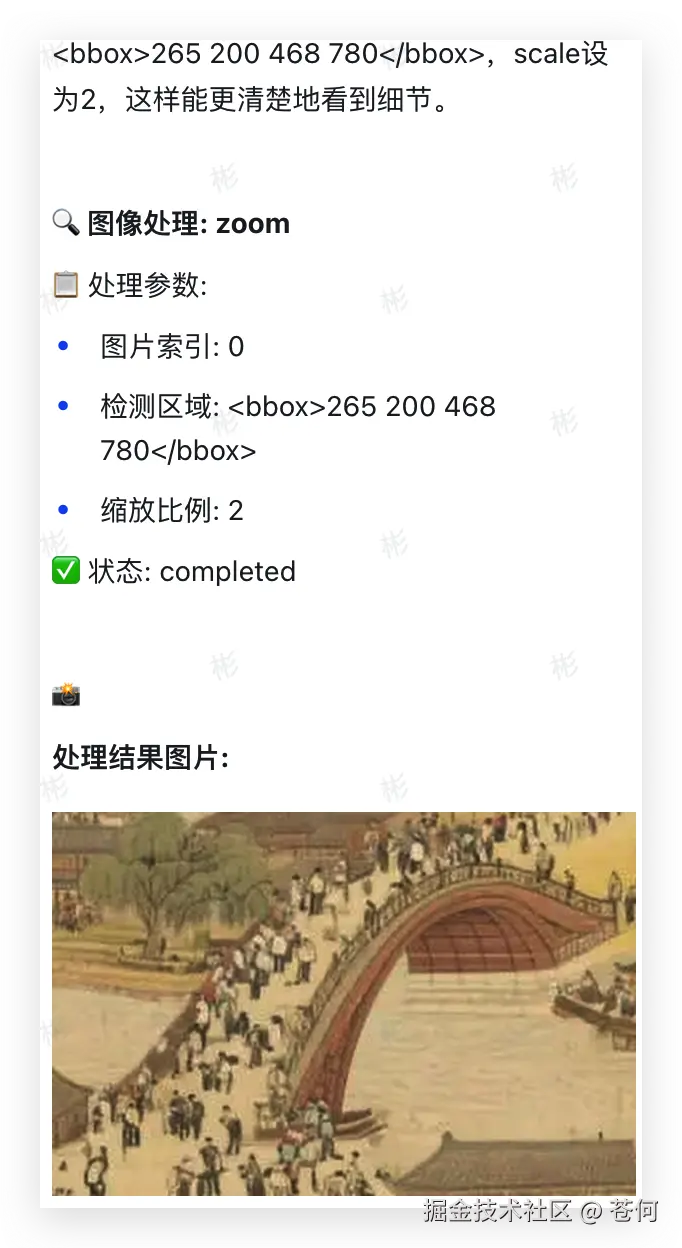
经过多次对比分析,最后找出人物,全流程视频如下:
历史背景不合分析

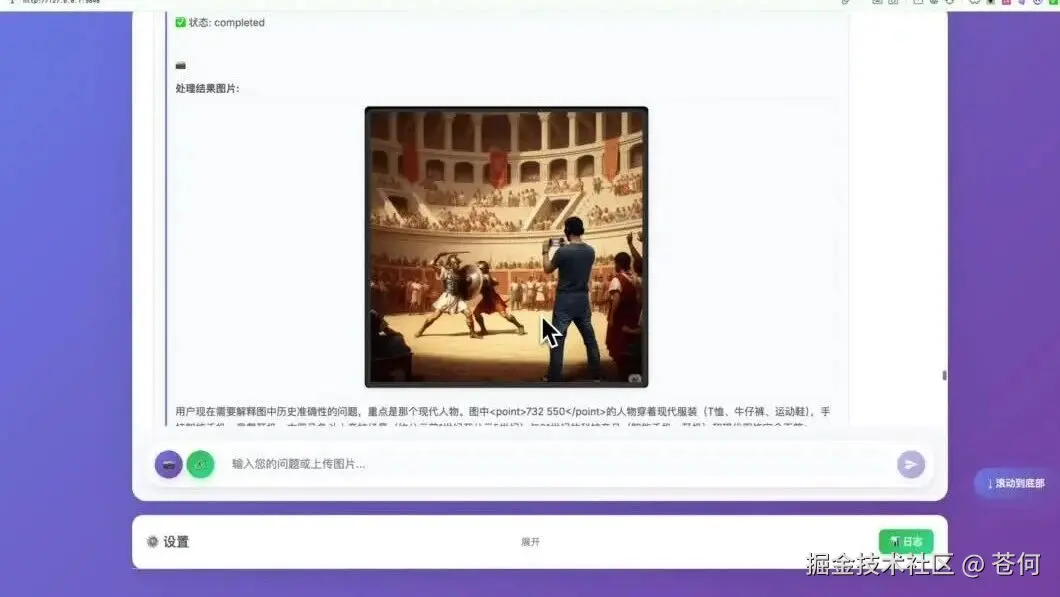
这张图片,让 Doubao-Seed-1.6-vision 分析下不符合常理的地方。
提示词:这张图片描绘的场景在历史准确性上存在什么问题?请解释为什么这个细节不符合历史背景。
它会调用一系列工具,推理分析图片细节,找出不符合的地方。

全过程视频如下:
安全隐患分析
VLM 视觉模型还有个非常实用的场景,就是可以对安全隐患进行分析。

提示词:这张看似平常的家庭照片中,存在哪些潜在的安全隐患?请具体指出危险点,并说明可能导致的后果。以及标注出有隐患的点
模型会调用 point 等工具先进行一轮分析,然后自主推理,根据常识判断是否会有安全隐患。
流程图识别
对于流程图的识别也不在话下。
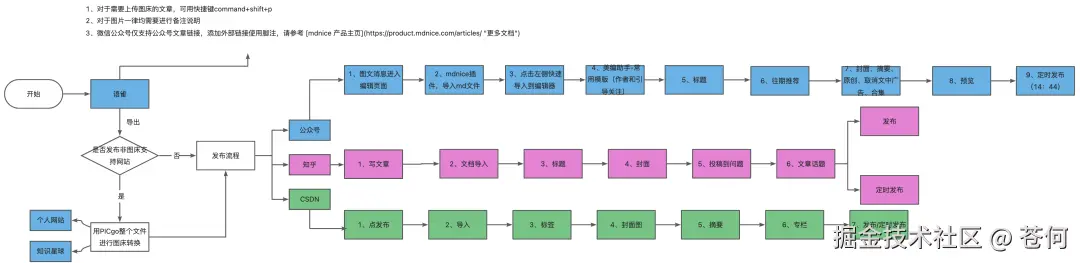
这是我的创作流程,Doubao-Seed-1.6-vision 能很好的别别并给到我反馈。

医疗影像分析
VLM 视觉模型另外一个使用场景就是在对医疗影像进行分析,比如:
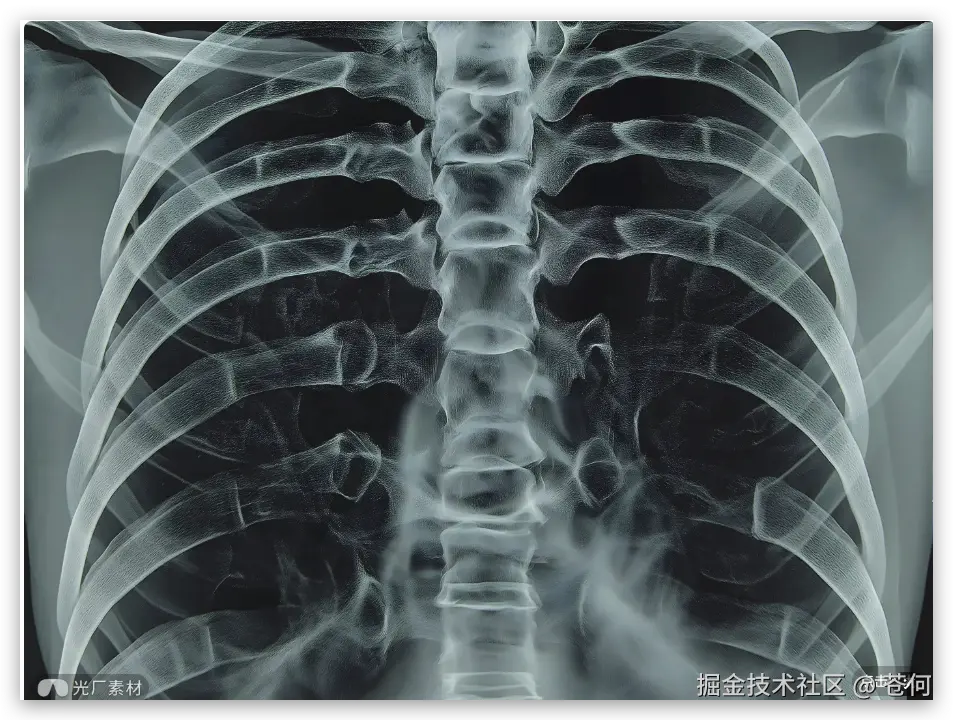
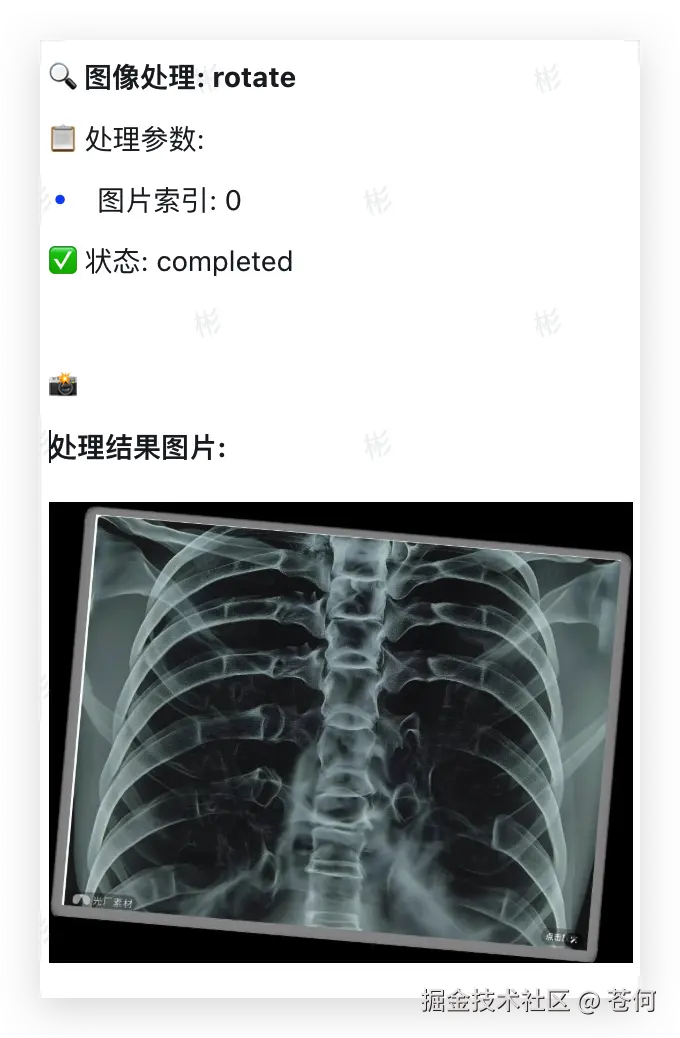
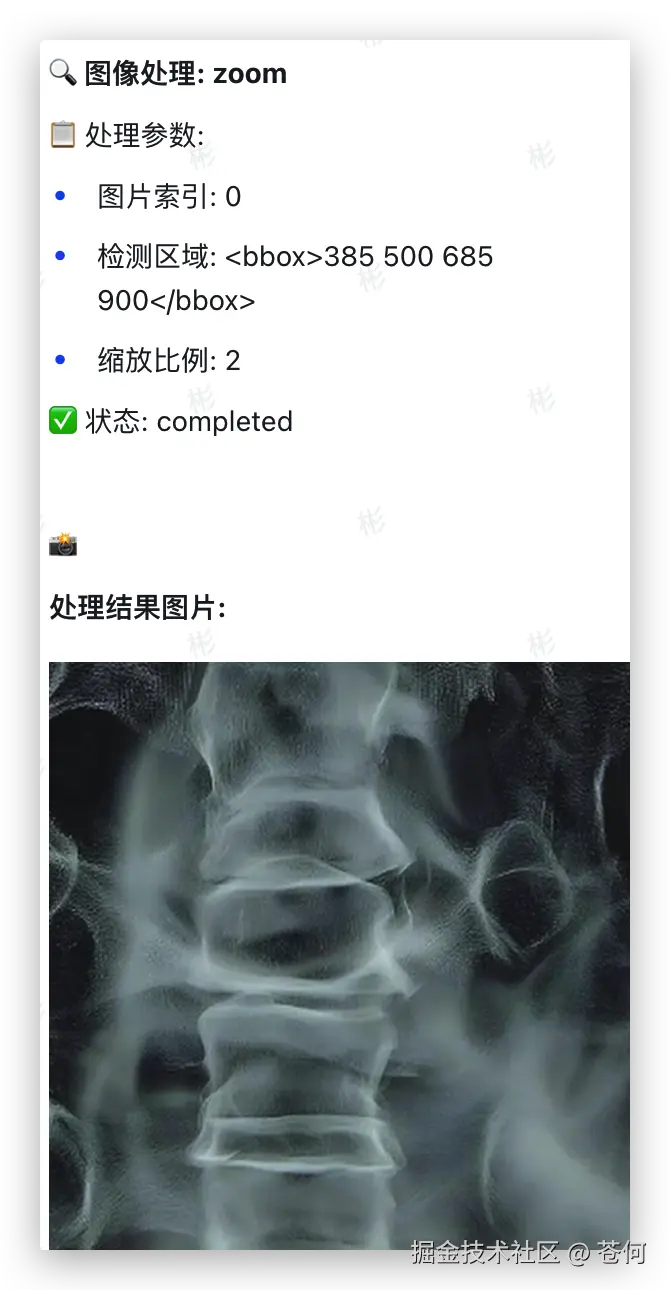
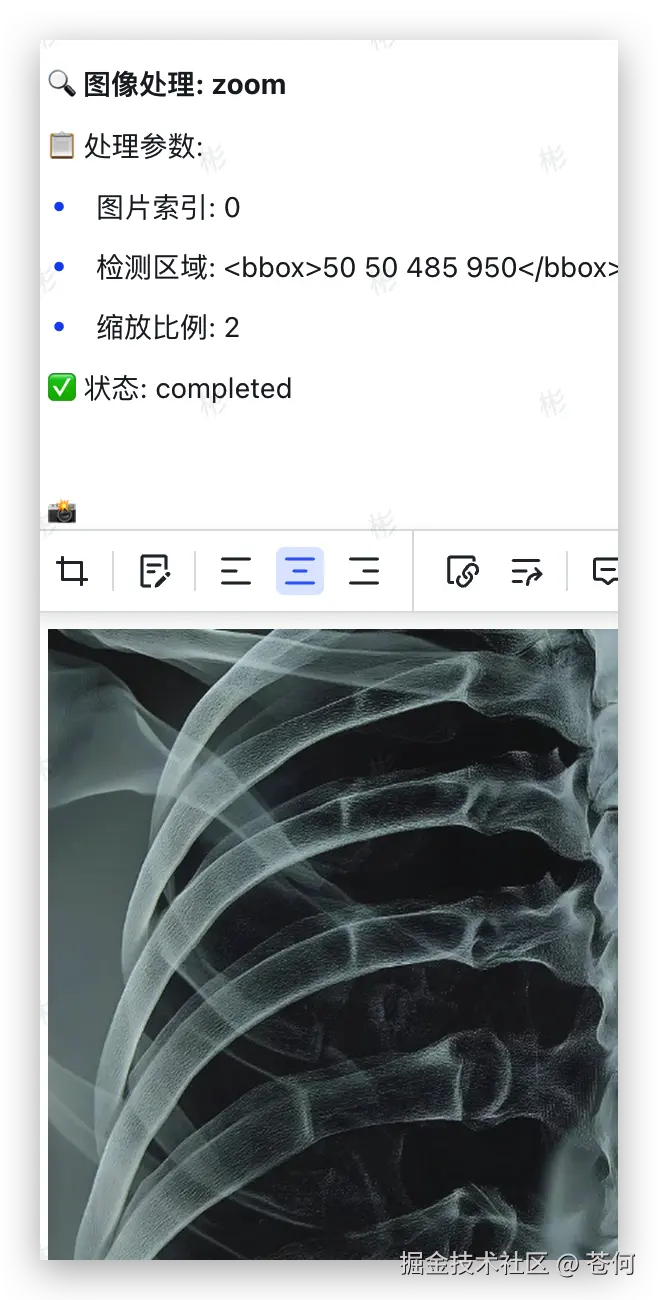
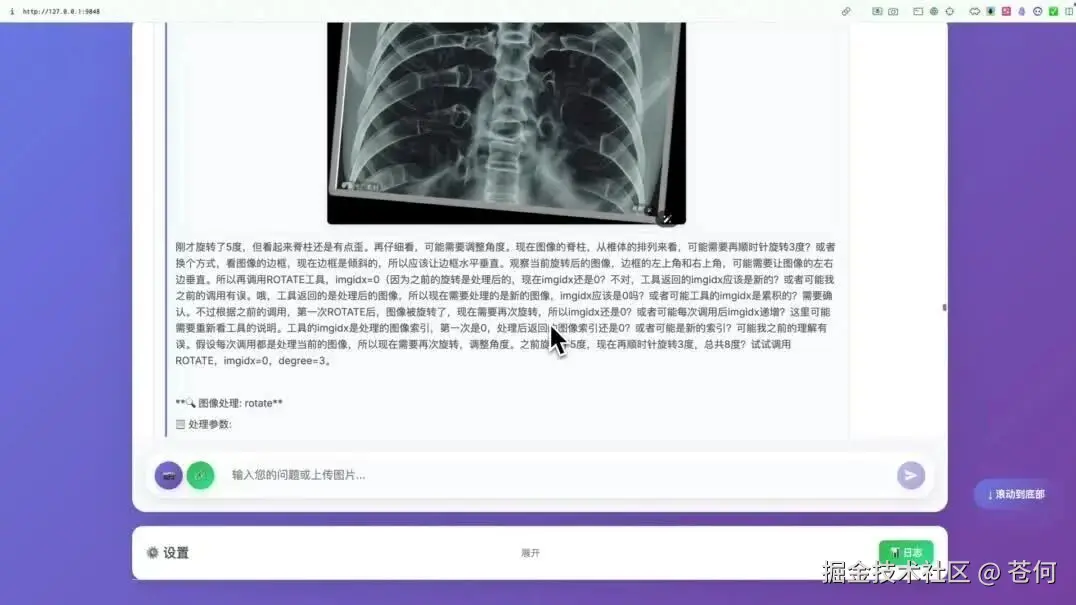
提示词:这是一张胸部X光片,请检查一下肺部是否有异常结节。如果发现可疑区域,请圈出来,并大致测量一下它的最大径。另外,这张片子有点歪,请帮我把它旋转扶正,让脊柱保持垂直,看下效果。
Doubao-Seed-1.6-vision 就会依次自主调用工具,先是调用rotate进行旋转,
然后调用 zoom 工具进行局部多次放大:
视频如下:
影视剧查找
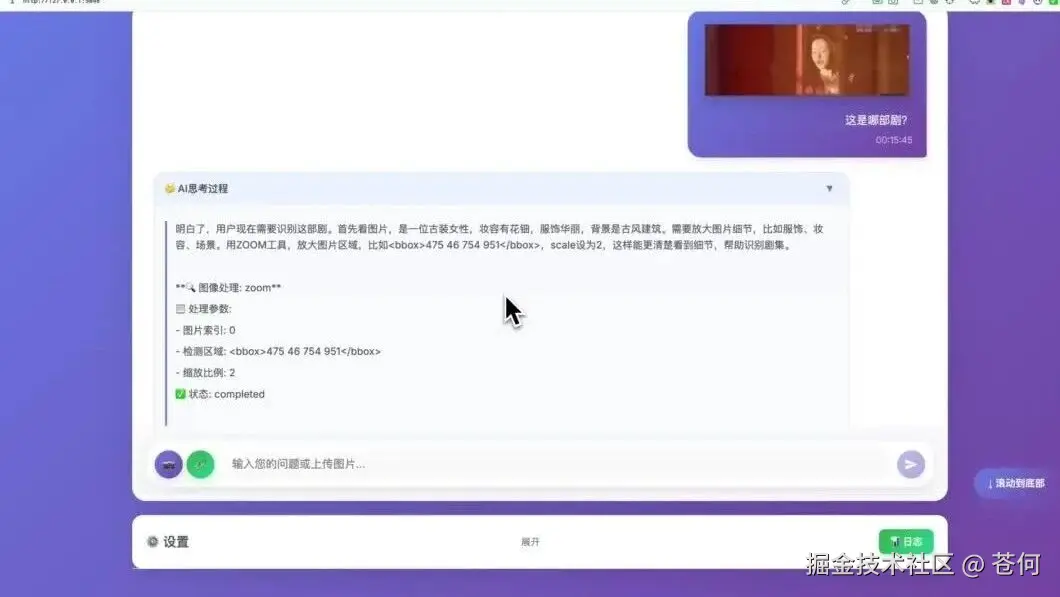
一些精彩的片头,总是想不出是哪部影视剧了,现在就可以借助 Doubao-Seed-1.6-vision 来分析。

提示词:这是哪部剧?
可以看到,它能精确找出影视剧的名字。
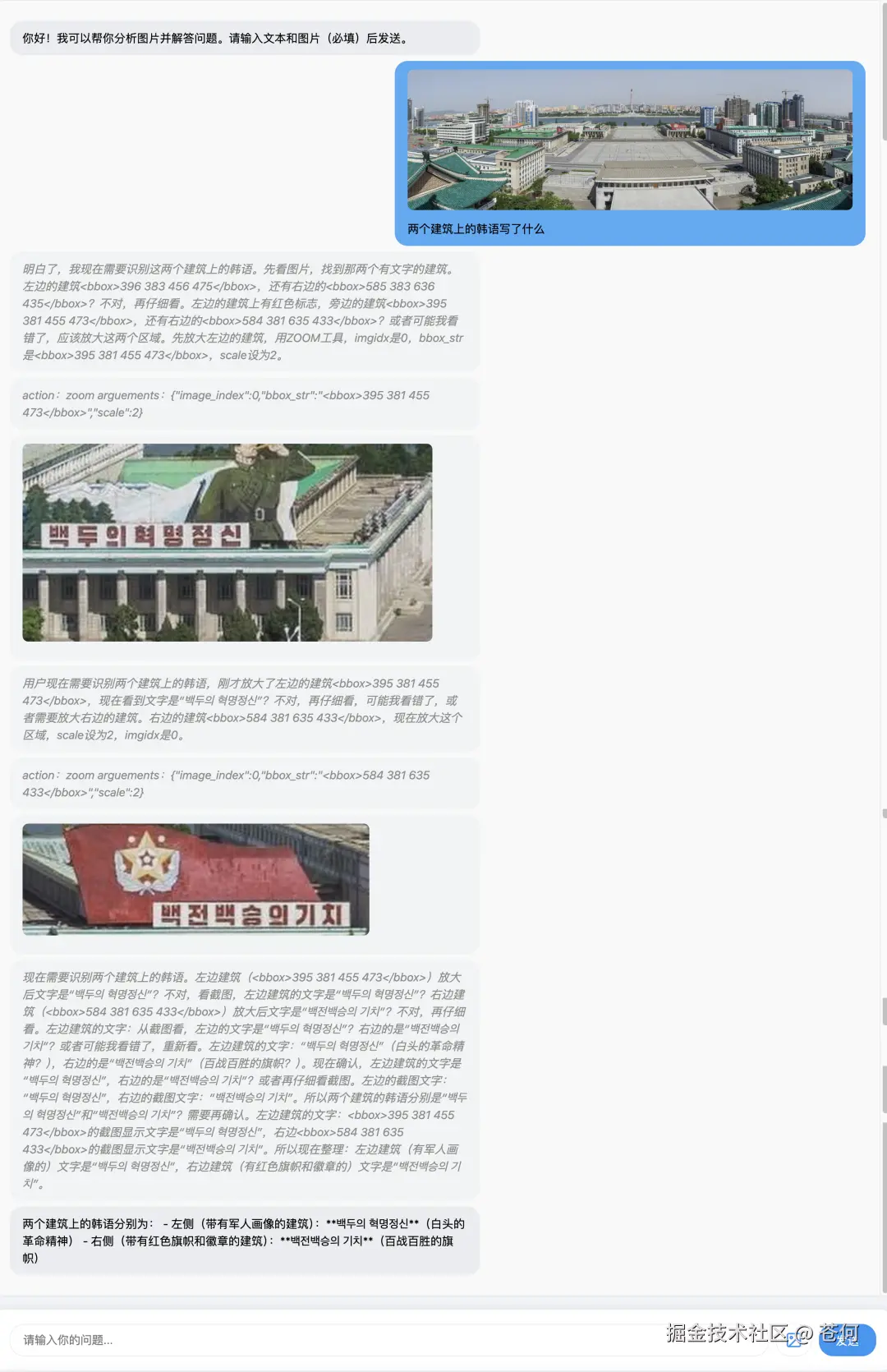
细节感知
这个 case 能看到 Doubao-Seed-1.6-vision 能自动进行图片的放大,并做翻译处理。
当一张照片模糊到看不清的时候,也可以借助 Doubao-Seed-1.6-vision 来进行细节放大。

这一点非常有用,对于放大细节来说,场景可太丰富了。
图例判断
这个 case,考察模型能否根据图片的细节,推理出在哪个城市。

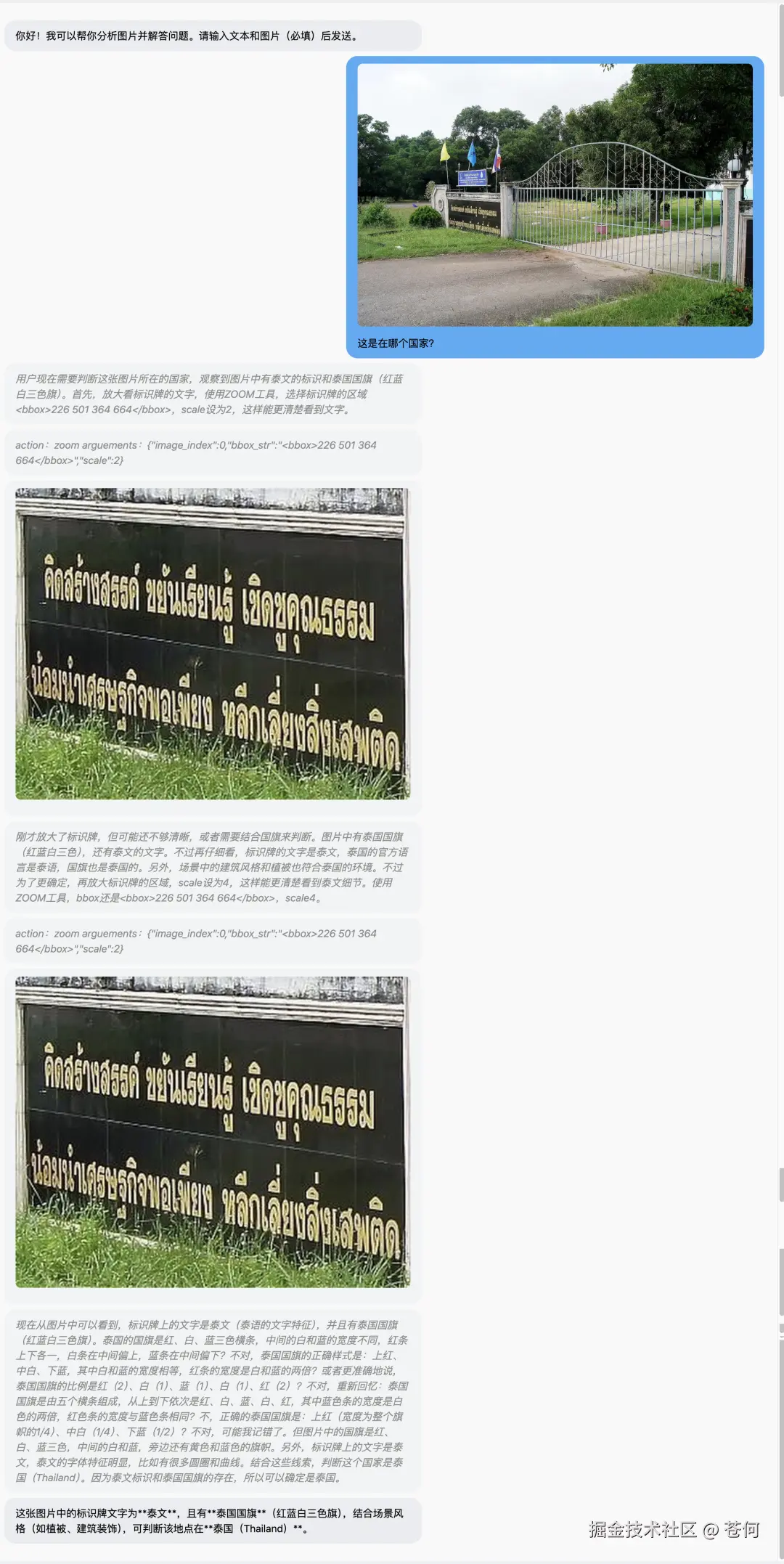
根据标识牌推理在哪个国家。
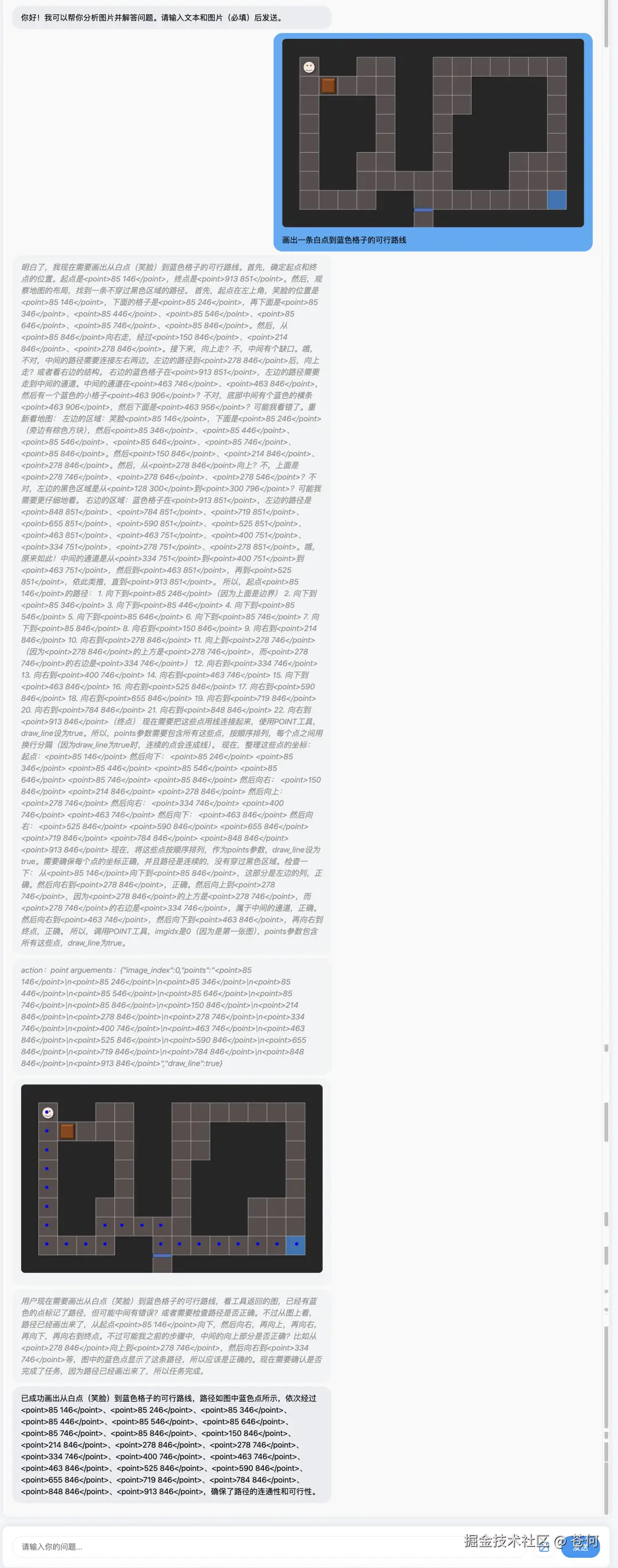
路径选择

多题解答

好了,搞完这些 case,我人直接麻了。
讲真的,AI 的发展速度已经快到让人有点窒息了。
最恐怖的地方在于,它不再是简单地「看懂」图片,而是在「思考」如何更好地去理解。通过调用旋转、缩放、标记这些工具,它就像一个真正的人,在想方设法地解决问题。
从在复杂的《清明上河图》里找人,到分析X光片的细节,这些以前我们想都敢想的场景,现在正一个个变成现实。
我们正处在一个技术爆炸的奇点,每天都有新的可能性诞生。今天我们还在惊叹它能找人,明天它可能就成了我们生活里离不开的眼睛。
这种感觉,真让人无比兴奋。