目录
[2.1 阶段一:最初的尝试(耗时:10分钟)](#2.1 阶段一:最初的尝试(耗时:10分钟))
[2.2 阶段二:第一次飞跃------引入"集装箱"(耗时:2分钟)](#2.2 阶段二:第一次飞跃——引入“集装箱”(耗时:2分钟))
[2.3 阶段三:终极优化------解锁硬件潜能(耗时:20秒)](#2.3 阶段三:终极优化——解锁硬件潜能(耗时:20秒))

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 Kimi开源轻量级中间件checkpoint-engine
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
引言:大模型训练中"等不起"的几分钟
大语言模型训练的"生成-反馈-学习"循环中,万亿级模型存在参数更新瓶颈:数千块GPU完成训练后,需将TB级新参数分发给推理GPU,此过程若耗时10分钟,会造成巨大计算资源空耗。为此,月之暗面工程师开源`checkpoint-engine`中间件,将更新时间从10分钟压缩至20秒,其技术演进与工程智慧值得探究。
一、舞台设定:Kimi独特的"同居"架构
要理解`checkpoint-engine`的设计,首先得了解Kimi的训练架构。他们采用了一种名为"Colocate"(共置)的方案。
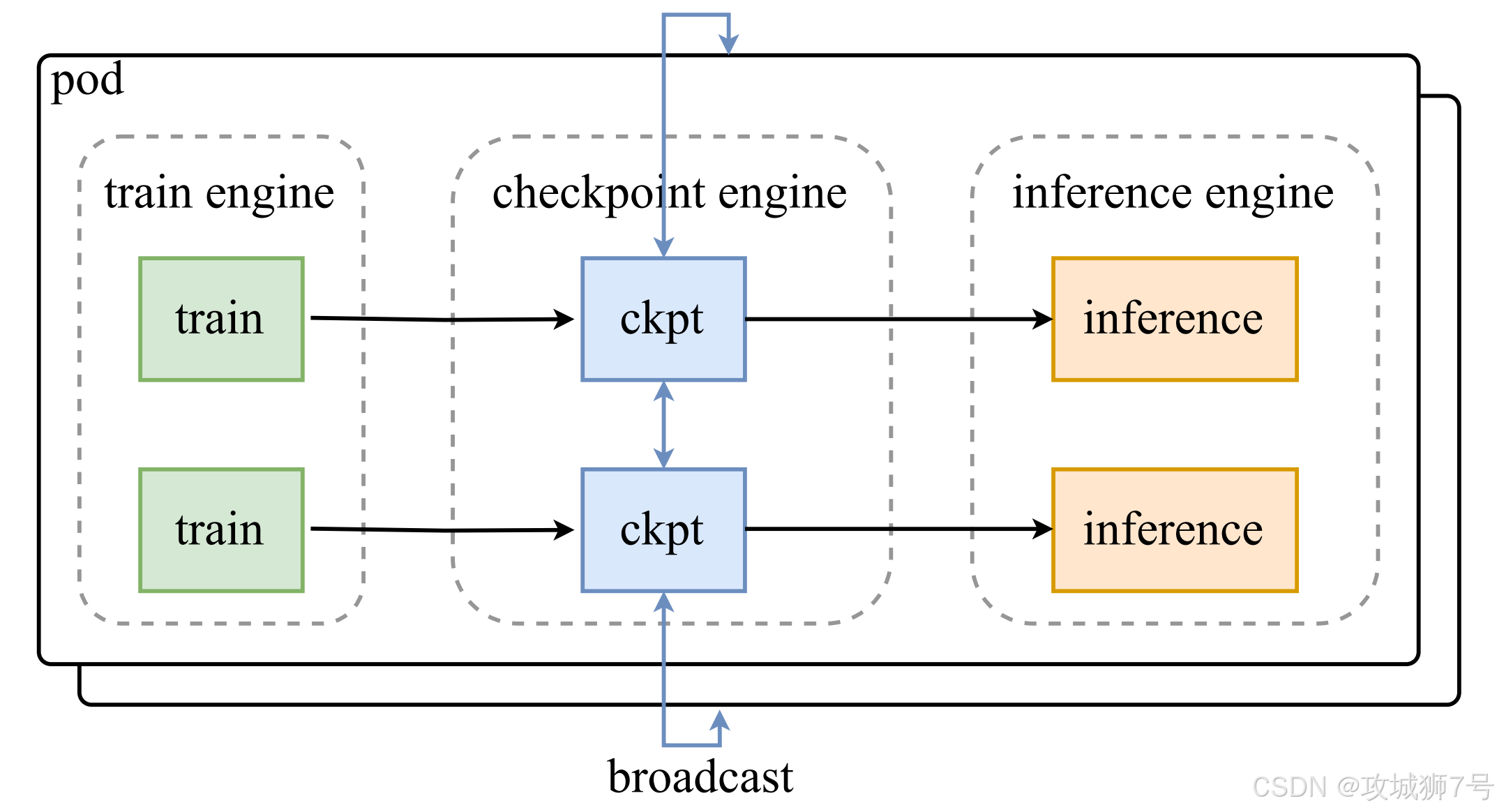
你可以把它想象成"训练引擎"和"推理引擎"这两个室友,共同住在一个装有数千块GPU的"大房子"里。他们轮流使用GPU:推理引擎工作时,训练引擎就"睡觉"释放资源;训练引擎工作时,推理引擎则"下线"等待。
这种"同居"架构的好处是,训练和推理可以完全解耦,各自独立开发、迭代,互不干扰,非常灵活。但也带来了一个棘手的问题:沟通障碍。由于它们被部署在不同的"容器"里,就像住在两个隔音效果极好的独立房间,很难直接感知对方的存在和状态。
当训练引擎完成了学习,想把最新的模型参数递给推理引擎时,就面临一个难题:怎么高效地把这个重达TB级别的文件,在两个"隔音房"之间快速传递?
这就是`checkpoint-engine`诞生的使命:在训练和推理之间,搭建一座高速、轻量的数据桥梁。
有趣的是,Kimi团队在这里做出了第一个重要的工程权衡。理论上,最理想的方案是精确计算出每个推理GPU需要哪一部分参数,然后点对点地精准投递。但这会让整个系统变得异常复杂,对训练和推理引擎的侵入性也极强。
**他们选择了另一条路:"简单粗暴"的全量广播。**即,不管每个推理GPU具体需要什么,干脆把完整的、TB级别的模型参数,一次性广播给集群里的每一块GPU。推理GPU收到后,再自己从中挑出需要的部分。
这听起来似乎很浪费带宽,会发送很多冗余数据。但在H800这样的现代硬件面前,GPU之间高达100GB/s的互联速度,让"全量广播"在10秒内完成成为可能。用一点点可接受的硬件开销,换来工程上的巨大解耦和简洁性,这笔账,很划算。
二、速度进化史:从10分钟到20秒的"填坑"之旅
有了"全量广播"这个大方向,`checkpoint-engine`的优化之路正式开启。这条路并非一帆風順,充滿了挑戰和叠代。
2.1 阶段一:最初的尝试(耗时:10分钟)
最早的版本,思路很直接:把模型参数按"层"或按"专家"(一种MoE模型结构)拆分成一个个小块,然后用CUDA IPC(一种GPU间高效通信技术)逐个传输。
这个方案在模型规模不大时还能应付。但当面对Kimi K2这个万亿参数的庞然大物时,问题就暴露了:
**(1)显存不稳定:**拆分出的小块大小不一,导致更新时显存占用波动剧烈,时常会因为内存溢出(OOM)而崩溃。
**(2)通信效率低下:**成千上万个"小包裹"式的零碎通信,带来了巨大的网络开销。
**(3)序列化开销大:**每个"小包裹"都需要打包成一个IPC Handle,接收方再解包,这个过程本身就耗费了大量时间。
结果就是,在千卡集群上,一次参数更新需要长达10分钟,这显然是无法接受的。
2.2 阶段二:第一次飞跃------引入"集装箱"(耗时:2分钟)
针对上述问题,团队进行了第一次关键优化,核心思想是:化零为整。
**他们不再发送无数个"小包裹",而是引入了"Bucket"(桶)的概念。**可以把它想象成一个固定大小的"集装箱"。所有零碎的参数,先被统一装进这个"集装箱"里,直到装满为止。然后,`checkpoint-engine`一次性广播整个"集装箱"。
同时,他们还优化了IPC机制。 不再为每个小块都创建一次性的IPC Handle,而是在一开始就创建一个共享的、可复用的"双份集装箱"(双Buffer),并把它们的"钥匙"(IPC Handle)一次性交给推理引擎。之后,训练引擎和推理引擎就通过这两个共享的"集装箱"来传递数据,一个用于装载,一个用于读取,交替进行,形成了两阶段流水线。
这次优化的效果是立竿见影的:
(1)显存占用变得稳定可控。
(2)消除了大量小通信的开销。
(3)大大降低了序列化和反序列化的负担。
通过这一系列操作,参数更新时间从10分钟骤降到了2分钟。这是一个巨大的进步,但工程师们知道,距离硬件的理论极限(约10秒)还有很大差距。
2.3 阶段三:终极优化------解锁硬件潜能(耗时:20秒)
经过分析,团队发现新的瓶颈在于H2D(Host-to-Device)拷贝,也就是数据从CPU内存拷贝到GPU显存的这个步骤。
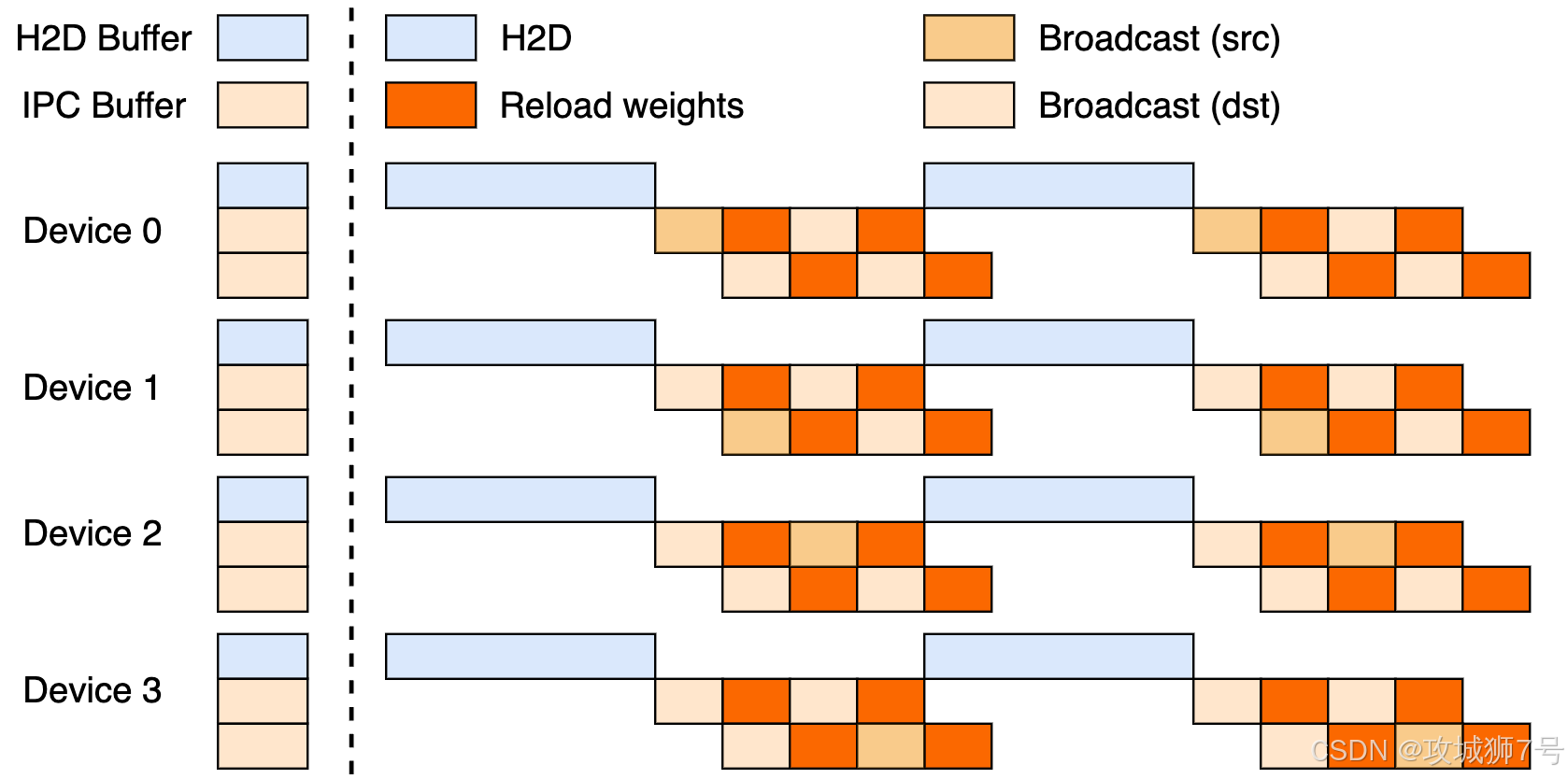
在之前的方案里,虽然实现了流水线,但数据流是这样的:某一块GPU先把一"桶"数据从CPU内存拷贝到自己的显存(H2D),然后再通过高速网络广播给其他所有GPU。这意味着,整个集群的广播速度,被这一块GPU的PCIe总线速度给限制住了。这就好比一个庞大的车队,无论有多少辆车,都必须排队通过一个狭窄的收费站,速度自然快不起来。
于是,终极优化方案诞生了:并行H2D。
与其让大家等一个"收费站",不如让每辆车都在自己的出发点先把货物装好。具体操作是:
**(1)并行预热:**所有GPU节点同时从各自的CPU内存执行H2D操作,将参数加载到自己的显存中。这相当于把整个集群的总PCIe带宽都利用了起来,装载速度大大提升。
**(2)高速广播:**当需要广播时,数据已经在各个GPU的显存里了。此时只需一次极快的D2D(Device-to-Device)拷贝,将数据从预热区放到广播"集装箱"里,然后通过高速的NVLink或网卡进行广播。
这个方案,将原本串行的"H2D -> 广播"流水线,变成了"并行H2D -> D2D -> 广播"的全新模式。它彻底打破了单点PCIe带宽的瓶颈。
经过这一轮优化,加上对推理引擎(vLLM)内部一些细节(如缓存、避免GPU-CPU同步)的打磨,Kimi K2万亿模型的参数更新时间,最终稳定在了20秒。
三、不止于快:故障自愈与启动加速
`checkpoint-engine`的价值远不止于提升训练效率,它还带来了两个非常实用的"副作用"。
(1)推理引擎的故障自愈: 在长时间的强化学习中,某个推理节点偶尔发生故障是在所难免的。过去,这可能导致整个任务崩溃。现在,借助`checkpoint-engine`的P2P(点对点)更新模式,可以实现"在线热修复"。当一个节点重启后,它可以不打扰其他正在运行的节点,而是直接从某个健康节点的CPU内存中,通过RDMA(一种高速网络传输技术)拉取最新的模型参数到自己的GPU中,然后重新加入工作。整个过程只需约40秒,大大增强了大规模训练的稳定性。
**(2)推理服务的启动加速:**通常,启动一个推理服务需要从硬盘加载庞大的模型文件,这个过程非常缓慢。利用`checkpoint-engine`,现在可以"两条腿走路":一边让推理服务以"假"的空模型(dummy)快速启动,完成自身的初始化;另一边,让`checkpoint-engine`在后台异步地从硬盘加载真正的模型参数。等到两边都准备就绪,直接触发一次20秒的参数更新,服务就能立即上线。这极大地缩短了服务的冷启动时间,提升了资源利用效率和用户体验。
结语:开源背后的工程哲学
**`checkpoint-engine`的故事,是现代大模型领域工程实践的一个缩影。**它告诉我们,通往极致性能的道路,往往不是靠单一的、革命性的算法,而是源于对系统瓶颈的深刻洞察、一系列循序渐进的优化,以及在复杂约束下做出明智权衡的工程智慧。
从最初选择"全量广播"的简洁方案,到后来通过"分桶"、"流水线"、"并行H2D"等手段不断逼近硬件极限,再到衍生出故障自愈和启动加速等实用功能,Kimi团队展示了如何在追求理论性能的同时,兼顾系统的解耦、稳定性和易用性。
最终,他们选择将这个打磨成熟的核心工具开源,与社区共享。这不仅是对vLLM等开源社区的回馈,也为所有从事大模型工程实践的开发者们,提供了一套宝贵的、经过实战检验的"方法论"。在AI飞速发展的今天,正是这样务实而卓越的工程能力,在为宏大的模型梦想,铺设着坚实可靠的前行之路。
参考链接:
https://x.com/Kimi_Moonshot/status/1965785427530629243
https://github.com/MoonshotAI/checkpoint-engine
https://arxiv.org/abs/2507.20534
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!