文章目录
- 1.引言
- 2.工作原理
-
- [2.1 线程分工:核心线程与辅助线程](#2.1 线程分工:核心线程与辅助线程)
- [2.2 单线程的核心优势:天然的线程安全](#2.2 单线程的核心优势:天然的线程安全)
- 3.单线程支撑高并发的原因
-
- [3.1 纯内存操作,规避磁盘 IO 瓶颈](#3.1 纯内存操作,规避磁盘 IO 瓶颈)
- [3.2 精简的核心功能,减少冗余开销](#3.2 精简的核心功能,减少冗余开销)
- [3.3 单线程模型,消除线程竞争成本](#3.3 单线程模型,消除线程竞争成本)
- [3.4 IO 多路复用,突破单线程连接限制](#3.4 IO 多路复用,突破单线程连接限制)
-
- [3.4.1 IO 多路复用的本质:"一个线程监听多个连接"](#3.4.1 IO 多路复用的本质:“一个线程监听多个连接”)
- [3.4.2 select/poll/epoll的核心差异](#3.4.2 select/poll/epoll的核心差异)
- [3.4.3 Redis 的 IO 处理流程(简化版)](#3.4.3 Redis 的 IO 处理流程(简化版))
- 4.小结
1.引言
提起高并发系统,多数人会默认 "多线程是最优解",但 Redis 却用单线程模型支撑起每秒数万次的请求处理。这种 "反常识" 的设计并非偶然 ------ 它既规避了多线程的竞争开销,又通过 IO 多路复用等技术弥补了单线程的天然局限。本文将从单线程工作原理出发,拆解其高效的核心逻辑,剖析潜在风险,并解读最新的多线程演进方向。
2.工作原理
Redis 的 "单线程" 并非指服务器进程仅含一个线程,而是核心的命令执行逻辑由单个线程串行处理。这种设计既保证了数据一致性,又简化了底层实现。
2.1 线程分工:核心线程与辅助线程
Redis 服务器进程包含多个线程,但职责划分明确,核心逻辑与辅助操作完全分离:
- 核心线程(主线程):负责处理客户端命令请求(如get/set)、执行数据读写操作、解析命令语法 ------ 这是 Redis "单线程模型"的核心载体,所有命令执行严格串行,不存在并发竞争。
- 辅助线程:负责耗时的非核心操作,不参与命令执行,例如:
- 网络 IO 相关线程:处理 TCP 连接建立、数据接收与发送的底层 IO 操作(部分版本引入,减轻主线程负担);
- 后台线程:执行 AOF 日志重写、RDB 持久化、大 Key 删除等耗时任务,避免阻塞主线程;
- 集群相关线程:处理节点心跳检测、数据同步等集群维护操作。
这种分工让主线程聚焦于 "短平快" 的命令处理,将耗时操作剥离到辅助线程,完美平衡了 "单线程的简洁性" 与 "多线程的高效性"。
2.2 单线程的核心优势:天然的线程安全
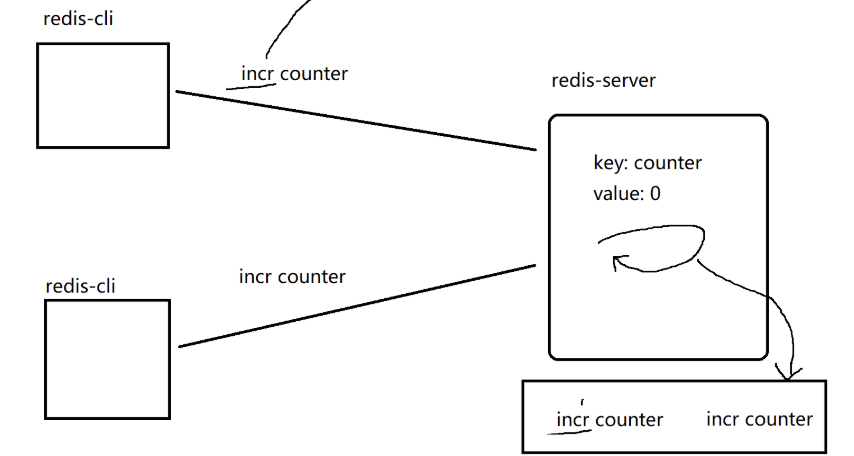
在多线程场景下,如果两个线程同时对一个变量自增,不加锁的情况下,实际可能只自增了一次。因为当a线程将这个变量写入寄存器时,可能时间片刚好用完了,轮到b线程把这个变量写入寄存器,修改后再写回内存,之后a线程继续执行,然后把结果写回内存,实际只进行了一次自增。
而 Redis 的单线程模型从根源上解决了该问题:
所有命令按 "先来后到" 的顺序串行执行,同一时刻仅处理一个请求;
不过单线程也有缺点,就是要小心某个操作占用时间长而阻塞其他命令的执行。比如前面的keys* 这种要扫描全量数据的操作。
3.单线程支撑高并发的原因
3.1 纯内存操作,规避磁盘 IO 瓶颈
这是 Redis 与 MySQL、Oracle 等关系型数据库最本质的区别:
- Redis:所有数据存储在内存中,内存读写速度可达 100GB/s 以上,命令执行仅需 "内存寻址 - 数据操作"
两个步骤,耗时通常在纳秒级; - 关系型数据库:数据主要存储在磁盘,磁盘读写速度仅为 100MB/s 左右,且需经历 "磁盘寻址 - 数据加载到内存 - 操作 -写回磁盘" 等步骤,耗时在毫秒级(是内存操作的 10 万倍以上)。
3.2 精简的核心功能,减少冗余开销
关系型数据库需支撑复杂的功能特性,如:
- 事务 ACID 特性(尤其是持久化与隔离级别的实现);
- 复杂查询优化(多表关联、子查询、索引选择);
- 数据一致性保障(外键约束、触发器)。
这些功能虽强大,但也带来了大量冗余开销。而 Redis 聚焦 "键值对存储" 核心需求,仅保留必要功能:
- 事务仅支持 "弱一致性"(不满足隔离性),实现简单;
- 无复杂查询语法,命令直接映射到底层数据结构操作;
- 无外键、触发器等约束,数据处理流程极简。
功能的精简让 Redis 的命令执行路径极短,避免了不必要的计算开销。
3.3 单线程模型,消除线程竞争成本
多线程模型的性能损耗主要来自 "线程切换" 与 "锁竞争":
- 线程切换:操作系统切换线程时需保存 / 恢复上下文(寄存器、栈信息等),每次切换耗时约 10 微秒,高频切换会严重拖累性能;
- 锁竞争:为保证线程安全,需引入互斥锁、读写锁等机制,线程等待锁时会进入阻塞状态,进一步降低效率。
Redis 的单线程模型完全规避了这些损耗
3.4 IO 多路复用,突破单线程连接限制
单线程的天然局限是 "无法同时处理多个 IO 请求"------ 若一个客户端连接占用线程等待数据,其他客户端会被阻塞。而 Redis 通过IO 多路复用机制,让单线程可同时管理数万甚至数十万客户端连接。
3.4.1 IO 多路复用的本质:"一个线程监听多个连接"
IO 多路复用的核心思想是:由内核监听多个 socket(客户端连接)的 IO 事件(可读 / 可写),当某个 socket 的事件就绪时(如客户端发送数据),内核通知应用程序处理,处理完成后继续监听其他 socket。
这就像 "一个接线员同时监听多个电话线路":哪个线路有通话请求就接哪个,接完后继续监听,无需为每个线路配一个接线员。Redis 通过封装ae事件处理器模块,根据操作系统自动选择最优的多路复用实现:
- Linux 系统:优先使用epoll(性能最优);
- macOS/BSD 系统:使用kqueue;
- 其他系统:兼容使用select/poll。
3.4.2 select/poll/epoll的核心差异
Linux 提供的三套 IO 多路复用 API,性能差距显著,Redis 选择epoll是提升并发能力的关键:
| 特性 | select | poll | epoll |
|---|---|---|---|
| 存储结构 | 固定大小数组 | 动态数组 | 共享内存(mmap) |
| 轮询方式 | 遍历所有注册 socket(O (N)) | 遍历所有注册 socket(O (N)) | 回调通知就绪 socket(O (1)) |
| 连接数限制 | 默认≤1024 | 无限制,但受系统资源约束 | 无限制,支持数十万连接 |
| 数据拷贝 | 每次调用拷贝用户态→内核态 | 每次调用拷贝用户态→内核态 | 共享内存,无需拷贝 |
| 触发模式 | 水平触发(重复通知) | 水平触发(重复通知) | 支持水平触发 / 边缘触发(仅通知一次) |
| 性能 | 低(适用于少量连接) | 中(适用于中量连接) | 高(适用于高并发连接) |
3.4.3 Redis 的 IO 处理流程(简化版)
-
监听连接:主线程通过epoll注册所有客户端 socket 的可读事件;
-
等待就绪:调用epoll_wait等待事件就绪,此时主线程阻塞(但不消耗 CPU);
-
处理事件 :epoll返回就绪的 socket 列表,主线程依次处理:
读取客户端发送的命令(如get key);
解析命令并执行数据操作(内存级操作,极快);
将结果写回客户端(注册可写事件,就绪后发送);
-
循环监听:处理完所有就绪事件后,回到步骤 2,继续等待下一批事件。
4.小结
Redis 的单线程模型是 "场景适配" 的经典设计 ------ 针对 "高频、简单、内存级" 的键值对操作,单线程的简洁性与高效性远超多线程。其核心逻辑可归纳为:
- 核心命令串行执行,保证线程安全;纯内存操作 + IO 多路复用,支撑高并发基础
- 耗时操作剥离到后台线程;复杂查询引入多线程执行,突破性能瓶颈
- 规避阻塞操作,保持核心命令 "短平快";监控线程状态,及时发现性能问题