引言:Epoch------模型训练的隐形调节器
在深度学习模型训练中,Epoch(轮次)是一个看似简单却影响深远的超参数。它决定了模型遍历整个训练数据集的次数,直接影响模型的收敛速度、泛化能力以及计算成本。然而,Epoch的设置并非简单的"越多越好"或"越少越省",而是需要在训练效率 、任务性能 和泛化能力之间找到微妙的平衡。
本文将系统探讨Epoch的作用机制、选择策略及其与数据规模、训练方法的协同效应,并结合实际案例分析如何优化Epoch设置,以实现模型性能的最大化。
一、Epoch的核心作用:从数据遍历到模型收敛
1.1 Epoch的数学定义与物理意义
一个Epoch表示模型完整遍历一次训练数据集的过程。假设数据集包含N个样本,批量大小(Batch Size)为B,则一个Epoch包含的迭代次数为:
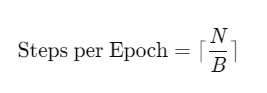
Epoch的数量(T)决定了模型训练的总轮次,而总训练步数(T×Steps per Epoch)则决定了参数更新的总次数。
物理意义:Epoch反映了模型对数据分布的"学习深度"。较少的Epoch可能导致模型欠拟合(未充分学习数据规律),而过多的Epoch则可能引发过拟合(模型过度记忆训练数据中的噪声)。
1.2 Epoch与模型收敛的关系
模型的收敛过程通常分为三个阶段:
- 快速下降期:初始Epoch中,损失函数迅速下降,模型快速学习主要特征。
- 缓慢优化期:中间Epoch中,损失下降速度减缓,模型精细调整参数。
- 过拟合风险期:后期Epoch中,训练损失继续下降,但验证损失可能上升,模型开始记忆噪声。
关键问题:如何确定Epoch的"甜点"(Sweet Spot),即在验证损失开始上升前停止训练?
二、Epoch的选择策略:数据规模与训练目标的协同
2.1 数据规模对Epoch的影响
数据规模是决定Epoch数量的核心因素之一。根据经验法则:
| 数据规模 | 推荐Epoch范围 | 典型值 | 理由 |
|---|---|---|---|
| 小数据(<1K样本) | 10-50 | 15-30 | 需更多轮次充分学习,但需防过拟合 |
| 中等数据(1K-10K样本) | 5-20 | 8-15 | 平衡收敛速度与泛化能力 |
| 大数据(>10K样本) | 1-10 | 2-5 | 少量轮次即可收敛,过多易过拟合 |
案例分析:
- 在100条数据的场景下,Epoch=15可使模型充分学习(每个样本被处理约15次)。
- 在10,000条数据的场景下,Epoch=2即可达到类似效果(每个样本被处理约0.2次)。
2.2 训练目标对Epoch的约束
场景1:注重基座模型通用能力(小数据+LoRA)
- 策略:优先使用LoRA(低秩适应)等轻量级微调方法,配合中等Epoch(如10-20)。
- 理由:LoRA通过约束参数更新范围,减少对基座模型的干扰,适合小数据场景。
- 风险:Epoch过多可能导致基座模型的通用NLP能力退化。
场景2:注重任务特定效果(大数据+全量更新)
- 策略:使用全量更新,配合低Epoch(如1-5)。
- 理由:大数据本身已提供足够信息,少量轮次即可收敛。
- 风险:Epoch过多可能导致任务特定效果饱和,甚至退化。
场景3:平衡通用与特定能力(混合数据)
- 策略:将通用数据与任务数据混合,采用中等Epoch(如5-15)。
- 理由:混合数据可缓解过拟合,同时保持基座模型的泛化能力。
- 案例:某用户场景中,混合数据后Epoch=10的综合效果优于纯任务数据的Epoch=5。
三、Epoch的风险与应对策略
3.1 过高的Epoch:过拟合与能力遗忘
风险表现:
- 训练损失持续下降,但验证损失上升(过拟合)。
- 基座模型的通用NLP能力下降(如问答、摘要等任务性能退化)。
应对策略:
- 早停机制(Early Stopping):监控验证损失,当连续N个Epoch无改进时停止训练。
- 正则化约束:添加L2正则化、Dropout或标签平滑,减缓过拟合速度。
- 数据增强:对小数据场景,通过回译、同义词替换等方式扩充数据。
案例:某文本分类任务中,Epoch=30时验证准确率开始下降,通过早停(Patience=5)将Epoch控制在25,避免过拟合。
3.2 过低的Epoch:欠拟合与收敛不足
风险表现:
- 训练损失与验证损失均未充分下降。
- 模型在简单任务上表现不佳(如分类准确率低于随机基准)。
应对策略:
- 增加Epoch:逐步提升Epoch,观察损失曲线变化。
- 学习率调整:配合学习率预热或动态调整,加速收敛。
- 模型复杂度提升:若欠拟合持续存在,可能需增加模型容量(如层数、宽度)。
案例:某图像分类任务中,Epoch=5时模型准确率仅60%,提升至Epoch=15后准确率升至85%。
3.3 数据真实性对Epoch的影响
关键问题:若数据存在重复或低多样性,高Epoch会加剧过拟合。
验证方法:
- 数据去重:检查训练集与验证集的重复样本比例。
- 多样性评估:计算类别分布、句长分布等指标。
- 交叉验证:使用K折交叉验证确认模型稳定性。
案例:某用户提供1000条数据,实际为100条数据的10次重复,导致Epoch=20时模型在验证集上过拟合严重。经去重后,Epoch=10即可稳定收敛。
四、Epoch的优化实践:从理论到落地
4.1 动态Epoch调整策略
策略1:基于验证损失的早停
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
monitor='val_loss',
patience=5, # 连续5个Epoch无改进则停止
restore_best_weights=True
)
model.fit(X_train, y_train,
validation_data=(X_val, y_val),
epochs=100,
callbacks=[early_stopping])策略2:学习率-Epoch协同调整
结合OneCycle策略,在Epoch中期降低学习率以精细调整:
from torch.optim.lr_scheduler import OneCycleLR
scheduler = OneCycleLR(
optimizer,
max_lr=0.01,
epochs=20, # 总Epoch数
steps_per_epoch=len(train_loader)
)4.2 混合数据场景的Epoch配置
场景:通用数据(90%)+ 任务数据(10%)。
策略:
- 分阶段训练 :
- 第一阶段:仅通用数据,Epoch=5(预热基座模型)。
- 第二阶段:混合数据,Epoch=10(任务适配)。
- 加权采样:对任务数据赋予更高采样概率(如2倍)。
效果:某对话系统通过此策略,在保持通用对话能力的同时,任务特定响应准确率提升12%。
五、未来方向:自适应Epoch与终身学习
5.1 基于模型状态的动态Epoch
未来优化器可能实时评估模型状态(如梯度范数、损失曲率),动态调整Epoch:
- 若梯度稳定下降,增加Epoch。
- 若梯度开始震荡,减少Epoch并触发早停。
5.2 终身学习中的Epoch管理
在持续学习场景下,Epoch需适应数据流的动态变化:
- 新数据到达时,短暂增加Epoch以快速适配。
- 旧数据遗忘时,减少Epoch以避免灾难性遗忘。
5.3 硬件协同的Epoch优化
结合新型加速器(如TPU、光子芯片)的特性,设计Epoch-硬件协同策略:
- 高吞吐硬件可支持更高Epoch,但需防过拟合。
- 低功耗硬件需优化Epoch以减少能耗。
结语:Epoch------在效率与泛化间寻找平衡
Epoch作为模型训练的"时间控制器",其设置需综合考虑数据规模、训练目标、模型架构和硬件资源。通过动态调整策略、混合数据训练和早停机制,可在保证泛化能力的同时最大化任务性能。未来,随着自适应优化算法和终身学习框架的发展,Epoch的选择将更加智能化,真正实现"按需训练"的愿景。
实践建议:
- 从小数据场景开始,优先测试Epoch=10-20的范围。
- 结合验证损失曲线和早停机制,避免手动设置的盲目性。
- 在混合数据场景下,分阶段配置Epoch以平衡通用与特定能力。
Epoch的优化没有终极答案,但通过系统实验和理论分析,我们可以不断逼近这个动态平衡的"甜点"。