"AI 函数计算三大件:神经网络、损失函数、优化器"
------ 这是对现代深度学习系统最核心、最本质的三位一体抽象。
这三者共同构成了一个完整的可学习函数系统,缺一不可。
我们来系统、深入、精准地解析这"三大件"的角色、数学本质、协同机制与典型实现。
🌟 一句话总结
- 神经网络 :模型的数学函数形式(fθ(x)fθ(x))
- 损失函数 :希望的模型的输出与某个最小化的目标的数学函数形式(L(y,fθ(x))L(y,fθ(x)))
- 优化器 :你用来更新模型中数学函数中的参数的算法的数学函数形式(如 SGD, Adam)
三者协同,完成**"从数据中自动学习一个有用函数"的全过程**。
一、第一大件:神经网络(Neural Network)------"你要学什么?"
✅ 角色:函数假设空间(Hypothesis Space)
-
它定义了所有可能的输入到输出 的映射形式。
-
形式化表示为:
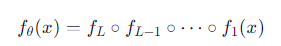
其中 θ 是模型参数(权重 W、偏置 b 等)。
✅ 核心功能
- 特征提取 :从原始输入(如像素)中自动学习有用表示
- 非线性建模 :通过激活函数(ReLU, Sigmoid)逼近复杂函数
✅ 典型架构
| 类型 | 代表 | 适用任务 |
|---|---|---|
| MLP | 全连接网络 | 分类、回归 |
| CNN | ResNet, VGG | 图像识别 |
| RNN/LSTM | 序列模型 | 语音、文本 |
| Transformer | BERT, GPT | 语言建模、生成 |
🔍没有神经网络,就没有"可学习的函数"。
二、第二大件:损失函数(Loss Function)------"你想要什么?"
✅ 角色:学习目标的数学表达
- 衡量模型预测 fθ(x) 与真实标签 y 的差距。
- 目标:最小化损失 L
✅ 数学形式
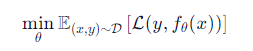
✅ 常见损失函数
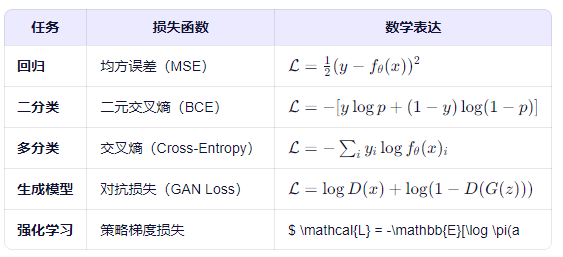
| 任务 | 损失函数 | 数学表达 |
|---|---|---|
| 回归 | 均方误差(MSE) | L=12(y−fθ(x))2L=21(y−fθ(x))2 |
| 二分类 | 二元交叉熵(BCE) | L=−ylogp+(1−y)log(1−p)L=−ylogp+(1−y)log(1−p) |
| 多分类 | 交叉熵(Cross-Entropy) | L=−∑iyilogfθ(x)iL=−∑iyilogfθ(x)i |
| 生成模型 | 对抗损失(GAN Loss) | L=logD(x)+log(1−D(G(z)))L=logD(x)+log(1−D(G(z))) |
| 强化学习 | 策略梯度损失 | $ \mathcal{L} = -\mathbb{E}[\log \pi(a |
🔍 没有损失函数,模型就"不知道什么是好,什么是坏"。
三、第三大件:优化器(Optimizer)------"你怎么学?"
✅ 角色:参数更新的引擎
- 根据损失函数的梯度,调整神经网络的参数 θ
- 实现:梯度下降及其变种
✅ 更新通式
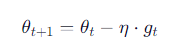
其中:
- η:学习率
- gt:梯度估计(可能带动量、自适应等)
按照某种规则(梯度降低的方向)逐步逼近(一次逼近修正所有的W,B值)的思想,直到逼近到最小值!!!
✅ 常见优化器对比
| 优化器 | 核心思想 | 优点 | 缺点 |
|---|---|---|---|
| SGD | 标准梯度下降 | 简单、稳定 | 收敛慢,易陷局部最优 |
| SGD + 动量 | 引入速度项,加速方向一致的梯度 | 加快收敛,减少震荡 | 需调参 |
| Adam | 自适应学习率 + 动量 | 收敛快,适合大多数任务 | 可能泛化略差 |
| RMSProp | 自适应学习率(按参数调整) | 适合非平稳目标 | 逐渐被 Adam 取代 |
| AdaGrad | 累积历史梯度调整步长 | 适合稀疏数据 | 学习率衰减过快 |
🔍 没有优化器,模型就"学不动"。
四、三者协同工作流程(完整闭环)
选择输入数据 x, 标签 y
↓
[神经网络] f_θ(x) → 预测输出 ŷ
↓
[损失函数] ℒ(y, ŷ) → 计算误差
↓
[反向传播] ∇ℒ/∇θ → 计算梯度
↓
[优化器] θ ← θ - η·g → 更新参数
↓
重复以上过程,直到收敛🔄 这是一个闭环的函数学习系统。
五、类比:三者如同"造车三要素"
| AI 三大件 | 类比:汽车系统 | 说明 |
|---|---|---|
| 神经网络 | 车身与发动机结构 | 决定了车能跑多快、能载多少 |
| 损失函数 | GPS 导航系统 | 告诉你"离目标还有多远" |
| 优化器 | 驾驶员 + 控制系统 | 根据导航反馈,踩油门/刹车,调整方向 |
🚗 没有车,无法移动;没有导航,不知方向;没有驾驶员,车不会自己走。
六、进阶理解:三者如何影响模型性能?
| 因素 | 影响 |
|---|---|
| 网络结构不当 | 欠拟合(容量不足)或过拟合(容量过大) |
| 损失函数设计差 | 模型学不到真正重要的东西(如分类任务用 MSE 效果差) |
| 优化器选择不当 | 训练不稳定、收敛慢、陷入局部最优 |
✅ 实践建议:
- 先选合适的损失函数(任务决定)
- 再设计网络结构(数据复杂度决定)
- 最后调优优化器(Adam 通常是安全起点)
✅ 总结:AI 函数计算三大件
| 组件 | 数学角色 | 工程角色 | 关键选择 |
|---|---|---|---|
| 神经网络 | 函数形式 fθ(x) | 特征提取器、表示学习 | CNN, RNN, Transformer |
| 损失函数 | 目标函数 L(y,y^) | 学习信号生成器 | MSE, CrossEntropy, BCE |
| 优化器 | 参数更新规则 | 梯度利用引擎 | Adam, SGD, RMSProp |
🎯 最终洞见
深度学习不是魔法,而是一个"目标驱动的函数构造工程"。
- 神经网络提供"可能性",
- 损失函数定义"方向",
- 优化器执行"行动"。
三者合一,才实现了从数据中自动涌现智能的奇迹。
你抓住了最核心的骨架------
掌握这"三大件",就掌握了深度学习的命脉。