一、模型介绍
DeepSeek-OCR 是深度求索(DeepSeek)于 2025 年 10 月 20 日开源的一款革命性 OCR 模型,其核心创新在于提出 上下文光学压缩 (Contexts Optical Compression)技术,通过视觉模态实现文本信息的高效压缩与解压。该模型以 3B 参数量实现了 SOTA 级性能,按照官方的说法,单张 A100-40G 显卡日处理能力超 20 万页数据,这为长文本处理和大模型优化提供了全新范式。
DeepSeek-OCR 采用 端到端视觉语言模型(VLM)架构 ,由两大核心组件构成:
1.DeepEncoder(视觉编码器)
专为高分辨率输入设计,通过 "局部感知 + 全局语义" 的双塔结构实现高效压缩:
SAM-base(80M 参数) :采用窗口注意力机制,提取图像局部细节(如文本位置、字体),避免全局注意力的高内存消耗。输入 1024×1024 图像时,生成 4096 个 16×16 的 Patch Token。
CLIP-large(300M 参数) :移除首个 Patch 嵌入层,接收前序输出 Token,通过密集全局注意力整合压缩后的视觉信息,提炼文档布局、文本逻辑等全局语义。
16 倍卷积压缩器 :在 SAM 与 CLIP 之间,通过两层 3×3 卷积(步长 2)将 4096 个 Token 压缩至 256 个,大幅减少后续计算量。此设计使模型在 1024×1024 分辨率下激活内存可控。
2.DeepSeek3B-MoE 解码器
基于混合专家架构(MoE),推理时仅激活 64 个路由专家中的 6 个及 2 个共享专家,实际激活参数约 5.7 亿。该设计在保持 3B 模型表达能力的同时,实现了 500M 小模型的推理效率(8.2 页 / 秒,A100 显卡),支持从压缩后的视觉 Token 中重建原始文本。
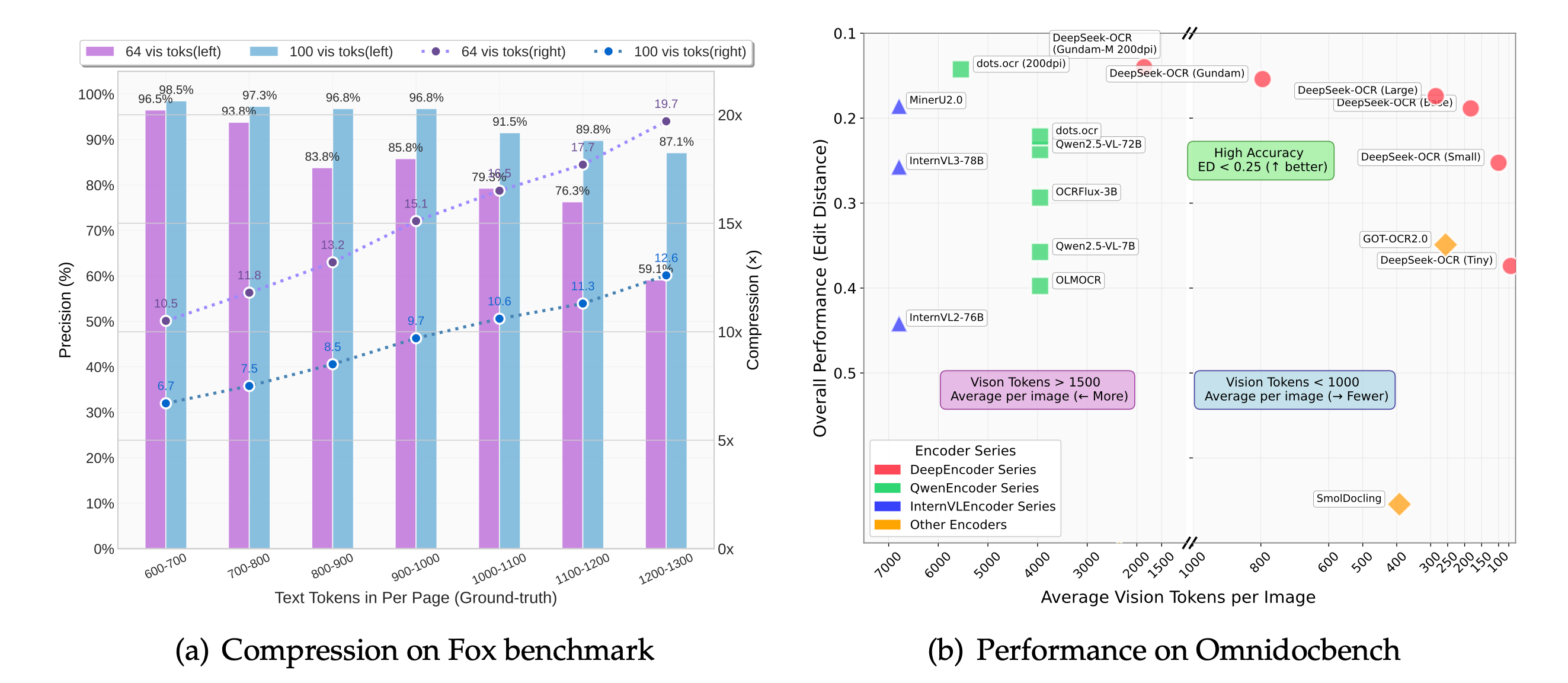
DeepSeek-OCR 支持灵活的分辨率模式,适应不同硬件和场景需求:
原生分辨率模式 :
Tiny(512×512,64 Token):适合移动端。
Small(640×640,100 Token):平衡性能与效率。
Base(1024×1024,256 Token):通用场景首选。
Large(1280×1280,400 Token):高性能服务器。
动态分辨率模式(Gundam) :
针对超大文档(如报纸),将图像分块为 n×640×640 局部视图(100 Token / 块)和 1024×1024 全局视图(256 Token),总 Token 数为 n×100+256(n≤9)。Gundam-Master 模式(1024×1024 局部 + 1280×1280 全局)通过增量训练实现,支持多栏排版、图文混杂的复杂文档。
更多详情请见: DeepSeek-OCR-镜像社区 算家云
二、部署流程
基础环境推荐:
| 环境名称 | 版本信息 |
|---|---|
| Ubuntu | 22.04.4 LTS |
| Cuda | V12.1 |
| Python | 3.12 |
| NVIDIA Corporation | RTX 4090 |
注:该模型对于显存占用要求较低,16G显存也可部署,不过在识别pdf的较大文件占用显存较高。
1.更新基础软件包
查看系统版本信息
#查看系统的版本信息,包括 ID(如 ubuntu、centos 等)、版本号、名称、版本号 ID 等
cat /etc/os-release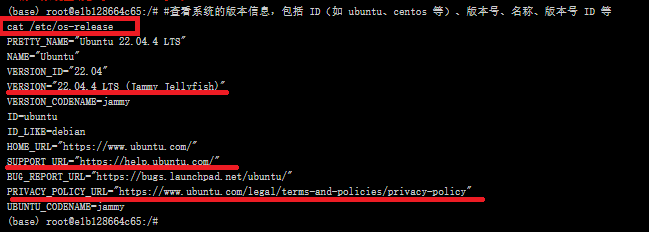
更新软件包列表
#更新软件列表
apt-get update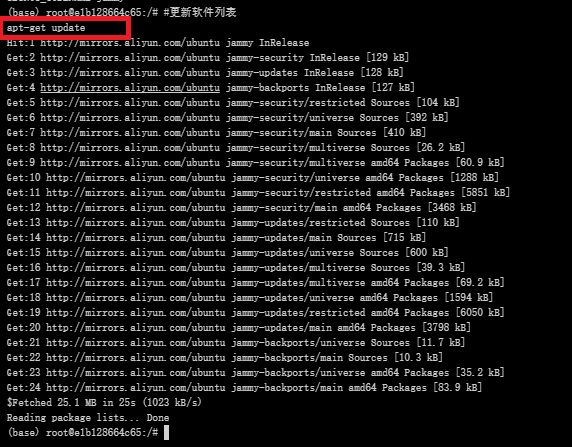
2.创建虚拟环境
创建虚拟环境
#创建名为DeepSeek-OCR的虚拟环境,python版本:3.12
conda create -n DeepSeek-OCR python=3.12 
激活虚拟环境
conda activate DeepSeek-OCR3.克隆仓库、安装依赖
在github中将DeepSeek-OCR有关的官方存储库克隆下来,可见:deepseek-ai/DeepSeek-OCR:上下文光学压缩
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
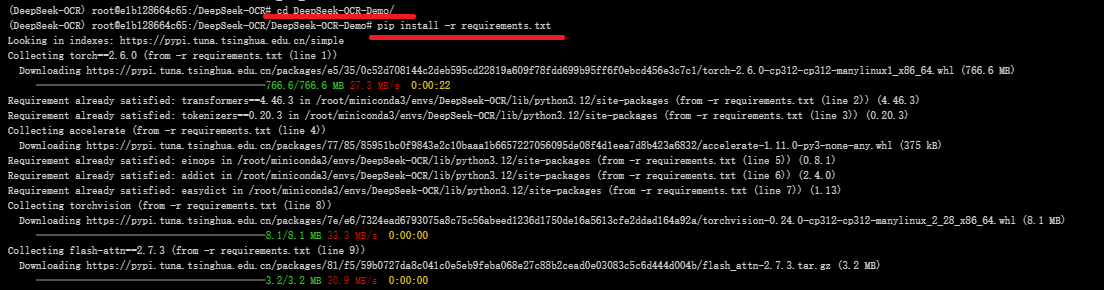
进行DeepSeek-OCR目录下,执行命令 pip install -r requirements.txt 将仓库所需的各版本号依赖项进行下载
特别的,如需要该模型可视化访问页面,这里推荐huggingface上官方给出的gradio页面模板
git clone https://huggingface.co/spaces/merterbak/DeepSeek-OCR-Demo
同样的,使用该模板,也需要进入DeepSeek-OCR-Demo目录下,安装所需依赖项
4.模型下载
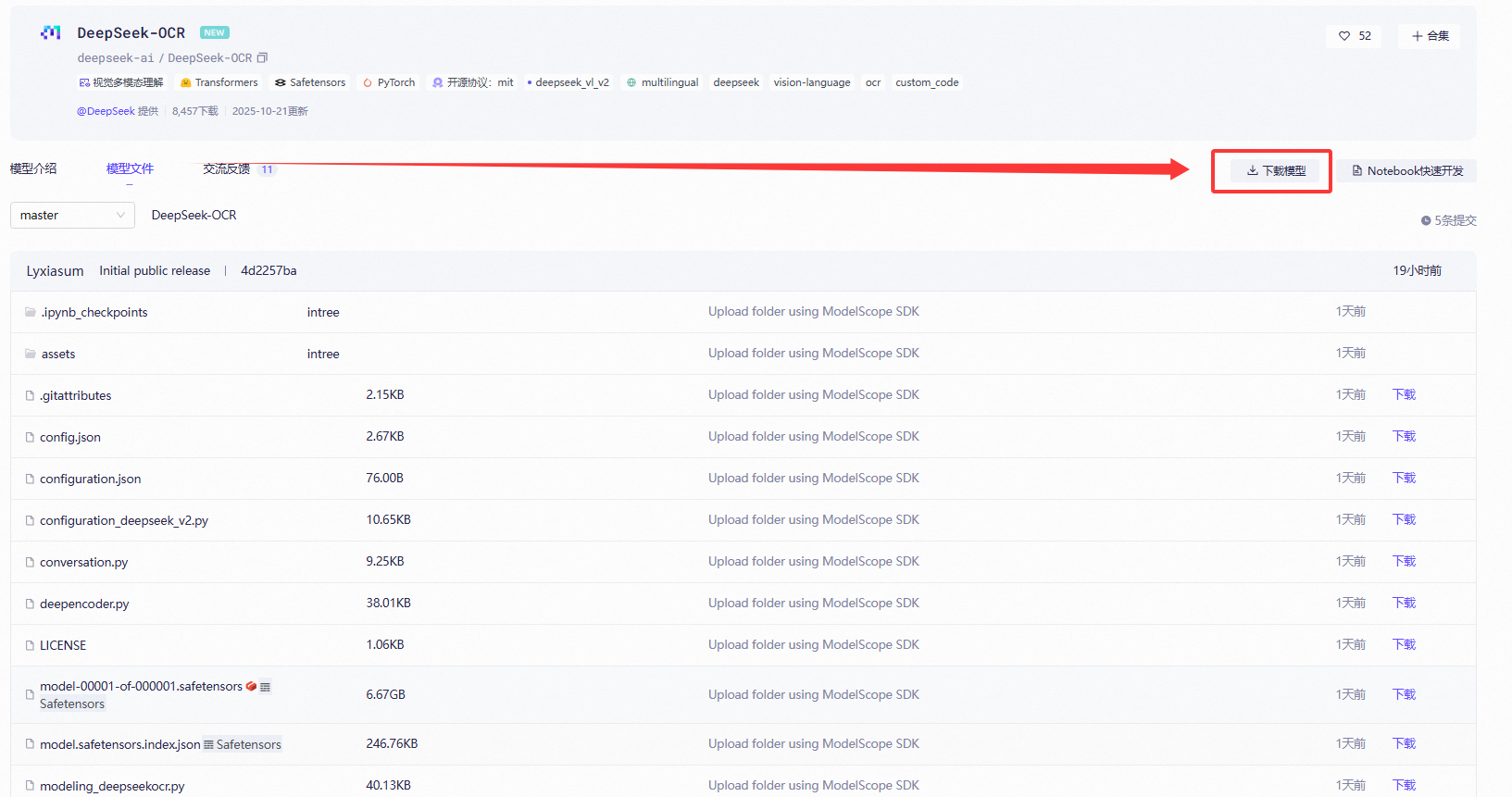
这里推荐转到魔塔社区官网下载模型文件:DeepSeek-OCR · 模型库
使用命令行下载完整模型库
#在下载前,请先通过如下命令安装
pip install modelscope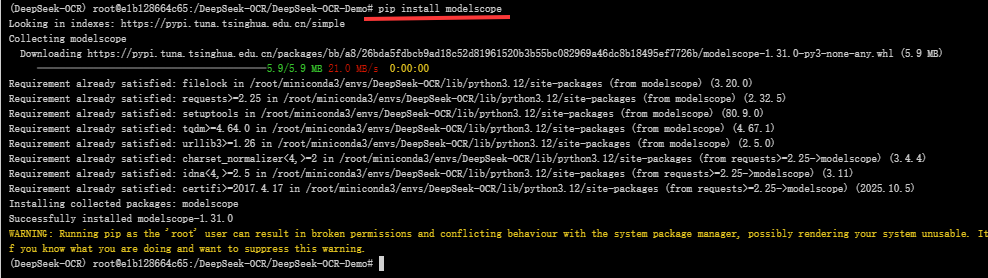
转到根目录下,创建 model目录用于存放模型权重文件,在使用命令行下载 modelscope download --model 'deepseek-ai/DeepSeek-OCR' --local_dir './'
cd /
mkdir model
cd model
modelscope download --model 'deepseek-ai/DeepSeek-OCR' --local_dir './'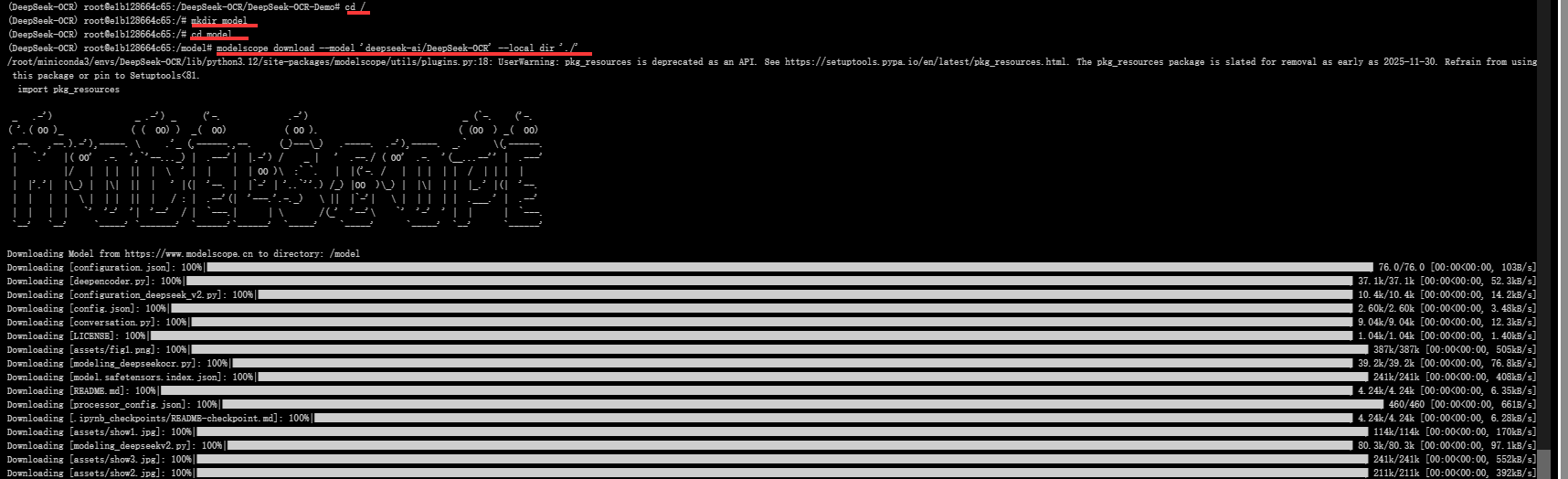
5.修改 web 页面启动脚本
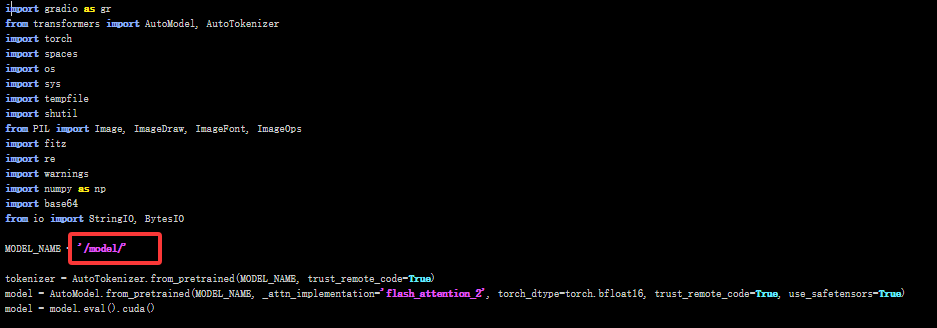
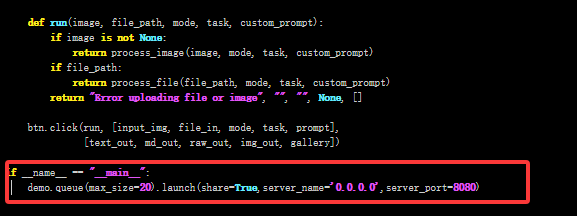
进入 /DeepSeek-OCR/DeepSeek-OCR-Demo 目录,修改其中的web启动代码app.py:
vim /DeepSeek-OCR/DeepSeek-OCR-Demo/app.py
将模型的加载路径改为本地路径 /model/ ,以及lunch加载函数中设置 share=True,server_name='0.0.0.0',server_port=8080
6.运行脚本
#执行修改好的 app.py 文件
python app.py
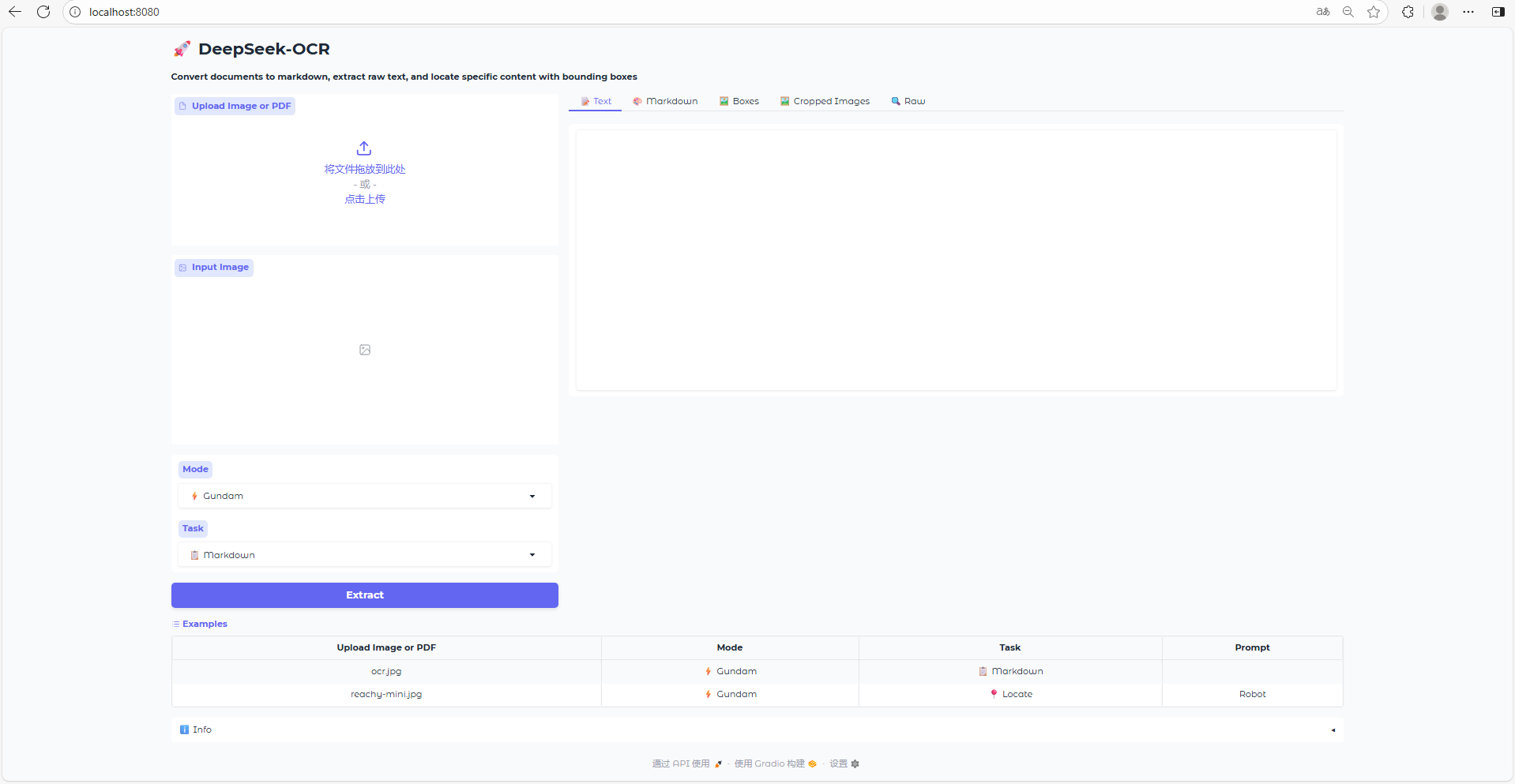
7.web 页面展示
将网址:http://localhost:8080/粘贴到浏览器中,便可与模型进行对话