网络请求:百度时一般输入网址https://www.baidu.com,将其称之为url:统一资源定位符。请求过程:客户端(web浏览器)向服务端发送请求,请求分为四部分:请求网址request url、请求方法request methods、请求头(伪装成正常用户)request header、请求体request body
爬虫的作用:数据采集、软件测试、抢票、网络安全、web漏洞扫描
网络爬虫的基本流程:url ->对url发送网络请求,获取网络请求的响应 ->解析响应,提取数据 ->保存数据
robots协议:**通过一个名为 robots.txt 的文本文件,告诉网络爬虫哪些页面或文件可以被抓取,哪些不可以。**并不是一个规范,是约定俗称的
超文本(不局限于文本,包括图片、音频、视频等)传输协议(HyperText Transfer Protocol,HTTP),并没有做传输的事情,数据的传输是交由TCP协议进行的。一种无状态的(不会存储用户的信息,即本次请求响应和下一次的请求响应是没有关系的,不会发生数据传递),以请求\应答方式运行的协议,它使用可扩展的语义和自描述消息格式,与基于网络的超文本信息系统灵活的互动。默认端口号是80
HTTPS协议:http+ssl(安全套接字层),ssl是对传输的内容进行加密,默认端口号是443。比http更安全,但是性能更低。
-
HTTP报文格式:
- 起始行:描述请求或响应的基本信息
- 请求行报文格式
- 请求方法GET(向服务器要资源)、HEAD、PUT、POST(向服务器提交资源,表示对资源的操作) 空格 请求目标(通常是一个URI,标记了请求方法要操作的资源) 空格 版本号(表示报文使用的HTTP协议版本) 换行
- 响应行报文格式
- 版本号(表示报文使用的HTTP协议版本) 空格 状态码(一个三位数,用代码的形式表示处理的结果,比如200是成功,500是服务器错误) 空格 原因(作为数字状态码的补充,是更详细的解释文字,帮助人理解原因) 换行
- 请求行报文格式
- 头部字段集合:使用Key-value形式更详细地说明报文,key 和value 之间用冒号分隔
- 空行
- 消息正文:实际传输的数据,不一定是纯文本,可以是图片、视频等二进制数据
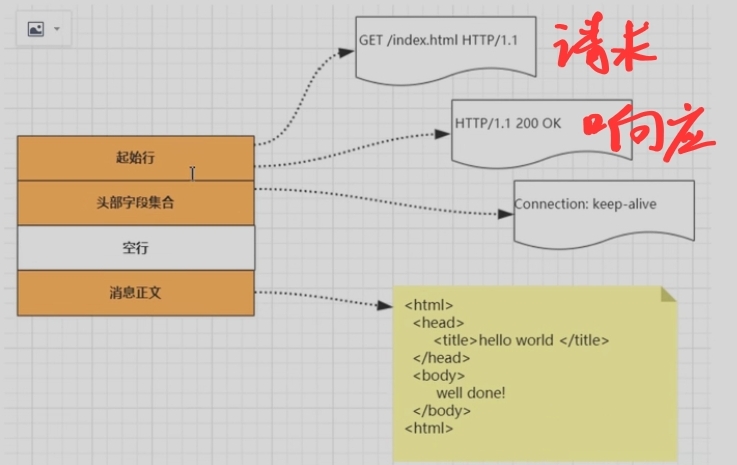
- 起始行:描述请求或响应的基本信息
-
HTTP请求的完整过程:当用户在浏览器输入网址回车后,网络协议做了哪些工作?第一、解析IP 地址。浏览器会从用户输入的网址中提取出域名,然后查询当前的域名对应的IP地址 。如果之前浏览过并且没有过期,会直接返回缓存的地址;否则本机域名解析文件,如果之前没有配置过,可发起DNS(ip地址标注服务器)获取IP,可以向更上一级的DNS发起请求。第二、网络请求。首先建立TCP的三次握手,然后浏览器向应用服务器发起HTTP请求 ,应用服务器收到请求后,开始处理用户请求,是想拿到一个资源还是进行修改呢,再以http 报文的形式返回浏览器,浏览器解析响应报文,渲染页面。没有其他响应后,进行TCP的四次挥手。
-
百度首页实际上是由很多部分组成起来,html文本、css样式控制文字大小颜色、js行为包括鼠标点击、jpg图片
-
网络通信的实际原理:一个请求只能对应一个数据包(文件),之后抓包可能会有很多个数据包,共同组成了这个页面。
-
200成功;302跳转,新的url在响应的Location头中给出;303浏览器对于Post的响应进行重定向至新的url;307浏览器对于get的响应重定向至新的url;403资源不可用,服务器理解客户的请求,但拒绝处理它(没有权限);404找不到该页面;500服务器内部错误;503服务器由于维护或者负载过重未能应答,在响应中可能会携带Retry-After响应头,有可能是因为爬虫频繁访问url,使服务器忽视爬虫的请求,最终返回503响应状态码
-
user-agent:模拟正常用户 cookie:登录保持 referer:当前这一次请求是由哪个请求过来的 抓包得到的响应内容才是判断依据,elements中的源码是渲染之后的,不能作为判断标准。
-
一些基本的使用
pythonimport requests #目标url url='https://www.baidu.com' #向目标url发送get请求 response=requests.get(url) print(response) #<Response [200]> #打印响应内容 #print(response.text) #用text是因为这是一个网页,响应内容有乱码,requests模块会自动寻求一种解码方式去解码 #如果就是想用text,那么可以将其编码设置为utf-8,response.encoding='utf-8' print(response.content.decode()) #会解码,不会乱码(默认utf-8解码)python#使用requests库保存图片 import requests #目标url,只获取某张图片需要右键在新标签页中打开图片,然后再右键检查 url='https://ss2.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=1659552792,3869332496&fm=253&gp=0.jpg' #向目标url发送请求,并获取响应 res=requests.get(url) print(res.content) #图片是二进制类型,所以使用content #保存响应 with open('1.jpg','wb') as f: #如果爬取文本、html等,可以将wb改为w,jpg也要改,如果是html就改成html,如果是文本就改为txt,如果是json就改为json f.write(res.content)pythonimport requests #目标url url='https://www.baidu.com' #向目标url发送get请求 response=requests.get(url) #保存响应 with open('baidu.html','w',encoding='utf-8') as f: f.write(response.content.decode())response.text和response.content的区别:text是返回str类型,content是返回bytes类型,可以通过decode()解码
python
import requests
#目标url
url='https://ss2.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=1659552792,3869332496&fm=253&gp=0.jpg'
res=requests.get(url)
#response.url响应的url,有时候响应的url和请求的url并不一致
print(res.url)
#response.status_code响应状态码
print(res.status_code)
#response.request.headers响应对象的请求头
print(res.request.headers)
#response.headers响应头
print(res.headers)
#response.request._cookies 响应对应请求的cookie;返回cookieJar类型
print(res.request._cookies )
#response.cookies响应的cookie(经过了set---cookie动作,返回cookieJar类型
print(res.cookies)
#response.apparent_encoding响应对象的编码格式-
在前面爬取'https://www.baidu.com'百度首页代码这个例子里,我们发现爬取的数据并不全,这是因为:请求头中有很多字段,其中user-agent字段是必不可少的,表示客户端的操作系统以及浏览器的信息
pythonimport requests url='https://www.baidu.com' #构建请求头 headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0' } #发送请求头 response=requests.get(url,headers=headers) print(response.request.headers) print(len(response.content.decode())) #发现内容比之前要多 #添加user-agent的目的是为了让服务器认为是浏览器在发送请求,而不是爬虫程序在发送请求
如果上述请求的次数过多,还是会被服务器识别出来,所以我们要构建一个user-agent池,每次在里面随机调用不同的user-agent字段,以此来防止反扒,被服务器识破是爬虫程序。下图可以切换不同的系统的user-agent值
python
import random
#方法一、随机调用user-agent值
UAlist=[
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0',
'Mozilla/5.0 (iPhone; CPU iPhone OS 18_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.5 Mobile/15E148 Safari/604.1 Edg/140.0.0.0',
'Mozilla/5.0 (Linux; Android 13; SM-G981B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Mobile Safari/537.36 Edg/140.0.0.0'
]
print(random.choice(UAlist))
#方法一有点麻烦,方法二:不构造UA池,可以使用其他模块
from fake_useragent import UserAgent #这种方法有可能会出现异常
print(UserAgent().random)发现字符串被当作url提交时自动进行url编码处理,在百度中输入学习(明文),浏览器在向服务端发送请求的时候,学习会被加密为密文,引入一个包,使得明文和密文互相转换