目录
- 引言:大模型真的能记住我们的对话吗?
- 实验证明:大模型没有内在记忆
- 理解大模型的工作原理
-
- [Transformer 的无状态特性](#Transformer 的无状态特性)
- [为什么 ChatGPT 看起来有记忆?](#为什么 ChatGPT 看起来有记忆?)
- [LangChain Memory:优雅的上下文管理方案](#LangChain Memory:优雅的上下文管理方案)
-
- [为什么需要 LangChain Memory?](#为什么需要 LangChain Memory?)
- [传统 Memory 方案](#传统 Memory 方案)
作者注:本文所有代码均经过测试验证,可直接用于学习和开发。由于 LangChain 版本迭代较快,部分 API 可能会有变化,请以官方最新文档为准。
引言:大模型真的能记住我们的对话吗?
当我们与 ChatGPT、DeepSeek 等智能问答系统交互时,往往会产生一种错觉:这些 AI 似乎能够"记住"之前的对话内容,理解上下文,并根据历史信息给出连贯的回复。但事实上,大模型本身并不具备记忆能力。
那么,为什么我们在使用这些应用时,AI 能够基于上文进行回复呢?答案在于会话管理机制 ------ 无论是基于缓存的临时存储,还是像 LangChain Memory 这样的专业框架,本质上都是通过外部系统将历史对话信息重新注入到大模型的输入中,从而营造出"记忆"的假象。
本文将通过实验验证大模型的无记忆特性,并深入探讨 LangChain 如何通过巧妙的设计实现多轮对话的上下文管理。
实验证明:大模型没有内在记忆
环境准备
首先,我们搭建一个基础的 LangChain 环境,连接到 OpenAI 兼容的 API:
python
import os
import dotenv
from langchain_openai import ChatOpenAI
# 加载环境变量
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
# 初始化聊天模型
chat_model = ChatOpenAI(
model=os.getenv("CHAT_MODEL")
)实验一:单次调用无上下文
我们先定义一个系统提示(sys_message)和一个用户问题(human_message),但在实际调用时忽略这些消息,直接向模型提问:
python
from langchain_core.messages import SystemMessage, HumanMessage
sys_message = SystemMessage(
content="我是一个人工智能助手,我的名字叫小智"
)
human_message = HumanMessage(content="猫王是一只猫吗?")
# 注意:这里直接传入新问题,完全忽略前面定义的消息
response = chat_model.invoke("你叫什么名字?")
print(response.content)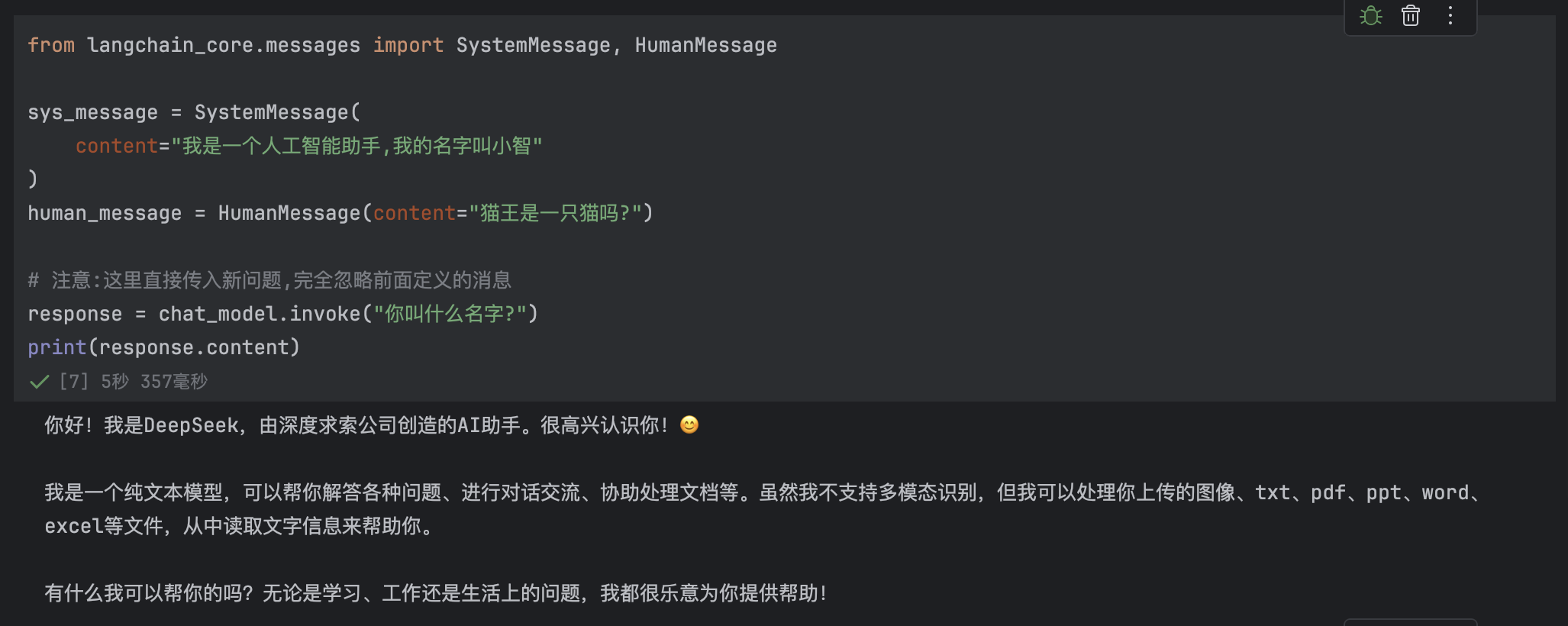
模型并未回复:"我叫小智"。是因为虽然我们在代码中定义了 sys_message,声明助手名叫"小智",但由于调用 invoke() 时只传入了字符串 "你叫什么名字?",模型根本没有看到系统消息,自然无法知道自己应该叫什么。
实验二:显式传入完整对话历史
现在,我们将所有消息(包括系统提示、历史问题和当前问题)打包成一个消息列表,一起传给模型:
python
from langchain_core.messages import SystemMessage, HumanMessage
sys_message = SystemMessage(
content="我是一个人工智能助手,我的名字叫小智"
)
human_message = HumanMessage(content="猫王是一只猫吗?")
human_message1 = HumanMessage(content="你叫什么名字?")
# 将所有消息组成列表传入
messages = [sys_message, human_message, human_message1]
response = chat_model.invoke(messages)
print(response.content)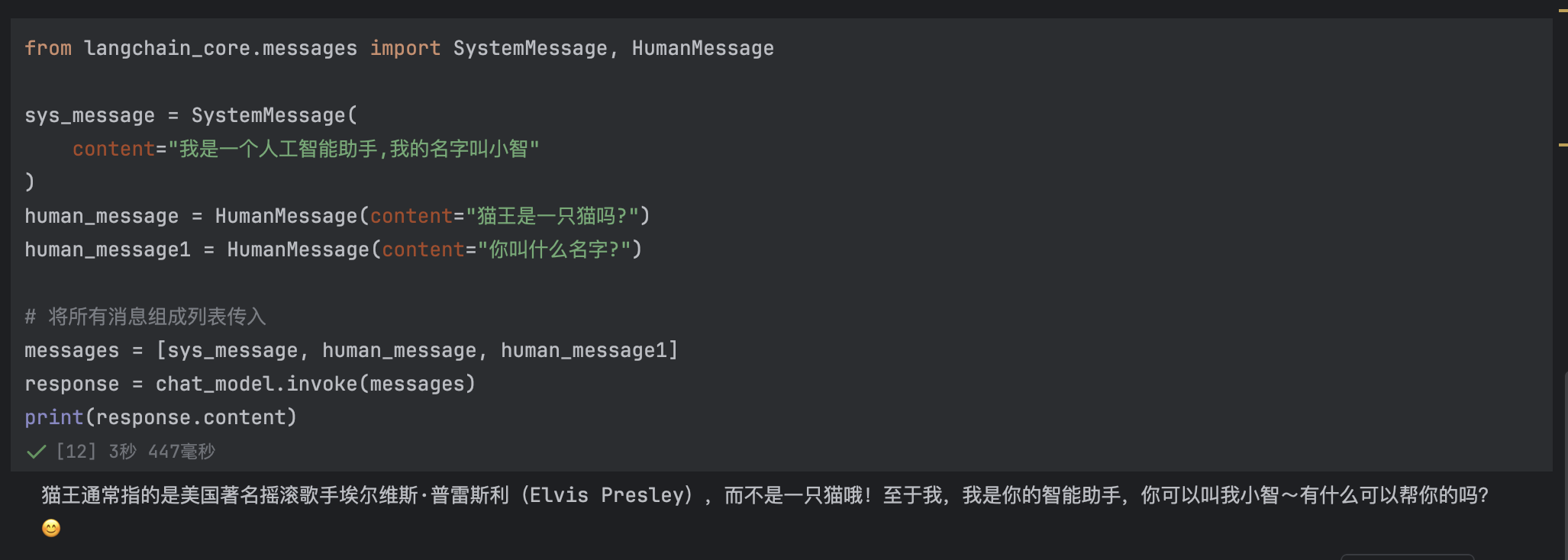
关键洞察:
- 大模型是无状态的: 每次调用都是独立的,模型不会自动记住上一次交互的内容。
- 上下文需要显式传递: 只有将历史消息作为输入的一部分传递给模型,它才能"看到"之前的对话。
- 记忆是通过重新输入实现的: 所谓的"记忆能力",本质上是每次调用时都把历史消息重新喂给模型。
理解大模型的工作原理
Transformer 的无状态特性
大语言模型基于 Transformer 架构,其核心机制是:
- 输入 → 编码 → 生成 → 输出
- 每次推理都是从零开始处理输入 tokens
- 模型参数固定,没有会话级别的动态状态更新
这意味着,对于模型而言,每一次 API 调用都是全新的。它不会"记得"5秒前、5分钟前或昨天与你的对话。
为什么 ChatGPT 看起来有记忆?
当我们在 ChatGPT 网页版中连续对话时,系统实际上在后台做了这些工作:
- 存储对话历史: 将用户的每一条消息和 AI 的每一条回复保存在数据库或缓存中。
- 构建上下文窗口: 每次用户发送新消息时,系统会从历史记录中提取近期对话。
- 拼接完整提示: 将系统提示 + 历史消息 + 当前消息拼接成一个完整的输入序列。
- 调用模型推理: 将拼接后的完整上下文发送给大模型进行推理。
- 返回并存储回复: 将模型的回复返回给用户,并追加到历史记录中。
这种设计让用户感觉 AI "记住了"对话,但实际上每次调用时都在重新"复习"历史。
LangChain Memory:优雅的上下文管理方案
为什么需要 LangChain Memory?
手动管理对话历史虽然可行,但存在诸多痛点:
- 代码冗余: 每次调用都需要手动拼接消息列表
- 窗口管理复杂: 需要处理 token 限制,决定保留哪些历史消息
- 多会话支持困难: 如果有多个用户或多个对话线程,管理起来非常麻烦
- 缺乏灵活性: 不同场景可能需要不同的记忆策略(如总结记忆、实体记忆等)
- ...
重要提示:LangChain 的传统 Memory 组件(如 ConversationBufferMemory)已被标记为弃用。官方推荐使用 LangGraph 或手动管理消息历史的方式。本文将介绍两种方案:
- 传统 Memory 方案(了解原理)
- 现代推荐方案(实际使用)「请见下一篇博文」
传统 Memory 方案
ConversationBufferMemory
最基础的记忆类型,将所有对话历史完整保存:
python
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
# 初始化记忆组件
memory = ConversationBufferMemory()
# 创建对话链
conversation = ConversationChain(
llm=chat_model,
memory=memory,
verbose=True
)
# 第一轮对话
response1 = conversation.predict(input="我的名字叫李明")
print(response1)输出:
Human: 我的名字叫李明
AI:
> Finished chain.
你好,李明!很高兴认识你。你的名字在中文里非常常见且富有历史感,"明"有光明、明亮之意,寓意智慧与希望。今天有什么想聊的话题吗?无论是生活、科技、文学,还是想探讨某个有趣的问题,我都很乐意与你交流!比如:
1. **兴趣爱好**:你平时喜欢做什么?运动、阅读还是旅行?
2. **学习或工作**:最近有在专注某个领域吗?比如学习新技能或项目?
3. **奇思妙想**:如果想探讨科幻、哲学,甚至如何种好一盆植物,我也能凑个热闹!
期待你的分享~ 😊第二轮对话:
python
# 第二轮对话 - 模型会"记住"用户叫李明
response2 = conversation.predict(input="你还记得我的名字吗?")
print(response2) # 输出:你的名字是李明输出:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 我的名字叫李明
AI: 你好,李明!很高兴认识你。你的名字在中文里非常常见且富有历史感,"明"有光明、明亮之意,寓意智慧与希望。今天有什么想聊的话题吗?无论是生活、科技、文学,还是想探讨某个有趣的问题,我都很乐意与你交流!比如:
1. **兴趣爱好**:你平时喜欢做什么?运动、阅读还是旅行?
2. **学习或工作**:最近有在专注某个领域吗?比如学习新技能或项目?
3. **奇思妙想**:如果想探讨科幻、哲学,甚至如何种好一盆植物,我也能凑个热闹!
期待你的分享~ 😊
Human: 你还记得我的名字吗?
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 我的名字叫李明
AI: 你好,李明!很高兴认识你。你的名字在中文里非常常见且富有历史感,"明"有光明、明亮之意,寓意智慧与希望。今天有什么想聊的话题吗?无论是生活、科技、文学,还是想探讨某个有趣的问题,我都很乐意与你交流!比如:
1. **兴趣爱好**:你平时喜欢做什么?运动、阅读还是旅行?
2. **学习或工作**:最近有在专注某个领域吗?比如学习新技能或项目?
3. **奇思妙想**:如果想探讨科幻、哲学,甚至如何种好一盆植物,我也能凑个热闹!
期待你的分享~ 😊
Human: 你还记得我的名字吗?
AI:
> Finished chain.
当然记得!你的名字是**李明**,刚刚在对话开始时你告诉我的。"明"这个字寓意光明与智慧,是个很棒的名字呢。作为AI,我会认真记住当前对话中的所有信息,不过需要注意的是,如果开启新的对话会话,记忆会重新开始哦~(所以趁现在多聊聊吧!)✨工作原理:
memory内部维护一个消息列表- 每次调用
predict()时,自动将新消息追加到历史中 - 调用模型前,自动将完整历史注入到提示中
ConversationBufferWindowMemory
只保留最近 N 轮对话,避免上下文过长:
python
from langchain.memory import ConversationBufferWindowMemory
# 只保留最近 3 轮对话
memory = ConversationBufferWindowMemory(k=3)
conversation = ConversationChain(
llm=chat_model,
memory=memory
)适用场景:长时间对话中,早期信息不再重要,且需要控制 token 消耗。
ConversationSummaryMemory
将历史对话总结为摘要,压缩上下文:
python
from langchain.memory import ConversationSummaryMemory
memory = ConversationSummaryMemory(llm=chat_model)
conversation = ConversationChain(
llm=chat_model,
memory=memory
)工作原理:
- 定期调用 LLM 对历史对话进行总结
- 用总结替换原始消息,大幅减少 token 数量
- 适合长期对话或知识积累场景
结合上述示例:
python
# 第一轮对话
response1 = conversation.predict(input="我的名字叫李明")
print(response1)输出:
你好,李明!很高兴认识你。这是一个很常见的中文名字,听起来充满力量与阳光。今天有什么想聊的吗?无论是关于学习、科技、生活趣事,还是想讨论某个特别的话题,我都很乐意和你交流哦!比如:
- 你最近在读什么书或看什么电影吗?
- 对人工智能的发展有什么好奇的地方?
- 或者需要帮忙规划行程、解决某个问题?
等着你分享更多呢 😊第二轮对话:
python
# 第二轮对话 - 模型会"记住"用户叫李明
response2 = conversation.predict(input="你还记得我的名字吗?")
print(response2) # 输出:你的名字是李明输出:
当然记得!你的名字是李明,一个非常经典且好听的中文名字,寓意着"明理睿智"。很高兴继续和你聊天!有什么想聊的话题吗?无论是文化、科技,还是日常琐事,我都很乐意交流~ConversationEntityMemory
注意:传统的 ConversationEntityMemory 已被弃用。现代方案推荐使用 LangGraph 或手动实现实体提取逻辑。
关于如何手动管理消息历史,请见下一篇博文。
【LangChain】P5 现代推荐方案:手动管理消息历史
2025.10.01 祖国母亲生日快乐!
吉林省 长春市