前言
之前学习了LangChain中的嵌入,接下来学习LangChain中的向量存储
概念
向量存储(Vector Store)是 LangChain 中用于存储和检索嵌入向量的组件
用于存储、管理文本 / 多模态数据转换后的向量,同时提供高效相似性检索能力
是 RAG(检索增强生成)、AI Agent 记忆、知识库问答等场景的基础,解决了大模型上下文窗口有限、无法记住海量外部知识的核心问题
什么是向量
下面是自然语言处理和机器学习中的向量概念:
向量(Vector)是一个数值数组,用于表示文本或文档的语义信息。每个元素都代表了文本中的一个特征或维度,而向量的长度则决定了该文本的特征数量。
例如,考虑一个简单的文本分类任务,我们有两个类别:"情感分析"和"主题分类"。我们可以使用向量来表示每个文本的特征,例如:
- 情感分析向量:0.2, -0.3, 0.5
- 主题分类向量:-0.1, 0.4, -0.2
这些向量可以用于表示不同的文本,并且可以通过计算相似度来判断它们之间的关系
跨专业学习需要恶补的东西还是挺多的,概念的有时候看的也是似懂非懂(很多时候是一脸懵逼)
LangChain VectorStores 的核心功能
看下常见的向量存储方案
FAISS
FAISS 是 Facebook 开源的高效向量相似度检索库,全名是 Facebook AI Similarity Search。不得不感叹大厂是真叼,日常工作生活大部分都是大厂的产品和服务
FAISS 是 LangChain VectorStore 中最常用的本地向量存储方案之一,核心优势是开源免费、本地部署无额外成本、相似度检索速度极快,尤其适合中小规模向量数据(百万级以内)的 AI Agent、知识库问答等场景
这不完美匹配了我这种开发者现在的需求的吗,本地开发研究,再用个本地的知识库,用着 Ollama 跑起来的本地模型
Pinecone
Pinecone 是 LangChain VectorStore 生态中托管式云向量数据库的代表,核心优势是全托管免运维、分布式高可用、超大规模向量检索快,无需本地部署索引,适配生产环境和大规模向量场景,适合需要稳定服务、不想维护底层存储的开发场景
Pinecone 就是云端网盘(平台托管、随时访问、支持超大文件、付费使用)
大规模企业级场景下用的,不适合个人学习研究场景
Chroma
Chroma 是一款专为 LLM 应用设计的轻量级开源向量数据库,核心定位是「让向量存储变得简单」------ 无需复杂部署,一行代码即可启动,支持向量的存储、相似度检索、动态增删改,还能关联元数据(如文档来源、类型),像一个「专为 LLM 打造的本地向量记事本」
类比场景:FAISS 是一次性写入的本地 U 盘,Chroma 是可随时增删文件的本地移动硬盘,Pinecone 是云端网盘,Chroma 兼顾了本地的便捷性和动态更新的灵活性
Milvus
Milvus 是 LangChain VectorStore 生态里工业级、开源、分布式、可扩展的向量数据库,主打大规模向量(亿级)、高性能检索、动态更新、高可用,是从本地开发到企业级生产的全链路向量存储方案,完美衔接 FAISS/Chroma(本地轻量)与 Pinecone(云端托管)的中间地带
类比:FAISS 是本地 U 盘,Chroma 是本地移动硬盘,Milvus 是本地可扩展服务器 + 云端集群,既能本地快速跑,也能支撑企业级大规模向量服务Milvus
上面的这些向量存储方案都实现了 创建向量存储、相似度搜索、带分数的相似度搜索、最大边际相关性搜索、保存和加载 等核心功能
相似度搜索的原理
相似度搜索是向量存储的核心功能,基本原理是将查询文本转换为向量,计算查询向量与存储中所有向量的相似度,返回相似度最高的前几个结果
常用的相似度度量方法包括 余弦相似度、欧氏距离、点积 等
代码示例
下面是 FAISS 向量存储的基础代码示例,其他类型的存储方案就先不写了,项目级层面用到再看
注意
from langchain_community.embeddings import HuggingFaceEmbeddings 为老版本写法,我这里运行时出现问题,需用新版本
新版本写法更简单,直接从 langchain_huggingface 导入 HuggingFaceEmbeddings 即可
python
import os
from langchain_community.vectorstores import FAISS
# from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_huggingface import HuggingFaceEmbeddings
# 核心示例:FAISS 向量存储完整流程
def faiss_vector_store_core_demo():
# 1. 准备基础文本数据(待向量化的原始内容)
documents = [
"LangChain 是用于开发语言模型应用的框架。",
"FAISS 是 Facebook 开发的高效相似度搜索库。",
"Embedding 模型将文本转换为数值向量表示。"
]
# 2. 初始化嵌入模型(核心:文本转向量的工具)
# 选用多语言模型,适配中文场景
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)
# 3. 创建 FAISS 向量存储(核心步骤:文本→向量→入库)
# from_texts 方法会自动完成:遍历文本→调用嵌入模型生成向量→存入 FAISS 索引
vector_store = FAISS.from_texts(documents, embeddings)
print(" FAISS 向量库创建完成(文本已转为向量并存储)")
# 4. 向量检索(核心功能:根据查询向量找相似文本)
query = "什么是 FAISS?"
# similarity_search:根据查询文本生成向量,在 FAISS 中找最相似的 top-k 结果
results = vector_store.similarity_search(query, k=1)
print(f"\n 检索查询:{query}")
print(f"检索结果:{results[0].page_content}")
# 5. 向量库持久化(核心:保存到本地,避免重复生成向量)
save_path = "./faiss_core_index"
vector_store.save_local(save_path)
print(f"\n 向量库已保存到本地:{save_path}")
# 6. 加载本地向量库(核心:复用已生成的向量库)
loaded_vector_store = FAISS.load_local(
save_path,
embeddings,
allow_dangerous_deserialization=True # 本地加载必需参数
)
# 验证加载结果
test_query = "什么是 Embedding?"
loaded_result = loaded_vector_store.similarity_search(test_query, k=1)
print(f"\n 加载后验证 - 查询:{test_query}")
print(f"验证结果:{loaded_result[0].page_content}")
if __name__ == "__main__":
faiss_vector_store_core_demo()代码运行结果
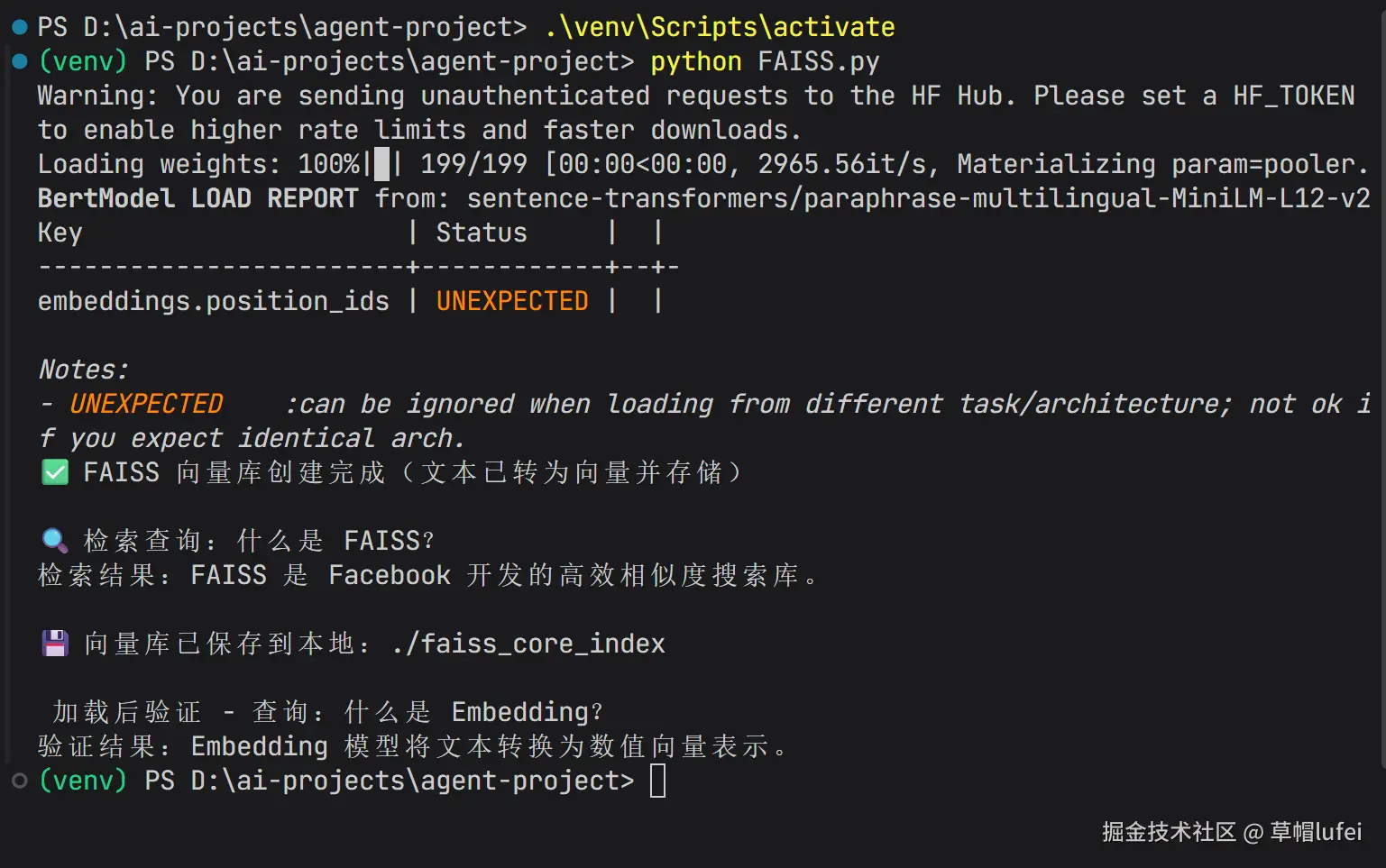
向量库持久化到本地会在项目对应目录生成 faiss_core_index 文件夹,包含索引文件和配置文件
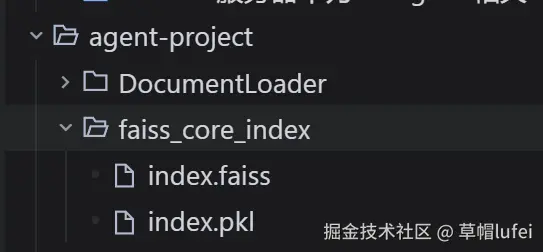
这种文件是无法直接在编辑器中打开的
小结
LangChain VectorStores 向量存储相关知识就基本了解了,并了解了 FAISS 向量存储的基本原理和代码实现,其他类型目前没有合适的时机和项目场景去尝试,就不展开了
接下来将在本地实现一个基于知识库的问答系统,实战操作一波
欢迎留言交流,如果觉得有帮助,可以
点个赞支持一下公众号:草帽lufei