概述
文本预处理:文本语料在输送给模型前一般需要一系列的预处理工作, 才能符合模型输入的要求。
主要环节包括如下:
-
文本处理基本方法(本文)
-
文本张量表示方法
-
文本语料数据分析
-
文本特征处理
-
数据增强方法
文本处理基本方式:
-
分词
-
词性标注
-
命名实体识别
一、分词
含义:将连续的字序列按照一定规范分割为词序列

作用:nlp处理人类语言,而词是作为人类语言的基本单元,分词也就是nlp的领域的重要基础环节
使用:jieba分词工具,做最好的python中文分词组件
- jieba
安装:
pip install jieba -i https://mirrors.aliyun.com/pypi/simple/特性:
1.支持多种分词模式(本质是分词的颗粒度)
(1)精确模式:尽可能按照语义进行分割 (常用)
jieba.lcut(content, cut_all=False)(2)全模式:尽可能分割出所有成词的词语,不能消除歧义
jieba.lcut(content, cut_all=True)(3)搜索引擎模式:在精确模式基础上,对长词再次切分
jieba.lcut_for_search(content)2.支持中文繁体分词
- 中国香港, 台湾地区的繁体文本进行分词
- api = 精确模式
3.支持用户自定义词典
-
词典格式: 词语、词频(可省)、词性(可省),用空格隔开,顺序不可颠倒。
-
jieba.load_userdict("./userdict.txt")
mydata2 = jieba.lcut(sentence, cut_all=False)
二、词性标注
含义:基于分词后,对词汇的词性进行标注
API:
import jieba.posseg as pseg
pseg.lcut("text")返回的是:装有pair元组的列表 , 每个pair元组中装有:词汇、词性
jieba词性标注对照表:
a 形容词
ad 副形词
ag 形容词性语素
an 名形词
b 区别词
c 连词
d 副词
df
dg 副语素
e 叹词
f 方位词
g 语素
h 前接成分
i 成语
j 简称略称
k 后接成分
l 习用语
m 数词
mg
mq 数量词
n 名词
ng 名词性语素
nr 人名
nrfg
nrt
ns 地名
nt 机构团体名
nz 其他专名
o 拟声词
p 介词
q 量词
r 代词
rg 代词性语素
rr 人称代词
rz 指示代词
s 处所词
t 时间词
tg 时语素
u 助词
ud 结构助词 得
ug 时态助词
uj 结构助词 的
ul 时态助词 了
uv 结构助词 地
uz 时态助词 着
v 动词
vd 副动词
vg 动词性语素
vi 不及物动词
vn 名动词
vq
x 非语素词
y 语气词
z 状态词
zg
三、命名实体识别
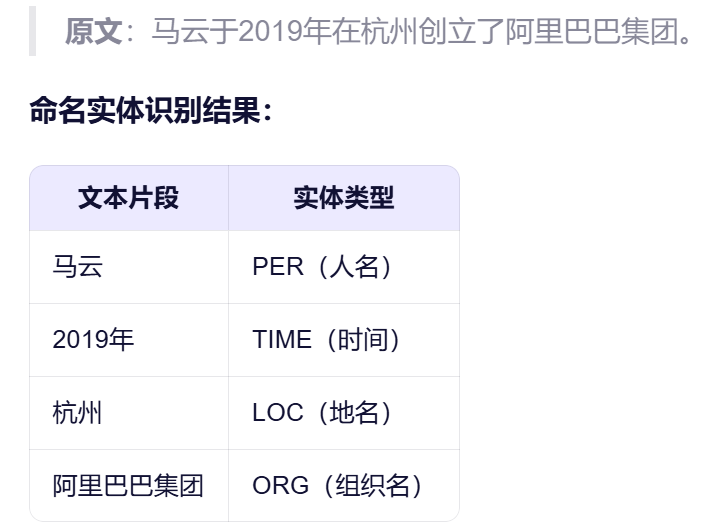
含义:识别语料中的命名实体
命名实体:人名、地名、机构名、时间、日期、货币、百分比