目录
[1. 什么是数据库](#1. 什么是数据库)
[2. 主流数据库](#2. 主流数据库)
[2.1 关系型数据库](#2.1 关系型数据库)
[2.2 非关系数据库](#2.2 非关系数据库)
[3. MySQL下载](#3. MySQL下载)
[4. Navicat Lite](#4. Navicat Lite)
[5. 数据库的操作](#5. 数据库的操作)
[5.1 连接数据库](#5.1 连接数据库)
[5.2 查看所有数据库](#5.2 查看所有数据库)
[5.3 创建数据库](#5.3 创建数据库)
[5.4 字符集编码和校验规则](#5.4 字符集编码和校验规则)
[5.5 查看创建语句](#5.5 查看创建语句)
[5.6 使用数据库](#5.6 使用数据库)
[5.7 删除数据库](#5.7 删除数据库)
[6. 数据类型](#6. 数据类型)
[6.1 SQL的数据类型](#6.1 SQL的数据类型)
[6.2 数据值类型](#6.2 数据值类型)
[6.3 字符串类型](#6.3 字符串类型)
[6.4 如何选择char和varchar](#6.4 如何选择char和varchar)
[6.5 日期类型](#6.5 日期类型)
[7. 表的操作](#7. 表的操作)
[7.1 查看所有的表](#7.1 查看所有的表)
[7.2 创建表](#7.2 创建表)
[7.3 表在磁盘上对应的文件](#7.3 表在磁盘上对应的文件)
[7.4 查看表结构](#7.4 查看表结构)
[7.5 修改表](#7.5 修改表)
[7.6 删除表](#7.6 删除表)
[8. 增删改查](#8. 增删改查)
[8.1 insert(增)](#8.1 insert(增))
[8.1.1 单行数据的插入](#8.1.1 单行数据的插入)
[8.1.2 单行元素的部分属性插入](#8.1.2 单行元素的部分属性插入)
[8.1.3 多行数据指定列属性插入](#8.1.3 多行数据指定列属性插入)
[8.2 select(查)](#8.2 select(查))
[8.2.1 全列查询](#8.2.1 全列查询)
[8.2.2 指定列查询](#8.2.2 指定列查询)
[8.2.3 查询的字段为表达式](#8.2.3 查询的字段为表达式)
[8.2.4 为查询结果设置别名](#8.2.4 为查询结果设置别名)
[8.2.5 查询结果去重](#8.2.5 查询结果去重)
[8.3 where(条件查询)](#8.3 where(条件查询))
[8.3.1 语法](#8.3.1 语法)
[8.3.2 比较运算符](#8.3.2 比较运算符)
[8.3.3 逻辑运算符](#8.3.3 逻辑运算符)
[8.3.4 比较运算符使用案例](#8.3.4 比较运算符使用案例)
[8.3.5 逻辑运算符使用案例](#8.3.5 逻辑运算符使用案例)
[8.3.6 范围查询](#8.3.6 范围查询)
[8.3.7 模糊查询](#8.3.7 模糊查询)
[8.3.8 null的查询](#8.3.8 null的查询)
[8.4 order by 排序](#8.4 order by 排序)
[8.5 分页查询](#8.5 分页查询)
[8.6 update(修改)](#8.6 update(修改))
[8.7 delete(删除)](#8.7 delete(删除))
[10. 插入查询结果](#10. 插入查询结果)
[11.1 常用的函数](#11.1 常用的函数)
[11.2 分组查询(group by)](#11.2 分组查询(group by))
[11.3 having子句](#11.3 having子句)
[12. 内置函数](#12. 内置函数)
[12.1 日期函数](#12.1 日期函数)
[12.2 字符串处理函数](#12.2 字符串处理函数)
[12.3 数学函数](#12.3 数学函数)
[12.4 其他常用函数](#12.4 其他常用函数)
1. 什么是数据库
数据库也就是用来存储数据的,可以帮你更好的管理数据, 当你需要数据的时候可以更加方便的去查找数据.
数据库可以持久化的保存数据, 可以是数据结构化方便查询, 数据库具有可拓展性, 数据库还支持多个用户同时进行数据的访问.\
2. 主流数据库
2.1 关系型数据库
关系型数据库指的是利用行和列来组织数据,也就相当于是一个表格,里面包含了数据.
当前主流的关系数据库:
1. Oracle: 不开源,贵
2. MySQL:开源免费.
3. Sql sever: 微软旗下的
4. SQLite: 轻量级数据库.
2.2 非关系数据库
Redis:流行的基于键值对的内存数据库,常用作缓存,支持数据持久化,支持多种数据结构。 MongoDB:基于NoSQL的文档型数据库,易扩展,高性能 ,高可用性, 支持丰富的查询和聚合操 作。
3. MySQL下载
我们这里下载MySQL来进行学习可以去官网进行下载:
MySQL :: Download MySQL Installer
下载完之后会有这两个软件:
第一个是MySQL提供的命令行客户端,可以编写SQL语句.
最后一个是MySQL官方提供的可视化窗口的客户端.
4. Navicat Lite
我们使用的是第三方的数据库客户端的可视化界面,可以去官网下载:
这里下载社区版,可以免费使用.
5. 数据库的操作
5.1 连接数据库
首先我们需要创建一个数据库进行连接,下面是打开Navicat软件后的操作:
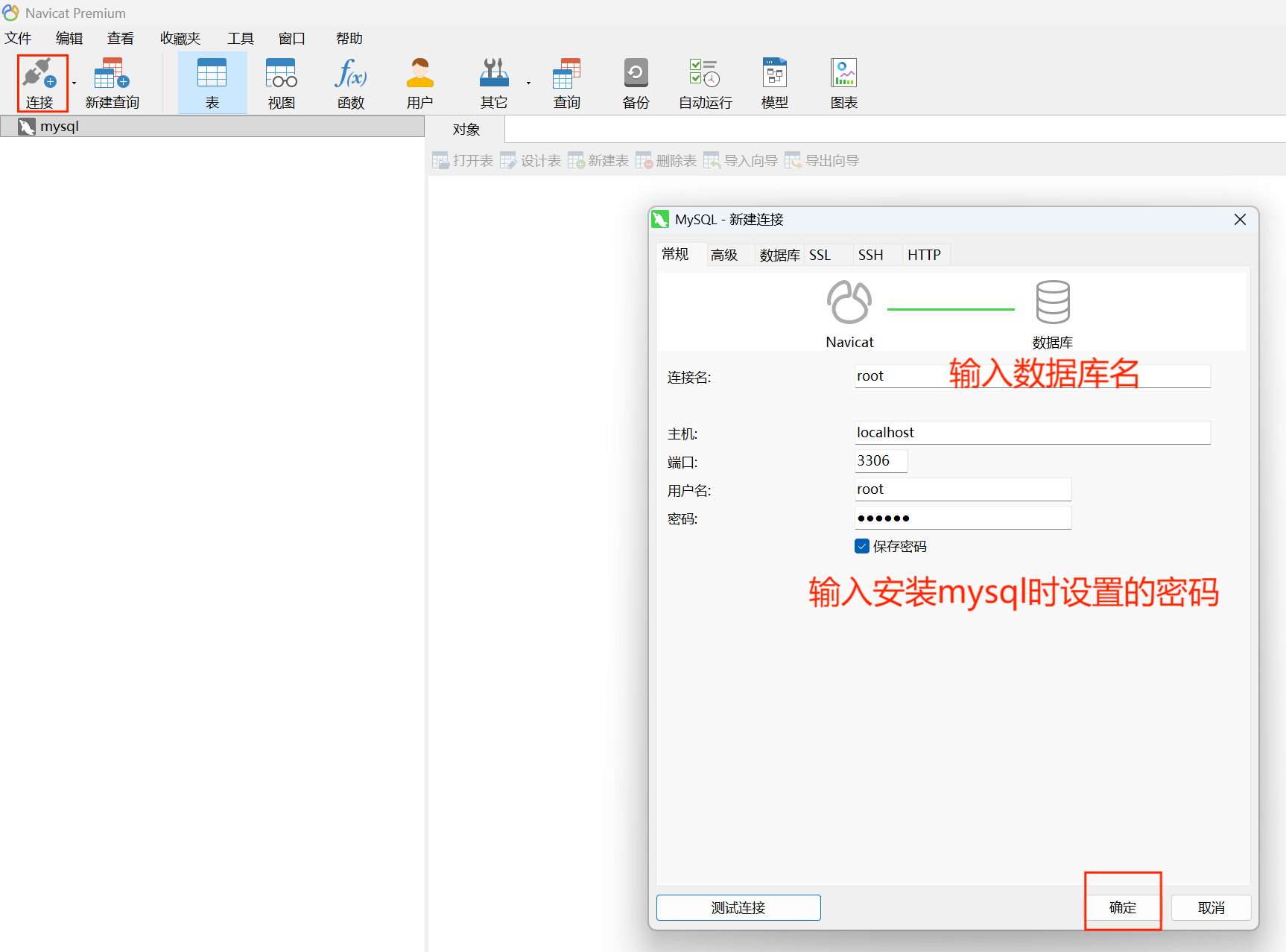
操作完之后再新建查询(左上角),就可以输入SQL语句了.
5.2 查看所有数据库
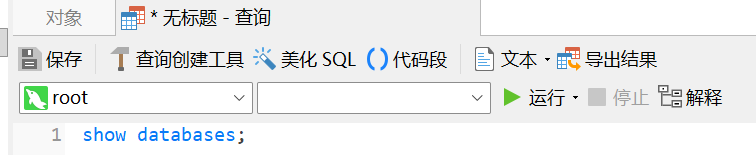
语句:
show databases;
这里的databases是复数形式, 两个词之间要有空格.
这个操作是看你当前连接的数据库下面有几个数据库:
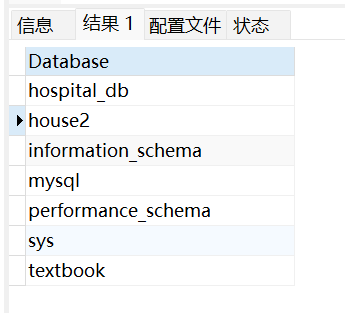
上面我们可以用鼠标选择要执行的SQL语句来运行, 也可以直接点击运行按钮会执行全部的SQL语句.
5.3 创建数据库
语句:
sql
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name [create_option] ...
create_option: [DEFAULT] {
CHARACTER SET [=] charset_name
| COLLATE [=] collation_name
| ENCRYPTION [=] {'Y' | 'N'}
}上面的大部分表示的是关键字,
db_name : 表示自定义的数据库名字
{ } 大括号表示必须要选
| : 表示选择其中一个
: 里面的内容可以写可以不写
character set: 指定数据库采用的字符集编码 , 可以写成 charset
collate: 指定字符集的校验规则
encryption : 数据库是否加密
其实最简洁的创建数据库的语句就是下面的形式:
create database 数据库名字 charset utf8mb4;
数据库使用` ` 反引号可以把关键字当作数据库名字。
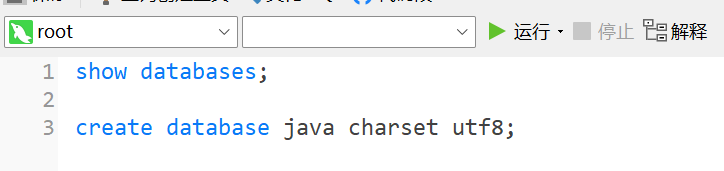
当我们创建的数据库的名字已经存在,但是我们不想报错终止语句执行,可以改成下面语句:
sql
create database if not exists java charset utf8;如果创建的数据库名字已经存在而不会报错也没有任何行为,直接执行下一条语句.
5.4 字符集编码和校验规则
查看数据库支持的字符集编码, MySQL8.0默认的是utf8mb4. 也就是utf-8.
sql
show charset;查看数据库支持的排序规则:
java
show collation;5.5 查看创建语句
这里展示的是创建数据库时定义的数据库的属性。
sql
show create database java;5.6 使用数据库
我们使用某个数据库时,可以使用ues + 数据库名的形式使用:
sql
use java;5.7 删除数据库
使用drop database + 数据库名字。
sql
drop database java;删除数据库这个操作很危险,我们要谨慎删除.
可以通过设置管理权限, 备份数据库, 等措施来降低删除数据库的风险.
6. 数据类型
6.1 SQL的数据类型
sql语句在表示实体的属性时, 不同的属性也需要使用不同的类型表示.
常用的数据类型有:
数据值类型 字符串类型 二进制类型 日期类型
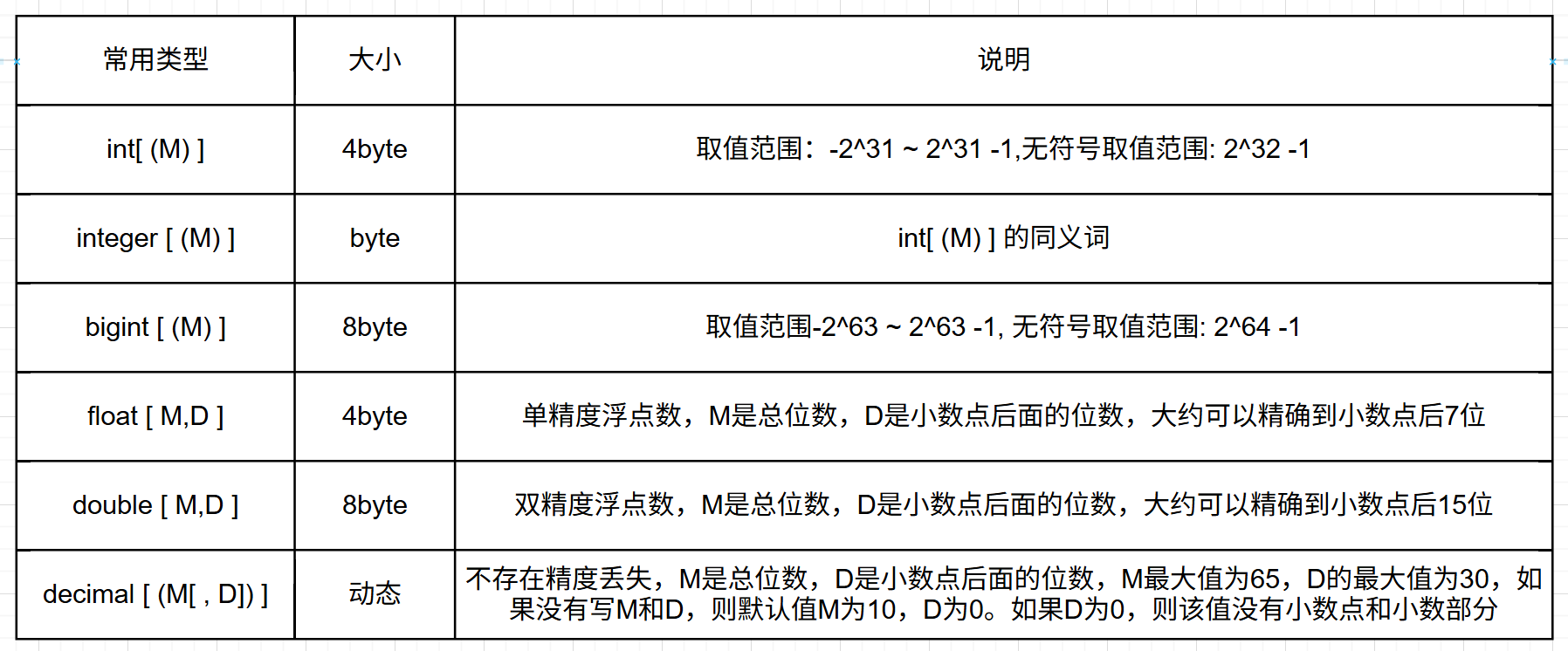
6.2 数据值类型
数据值类型(常用的类型)包括下面类型:
6.3 字符串类型
常用的字符串类型有:

6.4 如何选择char和varchar
- 如果数据确定长度相同时,使用char类型,比如说:身份证号。
- 如果数据长度有变化,使用varchar,比如姓名。
- char比较浪费磁盘空间,效率高。
- varchar节省磁盘空间,效率低。
- char类型会直接开辟好存储空间。
- varcahr类型再不超过定义长度范围的情况下,用多少空间开辟多少存储空间。
6.5 日期类型
常用的日期类型:
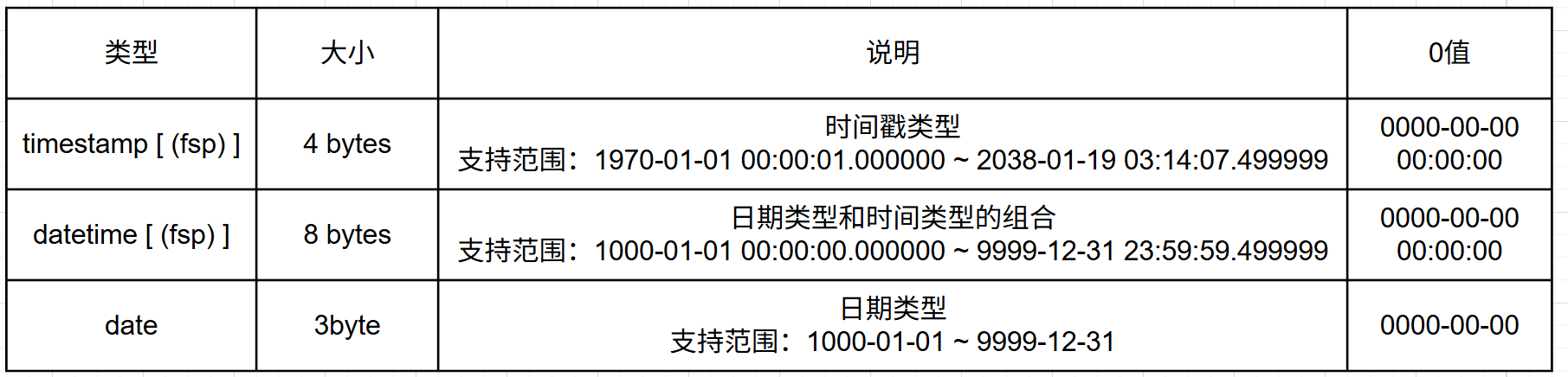
时间戳:就是从1970年1月1日0时0分0秒开始到现在的时间的秒数或者毫秒数。
上面的第二个类型比第一个类型表示的时间更长,第三个类型仅支持年月日的显示。
7. 表的操作
7.1 查看所有的表
show tables;
7.2 创建表
语法:
sql
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
field datatype [约束] [comment '注解内容']
[, field datatype [约束] [comment '注解内容']] ...
[engine 存储引擎] [character set 字符集] [collate 排序规则];TEMPOPARY:表示创建的是一个临时表
field:列名
datatype:数据类型
comment:对列的描述或者说明
engine:存储引擎,不指定的话,使用默认存储引擎。
character set:字符集,不指定的话,使用默认字符集。
collate:排序规则,不指定的话,使用默认排序规则。
举个例子:
创建一个用户表,包括 用户编号,用户名,密码,生日,指定字符集为utf8mb4,排序规则为utf8mb4_0900_ai_ci:
sql
create table user (
user_id int,
user_name varchar(20) comment '用户名',
password char(30) comment '密码',
birthday date comment '生日'
) character set = utf8mb4 collate = utf8mb4_0900_ai_ci;7.3 表在磁盘上对应的文件
MySQL创建的表存储在硬盘上,表的文件名是:表名.存储引擎的缩写:
我们可以找到mysql的命令行窗口,打开文件所在的位置:
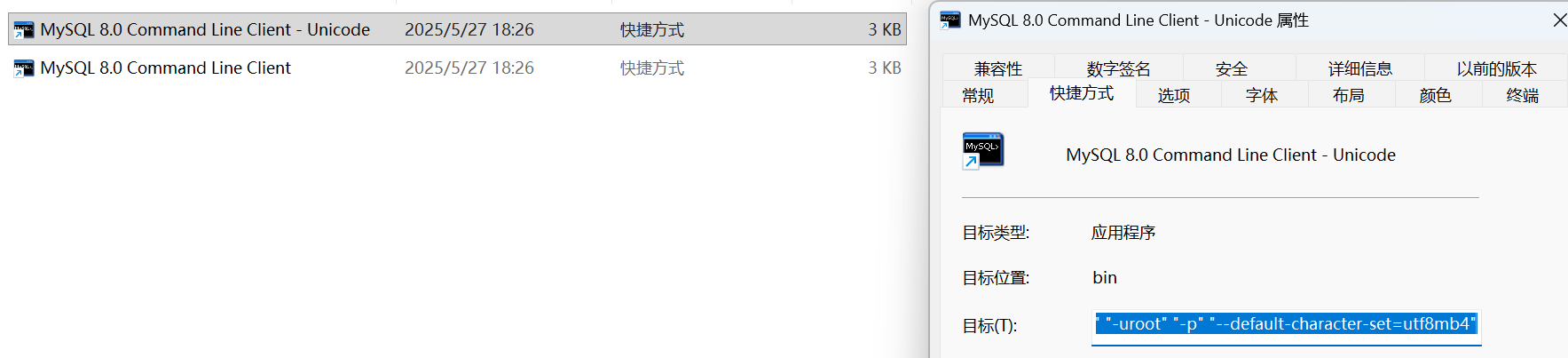
右击找到属性,里面有个目标,里面会有一串地址:
"C:\Program Files\MySQL\MySQL Server 8.0\bin\mysql.exe" "--defaults-file=C:\ProgramData\MySQL\MySQL Server 8.0\my.ini" "-uroot" "-p" "--default-character-set=utf8mb4"
下面路径里面就存放着你创建的数据库。
下面图片就是我们创建的表存储在文件中,里面是二进制码:
7.4 查看表结构
语法:
desc 表名;
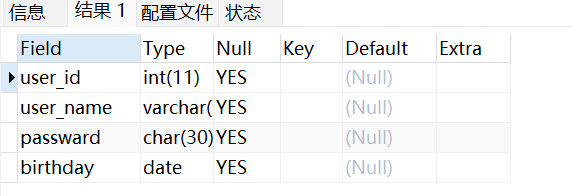
上面就是查询后的信息:
field:表示表中的列名。
type:列的数据类型。
Null:表示该列值是否可以设置为Null。
key:该列的索引类型。
Default:该列的默认值。
Extra:扩展信息
7.5 修改表
语法:
sql
ALTER TABLE tbl_name [alter_option [, alter_option] ...];
alter_option: {
table_options
| ADD [COLUMN] col_name column_definition [FIRST | AFTER col_name]
| MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name]
| DROP [COLUMN] col_name
| RENAME COLUMN old_col_name TO new_col_name
| RENAME [TO | AS] new_tbl_nametbl_name:要修改的表名。
add:向表中添加列。
alter table user add gender char(5) after birthday;
modify:修改表中现有的列的属性。
alter table user modify gender varchar(5);
rename column:重命名列名。
alter table user rename column gender to sex;
drop:删除表中现有的列。
alter table user drop sex;
7.6 删除表
语法:
DROP TEMPORARY TABLE IF EXISTS tbl_name , tbl_name ...
TEMPORARY:表示临时表。
tbl_name:表示要删除的表名。
注意:
删除表是一个危险的操作。
可以同时删除多个表,每个表名之间用 , (逗号)隔开。
8. 增删改查
8.1 insert(增)
语法:
sql
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES
(value_list) [, (value_list)] ...
value_list: value, [, value] ...8.1.1 单行数据的插入
语法:
insert into 表名 values(列1数据,列2数据,.........);
sql
insert into user values (1,'张三','男');
insert into user values (2,'李四','女');这样就是插入一行包含每列的所有属性的数据。
8.1.2 单行元素的部分属性插入
语法:
insert into 表名(列名1,列名2) values(列1数据,列2数据);
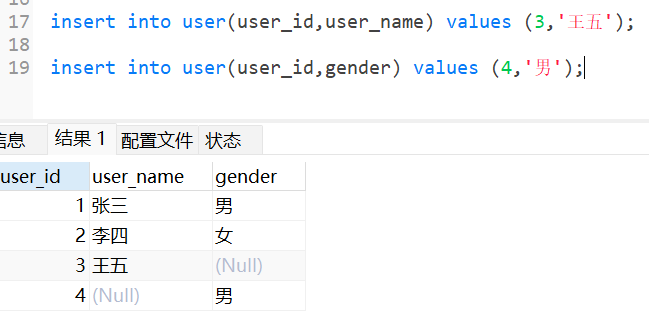
这样是指定插入的一行数据,添加那些列的属性。
8.1.3 多行数据指定列属性插入
语法:
insert into 表名(列名1,列名2) values (列1数据,列2数据),(列1数据,列2数据);
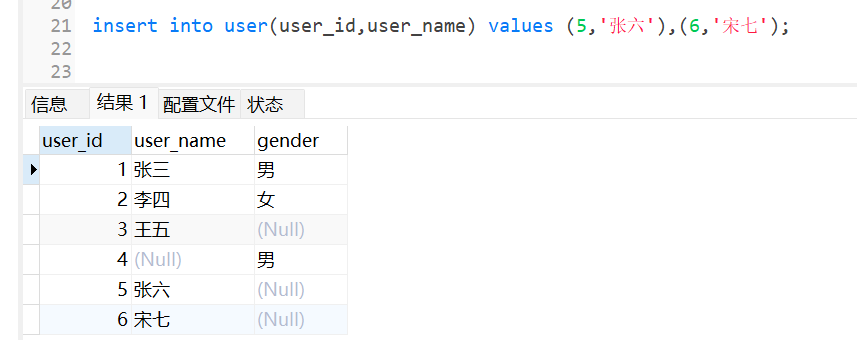
这样就一次性插入多条数据。
我们在每一次数据插入时,都需要申请网络通信,如果一次插入多条数据,可以减少网络通信的次数,但是如果一次插入太多的数据,也不太好。
8.2 select(查)
语法:
sql
SELECT
[DISTINCT]
select_expr [, select_expr] ...
[FROM table_references]
[WHERE where_condition]
[GROUP BY {col_name | expr}, ...]
[HAVING where_condition]
[ORDER BY {col_name | expr } [ASC | DESC], ... ]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]我们可以先创建一个表结构,方便下面进行使用:
java
create table exam (
id bigint,
name varchar(20) comment '学生姓名',
chinese float comment '语文成绩',
math float comment '数据成绩',
english float comment '英语成绩'
);
insert into exam (id,name,chinese,math,english) values
(1,'唐三藏',67,98,56),
(2,'孙悟空',87,78,77),
(3,'猪悟能',88,98,90),
(4,'曹孟德',82,84,67),
(5,'刘玄德',55,85,45),
(6,'孙权',70,73,78),
(7,'宋公明',75,65,30);8.2.1 全列查询
语句:
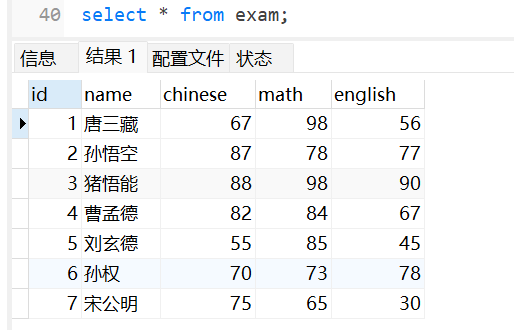
select * from exam;
可以查询表中的所有数据:
8.2.2 指定列查询
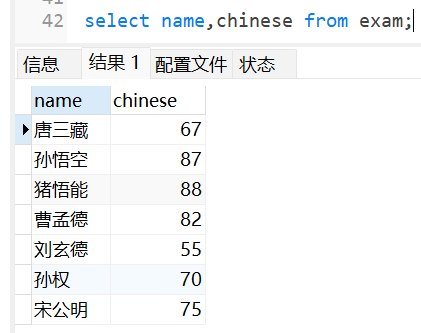
查询所有人的姓名和语文成绩:
8.2.3 查询的字段为表达式
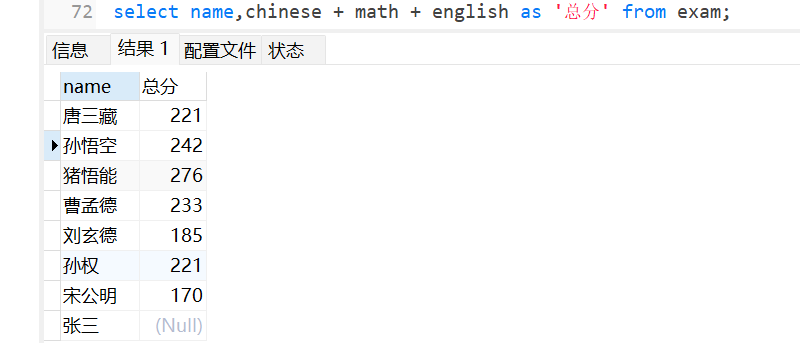
我们在查询时,可以将查出来的数据进行表达式计算,显示出来:
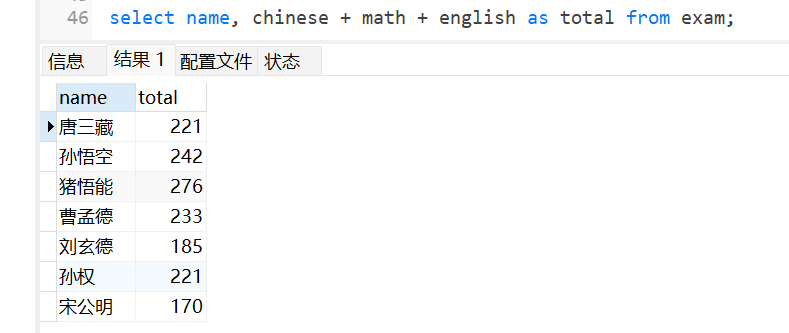
计算语文,数学和英语成绩的总和:
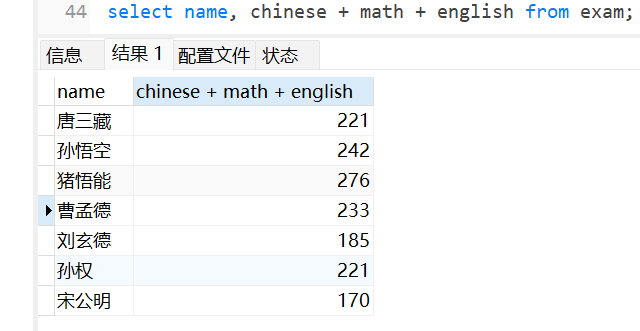
当然下面显示的表只是一个临时表,并不是在硬盘里面的表进行修改的。
8.2.4 为查询结果设置别名
我们上面在计算三门成绩的总和,在下面临时表中显示的话比较长,我们就可以给这个数据设置一个别名,使用的as关键字,as也可以省略不写。
8.2.5 查询结果去重
我们在查询时,可以指定一列或者几列数据相同时,去重:
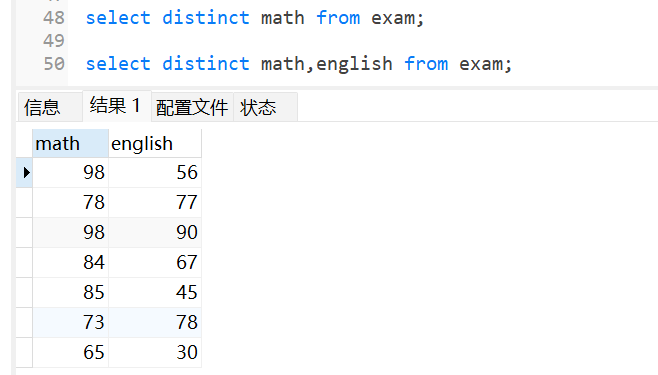
8.3 where(条件查询)
8.3.1 语法
sql
SELECT
select_expr [, select_expr] ... [FROM table_references]
WHERE
where_condition8.3.2 比较运算符
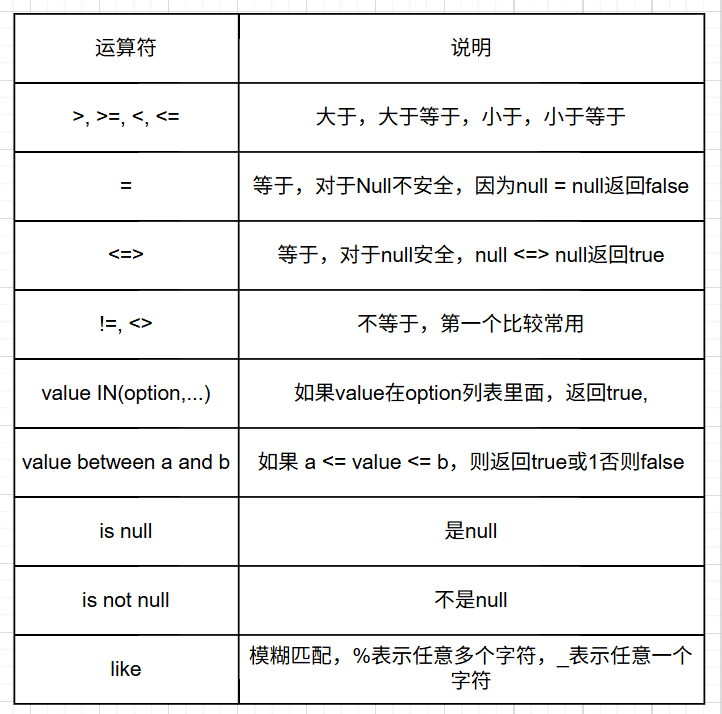
8.3.3 逻辑运算符

8.3.4 比较运算符使用案例
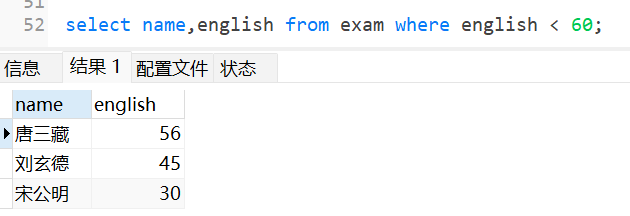
查询英语成绩不及格的同学:
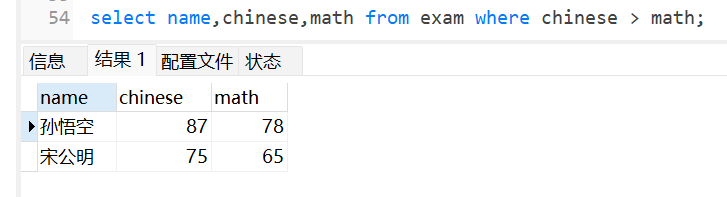
查询语文成绩高于数学成绩的同学:
查询总分在200分以下的同学:

8.3.5 逻辑运算符使用案例
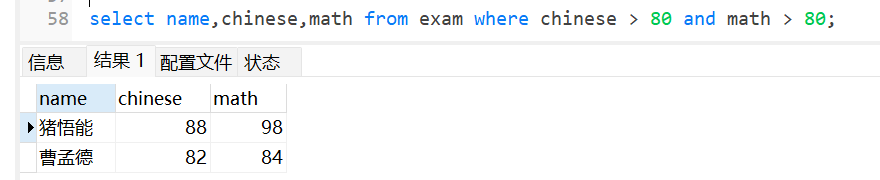
查询语文成绩和数学成绩都大于80的学生:
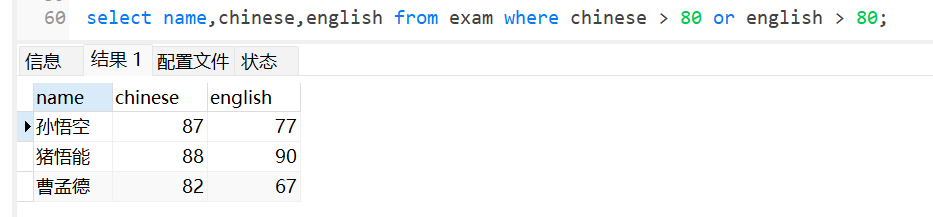
查询语文成绩大于80或者英语成绩大于80的学生:
注意:and的优先级比or的优先级高。
8.3.6 范围查询
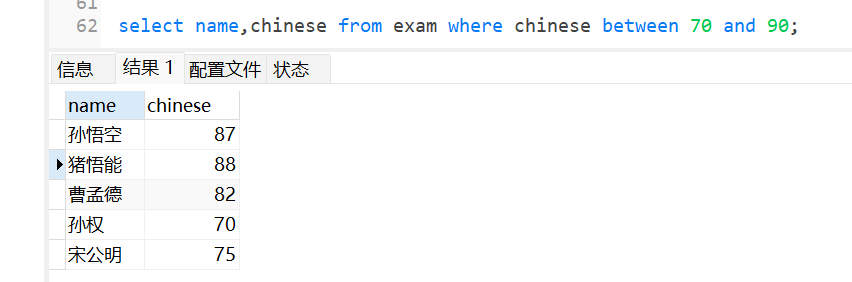
查询语文成绩在70,90 之间的学生:
8.3.7 模糊查询
查询所有姓孙的学生:
select * from 表名 where name like '孙%';
查询所有姓张的,并且名字是两个字:
select * from 表名 where name like '张_';
8.3.8 null的查询
查询某列为null的行:
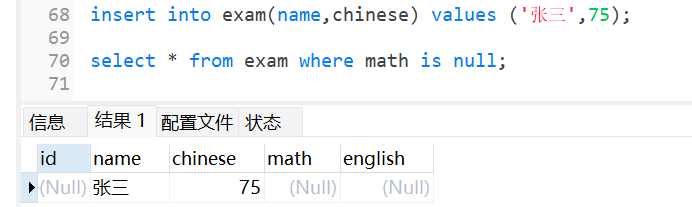
当null和其他元素运算结果仍为null:
8.4 order by 排序
这里在进行查询时,如果不写升序还是降序时候,默认是升序排列,写desc时候是降序排列。
sql
select into 列名 from 表名 order by 列名,列名[desc] [asc];在order by后面跟多个列时候,会先按照第一个列的属性来排序,如果第一列值一样,再按照第二列的属性去排序。
如果没有指定order by的话,就是随机排序,没有规律。
在排序时候我们可以使用列名的别名,进行排序。因为order by 是在前面查询完之后再进行排序的。
null值在排序时候是被认为是最小的。
8.5 分页查询
分页查询相当于将所有的数据分成几部分进行查询,这样我们每次查询的结果就是我们设置的数据量,语法如下:
sql
select 列名,列名 from 表名 limit 查询几条数据 [offset 从第几行开始查];当我们只输入limit 3 的时候,默认是从第1行开始查三条数据。
如果设置offset 3,表示从第四行开始查三条数据。
8.6 update(修改)
语法:
sql
update 表名 set 列名 = 数据 [where 条件] [order by ] [limit a offset b];下面是一些update修改的语句:
sql
update student set math = 80 where name = '孙悟空';
update student set math = 60,chinese = 70 where name = '曹孟德';
update student set math = math + 30 where math is not null order by chinese + math + english asc limit 3;
update student set chinese = 2 * chinese;update在修改时候,如果不加上条件的话,就会修改整个表对应列的元素。
8.7 delete(删除)
语法:
sql
delete from 表名 [where] [order by ] [limit offset];如果我们不设置条件的话,就会删除整张表的元素。
这里与drop的区别是,drop是将整张表给删除了,而delete 是将整张表的数据给删除了。
9.截断表
使用delete删除表中的数据是一条一条的删除的,比较慢,我们可以使用truncate 语句来直接删除表中的元素,效率比较高。
sql
truncate [table] 表名;而这种操作只能对整个表进行操作,不能单独对某些行的元素进行删除。
10. 插入查询结果
这种操作是将查询到的数据,插入到另一张表中。
sql
insert into student1 select * from student;这串代码是将student表里面查询到的元素,插入到student1表里面去。
插入的元素必须与被插入的表的列属性一一对应。
11.聚合函数
11.1 常用的函数
count(参数) 该方法是用来计算表中的数据数量。也就是行数(不包含null值),只能传一个参数。
sum(参数) 计算数据的和,必须是数字类型。
avg(参数) 计算平均数,必须是数字类型。
max(参数)计算最大值,必须是数字类型。
min(参数)计算最小值,必须是数字类型。
sql
select count(chinese) from student where chinese < 50;
select sum(math) from student;
select avg(english) from student;
select max(english) from student;
select min(chinese) from student;11.2 分组查询(group by)
分组查询是将表中的属性,按照某一列来进行分组,相同的分为一组,来进行操作。
语法:
sql
select 表达式 from 表名 group by 列名;下面是几个使用实例:
sql
select role,count(role) from emp group by role;
select role,avg(salary) from emp group by role;
select role,max(salary) from emp group by role;
select role,min(salary) from emp group by role;11.3 having子句
having语句是对分组后的数据,进行条件约束的,不能使用where。
如果是分组前的条件使用where,如果是分组后的条件使用having。
使用示例:
sql
select role,avg(salary) from emp group by role having avg(salary) < 20000;12. 内置函数
12.1 日期函数
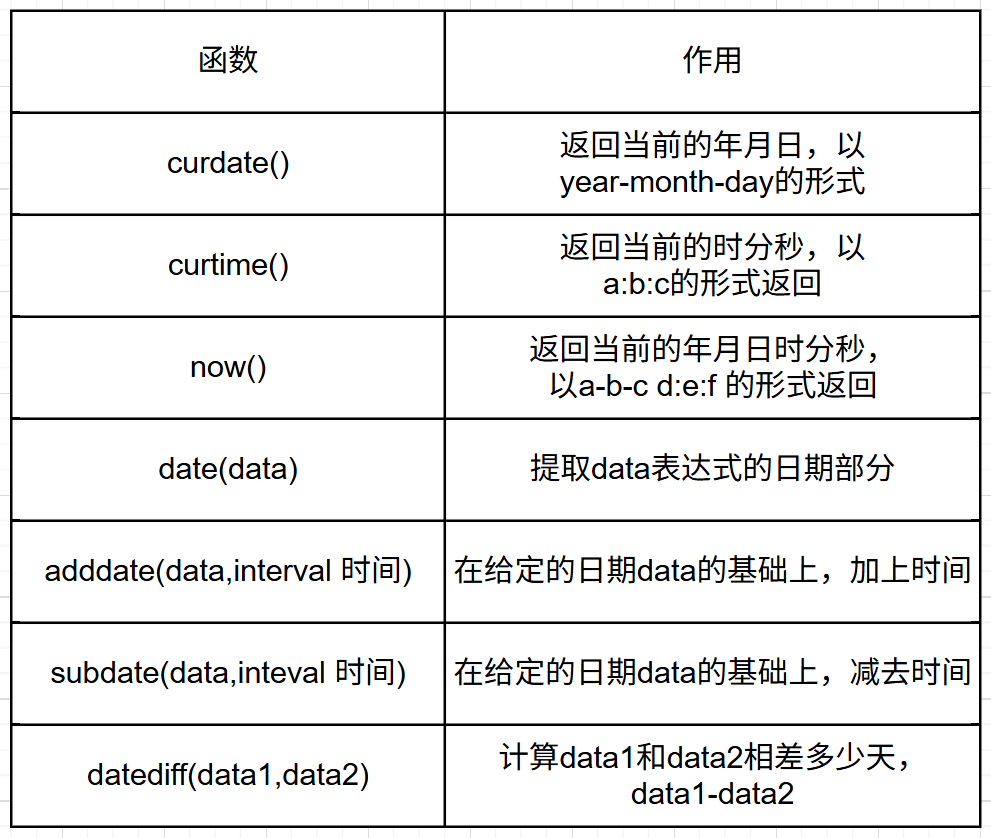
示例如下:
sql
select curdate();
select curtime();
select now();
select date('2018-01-01 11:12:13');
select adddate('2018-01-01 11:12:13',interval 5 month);
select subdate('2018-01-01 11:12:13',interval 1 day);
select datediff('2018-01-01 11:12:13','2016-01-01');12.2 字符串处理函数
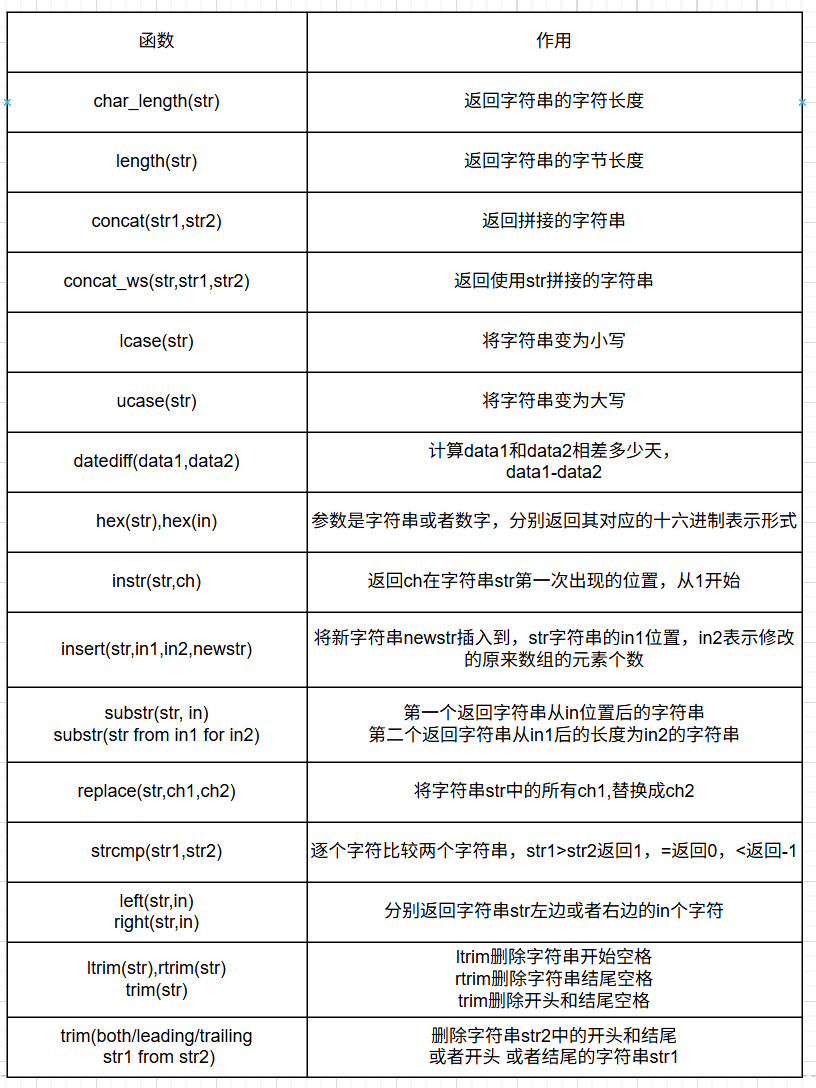
演示示例:
sql
select char_length('hello');
select length('hello');
select concat('hello','world');
select concat_ws('_','hello','world');
select lcase('HELLO');
select ucase('hello');
select hex('hello');
select hex(100);
select instr('hello','e');
select insert('hello',2,1,'aaaaa');
select substr('hello',2);
select substr('hello' from 2 for 3);
select replace('hello','l','a');
select strcmp('hello','hel');
select left('hello',2);
select right('hello',2);
select ltrim(' hello ');
select rtrim(' hello ');
select trim(' hello ');
select trim(both 'aaa' from 'aaabbbaaa');
select trim(leading 'aaa' from 'aaabbbaaa');
select trim(trailing 'aaa' from 'aaabbbaaa');12.3 数学函数
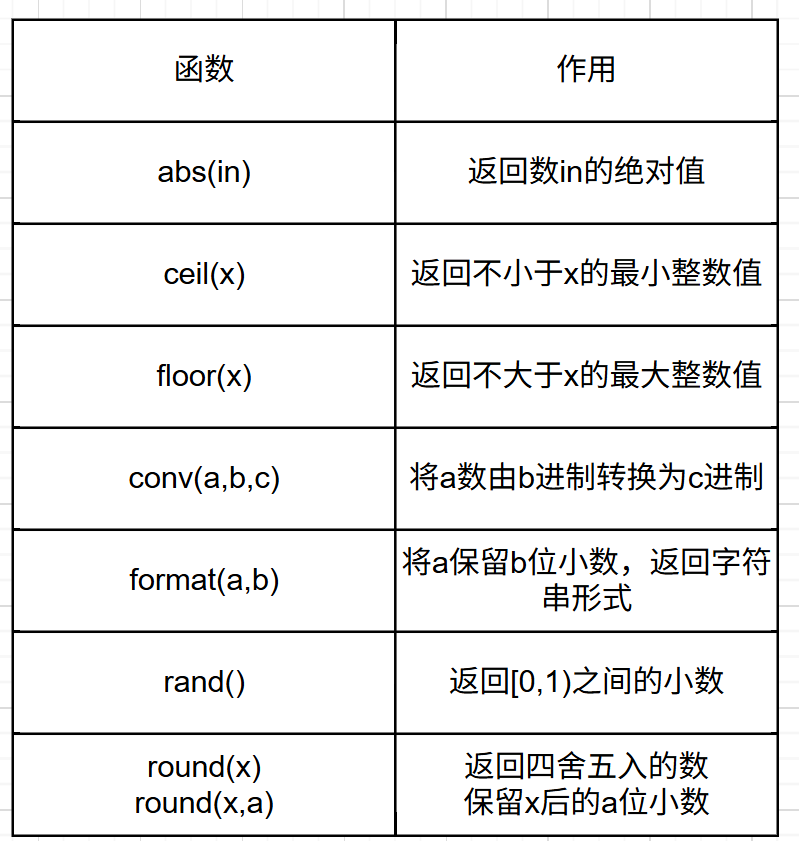
演示:
sql
select abs(-1);
select ceil(3.14);
select ceil(-3.14);
select floor(3.14);
select conv(11,10,16);
select format(3.1415926,3);
select rand();
select floor(rand() * 100 + 1);
select round(3.1436,2);12.4 其他常用函数
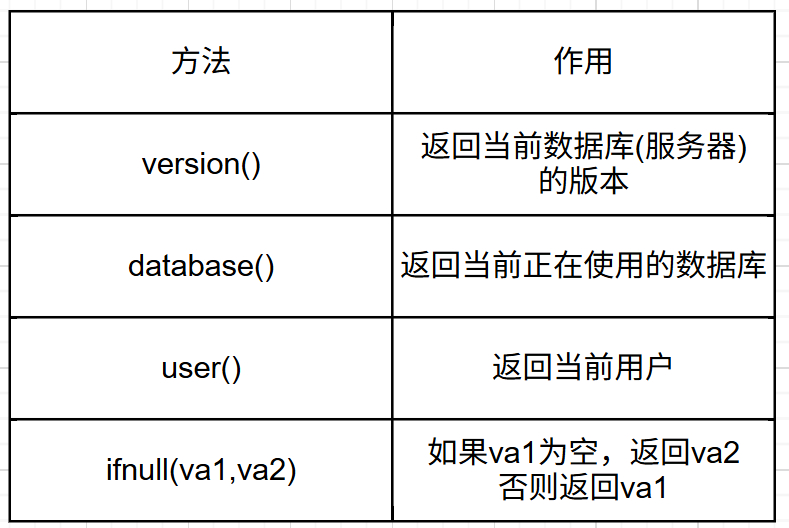
演示:
sql
select version();
select database();
select user();
select ifnull('hello','world');
select ifnull(null,'world');
select ifnull('hello',null);