大家国庆节快乐!
今天不聊那些高大上的概念,就讲一个真实的事故------因为缓存穿透,我们整个后台系统在凌晨瘫痪了半小时。
当时的情况是这样的:警报响了,数据库CPU 100%。我们第一反应是流量暴增,赶紧去看监控大盘,结果发现QPS稳如老狗。那感觉,就像家里漏水淹了,却找不到水管哪里破了,非常诡异。
靠着链路追踪,我们最终锁定了一个请求:它在疯狂查询一个早已下架的冷门商品,product_114514。这个key在Redis里没有,这很正常;但诡异的是,它在MySQL里也根本不存在。每一个这样的请求,都像拿着假通行证,顺利通过了缓存关卡,然后结结实实地砸在数据库上。
这就是缓存穿透。说白了,就是有人(大概率是脚本小子)在持续请求一个系统中根本不存在的数据。你的缓存形同虚设,数据库成了直接的背锅侠。
当时的流量路径是这样的
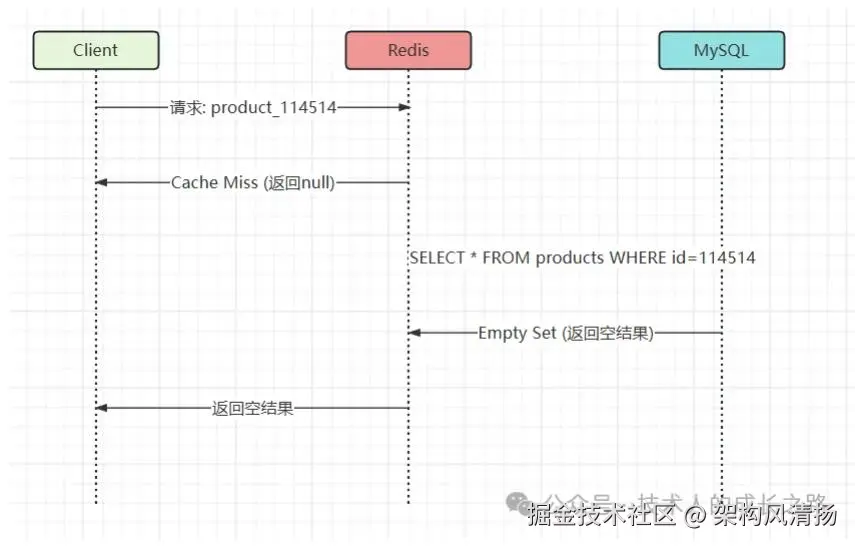
关键点在于,每一次请求,都完整地走完了这个链条。 如果每秒有1万个这样的请求,数据库就要执行1万次毫无意义的查询。
我们走过的弯路:缓存空对象
当时我们团队的第一个反应很直接:"既然数据库查不到,那就在Redis里存个空值,比如"",设置个短一点的有效期,比如5分钟,后续请求不就能拦截住了吗?"
我们当时的核心代码大概是这样的:
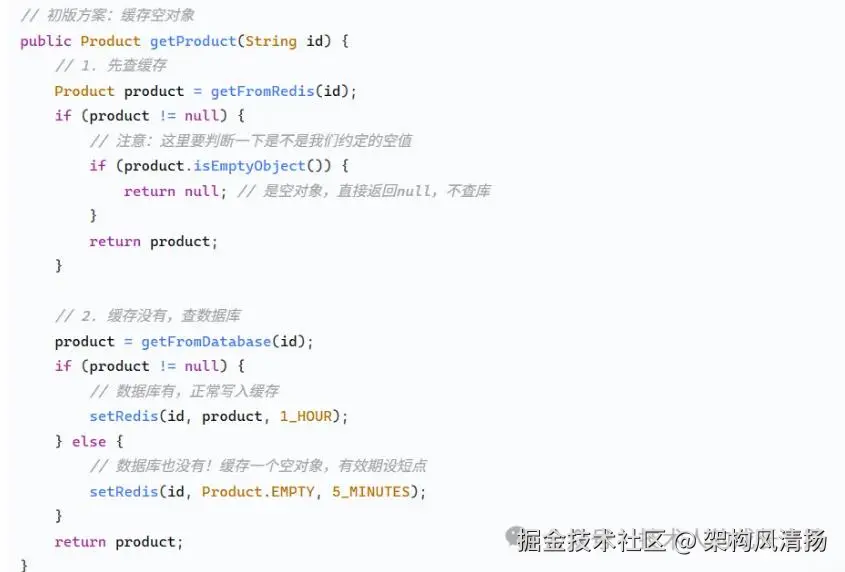
这方案上线后,警报立马就停了。我们当时还挺得意,觉得问题解决了。
结果没过一周,运维找过来了,说Redis内存使用率涨得有点离谱。一查才发现,攻击者换策略了,他开始用脚本海量生成不重复的随机ID。我们的Redis瞬间被几十万个不同的空key给塞满了。这个方案,等于用自己的内存去堵别人的枪眼,显然不是长久之计。
最终的解决方案:布隆过滤器
被逼到这个份上,我们才开始正经考虑布隆过滤器(Bloom Filter)。说实话,这玩意儿之前只在八股文里见过,真用还是头一回。
你可以把它理解成一个超级节省内存的"预检员"。它的核心就两句话:
-
如果它说某个key不存在 ,那这个key就肯定不存在。
-
如果它说某个key存在 ,那这个key有可能不存在(有微小的误判概率)。
注意,对我们防御缓存穿透的场景来说,我们只关心第一条,也就是它那100%准确的"不存在"判断。这就足够了。
我们在查询链路的最前面加上了这个"预检员":
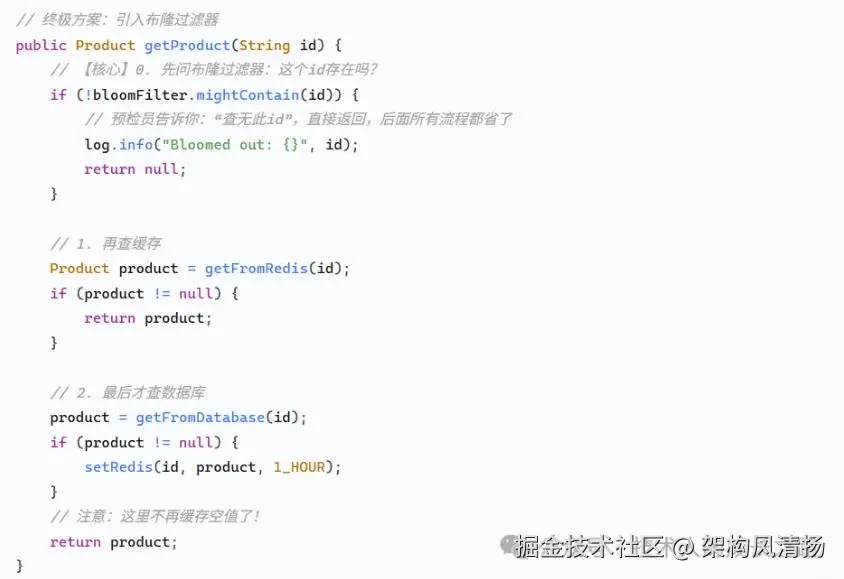
关于布隆过滤器,有几点必须说清楚:
-
它为啥省内存? 因为它底层是一个大位数组,只存0和1,不存原始数据。通过几个哈希函数把元素映射到几个位上,占用的空间比存完整的key小几个数量级。
-
误判怎么办? 比如它判断id product_191981存在,但实际数据库里没有。这种情况确实会发生,但概率可以通过参数配置得非常低(比如1%)。这个误判的后果,仅仅是多了一次缓存查询和一次数据库查询而已,而这种情况原本就会发生,所以完全在可接受范围内。
-
数据怎么来? 系统启动时,我们需要把数据库里所有有效的商品ID全部预加载到布隆过滤器中。后续有新的商品上架,也需要实时地put进去。
工程上怎么搞?
方案定了,落地就简单了:
-
Redis Module (推荐):我们最后用的是Redis自带的Bloom Filter模块。用BF.RESERVE命令创建一个过滤器,然后通过BF.ADD添加元素,BF.EXISTS判断存在性。性能和运维都集成在Redis里,非常方便。
-
Guava (单机版):如果用的是Java,并且是单机服务,Guava库里的BloomFilter类开箱即用,几行代码就能集成。
事后复盘
这次事故给我们最大的教训就是:别等到系统挂了才想起容错和防护。
在设计缓存这种核心组件时,不能只想着阳光明媚的日子。你得提前设想各种极端情况:海量的不存在的key、恶意的爬虫、突如其来的热点等等。在架构设计的第一天,就要把这些异常情况作为需求考虑进去,而不是事后打补丁。
布隆过滤器就是我们为"缓存穿透"这个特定场景设置的一道防火墙。它成本极低,效果立竿见影,让我们终于能睡个安稳觉了。
希望我们这次踩坑、填坑的经历,能给你们提个醒。下次设计系统的时候,不妨多问自己一句:"要是有人一直请求不存在的数据,我的系统顶得住吗?"
思考题:除了在Redis层面做好防御控制,从整个系统的架构设计中,我们还可以做哪些工作?欢迎你留言探讨