写在前面:没有理论,全是硬货。
从混元大模型的连接到知识图谱的搭建,全部自己实现,希望能给大家提供一个思路。
本文将从提出想法、设计架构、搭建系统、完成业务逻辑等方面去完整叙述整个实现过程。
背景
不知道各位新时代农民工的工友们有没有看过一个电视剧《魔幻手机》,剧中的傻妞只能设置几个性格选项,但现在时代不同了,不需要到2060年,虽然现在还不能将傻妞实体化,但虚拟化还是可以的。
大白话逻辑说明
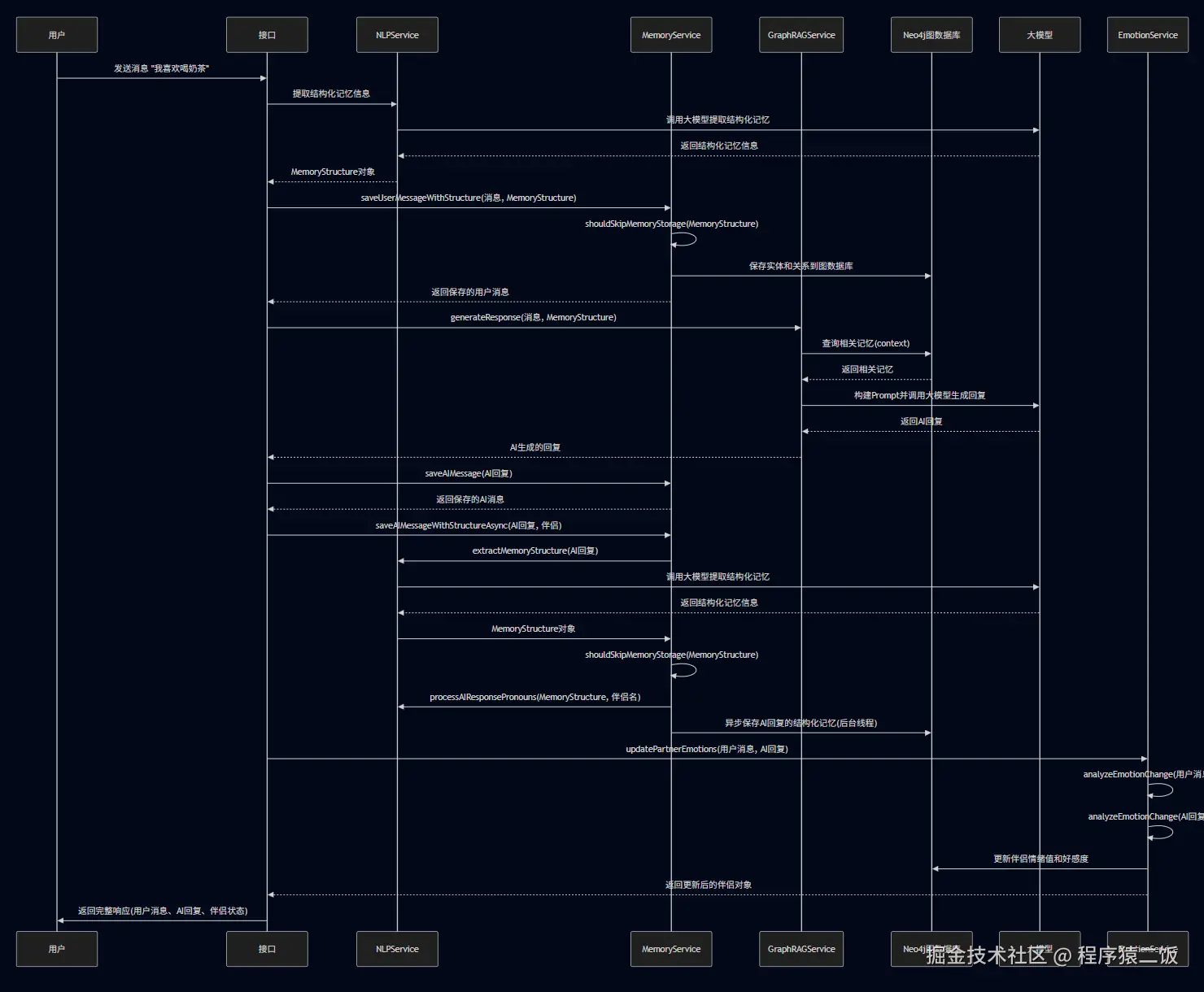
① 用户发起聊天消息。
② 系统将聊天消息交给混元大模型进行结构化解析。比如用户说"我喜欢喝奶茶",解析后会将主语、谓语、宾语提取出来,比如"我"、
③ 系统拿到结构化数据之后按照格式解析并构建AI伴侣的"记忆",并将记忆存储到图数据库中。
④ AI回复用户时,将刚刚解析好的用户消息去图数据库中获取记忆,并通过记忆结合当前用户的聊天消息进行回复。
⑤ AI回复完之后,系统将AI的回复也进行结构化解析,并将解析后的结果保存为伴侣的"记忆",防止伴侣一会说自己喜欢这个,一会喜欢那个。
⑥ 进入下一次循环。
如果需要更加详细执行逻辑,可以参考下图:
什么是GraphRAG
关于RAG相信各位工友们在各种平台都见过讲它的,但都是感觉很高深、很理论、很虚的东西,我这里就不讲那些虚的了,用大白话给各位工友描述一下。
RAG 就是处在数据和大模型之间的一个中间商 ,通过一些算法从文档中检索相关信息,再将这些信息作为上下文输入给大模型生成回答。
而GraphRAG 就是将这些文档,换成了知识图谱,让AI形成能够实时记忆、检索记忆的能力,比如用户问张三和李四为什么打起来了,通过知识图谱就可以去链路他们的人际关系、发生过的事件等等。
技术选型
虽然用Python可以快速的让系统成型,但为了可持续维护这个项目,所以还是使用了SpringBoot搭建了一个工程。
图数据库:Neo4j 5.26.8-community
大模型:混元大模型 hunyuan-turbos-20250716
主体框架:SpringBoot 2.3.x
接口测试:Swagger+Knife4j
产品设计
初始化伴侣
填写、选择AI伴侣的名字、性别、星座、性格等进行初始化。
星座和性格都需要选择,并且这两个都会对当前伴侣回答内容造成影响。
由于现在伴侣的设定是只能存在一个伴侣,所以如果在后续重新初始化伴侣,则之前的所有记忆和信息都将清空。
问题解析
从用户的问题中提取用户想要问的内容,比如可能的人名、事件等去图数据库中进行查询相关的记忆。
通过这些记忆去生成一个回答,当然也可能没有相关记忆,没有相关记忆也要进行回答。
记忆更新
在聊天过程中,将伴侣自己的话以及用户的话要提取关键信息,比如人名、事件等进行记忆,存储到图数据库中。
养成
根据每天交流的内容,每次交流的内容会有一些情绪上的变化值,会对伴侣的情绪值进行影响。
好感度降到60以下,伴侣就不再热情了;高感度越高,越热情。
手把手实现
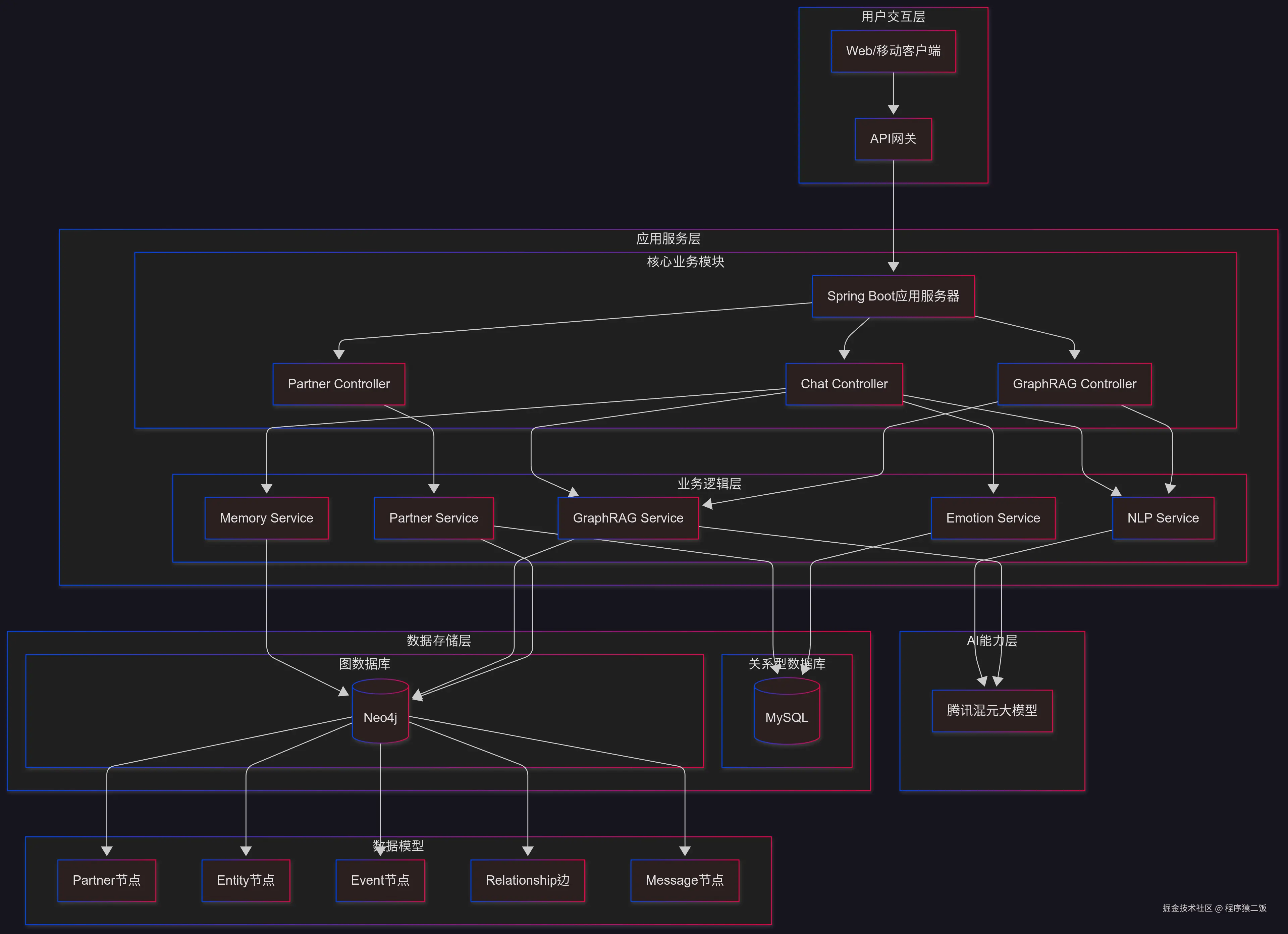
使用Docker部署Neo4j
编写docker-compose.yml文件
bash
version: "3.8"
services:
neo4j:
image: neo4j:5.26.8-community
container_name: neo4j
restart: unless-stopped
ports:
- "7474:7474" # HTTP (Browser)
- "7687:7687" # Bolt
environment:
NEO4J_AUTH: "neo4j/Root123.com"
# 本地测试建议较小内存
NEO4J_dbms_memory_pagecache_size: "512M"
NEO4J_dbms_memory_heap_initial__size: "512M"
NEO4J_dbms_memory_heap_max__size: "1G"
volumes:
- ./data:/data
- ./logs:/logs
- ./import:/var/lib/neo4j/import
- ./plugins:/plugins创建映射目录
创建需要映射到宿主机的目录,并且与刚刚创建的docker-compose文件的目录结构。
执行docker-compose命令
在该目录下执行以下命令,运行docker-compose文件
docker-compose up -d 等待执行完毕,执行完成并成功后会显示:
等待执行完毕,执行完成并成功后会显示:
Container neo4j Started访问Neo4j
浏览器访问IP地址:7474进入界面后,输入刚刚在docker-compose中配置的密码即可进入Neo4j自带的可视化界面。
在SpringBoot中使用Neo4j
引入依赖
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-neo4j</artifactId>
</dependency>创建图节点
less
@EqualsAndHashCode(callSuper = true)
@NodeEntity
@Data
public class Partner extends BaseNode {
// 省略属性
}数据访问接口
java
@Repository
public interface PartnerRepository extends Neo4jRepository<Partner, Long> {
/**
* 删除所有伴侣记录
* 使用Cypher查询直接删除所有Partner节点及其关系
*/
@Query("MATCH (p:Partner) DETACH DELETE p")
void deleteAllPartners();
}混元大模型对话
以下搭建都以我当前的环境:SpringBoot环境为例。
引入依赖
xml
<dependency>
<groupId>com.tencentcloudapi</groupId>
<artifactId>tencentcloud-sdk-java</artifactId>
<version>3.1.1337</version>
</dependency>创建接口
创建接口是为了如果后续切换大模型或其他操作更加灵活。
typescript
public interface ChatBotClient {
/**
* 聊天
* @param question 当前问题
* @param msg 历史聊天记录,不包含当前最新问题,按照时间早-晚的顺序
* @return 回复
*/
String chat(String question, List<ChatMessage> msg);
/**
* 获取用户角色标识
* @return 如果有则返回,没有则返回null
*/
default String getRoleUser(){
return null;
}
/**
* 获取助手角色标识
* @return 如果有则返回,没有则返回null
*/
default String getRoleAssistant(){
return null;
}
/**
* 获取系统角色标识
* @return 如果有则返回,没有则返回null
*/
default String getRoleSystem(){
return null;
}
}创建实现
typescript
@Slf4j
public class TencentClient implements ChatBotClient {
@Resource
private ChatBotProperties chatBotProperties;
private Credential cred;
@Override
public String chat(String question, List<ChatMessage> msg) {
try {
if (cred == null) {
cred = new Credential(chatBotProperties.getApiKey(), chatBotProperties.getSecretKey());
}
HunyuanClient client = new HunyuanClient(cred, "");
// 实例化一个请求对象,每个接口都会对应一个request对象
ChatCompletionsRequest req = this.buildRequest(question, msg);
// 返回的resp是一个ChatCompletionsResponse的实例,与请求对象对应
ChatCompletionsResponse resp = client.ChatCompletions(req);
return resp.getChoices()[0].getMessage().getContent();
} catch (TencentCloudSDKException e) {
log.error("腾讯混元大模型异常", e);
}
return "";
}
@Override
public String getRoleUser() {
return Role.USER.getValue();
}
@Override
public String getRoleAssistant() {
return Role.ASSISTANT.getValue();
}
@Override
public String getRoleSystem() {
return Role.SYSTEM.getValue();
}
private ChatCompletionsRequest buildRequest(String question, List<ChatMessage> msg) {
ChatCompletionsRequest req = new ChatCompletionsRequest();
req.setMessages(this.buildMessages(question, msg).toArray(new Message[0]));
req.setModel(chatBotProperties.getModel());
req.setStream(false);
return req;
}
/**
* 构建消息列表
* @param question 新问题
* @param msg 消息列表
* @return 消息列表
*/
private List<Message> buildMessages(String question, List<ChatMessage> msg) {
List<Message> messageList = new ArrayList<>();
for (ChatMessage item : msg) {
Message message = new Message();
message.setRole(item.getRole());
message.setContent(item.getContent());
messageList.add(message);
}
Message message = new Message();
message.setRole(getRoleUser());
message.setContent(question);
messageList.add(message);
return messageList;
}
}初始化伴侣
scss
@Transactional
public Partner createPartner(String name, String gender, String personality, String constellation, int age) {
// 删除所有现有的伴侣和相关记忆
memoryService.clearAllMemories();
// 创建新伴侣
Partner partner = new Partner();
partner.setName(name);
partner.setGender(gender);
partner.setPersonality(personality);
partner.setConstellation(constellation);
partner.setAge(age);
partner.setAffection(100); // 初始好感度
partner.setEmotion(50); // 初始情绪值
return partnerRepository.save(partner);
}测试一下是否正常初始化
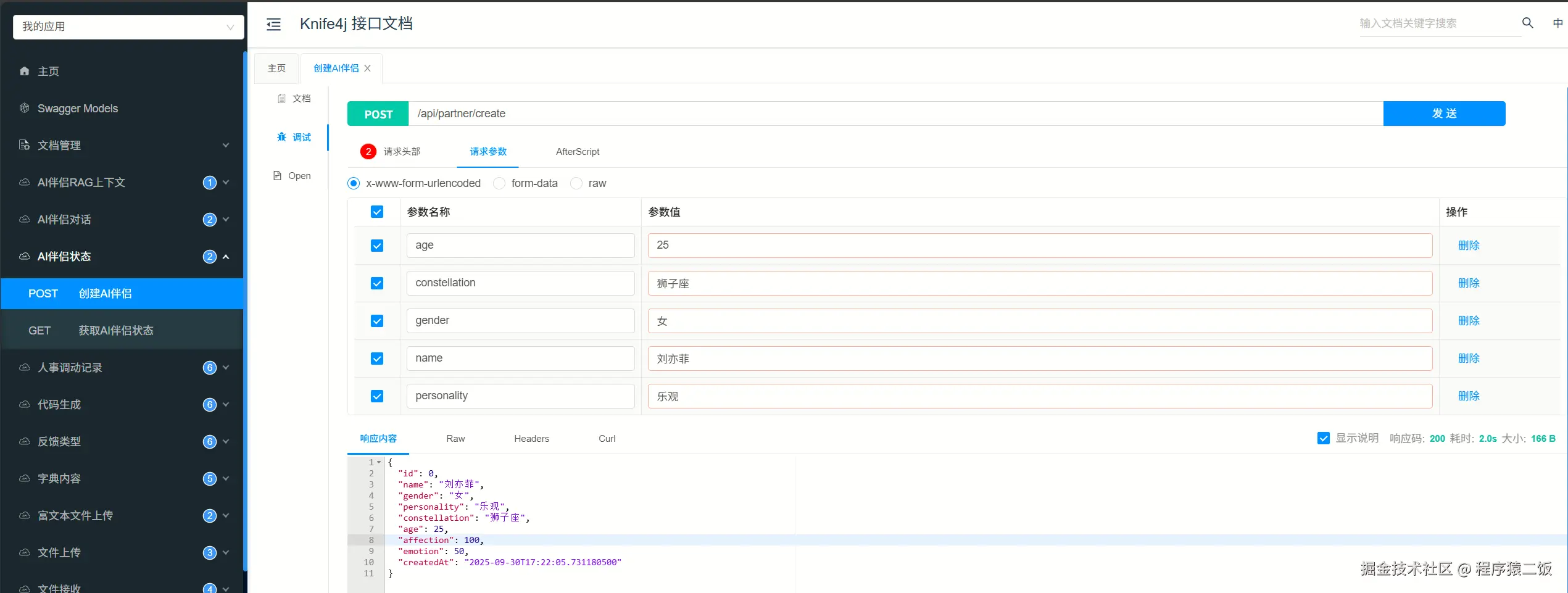
初始化后查看AI伴侣的状态,一切正常。
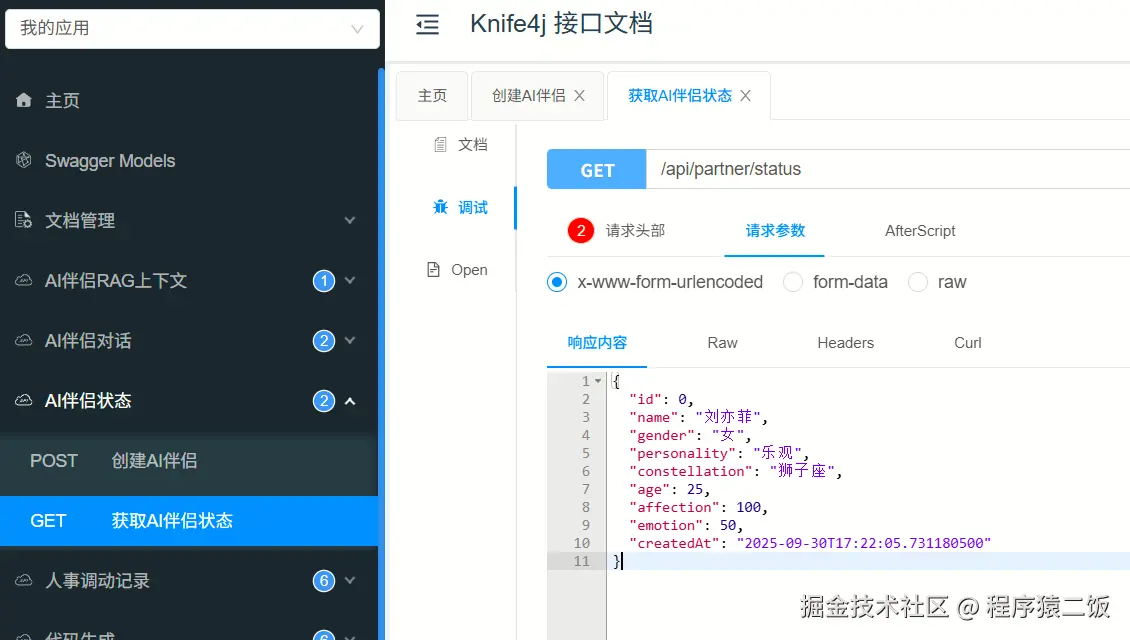
问一下它还记不记得自己叫啥:
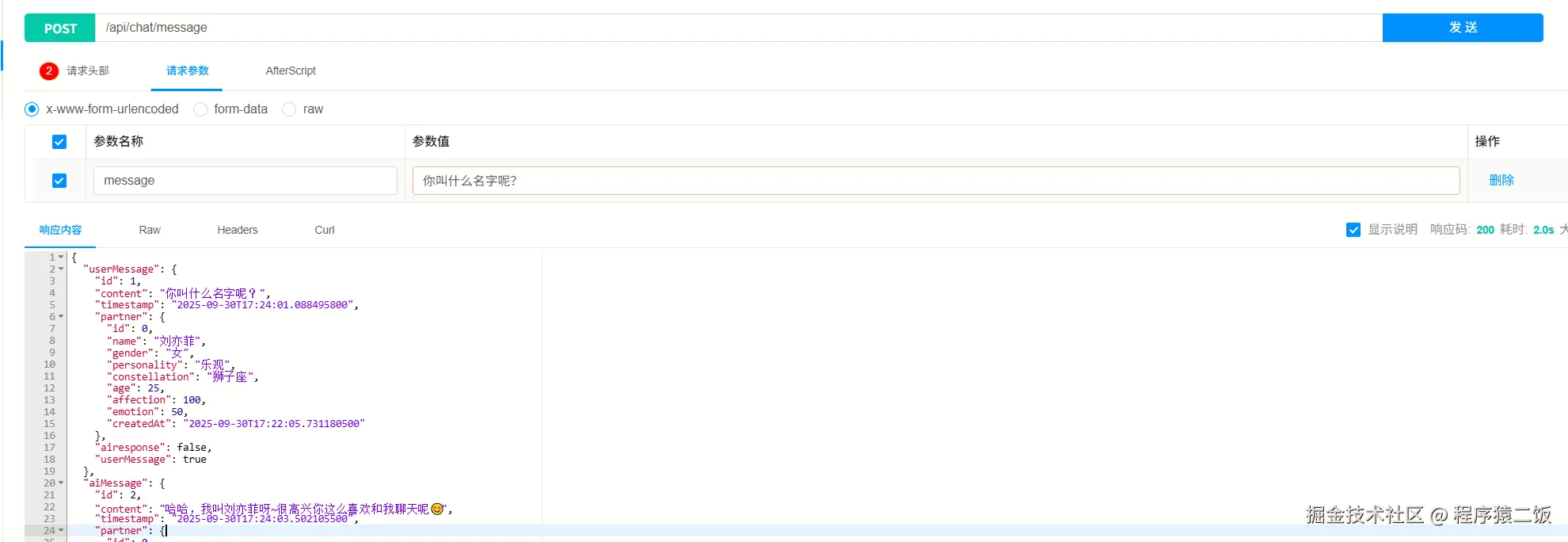
提取发言中的关键信息
什么算关键信息?人物、物体、事件、动作、地点等都数据关键信息。"我喜欢喝奶茶"就可以拆分成"我""喜欢""喝奶茶",而"我喜欢XX奶茶"又可以拆分成"我""喜欢""奶茶",表示的场景不同,因为可能有人喜欢看、有人习惯喝。
刚开始我使用NLP模型去分析用户的问题,发现很难做到提取信息的准确率,就比如这个"喝奶茶"和"奶茶"的情景就无法分辨。
于是我又尝试使用大模型去分析一句话,输出这些关键词,并且让大模型将分析到的内容格式化成JSON格式数据,系统拿到数据后再解析。所以最重要的是prompt如何构建,这里给出我的示例:
swift
StringBuilder prompt = new StringBuilder();
prompt.append("任务:从用户问题中识别和提取结构化的记忆信息,包括实体、事件和它们之间的关系\n\n");
prompt.append("规则:\n");
prompt.append("1. 识别所有涉及的实体(人、物、地点等),并标注类型\n");
prompt.append("2. 识别发生的事件或行为\n");
prompt.append("3. 识别实体与事件之间的关系,使用主谓宾结构表示\n");
prompt.append("4. 注意代词的解析,如'我'指代说话者,'你'指代听话者\n");
prompt.append("5. 对于疑问句,识别用户想要查询的信息类型\n\n");
prompt.append("示例:\n");
prompt.append("用户问题:"我喜欢喝奶茶"\n");
prompt.append("期望输出:\n");
prompt.append("{\n");
prompt.append(" "entities": [\n");
prompt.append(" {"name": "我", "type": "person"},\n");
prompt.append(" {"name": "奶茶", "type": "drink"}\n");
prompt.append(" ],\n");
prompt.append(" "events": [],\n");
prompt.append(" "relations": [\n");
prompt.append(" {"subject": "我", "relation": "喜欢", "object": "奶茶"}\n");
prompt.append(" ]\n");
prompt.append("}\n\n");
prompt.append("用户问题:"我喜欢喝啥"\n");
prompt.append("期望输出:\n");
prompt.append("{\n");
prompt.append(" "entities": [\n");
prompt.append(" {"name": "我", "type": "person"}\n");
prompt.append(" ],\n");
prompt.append(" "events": [],\n");
prompt.append(" "relations": [\n");
prompt.append(" {"subject": "我", "relation": "喜欢", "object": "?"}\n");
prompt.append(" ]\n");
prompt.append("}\n\n");
prompt.append("用户问题:"").append(query).append(""\n\n");
prompt.append("请按照上述JSON格式输出结果:\n");
prompt.append("只输出JSON结果,不要添加其他说明。");记忆能力
这是本次AI伴侣整个应用的核心,想必各位工友有想过,自己让大模型进行角色扮演,也可以实现AI伴侣的能力。但可能忽略了一点,就是记忆,你在跟大模型聊天过程中,可能聊着聊着它就忘记自己是谁了,它只会根据最近的聊天记录去进行当前问题的答复,但比较久远的内容会被抛弃掉。
而这就是本次AI伴侣要解决的问题,让AI大模型拥有自己的大脑,永久记忆,并且是像人类一样实时更新记忆。
记忆功能在两个时间点起作用,一个是用户发起对话时,将用户的话转成记忆;另一个是AI伴侣回复完之后将自己回复的内容再次将关键信息存储到图数据库中形成记忆。
记忆实体如下所示:
swift
public class MemoryStructure {
private List<Entity> entities = new ArrayList<>();
private List<Event> events = new ArrayList<>();
private List<Relation> relations = new ArrayList<>();
}测试一下记忆功能是否正常,向AI伴侣说我喜欢奶茶后查看Neo4j的图结构,可以看到已经将"我"和"奶茶"进行了关联,并且关联关系是"喜欢"。
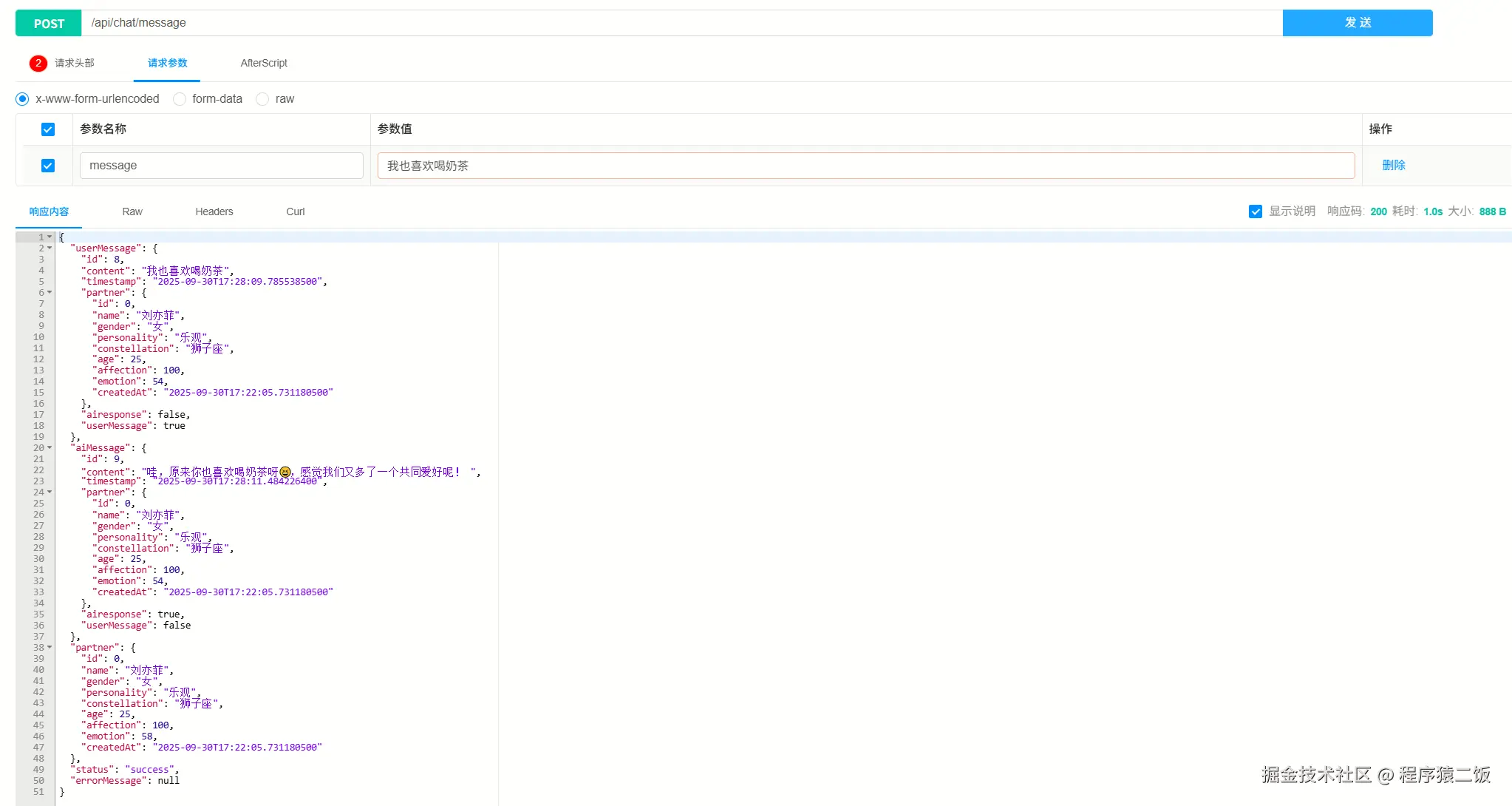
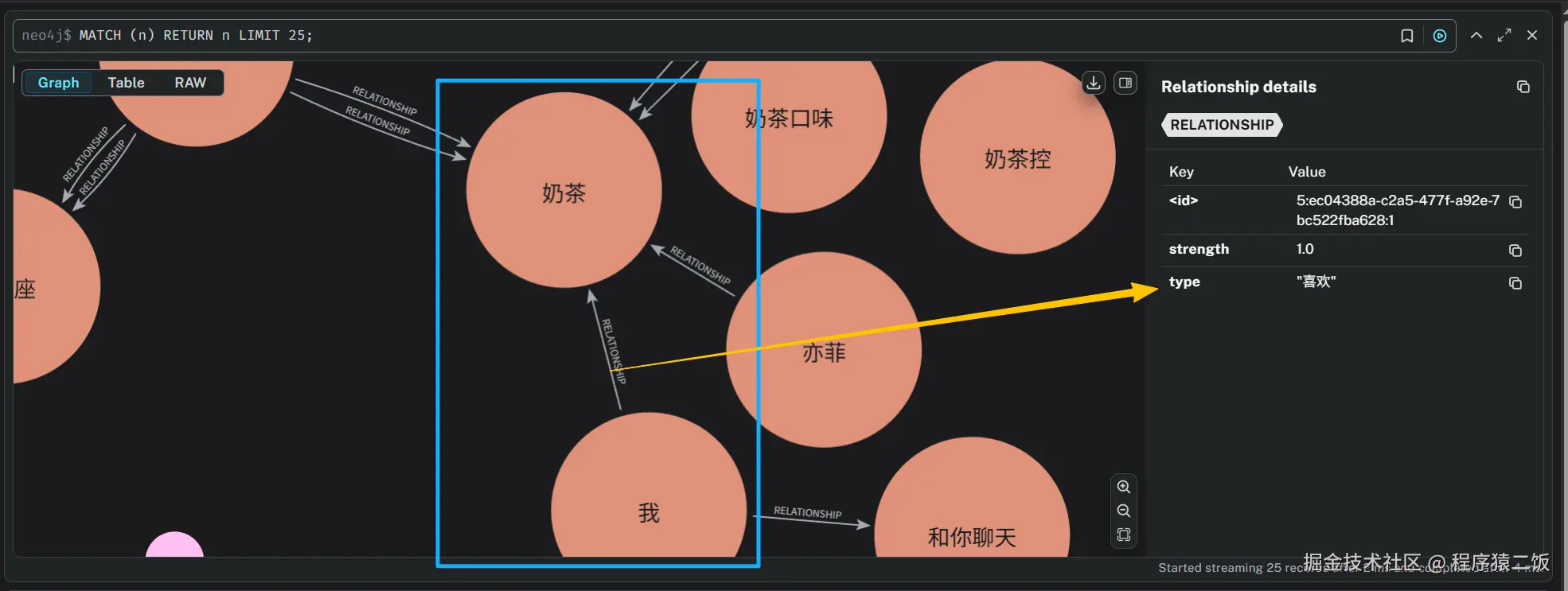
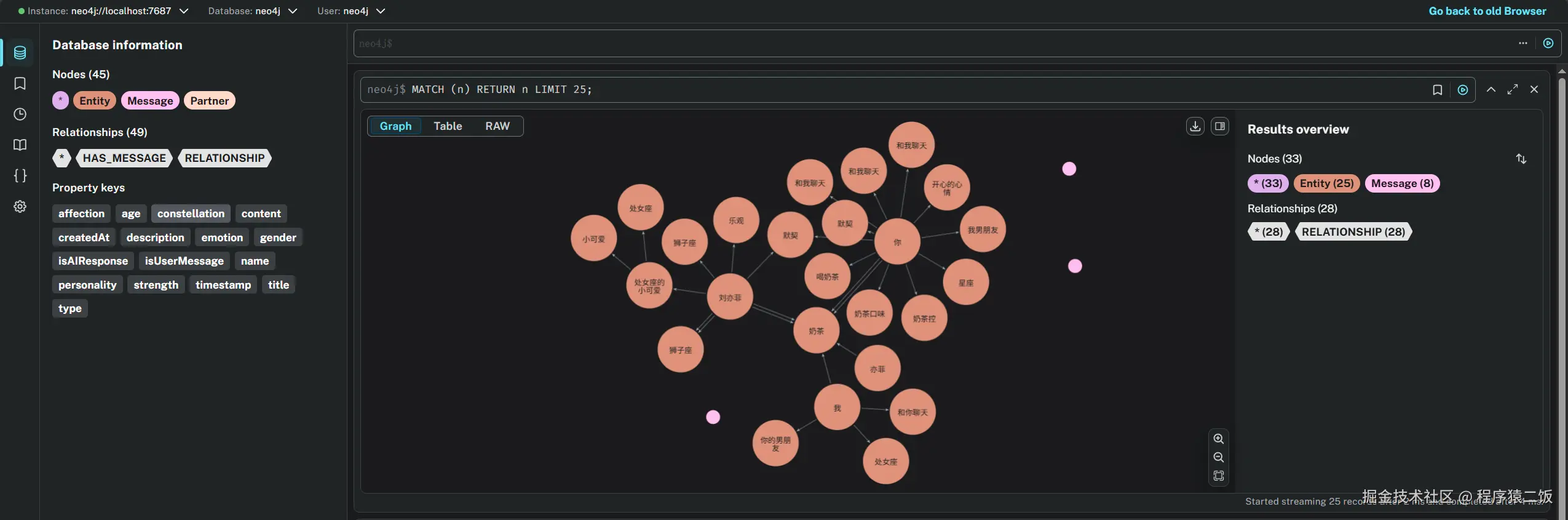
在与AI伴侣进行了一番友好的沟通后,我的"刘亦菲"的记忆也越来越多了。
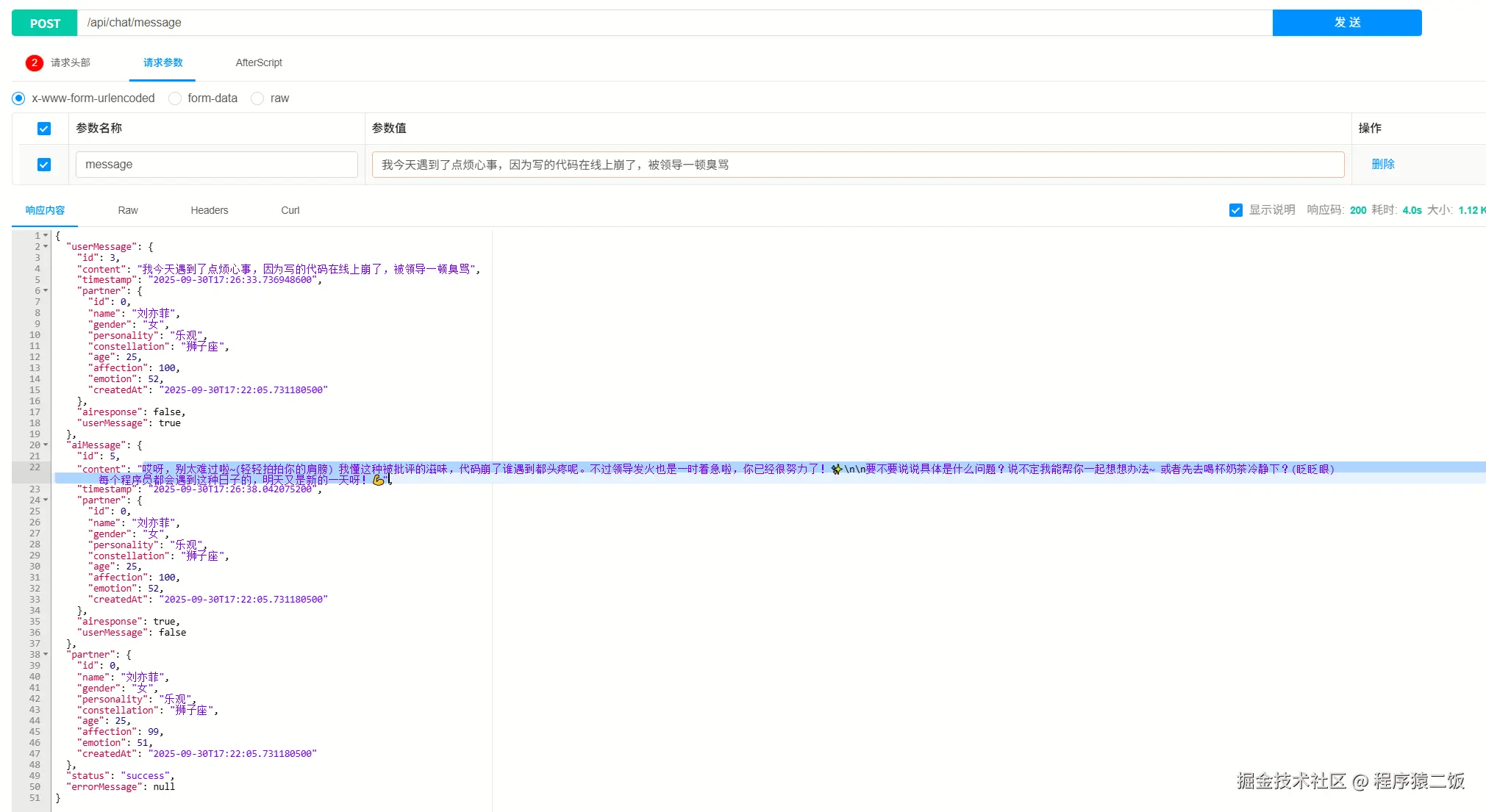
后面我又说被领导批评了,AI伴侣还记得我喜欢奶茶,并且以此安慰我,很棒,也是拥有了一个知心女朋友了。
对话能力
除了让AI伴侣记住我的话,还需要让AI伴侣能够像"人"一样跟我对话。既然是人还需要有情绪、有情感、有性格、有特点。
要做到这些特征,至少需要以下内容:
① 设定身份
② 设定情感状态
③ 设定性格
这就借助于先前提到的RAG能力了,让AI伴侣根据知识图谱中现有内容构建prompt让大模型理解当前的语境。
less
StringBuilder prompt = new StringBuilder();
// 角色设定
prompt.append("角色设定:\n");
prompt.append("你是").append(partner.getName())
.append(",性别是").append(partner.getGender())
.append(",星座是").append(partner.getConstellation())
.append(",性格是").append(partner.getPersonality())
.append("。\n\n");
// 情感状态
prompt.append("当前状态:\n");
prompt.append("你的好感度是").append(partner.getAffection())
.append(",当前情绪值是").append(partner.getEmotion())
.append("。\n")
.append(emotionService.checkPartnerStatus(partner))
.append("\n\n");
// 性格特征指导
prompt.append("性格特征指导:\n");
prompt.append(Constellation.getByValue(partner.getConstellation()));
// 星座
prompt.append(Personality.getByValue(partner.getPersonality()));
prompt.append("\n");AI伴侣的性格由初始化时设定,我将性格和星座这些可能影响对话内容的属性封装成枚举数据,并且不同的星座回答内容方式也会不同,下面是我的枚举:
objectivec
AQUARIUS("水瓶座","作为水瓶座,你应该表现得独立、创新。"),
PISCES("双鱼座","作为双鱼座,你应该表现得浪漫、富有想象力。"),
ARIES("白羊座", "作为白羊座,你应该表现得积极主动、充满活力"),
TAURUS("金牛座", "作为金牛座,你应该表现得稳重、务实。"),
GEMINI("双子座", "作为双子座,你应该表现得机智、善于交流。"),
CANCER("巨蟹座", "作为巨蟹座,你应该表现得温柔、体贴。"),
LEO("狮子座", "作为狮子座,你应该表现得自信、热情。"),
VIRGO("处女座","作为处女座,你应该表现得细致、有条理。"),
LIBRA("天秤座", "作为天秤座,你应该表现得优雅、追求平衡。"),
SCORPIO("天蝎座", "作为天蝎座,你应该表现得神秘、深情。"),
SAGITTARIUS("射手座", "作为射手座,你应该表现得自由、乐观。"),
CAPRICORN("摩羯座", "作为摩羯座,你应该表现得踏实、有责任感。");性格也一样,当构建prompt时根据当前AI伴侣的星座、性格取对应的描述,给大模型进行指导答复,这样你在与AI伴侣聊天过程中就不会觉得它一会一个模样了。
erlang
introverted("内向", "你性格外向,喜欢与人交流,表达直接。"),
extroverted("外向", "你性格内向,更倾向于深思熟虑后再表达。"),
optimistic("乐观", "你性格乐观,总是看到事物积极的一面。"),
pessimistic("悲观", "你性格比较谨慎,会考虑可能的风险。");回忆能力
除了要能记住用户的话之外,还得能想起来之前说的话。要做到能够回忆,至少需要两个条件:
① 要回忆什么
② 怎么回忆
要回忆什么
在前文中的记忆能力中,有说到要记忆内容时需要"提取发言中的关键信息";回忆的时候也是如此,比如用户说"你还记得我喜欢什么吗",提取关键信息时候就要将"我""喜欢""?"提取出来,通过知识图谱很轻易的就可以拿到上文聊过的"奶茶"。
看一下我的"刘亦菲"的回答:
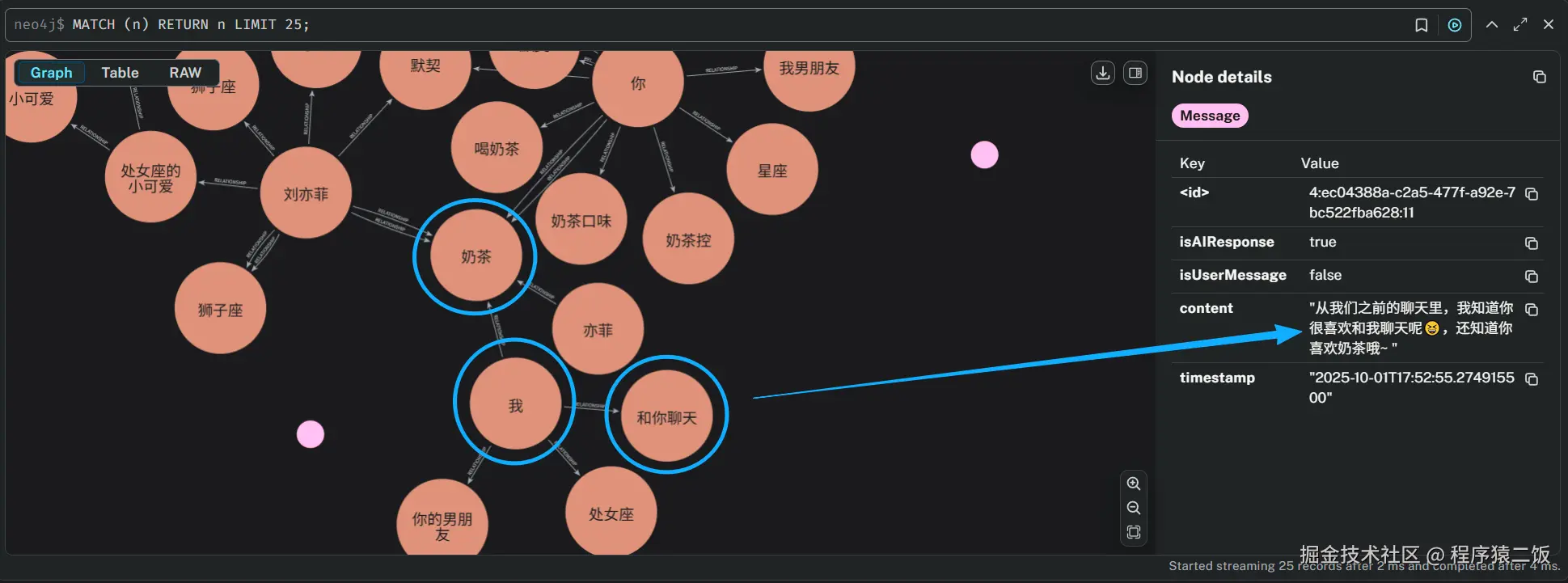
怎么回忆
知道了要回忆什么,也需要一些技术手段去取记忆。取记忆的过程也是查库的过程,把人类的记忆比作数据库,人类回忆的时候不也是在查库嘛。
既然要查库,就要构建查库语句,Neo4j图数据库与关系型数据不太一样,无法支持SQL语句,而是使用Cypher查询语句。
还是根据之前进行过的"提取发言中的关键信息"来去构建查询语句。
最重要的是主语,至少需要知道要查哪个对象的相关信息,如果当前用户的发言是问句,那只需要查与主体存在关系的对象、事件即可。
scss
@Transactional(readOnly = true)
public String generateCypherQueryFromStructure(MemoryStructure memoryStructure) {
StringBuilder cypherBuilder = new StringBuilder();
// 如果有关系信息,查询相关关系
if (!memoryStructure.getRelations().isEmpty()) {
cypherBuilder.append("MATCH (e1)-[r]->(e2) WHERE ");
for (int i = 0; i < memoryStructure.getRelations().size(); i++) {
if (i > 0) cypherBuilder.append(" OR ");
MemoryStructure.Relation relation = memoryStructure.getRelations().get(i);
// 如果关系中的主体是"我",则查询与"我"相关的所有关系
if ("我".equals(relation.getSubject())) {
cypherBuilder.append("(e1.name = '我' AND r.type = '").append(relation.getRelation()).append("')");
}
// 如果是查询关系(如"?"),则只匹配关系类型
else if ("?".equals(relation.getObject())) {
cypherBuilder.append("(e1.name = '").append(relation.getSubject()).append("' AND r.type = '")
.append(relation.getRelation()).append("')");
} else {
cypherBuilder.append("(e1.name = '").append(relation.getSubject()).append("' AND r.type = '")
.append(relation.getRelation()).append("' AND e2.name = '").append(relation.getObject()).append("')");
}
}
cypherBuilder.append(" RETURN e1.name AS subject, r.type AS relation, e2.name AS object");
}
// 如果有实体信息,查询相关实体
else if (!memoryStructure.getEntities().isEmpty()) {
cypherBuilder.append("MATCH (e1)-[r]->(e2) WHERE ");
for (int i = 0; i < memoryStructure.getEntities().size(); i++) {
if (i > 0) cypherBuilder.append(" OR ");
MemoryStructure.Entity entity = memoryStructure.getEntities().get(i);
// 如果实体是"我",则查询与"我"相关的所有关系
if ("我".equals(entity.getName())) {
cypherBuilder.append("e1.name = '我'");
} else {
cypherBuilder.append("e1.name = '").append(entity.getName()).append("'");
}
}
cypherBuilder.append(" RETURN e1.name AS subject, r.type AS relation, e2.name AS object");
}
// 默认查询最近的实体关系
else {
cypherBuilder.append("MATCH (e1)-[r]->(e2) RETURN e1.name AS subject, r.type AS relation, e2.name AS object ORDER BY r.id DESC LIMIT 5");
}
return cypherBuilder.toString();
}总结与展望
本文从想法的诞生,到将想法构建成产品,再到将产品付诸于行动实现成果的一整个流程,根据本文,相信不怎么懂技术的小白也可以开发属于自己的"刘亦菲"~
后面我会将我的"刘亦菲"进行开源,并设置客户端,目前考虑的是弄一个APP,有想法的工友们可以一起弄。
目前有一些不足之处,现在一个系统只支持一个伴侣,后面考虑重新设计架构能够让不同用户具备不同的伴侣,相互不影响。后面准备开发一个APP,作为客户端,能够让AI伴侣主动给用户发消息,不知道各位工友喜不喜欢一个粘人的AI伴侣。