点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月29日更新到: Java-136 深入浅出 MySQL Spring Boot @Transactional 使用指南:事务传播、隔离级别与异常回滚策略 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节完成了如下的内容:
- DataStreamAPI介绍
- 基于文件、Socket、基于集合
- 编写代码进行测试
- Kafka连接器

非并行源
基本介绍
在 Apache Flink 中,非并行源(Non-Parallel Source)是一种特殊的源操作(Source Operator),它的最大并行度被限制为 1。这意味着,无论 Flink 集群中有多少个 Task Manager 和 Slot,该源操作都只能在一个并行实例中运行。
主要特点
- 单线程执行 :非并行源始终以并行度 1 运行,即使通过
setParallelism()方法设置更高的并行度也无效 - 资源独占:会占用一个完整的 Task Slot,即使该 Slot 的计算资源不能被充分利用
- 顺序处理:保证数据处理的顺序性,适合需要严格顺序保证的场景
典型应用场景
- 单点数据源:如从单个文件、单个数据库连接或单个消息队列分区读取数据
- 状态集中管理:需要维护全局状态的场景,比如全局计数器
- 外部系统限制:某些外部系统(如旧版数据库)可能不支持并发连接
实现方式
在 Flink 中可以通过以下方式实现非并行源:
java
public class SingleSource implements SourceFunction<String> {
// 实现逻辑...
}
// 使用时
DataStream<String> stream = env.addSource(new SingleSource())
.setParallelism(1); // 显式设置为1性能考量
虽然非并行源简化了某些场景的实现,但需要注意:
- 可能成为整个作业的性能瓶颈
- 需要确保数据生成速率不会超过单个线程的处理能力
- 在故障恢复时,整个源需要重新启动
替代方案
对于需要并行处理但又要保证顺序的场景,可以考虑:
- 使用 Keyed Stream 配合分区保证
- 采用全局协调器模式
- 使用 Rescale 分区策略
这种设计通常用于处理那些不适合并行化的任务或需要集中处理的工作,特别是在需要保证严格顺序性或需要全局协调的场景下。
主要特点
单线程执行
- 非并行源采用单线程模型执行任务,所有操作都在同一个线程中顺序进行,不具备并行处理能力。
- 这种执行方式不会从多核CPU或多线程环境中获得性能提升,但可以保证操作的严格顺序性。
- 典型应用场景包括:
- 需要严格顺序处理的操作(如日志文件的顺序读取)
- 依赖全局状态且状态变化敏感的任务
- 对执行顺序有严格要求的业务流程
全局状态管理
- 由于在单线程环境中运行,非并行源可以轻松访问和修改全局状态,无需考虑并发冲突。
- 状态管理特点:
- 不需要复杂的同步机制(如锁、信号量等)
- 可以避免竞态条件和死锁问题
- 状态变更具有确定性,易于调试和追踪
- 适合需要频繁访问共享资源的场景,如:
- 全局计数器
- 系统配置信息
- 内存缓存管理
实现简单
- 非并行源在实现上具有明显优势:
- 不需要处理复杂的并行分片逻辑
- 不用考虑任务分配和负载均衡
- 无需实现线程间通信机制
- 典型简单实现案例:
- 文件读取器:顺序读取单个文件内容
- 时间戳生成器:按顺序产生时间戳
- 序列号生成器:生成连续递增的ID
- 开发维护成本低,特别适合:
- 原型开发
- 小型数据处理任务
- 对性能要求不高的应用场景
使用场景
- 时间戳生成:当需要在流处理作业中引入事件时间(Event Time)时,可以使用一个非并行源来生成时间戳。
- 控制输入:如从一个全局唯一的数据源(例如一个集中式消息队列)读取数据时,通常使用非并行源来确保顺序处理。
- 测试与调试:在开发和调试阶段,非并行源可以用于生成简单的测试数据流。
示例代码
java
// 创建一个非并行的自定义源
public class MyNonParallelSource implements SourceFunction<String> {
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isRunning) {
ctx.collect("Non-Parallel Source Data");
Thread.sleep(1000); // 模拟数据产生的延迟
}
}
@Override
public void cancel() {
isRunning = false;
}
}
// 在作业中使用非并行源
DataStream<String> stream = env.addSource(new MyNonParallelSource()).setParallelism(1);在上述示例中,MyNonParallelSource 是一个简单的自定义非并行源,每秒生成一条字符串数据,并且通过 setParallelism(1) 明确指定其并行度为 1。
注意事项
- 性能限制:由于非并行源仅在单个线程中执行,如果数据量较大或需要高吞吐量,可能成为系统的瓶颈。
- 容错与恢复:Flink 提供了检查点机制(Checkpointing)来保证故障恢复时的状态一致性。在使用非并行源时,确保源的状态可以在故障恢复时正确重放。
NoParallelSource
java
package icu.wzk;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
public class NoParallelSource implements SourceFunction<String> {
private Long count = 1L;
private boolean running = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (running) {
count ++;
ctx.collect(String.valueOf(count));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
}NoParallelSourceTest
java
package icu.wzk;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment;
public class NoParallelSourceTest {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> data = env.getJavaEnv().addSource(new NoParallelSource());
data.print();
env.execute("NoParallelSourceTest");
}
}运行结果
shell
3> 2
4> 3
5> 4
6> 5
7> 6
8> 7
1> 8
2> 9
3> 10
4> 11
5> 12
6> 13
7> 14运行过程的截图如下所示: 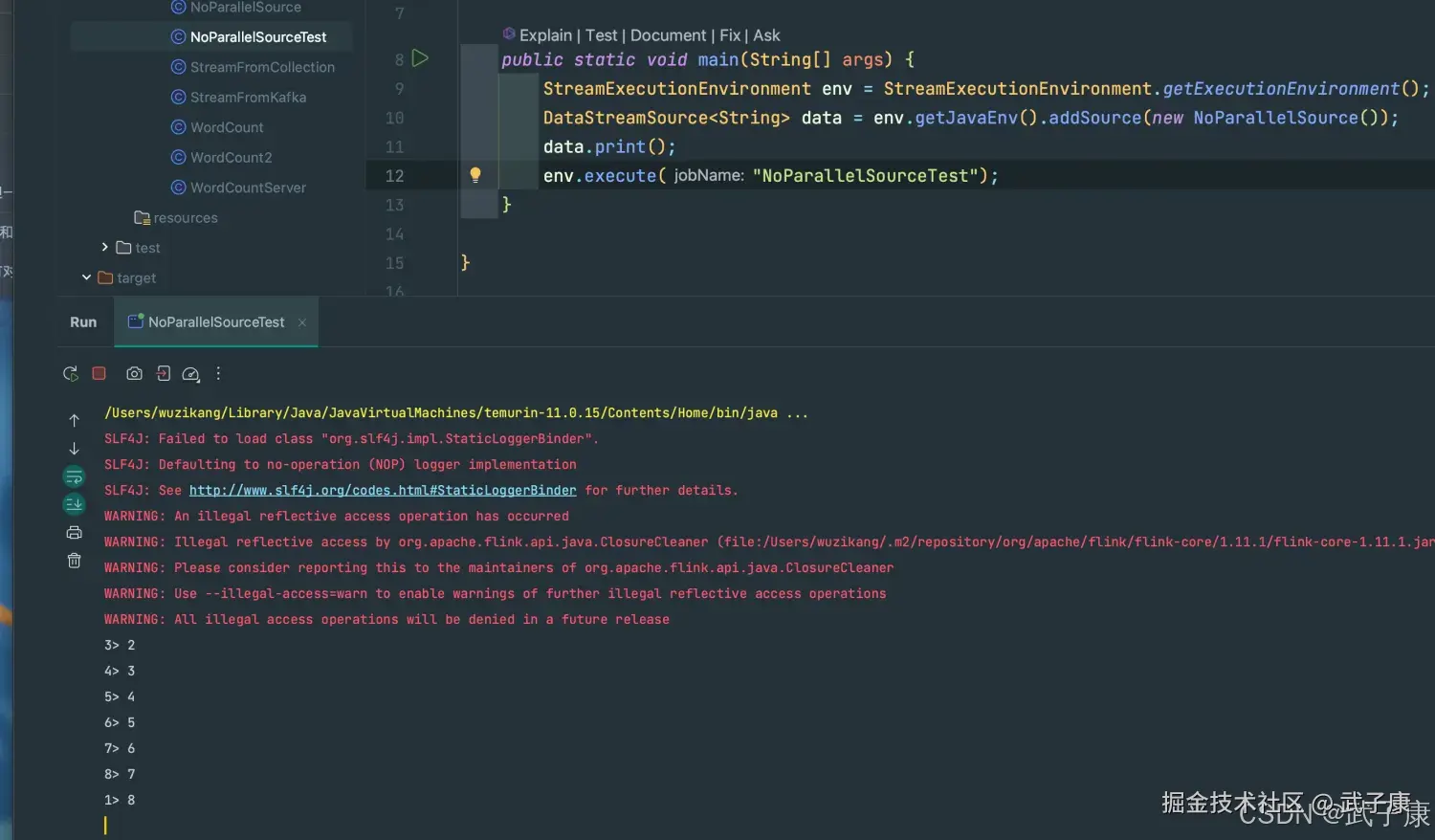
并行源
基本介绍
在 Apache Flink 中,并行源(Parallel Source)是一种可以在多个并行实例中运行的数据源操作。这种源操作允许通过分配多个任务槽(Task Slot)来并行地读取数据,从而提高数据处理的吞吐量和性能。与非并行源相比,并行源更适合处理大规模、可分割的数据源,如分布式文件系统、消息队列、数据库分片等。
主要特点
- 多实例执行:并行源可以通过多个并行实例执行,每个实例处理源数据的一个分片。这种架构允许利用集群中的多个计算资源,从而大大提高数据处理能力。
- 分片处理:并行源通常会将数据源分成多个分片(shard)或分区(partition),每个分片由不同的并行实例处理。这样可以将大量的数据分摊到多个并行实例上,实现更高的处理效率。
- 状态管理:每个并行实例通常会管理自己的状态,而不是像非并行源那样管理全局状态。Flink 提供了状态后端和检查点机制,帮助管理和恢复并行源的状态。
- 横向扩展:由于并行源可以在多个实例中运行,因此随着集群资源的增加(例如增加 Task Manager 和 Slot 的数量),并行源的处理能力也会随之增加。
使用场景
- 分布式文件系统读取:从 HDFS、S3 等分布式文件系统中读取数据时,通常使用并行源将文件分块并分配给不同的并行实例处理。
- 消息队列消费:从 Kafka、RabbitMQ 等消息队列中消费消息时,通常使用并行源来同时处理多个分区的数据。
- 数据库读取:当从分片数据库(例如 MySQL 分片、Cassandra 等)读取数据时,使用并行源可以让多个实例并行读取不同分片的数据。
示例代码
Flink 提供了一些内置的并行源,例如 KafkaSource、Flink's FileSource 等,这里以 KafkaSource 为例:
java
// 使用 Flink 内置的 Kafka Source
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flink-group");
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>(
"topic-name",
new SimpleStringSchema(),
properties
);
// 设置 Kafka Source 的并行度
DataStream<String> stream = env.addSource(kafkaSource).setParallelism(4);注意事项
- 数据分区一致性:在使用并行源时,需要确保数据源可以合理分区,并且每个并行实例只处理其分配的分区数据,避免数据重复处理或遗漏。
- 状态恢复:当并行源需要保存状态时,确保状态的正确管理,以便在故障恢复时可以正确地恢复各个并行实例的状态。
- 负载均衡:确保各个并行实例间的负载均衡,避免某些实例过载,而其他实例闲置。
ParallelSource
java
package icu.wzk;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
public class ParallelSource implements ParallelSourceFunction<String> {
private long count = 1L;
private boolean running = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (running) {
count ++;
ctx.collect(String.valueOf(count));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
}ParallesSourceTest
java
package icu.wzk;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment;
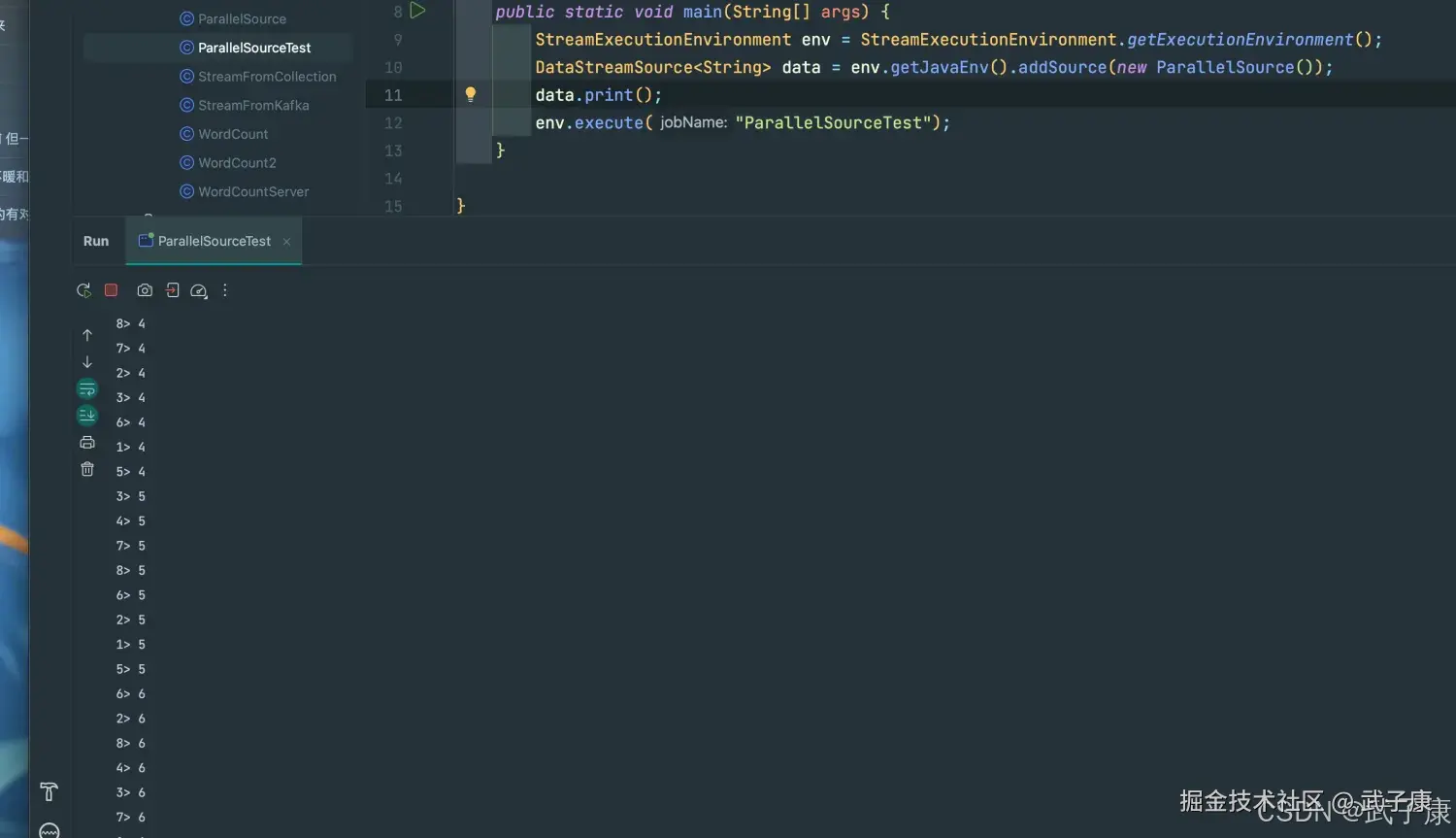
public class ParallelSourceTest {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> data = env.getJavaEnv().addSource(new ParallelSource());
data.print();
env.execute("ParallelSourceTest");
}
}运行结果
可以看到运行的速度是非常快的
shell
4> 2
5> 2
1> 2
2> 2
8> 2
3> 2
6> 2
7> 2
6> 3
5> 3
8> 3
7> 3
4> 3
3> 3
2> 3
1> 3
6> 4运行的对应的截图如下所示: