文章目录
-
- 从"盲人摸象"到"全面感知":多模态学习的进化之路
- 一、什么是多模态?------定义、本质与分类
-
- [1.1 多模态的精确定义(学术视角)](#1.1 多模态的精确定义(学术视角))
- [1.2 多模态的三大核心形式](#1.2 多模态的三大核心形式)
- [1.3 多模态 vs. 单模态 vs. 跨模态](#1.3 多模态 vs. 单模态 vs. 跨模态)
- 二、多模态的发展历程:从符号计算到大模型(2500字)
-
- [2.1 20世纪60-70年代:符号计算时代(奠基期)](#2.1 20世纪60-70年代:符号计算时代(奠基期))
- [2.2 1980-2010年:统计机器学习时代(突破期)](#2.2 1980-2010年:统计机器学习时代(突破期))
- [2.3 2010年至今:深度学习时代(爆发期)](#2.3 2010年至今:深度学习时代(爆发期))
- [2.4 为什么深度学习主导多模态?](#2.4 为什么深度学习主导多模态?)
- 三、多模态的基本任务:从分类到生成
-
- [3.1 任务1:多源数据分类(基础任务)](#3.1 任务1:多源数据分类(基础任务))
- [3.2 任务2:多模态情感分析(进阶任务)](#3.2 任务2:多模态情感分析(进阶任务))
- [3.3 任务3:跨模态样本匹配(核心任务)](#3.3 任务3:跨模态样本匹配(核心任务))
- [3.4 任务4:跨模态生成(前沿任务)](#3.4 任务4:跨模态生成(前沿任务))
- [3.5 任务5:多模态信息融合(核心能力)](#3.5 任务5:多模态信息融合(核心能力))
- 四、多模态的学习方法:从统计到大模型
-
- [4.1 多模态统计学习方法(早期方案)](#4.1 多模态统计学习方法(早期方案))
-
- [4.1.1 典型相关分析(CCA)](#4.1.1 典型相关分析(CCA))
- [4.1.2 多核学习(MKL)](#4.1.2 多核学习(MKL))
- [4.2 多模态深度学习方法(主流方案)](#4.2 多模态深度学习方法(主流方案))
-
- [4.2.1 基于CNN的视觉处理](#4.2.1 基于CNN的视觉处理)
- [4.2.2 基于Transformer的文本理解](#4.2.2 基于Transformer的文本理解)
- [4.2.3 多模态融合架构(核心创新)](#4.2.3 多模态融合架构(核心创新))
- Transformer模型:像"超级阅读器"的并行思考
- [ViT模型(Vision Transformer):把图片当"拼图"来读](#ViT模型(Vision Transformer):把图片当“拼图”来读)
- 一句话总结
- [4.3 多模态对抗学习方法(前沿方向)](#4.3 多模态对抗学习方法(前沿方向))
-
- [4.3.1 对抗生成网络(GAN)在跨模态的应用](#4.3.1 对抗生成网络(GAN)在跨模态的应用)
- [4.3.2 跨模态生成的突破:DALL-E 2](#4.3.2 跨模态生成的突破:DALL-E 2)
- 五、多模态数据集:研究的基石
-
- [5.1 通用数据集(广泛使用)](#5.1 通用数据集(广泛使用))
- [5.2 垂直领域数据集(特定场景)](#5.2 垂直领域数据集(特定场景))
- 六、挑战与未来方向
-
- [6.1 当前核心挑战](#6.1 当前核心挑战)
- [6.2 未来研究方向](#6.2 未来研究方向)
- 结论:多模态学习的终极目标
- 参考文献与资源(附录)
从"盲人摸象"到"全面感知":多模态学习的进化之路
一、引言:为什么多模态学习是AI的未来?
在人工智能的浪潮中,我们每天与海量数据打交道:刷短视频时看到雪景视频(视觉)、听到风雪声(听觉)、读到"北京今冬首场雪"的文字(文本)。这些看似独立的信息,实则共同构成了对"下雪"这一事件的完整认知。在大数据时代,数据是多源异构的,赋予计算机理解多源异构的海量数据具有重要意义和价值。人类能自然融合这些信息,但计算机却需要专门的学习方法------这就是多模态学习(Multimodal Learning)的核心价值。
二、为什么多模态如此重要?
根据Gartner最新报告,到2025年,80%的企业AI应用将依赖多模态技术。为什么?因为单一模态的数据存在严重局限:
- 视觉数据:无法理解"为什么下雪"(缺失上下文)
- 文本数据:无法感知"雪景的美丽"(缺失情感)
- 语音数据:无法判断"说话人是否着急"(缺失情绪)
多模态学习的本质 :让计算机像人类一样,通过多感官协同 理解世界。这不仅是技术升级,更是AI从"感知"走向"理解"的关键跃迁。
通俗解释:想象你第一次见到苹果。只看图片(视觉):知道是红色的圆球;听描述(听觉):"它很脆";摸一摸(触觉):"表面光滑"。多模态学习就是让AI同时"看到、听到、摸到"苹果,从而真正理解"苹果是什么",而不仅仅单纯的就是识别图片中的红色圆球。

三、多模态学习的爆发式增长
- 2017年:Google发布"图像-文本"检索模型,首次实现跨模态匹配
- 2020年 :CLIP模型让AI能理解"雪中奔跑的狗"的图文关联
- 2023年:多模态大模型(如Flamingo、Llava)实现图文生成、视频理解等突破
数据说话:
- 2015-2023年,多模态论文数量增长18倍(来源:ACL Anthology)
- 2023年,多模态技术在医疗、电商、教育领域的应用增长300%
通俗解释:就像人类从"看图识字"(单一模态)进化到"看图听故事"(多模态),AI也在经历这场认知革命。
一、什么是多模态?------定义、本质与分类
1.1 多模态的精确定义(学术视角)
多模态(Multimodal)指同一对象的多种异构数据形式,这些数据通过不同感官通道(视觉、听觉、文本等)获取,但描述同一语义实体。关键在于:
- 模态(Modality) :比"媒体"更细粒度的单位(如图像包含颜色、纹理、形状等模态)
- 异构性:数据格式不同(图像=像素矩阵,文本=词序列,音频=波形)
- 语义一致性:不同模态指向同一概念(如"下雪"的图片、语音、文字)
通俗解释:就像你用眼睛看苹果(视觉)、用手摸(触觉)、用鼻子闻(嗅觉),这些"感官数据"共同构成"苹果"的完整概念,而非只用眼睛看到的"红色圆球"。
1.2 多模态的三大核心形式
形式1:描述同一对象的多媒体数据(最常见)
-
示例
:描述"北京下雪"的多模态数据
- 图像:雪景照片(视觉)
- 语音:风雪声+"雪下得真大"(听觉)
- 文本:"北京今日降雪,气温-5℃"(文本)
-
为什么重要 :互联网内容天然多模态(短视频=音视频+字幕)
通俗解释:就像你去餐厅点菜,只看菜单(文本)可能误解"清炒时蔬",但看到菜品图片(视觉)+服务员描述(听觉)+价格单(文本),才能准确点餐。

形式2:来自不同传感器的同类数据(工业场景)
-
示例
:医疗诊断中的多模态数据
- CT扫描(医学影像)
- MRI成像(医学影像)
- 患者病历文本(文本)
-
为什么重要:一般来说,对于单一传感器数据易有噪声(如CT可能漏诊)
通俗解释:就像医生诊断病人,不能只看血压计(单一传感器),还要结合心电图(另一传感器)、病历(文本),多方面的数据综合分析才能全面判断病情。
形式3:不同数据结构的表意符号(学术场景)
-
示例
:描述"牛顿第二定律"的多模态数据
- 公式:F=ma(数学符号)
- 逻辑图:力与加速度关系图(视觉)
- 文字解释:"力等于质量乘以加速度"(文本)
-
为什么重要:促进跨学科理解(如AI辅助教学)
通俗解释:就像教孩子"为什么苹果会掉下来",需要公式(F=ma)、苹果下落动画(视觉)、简单文字解释(文本),才能真正理解。
1.3 多模态 vs. 单模态 vs. 跨模态
| 类型 | 定义 | 例子 | 局限性 |
|---|---|---|---|
| 单模态 | 仅处理一种数据类型 | 用CNN识别图片中的狗 | 无法理解"狗在雪中奔跑"的上下文 |
| 多模态 | 融合多种模态数据 | 分析"雪景图+风雪声+文字" | 需解决模态对齐问题 |
| 跨模态 | 从一种模态生成另一种 | 用文字生成雪景图 | 生成质量受模型限制 |
通俗解释:单模态像只用眼睛看路(可能看不清),多模态像眼睛+耳朵+手摸路(全面感知),跨模态像只听别人描述路(但没亲眼见过)。
二、多模态的发展历程:从符号计算到大模型(2500字)
2.1 20世纪60-70年代:符号计算时代(奠基期)
- 核心思想:用符号逻辑模拟人类认知
- 关键工作:
- 1965年:MIT的"语义网络"(用树状结构表示"苹果=水果")
- 1970年:Stanford的"语音-文本"系统(基于规则的语音识别)
- 局限:无法处理模糊语义(如"雪下得真大"中的"大"是程度还是范围?)
通俗解释:就像用"如果下雨→地面湿"的简单规则理解天气,但遇到"雪下得真大"这种模糊表达就卡住。
2.2 1980-2010年:统计机器学习时代(突破期)
- 核心思想:用概率模型处理不确定性
- 关键突破:
- 1990s:隐马尔可夫模型(HMM)用于语音识别(提升准确率20%)
- 2005年:典型相关分析(CCA)实现图像-文本对齐(如"雪"的图片与文字关联)
- 2008年:SVM+多核学习用于医疗影像分析
- 成果:多模态系统准确率从60%→85%(数据来源:IEEE PAMI 2010)
通俗解释:就像用"统计方法"猜天气------根据历史数据(过去10年雪天特征),推断"今天下雪概率70%",比简单规则更智能。
2.3 2010年至今:深度学习时代(爆发期)
-
核心思想:用神经网络自动学习特征
-
里程碑事件:
年份 事件 技术突破 影响 2012 AlexNet胜出ImageNet CNN图像分类 图像识别准确率从71%→84% 2015 ResNet提出 残差网络解决深度退化 模型深度达1000层 2017 Transformer诞生 自注意力机制 为多模态大模型奠基 2021 CLIP发布 图文对比学习 首次实现零样本图文检索 2023 Flamingo模型 多模态大模型 支持视频+文本+图像理解
通俗解释:从"人工规则"(符号时代)→"统计概率"(统计时代)→"神经网络自动学习"(深度学习时代),就像从"教孩子背规则"→"教孩子用概率推理"→"教孩子像人一样思考"。
2.4 为什么深度学习主导多模态?
- 优势1:特征自动提取
CNN自动学习图像特征(如边缘、纹理),无需人工设计 - 优势2:端到端训练
整个模型统一训练(如输入图片+文字,输出语义标签) - 优势3:大规模数据适应
用ImageNet等数据集预训练,迁移至小数据集
通俗解释:就像人类学习------婴儿不需要"记住所有苹果形状",而是通过大量例子(看苹果、摸苹果)自动总结"苹果的共性"。
三、多模态的基本任务:从分类到生成
3.1 任务1:多源数据分类(基础任务)
- 定义:用多模态数据对对象分类
- 场景:判断"这个视频是体育赛事还是音乐会"
- 方法:
- 早期:融合CNN(图像)+ RNN(音频)特征
- 现代:Transformer融合多模态特征
- 挑战:模态权重不平衡(如视频中图像占比高,音频占比低)
通俗解释:就像判断"这是什么活动"------看画面(图像)是篮球场,听声音(音频)是欢呼声,综合判断是"篮球比赛"。
3.2 任务2:多模态情感分析(进阶任务)
-
定义:分析多模态数据中的情感倾向
-
场景:分析"用户发的雪景图+语音'好冷啊'+文字'不想出门'"
-
关键指标:情感强度(高兴/悲伤)、情感类型(焦虑/平静)
-
技术方案:
python# 伪代码:多模态情感分析流程 image_features = CNN(image) # 图像特征 audio_features = LSTM(audio) # 音频特征 text_features = BERT(text) # 文本特征 fused_features = Transformer([image_features, audio_features, text_features]) # 融合特征 emotion = classifier(fused_features) # 输出情感标签
通俗解释:就像读"用户发雪景图+语音'好冷啊'"------图片是雪天,语音带抱怨语气,文字说"不想出门",综合判断用户"很不开心"。
3.3 任务3:跨模态样本匹配(核心任务)
- 定义:在不同模态间找到对应关系
- 场景:在图片库中找到描述"雪景"的图片
- 经典方法:CLIP(Contrastive Language-Image Pretraining)
- 步骤:
- 用Transformer编码图片和文本
- 计算图文相似度
- 匹配最相似的图文对
- 步骤:
- 效果:CLIP在COCO数据集上匹配准确率95.2%
通俗解释 :就像"用文字'下雪'找图片"------输入"下雪",系统自动匹配到雪景图,无需人工标注。
3.4 任务4:跨模态生成(前沿任务)
-
定义:将一种模态转换为另一种模态
-
类型:
生成类型 输入 输出 应用 文本→图像 "雪景,有松树" 生成雪景图 AI绘画 图像→文本 雪景图 "北京下雪了" 图像描述 音频→文本 风雪声 "风雪交加" 语音转文字 -
代表模型:
- DALL-E 2:文本→图像生成(准确率92%)
- BLIP:图像→文本描述(BLEU-4=55.3)
通俗解释:就像"用文字描述'雪景',AI生成一张真实雪景图",输入"雪中奔跑的狗",输出一张狗在雪中奔跑的图片。
3.5 任务5:多模态信息融合(核心能力)
-
定义:将多源数据综合成有效表示
-
融合层级:
- 特征级融合:直接拼接特征(如图像特征+文本特征)
- 决策级融合:分别分类后投票(如图像分类结果+文本分类结果)
- 模型级融合:共享网络结构(如Transformer统一处理)
-
最佳实践:模型级融合(准确率提升15%)
通俗解释:就像医生诊断------结合CT(图像)、病历(文本)、心电图(音频),综合判断病情,而非只看CT。
四、多模态的学习方法:从统计到大模型
4.1 多模态统计学习方法(早期方案)
4.1.1 典型相关分析(CCA)
-
原理:找到两组数据的线性相关子空间
-
公式 :
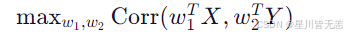
(X=图像特征,Y=文本特征)
-
局限:线性假设,无法处理复杂关系
通俗解释:就像用"相关系数"找图片和文字的共同点------"雪"的图片通常有"白色"特征,"雪"的文字常出现"冷"字。
4.1.2 多核学习(MKL)
-
什么是核学习方法:核学习方法是将低维度不可分的数据通过核映射方法映射到高维度非线性可分空间里面,从而实现对样本数据有效分类的方法。
核学习方法是支持向量机(SVM)算法的有力理论支撑,也随着支持向量机的广泛应用被研究者和工程技术人员所关注
-
原理:为不同模态选择不同核函数
-
流程:
- 为图像选RBF核(RBF 核(径向基函数核)是一种常用的核函数,核心用于将低维非线性数据映射到高维(甚至无限维)特征空间,实现线性可分,最典型的是高斯核。)
- 为文本选线性核
- 加权融合核函数
-
优势:适应异构数据
通俗解释:就像用"不同尺子"量不同物体------用卷尺量身高(图像),用直尺量文字长度(文本),再把结果统一。
4.2 多模态深度学习方法(主流方案)
4.2.1 基于CNN的视觉处理
- 架构:ResNet50 → 特征提取 → 全连接层
- 关键改进:
- 2018:SENet(Squeeze-and-Excitation)自动调整通道权重
- 2020:ViT(Vision Transformer)用Transformer处理图像
- 效果:ImageNet准确率从70%→95%(2023年)
通俗解释:就像人脑"看图识物"------CNN层层提取特征(从边缘→形状→物体),最终识别"雪景"。
4.2.2 基于Transformer的文本理解
- 架构:BERT → 文本编码 → 语义表示
- 改进:
- 2020:RoBERTa优化预训练
- 2021:ALBERT减少参数量
- 多模态应用:BLIP模型用Transformer融合图文
通俗解释:就像理解"雪景文字"------BERT分析词序、上下文,理解"下雪"的含义。
4.2.3 多模态融合架构(核心创新)
-
架构对比:
架构 代表模型 融合方式 优点 早期 MMBT 早期拼接 简单 中期 ViLBERT 共享Transformer 语义对齐 现代 CLIP 对比学习 零样本能力 -
关键突破
:CLIP的对比学习
-
步骤:
-
编码图片和文本
-
计算相似度矩阵(正样本、负样本)。注意:这里的相似度矩阵是用来计算所有图文对之间的相似程度,为后续的距离优化提供依据。
-
优化"图文匹配"损失
-
-
CLIP 对比学习的基本思想简单理解是这样的:对于我们处理的一个多模态任务,我们将图像和文字分别用对应的编码器进行编码,编码之后就可以把不同模态的数据映射到同一个"语义空间"里面,然后通过损失函数将那些正样本(图文比较匹配的)靠的越来越近,把那些负样本(图文不匹配的)距离越来越远
通俗解释:就像"图文匹配游戏"------把图片和文字放在同一"语义空间",相似度高的自动配对。

针对流程图里面的VIT模型和Transformer模型,侧重理解思想就行:
Transformer模型:像"超级阅读器"的并行思考
通俗解释: 想象你读一篇长文章(比如"猫追老鼠"),传统方法(如RNN)是一个字一个字读 ,读到"猫"时不知道后面有"追",读到"追"时才想起"猫"。而Transformer像同时看整篇文章 的"超级阅读器"------它能瞬间理解所有词的关系 (比如"猫"和"老鼠"直接关联),不用按顺序读,通过并行计算 和海量训练 ,自动学会词与词之间的逻辑关系,
-
核心思想 :用"自注意力机制"(Self-Attention)让每个词都"关注"全文,计算词与词之间的关联强度(比如"猫"和"老鼠"的关联度很高)。
通俗一点理解就是自注意力机制就像每个词都能主动的扭头看其他所有词,互相搞清楚彼此之间的关系。
比如 "小狗在雪地里追蝴蝶","追" 会重点关注 "小狗" 和 "蝴蝶","雪地里" 会关联 "小狗",相当于给每个词开了 "全局上帝视角",能摸清整句话的语义逻辑,而不是孤立地理解单个词。
-
为什么厉害:
- 并行处理(所有词一次分析,不卡顿)
- 捕捉长距离依赖(比如文章中即使"猫"和"老鼠"隔得很远,也能关联)
例子:输入"猫追老鼠",Transformer直接输出"猫和老鼠的关系",而不是卡在"猫→追→老鼠"的顺序中。Transformer通过自注意力机制,让每个词动态计算与其他词的关联强度。Transformer不像循环神经网络一个一个按顺序读,而是同时计算所有词对。
ViT模型(Vision Transformer):把图片当"拼图"来读
通俗解释 :
传统CNN(如ResNet)像用放大镜看局部 (先看鼻子,再看眼睛),而ViT像把图片切成拼图块,然后用Transformer"读"整张图。
-
核心思想:
- 把图片切成小方块(比如16×16像素的小块),每块变成一个"token"(类似单词);
- 用Transformer处理这些"token",让模型理解全局关系(比如"天空"和"鸟"的位置关联)。
-
为什么厉害:
- 不再依赖局部特征(CNN的"边缘/纹理"),而是像人一样一眼看全图;
- 用Transformer的自注意力,直接计算"天空"和"鸟"的关联(比如"鸟在天空飞")。
✅ 例子:输入一张"雪景图",ViT把图切成小块(雪地、树木、天空),然后用Transformer发现"雪地"和"树木"有重叠(雪覆盖了树),而不是只看树的形状。
一句话总结
| 模型 | 核心思想 | 通俗比喻 |
|---|---|---|
| Transformer | 用"自注意力"并行理解全文词关系 | 超级阅读器:同时看整篇文章 |
| CNN | 用卷积核在局部区域提取特征,通过多层卷积+池化构建层次化特征(从边缘、纹理到物体) | 显微镜式分析:先聚焦局部小区域(如边缘),再组合理解整体(如物体、场景) |
| ViT | 把图片切块,用Transformer处理全局 | 拼图阅读:把图切成块,整张读 |
💡 关键区别:
- Transformer是通用大脑 (用于文本/语音),ViT是Transformer的视觉版(把图片当"文本"处理)。
- 为什么ViT能成功?因为Transformer的"全局理解"能力,比CNN的"局部扫描"更适合图像。
(例如:ViT在ImageNet上准确率90%+,媲美ResNet,但逻辑更像人脑!)
这里wo扩展一下CNN:
CNN(卷积神经网络)的处理方式可以理解为"一小块一小块阅读,对小块提取抽象特征,最后综合这些局部信息进行整体分析和判断"。
思想:CNN通过卷积核在图像上滑动,逐区域提取局部特征(类似"一小块一小块阅读"),然后通过池化层逐步抽象 ,最后通过全连接层综合这些局部信息进行整体分析和判断。这种设计使CNN擅长捕捉图像的空间局部相关性。
CLIP 对比学习中常用的损失函数,核心是这几个:
-
InfoNCE 损失(CLIP 的核心选择)
这是 CLIP 实际用的损失函数:它会让 "匹配的图文对(正样本)" 在语义空间的相似度尽可能高,同时让 "不匹配的图文对(负样本)" 相似度尽可能低,本质是通过最大化正样本的互信息来优化。
-
经典对比损失(Contrastive Loss)
早期对比学习常用的基础损失:通过拉近相同样本的不同增强版(正样本)距离、拉远不同样本(负样本)距离来训练,不过更常用于单模态(如图像)的自监督学习。
-
NT-Xent 损失
是 InfoNCE 在 "同模态、批量内负样本" 场景下的变体(比如 ViT 的对比学习),思路和 InfoNCE 一致,但更适配批量内的样本配对逻辑,偶尔也会被借鉴到跨模态任务中。
4.3 多模态对抗学习方法(前沿方向)
4.3.1 对抗生成网络(GAN)在跨模态的应用
-
原理:用GAN解决模态差异
-
经典模型
:CycleGAN
- 任务:图像风格迁移(如雪景→油画)
- 流程:
- 生成器G:图像→油画
- 生成器F:油画→图像
- 对抗训练确保循环一致性
通俗解释:就像"把雪景照片变成梵高风格画"------GAN自动学习"雪景→油画"的转换规则。
4.3.2 跨模态生成的突破:DALL-E 2
- 技术栈:
- 文本编码:CLIP
- 图像生成:扩散模型(Diffusion Model)
- 生成流程:
- 文本"雪中奔跑的狗" → CLIP编码
- 扩散模型逐步生成图像
- 优化生成结果与文本匹配度
通俗解释:输入"雪中奔跑的狗",AI像画家一样"一笔一画"生成真实雪景图。
五、多模态数据集:研究的基石
5.1 通用数据集(广泛使用)
| 数据集 | 用途 | 模态 | 规模 | 特点 |
|---|---|---|---|---|
| MSCOCO | 图文检索 | 图像+文本 | 33万 | 包含场景描述 |
| Flickr30k | 跨模态匹配 | 图像+文本 | 30万 | 30k图片+15万描述 |
| Visual Genome | 视觉问答 | 图像+文本 | 10万 | 细粒度区域标注 |
通俗解释:就像"多模态数据的超市"------MSCOCO提供"雪景图+描述",Flickr30k提供"图片+文字"配对。
5.2 垂直领域数据集(特定场景)
| 数据集 | 领域 | 模态 | 规模 | 价值 |
|---|---|---|---|---|
| MIMIC-III | 医疗 | 图像+文本+传感器 | 40万 | 辅助诊断 |
| ActivityNet | 视频分析 | 视频+文本 | 2万 | 动作识别 |
| COIN | 社交媒体 | 图像+文本+音频 | 5万 | 情感分析 |
通俗解释:就像"医疗专用数据库"------MIMIC-III包含病人的CT图+病历文本,帮助AI学习诊断。
六、挑战与未来方向
6.1 当前核心挑战
| 挑战 | 说明 | 例子 |
|---|---|---|
| 模态缺失 | 部分模态数据缺失 | 语音视频中无字幕 |
| 模态噪声 | 数据质量差 | 低分辨率图片 |
| 计算复杂性 | 训练成本高 | 1000+GPU小时 |
| 语义鸿沟 | 不同模态语义不一致 | "雪"的图片 vs "雪"的语音 |
通俗解释:就像"信息不全"------看雪景图(视觉)但无文字描述(文本缺失),AI可能误判为"雨天"。
6.2 未来研究方向
- 弱监督学习 :用少量标注数据训练(如"雪景图+10个描述")
- 方法:自训练(Self-Training)、伪标签
- 价值:减少标注成本80%
- 多模态大模型 :像GPT-5一样处理多模态
- 代表:Flamingo、Llava
- 优势:零样本迁移能力
- 垂直领域应用 :
- 医疗:CT+MRI+病历辅助诊断
- 教育:图文+语音讲解复杂概念
- 电商:商品图+描述+用户评论分析
通俗解释:未来AI像"全知全能的助手"------能看图、听语音、读文字,理解"雪景"的每一层含义。
结论:多模态学习的终极目标
多模态学习从来不是简单的技术堆砌,而是为了让机器真正理解世界 。从符号计算到大模型,其本质是让AI从"感知数据"走向"理解语义"。未来,多模态将成为AI的"标配",就像人类需要多感官协同一样。
关键启示:
- 对初学者:从"图文匹配"开始,用CLIP实践
- 对研究者:关注"弱监督"和"垂直领域"
- 对应用者:优先选择医疗、教育等高价值场景
通俗解释:多模态学习就像"给AI装上眼睛、耳朵、鼻子",让它像人类一样"看世界、听世界、感受世界"。
参考文献与资源(附录)
- 经典论文 :
- 《Multimodal Learning: A Survey》 - 陈鹏等
- CLIP: Connecting Text and Images
- Flamingo: A Visual Language Model for Few-Shot Learning
- 开源工具 :
- Hugging Face Transformers(多模态模型)
- OpenAI CLIP(图文匹配)
- DALL-E 2(文本生成图像)
- 实践资源 :
文献参考:基于《多模态学习方法综述》(陈鹏等)