ForkJoin
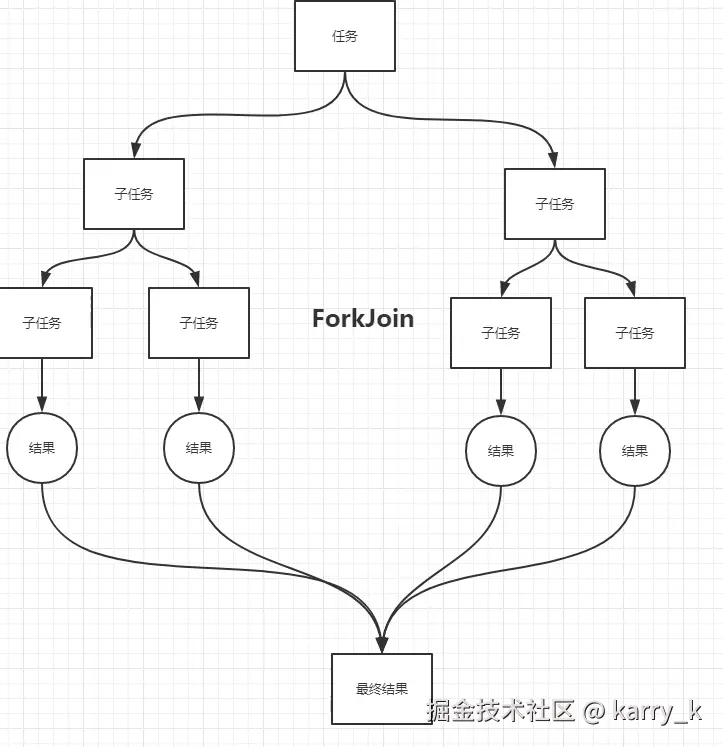
Fork/Join 是什么?
- 它是Java7 引入的一个 并行计算框架, 位于
java.util.concurrent包下 。 - 主要解决的问题是:把大任务拆分成多个小任务并行执行,然后合并结果。
- 核心思想:分治法+工作窃取
核心类
ForkJoinPool
-
- 一个特殊的线程池,支持"工作窃取"算法。
- 每个线程都有自己的任务队列,如果某个线程空闲,会去偷别人的任务执行。
RecursiveTask<V>
-
- 代表有返回值的任务。
- 必须重写
protected abstract V compute()方法。
RecursiveAction
-
- 代表没有返回值的任务。
- 也要重写
compute()方法。
使用步骤
假设我们要求 1 + 2 + ... + 1000 的和,可以用 Fork/Join 来并行计算:
java
import java.util.concurrent.*;
public class ForkJoinTest {
public static void main(String[] args) throws Exception {
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Long> task = new MyTask(1, 1000);
Long result = pool.invoke(task);
System.out.println("结果: " + result);
}
}
class MyTask extends RecursiveTask<Long> {
private long start;
private long end;
private static final long THRESHOLD = 100; // 阈值,任务足够小就不拆分
public MyTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
// 如果任务足够小,直接计算
if ((end - start) <= THRESHOLD) {
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
// 任务太大,拆分为两个小任务
long mid = (start + end) / 2;
MyTask left = new MyTask(start, mid);
MyTask right = new MyTask(mid + 1, end);
// fork 子任务(异步执行)
left.fork();
right.fork();
// join 合并结果(等待子任务完成并返回)
return left.join() + right.join();
}
}
}运行流程
MyTask(1,1000)太大 → 拆分成MyTask(1,500)和MyTask(501,1000)- 再继续拆,直到区间长度 ≤ 100 时,直接计算
- 最后通过
join()把结果逐级汇总
Fork/Join 特点
1. 分治思想:
递归拆分任务 → 小任务直接执行 → 结果汇总。
2. 工作窃取:
如果某个线程执行完了,会去偷其他线程队列里的任务,提升 CPU 利用率。
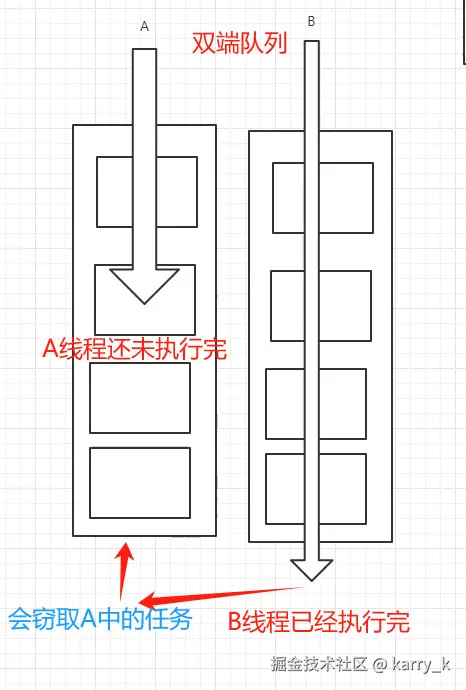
a. 基本原理
- 每个工作线程 (
ForkJoinWorkerThread)都有一个 双端队列(Deque) 来存放任务。 - 当线程自己提交任务时,会把任务放在 双端队列的队头。
- 线程会优先从自己队列的 队尾 获取任务执行(LIFO,减少缓存未命中,提高局部性)。
- 如果线程自己的任务执行完了(队列空了),它就会 "窃取"其他线程队列头部的任务 来执行。
b. 为什么要用双端队列?
- 本地线程取任务:从队尾取(后进先出,减少任务拆分深度)。
- 其他线程窃取任务:从队头取(先进先出,避免和本地线程竞争)。
3. 适合 CPU 密集型任务
比如大数据计算、数组求和、递归处理。
Fork/Join 框架 = 多线程版的递归分治 ,背后依赖 ForkJoinPool 和 工作窃取算法 来保证高效执行。