文章目录
- [1. 导论](#1. 导论)
-
- [1.1 课程介绍](#1.1 课程介绍)
- [1.1.1 学习算法](#1.1.1 学习算法)
- [1.2 什么是机器学习?](#1.2 什么是机器学习?)
-
- [1.3 为什么我们需要机器学习?](#1.3 为什么我们需要机器学习?)
- [1.4 和统计学的关系](#1.4 和统计学的关系)
- [1.5 和AI的关系](#1.5 和AI的关系)
- [1.6 机器学习和人类学习的关系](#1.6 机器学习和人类学习的关系)
- [1.7 机器学习的种类](#1.7 机器学习的种类)
- [1.8 机器学习的历史和应用](#1.8 机器学习的历史和应用)
- [1.9 机器学习的流程](#1.9 机器学习的流程)
- [2. Nearest Neighbor Methods(最近邻方法)](#2. Nearest Neighbor Methods(最近邻方法))
-
- [2.1 机器学习的预备知识](#2.1 机器学习的预备知识)
- [2.2 最近邻(Nearest Neighbors)算法](#2.2 最近邻(Nearest Neighbors)算法)
- [2.3 可视化](#2.3 可视化)
-
- [2.3.1 Voronoi图(Voronoi diagram)](#2.3.1 Voronoi图(Voronoi diagram))
- [2.3.2 决策边界(Decision boundary)](#2.3.2 决策边界(Decision boundary))
- [2.4 k-NN(k-最近邻算法)](#2.4 k-NN(k-最近邻算法))
- [2.4.1 k-NN 算法的泛化能力](#2.4.1 k-NN 算法的泛化能力)
-
- [2.4.2 超参数](#2.4.2 超参数)
- [2.4.3 应用](#2.4.3 应用)
- [2.4.4 总结](#2.4.4 总结)
1. 导论
1.1 课程介绍
本学期我要上的课程有INT301,INT303,INT305,这三门课的知识其实都与AI相关。因此整体课程难度不大,而且在大二的时候INT104就已经向我们介绍了关于AI的一些基础知识。
这门功课为机器学习,集中于机器学习的理论知识(包含机器学习问题和优化问题(Optimization Problem))、机器学习算法(包含学习算法和优化算法)、实际的机器学习(从人工和现实世界数据中学习)
1.1.1 学习算法
学习算法包含Supervised Learning(监督学习)、Unsupervised Learning(无监督学习)、Reinforcement Learning(强化学习)。
就像我们以前所学习的那样,监督学习和无监督学习之间的差异在于有无Label,监督学习使用标记的数据来训练模型。训练数据包含输入特征和对应的输出标签,模型的目标是学习输入和输出之间的映射关系。
它包含的算法有:
- Nearest Neighbors(最近邻算法)
比如K-Nearest Neighbors (KNN):通过查找训练数据中与当前样本最近的K个点来预测新样本的标签。对于分类问题,通常是多数投票;对于回归问题,通常是取平均值。 - Decision Trees(决策树)
分类树和回归树:通过一系列的决策规则(通常是基于特征的阈值)来预测目标变量。决策树易于理解和解释,但容易过拟合。 - SVMs(支持向量机)
通过找到一个最优的超平面来最大化不同类别之间的间隔。支持向量机可以处理线性和非线性分类问题,通过核技巧将数据映射到高维空间。 - Linear Regression(线性回归)
用于预测连续值目标变量。假设输入特征和目标变量之间存在线性关系,通过最小化预测值和真实值之间的平方误差来训练模型。 - Logistic Regression(逻辑回归)
用于分类问题,特别是二分类问题。通过Sigmoid函数将线性回归的输出映射到(0,1)区间,从而预测样本属于某个类别的概率。 - Ensembles(集成学习)
Bagging(装袋法):如随机森林,通过构建多个决策树并结合它们的预测来提高模型的稳定性和准确性。
Boosting(提升法):如AdaBoost、Gradient Boosting,通过逐步训练弱学习器并赋予不同的权重来提高模型的性能。
Stacking(堆叠法):将多个不同类型的模型的预测结果作为新特征,再训练一个模型来组合这些预测。 - Neural Networks(神经网络)
由多层神经元组成,通过激活函数和权重来学习复杂的非线性关系。包括前馈神经网络、卷积神经网络(CNN)、循环神经网络(RNN)等。
无监督学习使用未标记的数据来训练模型,目标是发现数据中的结构和模式,或者说是发现数据的特征。因此如果我们没有数据的特征我们就使用无监督学习,有其特征想去继续推测,我们便使用监督学习。
它包含的算法有:
- K-means(K均值聚类)
一种简单的聚类算法,通过将数据点分配到K个簇中来最小化簇内距离的平方和。适用于发现数据中的自然分组。 - Mixture models(混合模型)
一种概率模型,假设数据是由多个分布的混合生成的。最常见的是高斯混合模型(GMM),通过EM算法来估计每个分布的参数和混合权重。
强化学习是一种让智能体通过与环境的交互来学习最优行为策略的机器学习类型。用通俗的话来说,通过奖赏机制(Reward Mechanism)来训练智能体(Agent),使其能够自主学习如何在环境中做出最优决策。当训练的对象做的对就加分,否则就减分,通过这样的方式让其自主学习。
1.2 什么是机器学习?
我们先看一个学习的定义:通过学习、练习、被教导或体验某事来获得知识或技能的活动或过程。
机器学习的定义:如果一个计算机程序在T中的任务表现(由P衡量)随着经验E的提高而提高,那么它就可以从经验E中学习某些类别的任务T和绩效指标P。
通过这两个定义,我们可以看出机器学习相较于传统的学习来说,形式更具体,它们会有一个具体的衡量指标。
通过这个例子,我们可以假设有一个图像分类任务(T),任务是识别照片中的动物(如猫或狗)。经验(E)是一组标记了猫和狗的图像数据。性能度量(P)是分类准确率。
如果随着训练数据的增加,模型的分类准确率提高,那么我们可以说这个模型从经验中学习了。这便是机器学习。
1.3 为什么我们需要机器学习?
对于许多复杂的问题,直接编写程序来实现正确的行为是非常困难的。这些问题通常涉及大量的数据和复杂的模式,很难用传统的编程方法来解决。具体例子包括:Recognizing people and objects(识别人员和物体)、Understanding human speech(理解人类语音)。
机器学习的核心思想是让计算机通过数据或经验自动学习,而不是手动编写复杂的规则。
通过数据学习就是监督学习:提供大量的标记数据(如带标签的图像或语音样本),让算法从中学习模式和规律。
通过经验学习就是强化学习:让算法通过试错(Trial and Error)来学习最优的行为策略,例如在强化学习中,智能体通过与环境的交互来学习。
我们可以使用机器学习于以下集中任务:
- 难以手工编写解决方案:对于一些复杂的问题,如图像识别和语音识别,很难通过手工编写代码来实现。这些问题涉及大量的数据和复杂的模式,传统的编程方法很难处理。
- 系统需要适应变化的环境:在某些应用中,如垃圾邮件检测,数据和环境是动态变化的,系统需要能够自动适应这些变化。机器学习算法可以通过不断学习新的数据来调整和优化。
- 希望系统表现优于人类程序员:在某些任务中,机器学习算法可以通过大量的数据学习到更优的模式和规律,从而表现优于人类程序员。如图像识别和棋类游戏(AlphaGo)
- 隐私问题。在某些应用中,机器学习算法可以帮助保护用户隐私和确保公平性。例如,在搜索结果排名中,算法可以避免人为偏见,确保结果的公平性和客观性。
1.4 和统计学的关系
机器学习和统计学在某些方面非常相似,它们都试图从数据中发现模式和规律。它们都依赖于高等数学,但两者还是在目标和方法上存在显著差异。
目标上:
统计学:更关注帮助科学家和政策制定者从数据中得出可靠的结论。它强调数据的解释和推断,以支持科学发现和政策决策。
机器学习:更关注构建能够自主运行的智能系统。它强调系统的自动化和自主性,使计算机能够独立做出决策。
方法上:
统计学:
可解释性(Interpretability):统计学强调模型的可解释性,即能够清楚地解释模型的决策过程和结果。
数学严谨性(Mathematical Rigor):统计学更注重数学上的严格性和理论基础,确保模型的可靠性和有效性。
机器学习:
预测性能(Predictive Performance):机器学习更关注模型的预测能力,即模型在新数据上的表现。
可扩展性(Scalability):机器学习强调处理大规模数据的能力,确保模型能够高效地处理大量数据。
自主性(Autonomy):机器学习强调系统的自主性,即系统能够自动学习和适应新情况,而不需要人工干预。
1.5 和AI的关系
人工智能并不总是基于学习的系统。除了机器学习之外,人工智能还包括许多其他类型的系统,这些系统并不依赖于数据驱动的学习。具体例子包括:
- Symbolic reasoning(符号推理):
符号推理是基于逻辑和符号表示的推理方法。它通过规则和逻辑推理来解决问题,而不是通过数据学习。例如,专家系统(Expert Systems)就是一种符号推理系统,它通过一系列预定义的规则来模拟专家的决策过程。 - Rule-based system(基于规则的系统):
基于规则的系统使用一组预定义的规则来处理输入数据并生成输出。这些规则通常由人类专家编写,系统通过匹配规则来做出决策。例如,医疗诊断系统可以通过一系列规则来判断患者可能患有的疾病。 - Tree search(树搜索):
树搜索是一种用于解决路径搜索问题的方法,例如在棋类游戏中寻找最优走法。它通过构建和搜索决策树来找到从初始状态到目标状态的路径。例如,Minimax算法是一种经典的树搜索算法,用于解决两人对弈问题。 - 其他:
人工智能还包括其他许多方法和技术,如遗传算法、模拟退火等,这些方法并不依赖于数据驱动的学习。
而机器学习是基于学习的系统,基于学习的系统是通过数据学习来解决问题的系统。这些系统通常具有以下特点:
Learned based on the data(基于数据学习):
基于学习的系统通过大量的数据来训练模型,从而学习数据中的模式和规律。例如,深度学习算法通过大量的图像数据来训练神经网络,从而能够识别新的图像。
Flexibility(灵活性):
基于学习的系统通常具有很高的灵活性,能够适应不同的任务和数据。例如,同一个深度学习模型可以用于图像识别、语音识别和自然语言处理等多种任务。
Good at solving pattern recognition problems(擅长解决模式识别问题):
基于学习的系统特别擅长解决模式识别问题,如图像识别、语音识别和自然语言处理等。这些任务通常涉及大量的数据和复杂的模式,传统的编程方法很难解决,而基于学习的系统可以通过数据自动学习这些模式。
1.6 机器学习和人类学习的关系
机器学习的目标是为特定的任务提供解决方案,而不是完全模拟人类学习的过程。机器学习系统可以采用与人类学习完全不同的方法来实现目标。
机器学习系统可以通过大量的数据和计算资源来快速学习,而人类学习则需要更少的数据和更长的时间。
机器学习系统可以针对特定任务进行优化,而人类学习则需要处理多种任务和复杂的情境。
机器学习系统在某些任务上可能表现得比人类更好,而在其他任务上可能表现得更差。具体表现取决于任务的性质和系统的优化程度。
机器学习也可以借鉴生物系统中的概念和机制。例如:
神经网络:人工神经网络(Artificial Neural Networks, ANN)是受生物神经网络启发的一种机器学习模型。它通过模拟生物神经元的结构和功能来处理数据。
强化学习:强化学习中的某些机制(如奖励机制)也受到生物学习过程的启发。
总结如下:
人类学习:
数据效率高,只需要少量数据就能学习。
是一个复杂的多任务系统,能够同时处理多种任务。
是一个长期的过程,需要几年甚至十几年的时间。
机器学习:
为特定任务提供解决方案,不一定需要完全模拟人类学习。
可以借鉴生物系统中的概念和机制,如神经网络。
在某些任务上可能表现得比人类更好,而在其他任务上可能表现得更差。
1.7 机器学习的种类
正如前面所说,一共有三种:
- Supervised Learning(监督学习):训练数据包含输入特征和对应的正确输出标签。算法通过学习输入特征和输出标签之间的映射关系来构建模型
- Reinforcement Learning(强化学习):学习系统(称为智能体或代理)通过与环境的交互来学习最优的行为策略。智能体根据环境的反馈(奖励或惩罚)来调整自己的行为,以最大化长期累积奖励。
- Unsupervised Learning(无监督学习):训练数据是未标记的,算法的目标是发现数据中的"有趣"模式或结构。
1.8 机器学习的历史和应用
- 1957年,弗兰克·罗森布拉特(Frank Rosenblatt)发明了感知机(Perceptron)算法。感知机是一种早期的人工神经网络,用于二分类任务。它最初是通过电路实现的,而不是通过软件。
- 1959年,亚瑟·塞缪尔(Arthur Samuel)编写了一个基于学习的跳棋程序,这个程序能够通过自我对弈不断学习,最终击败了塞缪尔本人。
- 1969年,马文·明斯基(Marvin Minsky)和西摩尔·帕珀特(Seymour Papert)出版了《感知机》一书。书中详细讨论了感知机的局限性,特别是线性模型的局限性。
- 1980年代,机器学习领域出现了一些重要的基础思想和方法。
连接主义心理学家开始探索基于神经网络的认知模型,这些模型试图模拟大脑的神经元网络。
1984年,莱斯利·瓦利安特(Leslie Valiant)提出了概率近似正确(PAC)学习理论,这是一种形式化的学习理论,用于描述学习算法的性能。
1988年,杰弗里·辛顿(Geoffrey Hinton)及其同事重新发现了反向传播(Backpropagation)算法。反向传播是一种用于训练多层神经网络的算法,通过计算损失函数的梯度来更新网络的权重。
1988年,朱迪亚·珀尔(Judea Pearl)出版了《智能系统中的概率推理》一书,书中介绍了贝叶斯网络(Bayesian Networks)。贝叶斯网络是一种基于概率图模型的表示方法,用于表示变量之间的概率关系。 - 1990年代被称为"AI寒冬"(AI Winter),这是一个对人工智能研究和应用持悲观态度、资金支持减少的时期。
尽管1990年代整体上对AI持悲观态度,但这一时期在机器学习研究方面却取得了许多重要进展。以下是一些关键的机器学习技术和方法:
Markov chain Monte Carlo(马尔可夫链蒙特卡洛方法):
一种用于从复杂概率分布中抽样的方法,广泛应用于贝叶斯统计和机器学习中的概率模型。
Variational inference(变分推断):
一种用于近似复杂概率分布的方法,通过优化一个变分下界来近似后验分布。
Kernels and support vector machines(核方法和支持向量机):
核方法是一种将数据映射到高维空间的技术,支持向量机(SVM)是一种基于核方法的分类算法,能够处理非线性分类问题。
Boosting(提升方法):
一种集成学习方法,通过组合多个弱学习器来构建一个强学习器。例如,AdaBoost是一种经典的提升算法。
Convolutional networks(卷积神经网络):
一种深度学习模型,特别适用于图像处理任务。卷积神经网络通过卷积层和池化层来提取图像的特征。
Reinforcement learning(强化学习):
一种机器学习方法,智能体通过与环境的交互来学习最优的行为策略,以最大化长期累积奖励。 - 2000年代,机器学习开始在应用型人工智能领域(如计算机视觉、自然语言处理等)得到广泛应用。这些领域的研究者开始采用机器学习算法来解决实际问题。
- 2010年代,深度学习成为机器学习领域的主导技术。深度学习通过构建多层神经网络来学习数据中的复杂模式和特征。
2010-2012年,神经网络在语音识别和图像识别任务中取得了突破性进展,打破了之前的记录。
深度学习技术逐渐被科技行业广泛采用,推动了许多应用的发展,如自动驾驶、语音助手、图像识别等。
2016年,DeepMind的AlphaGo击败了人类围棋冠军李世石,标志着强化学习和深度学习在复杂决策任务中的强大能力。
2018年至今,生成对抗网络(GANs)等技术被用于生成逼真的图像和视频,推动了生成模型的发展。
2020年,OpenAI发布了GPT-3语言模型,展示了自然语言处理领域的巨大进步,能够生成高质量的文本。 - 近年来,随着机器学习和人工智能的广泛应用,人们越来越关注其伦理和社会影响。这些问题包括算法偏见、隐私保护、自动化对就业的影响等。
现如今机器学习(Machine Learning, ML)在计算机视觉(Computer Vision,例如目标检测、语义分割、姿态估计)、语音处理(Speech Processing,例如语音转文本、个人助手、说话人识别)和自然语言处理(Natural Language Processing, NLP,例如机器翻译、情感分析、主题建模、垃圾邮件过滤)三个领域中的广泛应用。
1.9 机器学习的流程
1.在开始使用机器学习之前,需要评估是否适合使用机器学习来解决这个问题。以下是一些关键问题:
是否存在可检测的模式?(机器学习的核心是发现数据中的模式。如果问题中没有明显的模式,机器学习可能不是最佳选择。)
我能否通过分析方法解决它?(如果问题可以通过传统的分析方法,如数学公式或逻辑规则解决,那么可能不需要机器学习。)
我是否有数据?
2.收集和整理数据:
Preprocessing(预处理):数据预处理包括数据清洗、归一化、标准化等,以确保数据的质量和一致性。
Cleaning(清洗):数据清洗涉及去除噪声、处理缺失值、纠正错误等,以提高数据的质量。
Visualizing(可视化):数据可视化有助于理解数据的分布、特征之间的关系以及潜在的模式。
3.建立一个基线模型。基线模型可以是一个简单的模型,用于比较后续更复杂模型的性能。例如:
使用简单的统计方法:
对于分类问题,可以使用多数类分类器作为基线。
对于回归问题,可以使用均值预测作为基线。
4.选择合适的模型、损失函数和正则化方法。以下是一些考虑因素:
Model(模型):选择适合问题的模型,如线性回归、决策树、神经网络等。
Loss(损失函数):选择合适的损失函数,如均方误差(MSE)用于回归问题,交叉熵损失(Cross-Entropy Loss)用于分类问题。
Regularization(正则化):使用正则化方法(如L1、L2正则化)来防止过拟合。
5.优化,这涉及调整模型参数以最小化损失函数。优化方法可以简单也可以非常复杂,具体取决于问题的复杂性和模型的类型。例如:
简单优化:使用梯度下降等基本优化算法。
复杂优化:使用更高级的优化算法,如Adam、RMSprop等。
6.超参数搜索是调整模型超参数以优化模型性能的过程。超参数包括学习率、正则化参数、网络结构等。常见的方法包括:
Grid Search(网格搜索):系统地搜索超参数空间。
Random Search(随机搜索):随机选择超参数进行搜索。
Bayesian Optimization(贝叶斯优化):
使用贝叶斯方法来优化超参数。
7.分析模型的性能和错误,并根据结果进行迭代改进。这可能涉及:
Performance Analysis(性能分析):使用评估指标(如准确率、召回率、F1分数、均方误差等)来评估模型的性能。
Error Analysis(错误分析):分析模型的错误,了解模型在哪些情况下表现不佳。
Iterate(迭代):根据分析结果,返回步骤4(选择模型和优化)或步骤2(数据收集和预处理),进行进一步的改进。
2. Nearest Neighbor Methods(最近邻方法)
2.1 机器学习的预备知识
今天我们先专注于监督学习。这意味着我们有一个由输入和相应标签组成的训练集,例如:
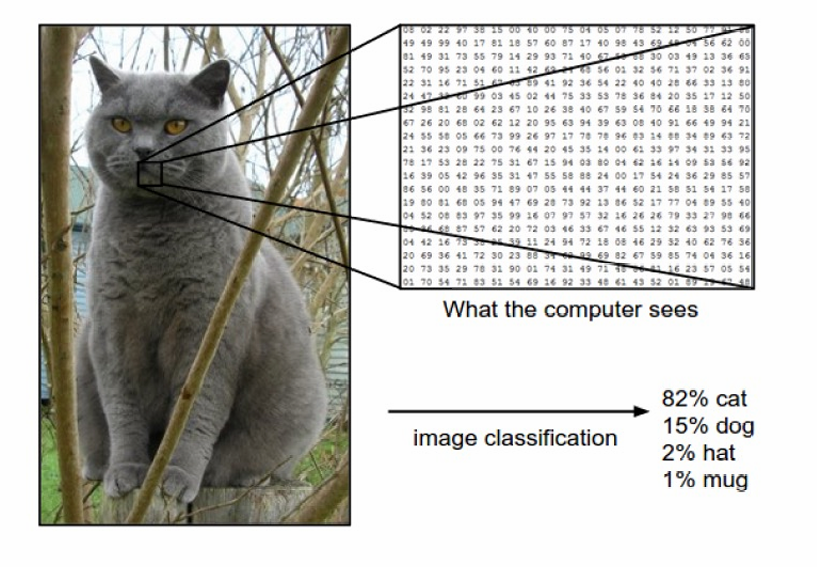
机器学习算法需要处理多种类型的数据,包括图像、文本、音频波形、信用卡交易等。这些数据的格式和结构各不相同,因此需要一种通用的方法来处理它们。
一种常见的策略是将输入数据表示为实数空间( R d ℝ^d Rd)中的向量。这意味着无论原始数据的类型如何,都可以将其转换为一个数值向量,这个向量可以在数学上进行操作和处理。
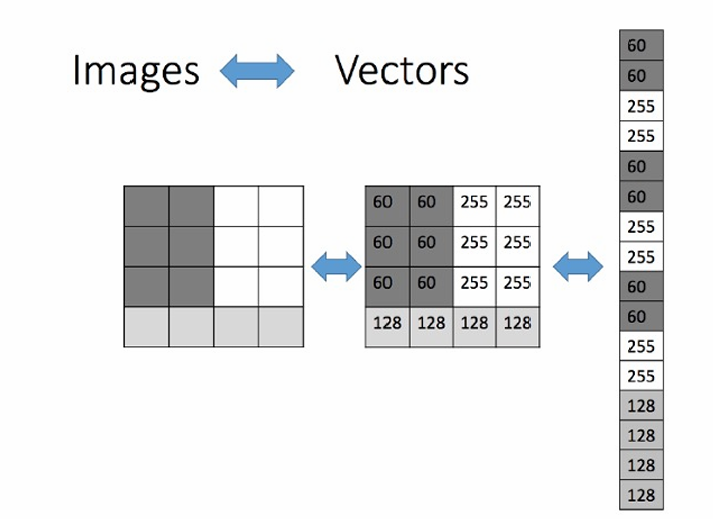
下图展示了如何将图像可以被转换为向量形式。
从数学上讲,训练集由输入向量 x x x和其对应的目标或标签 t t t组成的一对对数据组成。这里 x x x是一个 d d d维实数向量( x ∈ R d x∈R^d x∈Rd),表示输入特征; t t t是与输入 x x x相关联的目标值或标签。
在回归任务中,目标 t t t是一个实数,例如股票价格。回归任务的目标是预测一个连续值。
在分类任务中,目标 t t t是一个离散集合中的元素,例如 1 , 2 , 3 , ... , C {1,2,3,...,C} 1,2,3,...,C,其中 C C C是类别的总数。分类任务的目标是预测输入属于哪个类别。
如今,目标 t t t常常是一个高度结构化的对象,例如图像。这可能指的是在某些任务中,目标本身可能是复杂的数据结构,而不仅仅是一个简单的数值或类别标签。
训练集可以表示为 { ( x ( 1 ) , t ( 1 ) , . . . , ( x ( N ) , t ( N ) } \{(x^{(1)},t^{(1)},...,(x^{(N)},t^{(N)}\} {(x(1),t(1),...,(x(N),t(N)},其中 N N N是训练样本的数量。每个 { ( x ( i ) , t ( i ) ) } \{(x^{(i)},t^{(i)})\} {(x(i),t(i))} 对代表第 i i i个训练样本及其对应的标签或目标值。
2.2 最近邻(Nearest Neighbors)算法
假设我们有一个新输入向量 x x x,我们想要对其进行分类。
现在我们使用最近邻算法去解决这里的分类问题。这种方法的基本思想是在训练集中找到与 x x x最接近的输入向量,并复制它的标签。
我们可以用最简单的数学方法去解决这里的接近,我们通过欧几里得距离的形式化定义"最近"。欧几里得距离是两点在欧几里得空间中的直线距离。

因此这个算法的步骤如下:
- 找到训练集种与 x x x距离最近的样本 x ∗ x^* x∗。
- 输出 y y y作为 x x x的预测标签,这里 y y y是 t ∗ t^* t∗的标签。
2.3 可视化
2.3.1 Voronoi图(Voronoi diagram)
我们可以使用Voronoi图来可视化分类问题中模型的行为。如下图所示。
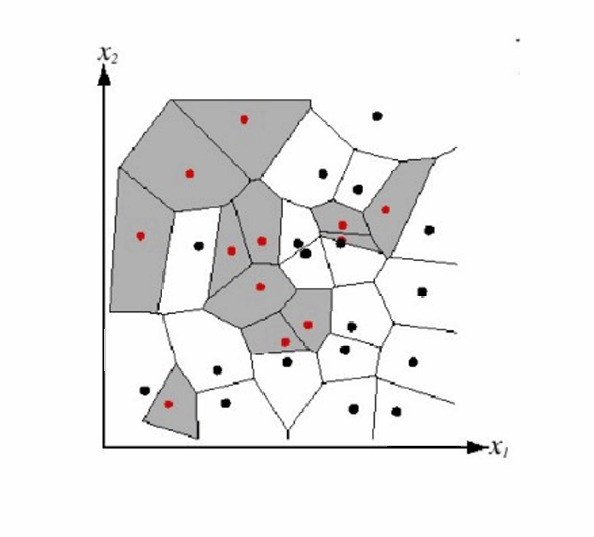
Voronoi图中的每个区域可以代表一个分类边界,即模型决定将输入分配给特定类别的区域。
每个由Voronoi图定义的区域可以看作是模型对于输入数据点的决策区域,即输入数据点落在哪个区域就属于哪个类别。
在最近邻算法中,Voronoi图可以帮助我们理解每个训练样本如何影响分类决策。每个训练样本对应Voronoi图中的一个区域,该区域内的所有点都被认为是最靠近该训练样本的。
通过Voronoi图,我们可以直观地看到模型是如何根据训练数据做出分类决策的,这有助于提高模型的可解释性。
如图,红色的点和黑色的点代表不同的类,它们都是这个区域的生成点。如果一个新的输入数据落在阴影区域那就属于红色的点所代表的类。
2.3.2 决策边界(Decision boundary)
决策边界是分类模型在输入空间中划分不同类别区域的边界。
下图的黑线便展示了一个决策边界。
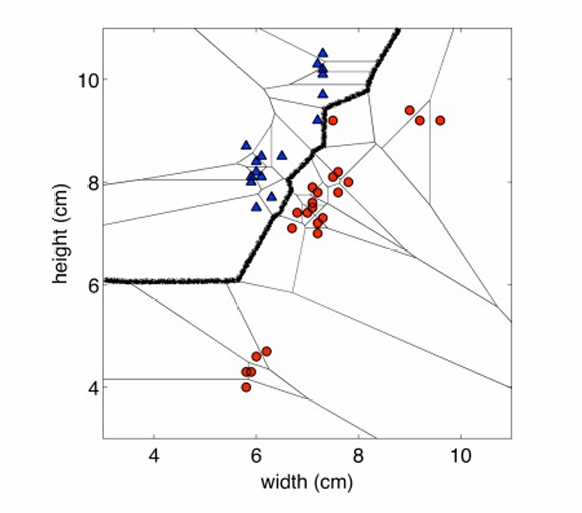
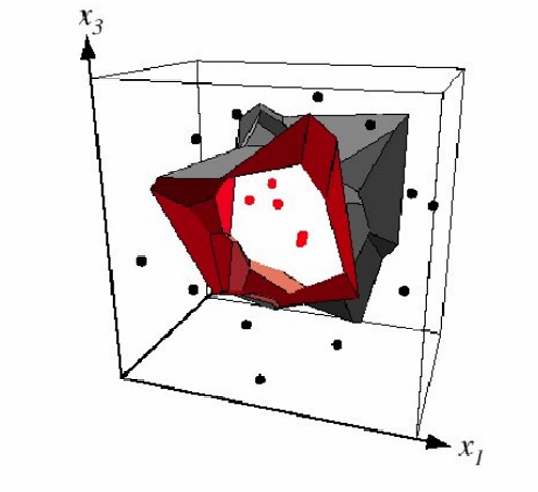
上面的示例是二维的,下面再给出一个三维的例子,那这里的边界就会变成二维了。
2.4 k-NN(k-最近邻算法)
最近邻(Nearest Neighbors,简称NN)算法在处理噪声或错误标记数据是敏感的,换句话说最近邻算法容易在有噪点时产生误差。
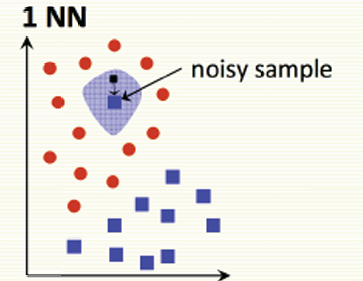
图中蓝色阴影区域将被错误分类为蓝色类别的样本区域。
对于这种传统的方法,我们现在推出k-NN算法(k-最近邻算法),这个算法通过考虑多个最近邻样本并进行投票从而减少单个噪声样本的影响,从而提高分类的准确性和鲁棒性。
k-NN算法的详细步骤如下:
- 算法首先在训练集中找到与新的测试实例 x x x最接近的 k k k个样本。这些样本及其对应的标签表示为 { x ( i ) , t ( i ) } \{x^{(i)} ,t^{(i)}\} {x(i),t(i)}。
因此最近邻算法就是k-NN算法中 k=1 的情况。 - 然后,算法根据这 k k k个最近邻居的标签进行多数表决,以确定新实例的预测标签。即,选择出现次数最多的标签作为预测结果。(下面的数学公式可能较难理解,理解这句话就好)
y = arg max t ( z ) ∑ i = 1 k I ( t ( z ) = t ( i ) ) y = \arg\max_{t^{(z)}} \sum_{i=1}^{k} \mathbb{I}(t^{(z)} = t^{(i)}) y=argmaxt(z)∑i=1kI(t(z)=t(i))
这个公式表示,对于每个可能的标签 x ( z ) x^{(z)} x(z) ,计算在 k k k个最近邻居中,标签等于 t ( z ) t^{(z)} t(z)的样本数量。
I \mathbb{I} I是指示函数(identity function),当括号内的陈述为真时,其值为 1 1 1,否则为 0 0 0。这里,它用于计算标签 t ( z ) t^{(z)} t(z)在 k k k个最近邻居中出现的次数。 arg max \arg\max argmax表示找到使括号内求和最大的 t ( z ) t^{(z)} t(z) ,即选择出现次数最多的标签作为预测标签 y y y。
因此指示函数可以写成
δ ( a , b ) = { 1 , if a = b 0 , otherwise \delta(a, b) = \begin{cases} 1, & \text{if } a = b \\ 0, & \text{otherwise} \end{cases} δ(a,b)={1,0,if a=botherwise
所以公式现在可以重写为
y = arg max t ( z ) ∑ i = 1 k δ ( t ( z ) , t ( i ) ) y = \arg\max_{t^{(z)}} \sum_{i=1}^{k} \delta(t^{(z)}, t^{(i)}) y=argmaxt(z)∑i=1kδ(t(z),t(i))
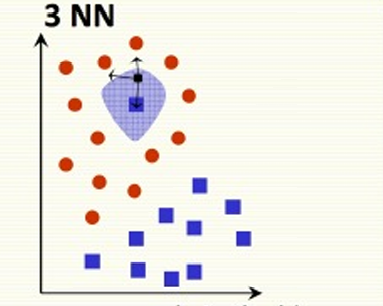
因此前面的情况使用k-NN算法,k=3 的时候,由于蓝色阴影区域内最近的三个样本中有两个是红色点,因此这些样本会被正确地分类为红色类别。
因此我们现在知道随着k上升,这些噪点对于结果的影响就会越小,误差就会越小。
如下图所示,k=1。
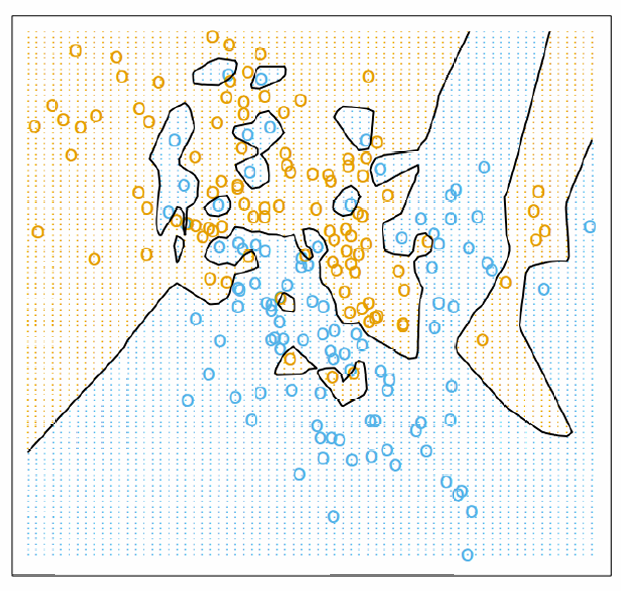
当K=15。
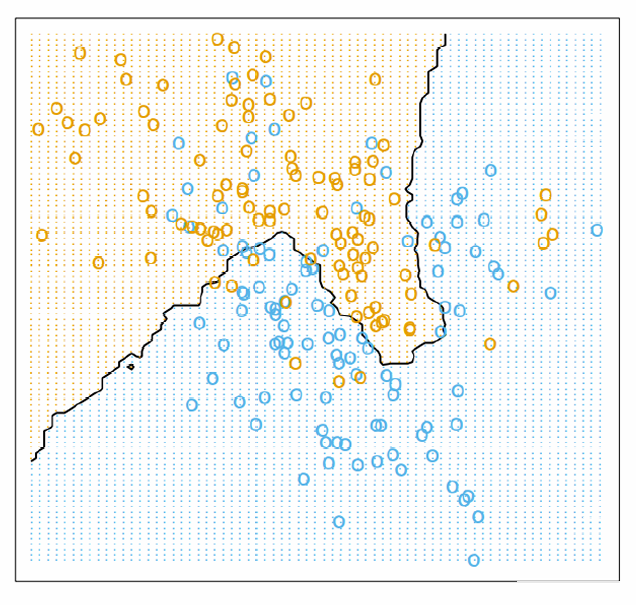
当然我们的 k 也不能无限大,k 太小的话结果就不够全面,信息过于片面,如果 k 太大,比如 k 和数据的值一样多,那我们也没法完成分类,分类变成了少数服从多数。
选择小 k 值的权衡:
优点:
能够捕捉到更细粒度的模式(Good at capturing fine-grained patterns)。这意味着小 k 值可以帮助模型识别数据中的细微差别。
缺点:
可能会过拟合(May overfit)。过拟合是指模型对训练数据中的随机噪声过于敏感,导致模型在新数据上的泛化能力差。
选择大 k 值的权衡:
优点:
通过平均许多样本来做出稳定的预测(Makes stable predictions by averaging over lots of examples)。大 k 值可以使模型的预测更加平滑和稳定。
缺点:
可能会欠拟合(May underfit)。欠拟合是指模型无法捕捉到数据中的重要模式,导致模型在训练数据上的性能也不好。
所以我们需要平衡 k 值, k 值的最佳选择取决于数据点的数量 n。 如果 k 趋向于无穷大,并且 k/n 趋向于 0,那么理论上其有良好的性质。
我们经验上一般选择 k 小于数据点数量的平方根( k < √ n k < √n k<√n)。
当然我们可以使用验证集来选择最佳的 k 值。通过在验证集上评估不同 k 值的性能,可以找到使模型性能最优的 k 值。
2.4.1 k-NN 算法的泛化能力
泛化能力是指模型在新数据上的表现能力,即模型能够处理未见过的数据并做出准确预测的能力。
因此我们希望我们的算法能有较好的泛化能力。
我们可以使用测试集来衡量泛化误差(新样本上的误差率)。
下图展示了一个例子。
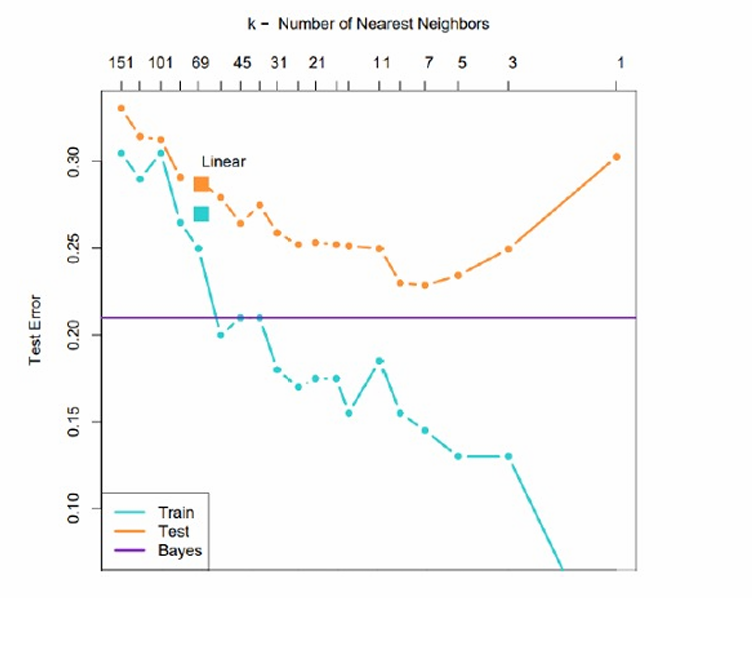
训练误差随着 k 值的增加,训练误差逐渐降低。这是因为较大的 k 值使得模型更加平滑,能够更好地拟合训练数据。
测试误差在 k 值较小时较高,随着 k 值的增加而降低,但在 k 值过大时又开始上升。这是因为较小的 k 值可能导致过拟合,而较大的 k 值可能导致欠拟合。
2.4.2 超参数
k 是 k-NN 算法中的一个超参数,它决定了在进行预测时考虑多少个最近的邻居。
超参数是学习算法的配置参数,不能通过训练数据本身来学习,需要手动设置。我们通过使用验证集来调整超参数 k。
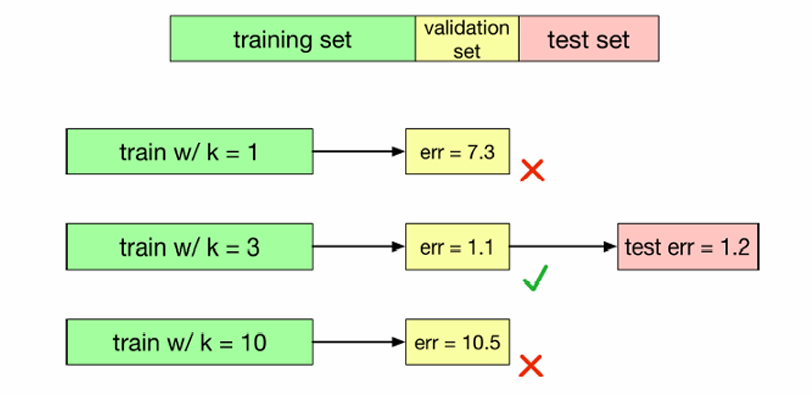
注意我们不能使用测试集去训练,因为这样就是对着答案写答案,而是应该以验证集的结果去评估超参数的性能,调整超参数。
如上图所示,k=3 的时候,验证误差最小,因此我们选其进行测试。
2.4.3 应用
k-NN 算法的性能很大程度上取决于如何度量输入数据之间的相似性。一个更好的相似性度量可以显著提高分类的准确性。
例如形状上下文(Shape Contexts)用于对象识别,形状上下文是一种用于对象识别的技术,旨在实现对图像变换的不变性。它通过将一个图像变形(warp)以匹配另一个图像来实现这一点。
在形状上下文中,距离度量是通过计算变形图像上对应点之间的平均距离来定义的。

使用形状上下文的 k-NN 算法在 MNIST 数据集上的错误率为 0.63%,而使用传统的欧几里得距离的 k-NN 算法的错误率为 3%。这便是使用形状上下文技术来改善相似相似性度量来提高对象识别的准确性。然而,这种方法需要复杂的图像处理和变形技术,而相比之下,卷积神经网络可能提供了一种更自动化和易于扩展的解决方案。
2.4.4 总结
- k-NN 是一个简单的算法,它在测试时完成所有工作,从某种意义上说,它并没有"学习"过程。因为他无需训练,而是直接将训练数据存储起来,等到有新的数据需要预测时,再根据存储的数据进行分类或回归。
- 可以通过改变 k 值来控制模型的复杂度。较小的 k 值会使模型更敏感于训练数据中的噪声,可能导致过拟合;较大的 k 值会使模型更平滑,但可能无法捕捉到数据中的重要模式,导致欠拟合。
- k-NN 算法可能会受到"维度的诅咒"(Curse of Dimensionality)的影响。随着特征维度的增加,数据点之间的距离变得不那么有意义,导致算法性能下降。这是因为在高维空间中,数据点之间的距离趋向于相等,使得"最近邻"的概念变得模糊。