还记得 一道面试题,开始性能优化之旅(3 )-- DNS 查询 +TCP(一) 里面我们提到过 TCP的耗时吗? 对,是至少1RTT
优化手段里我们提到 复用连接,今天我们就由 复用连接引出 今天的主角 HTTP/2 和 HTTP/3
tips:HTTP/2 与 HTTPS 有关系吗?
HTTPS本质是HTTP over TLS,即在TLS加密的TCP连接上传输HTTP数据,是安全传输框架
HTTP/2 是应用层协议,是HTTP协议的一个新版本,主要解决HTTP/1.x的性能问题。
典型错误认知澄清
| 误区 | 事实说明 |
|---------------------------|----------------------------|
| "HTTP/2 替代 HTTPS" | HTTP/2 依赖 HTTPS |
| "HTTPS 自动支持 HTTP/2" | 需显式配置ALPN和协议支持 |
| "HTTP/2 不需要加密" | 浏览器强制要求加密传输
HTTP/2和性能
问题本质:TCP 与 HTTP/1.x 的协作矛盾
关键痛点详解
复用连接
1. TCP 建连成本高昂
- 三次握手耗时 :至少 1 RTT (Round-Trip Time)
- 典型延迟 :
- 本地网络:1~10ms
- 跨国访问:100~500ms
- 结果:小文件请求的建连时间可能超过实际传输时间
2. 连接无法复用造成浪费
- HTTP/1.0 问题:默认每个请求新建 TCP 连接
- HTTP/1.1 改进 :引入
Connection: keep-alive
3. 资源占用问题
| 资源类型 | 单连接消耗 | 并发 100 连接消耗 |
|---|---|---|
| 内存 | 约 200 KB | 20 MB |
| 文件描述符 | 1 个 | 100 个(易触达上限) |
| CPU | 握手加解密消耗 | 雪崩式增长 |
Keep-Alive 工作原理
1. 启用流程
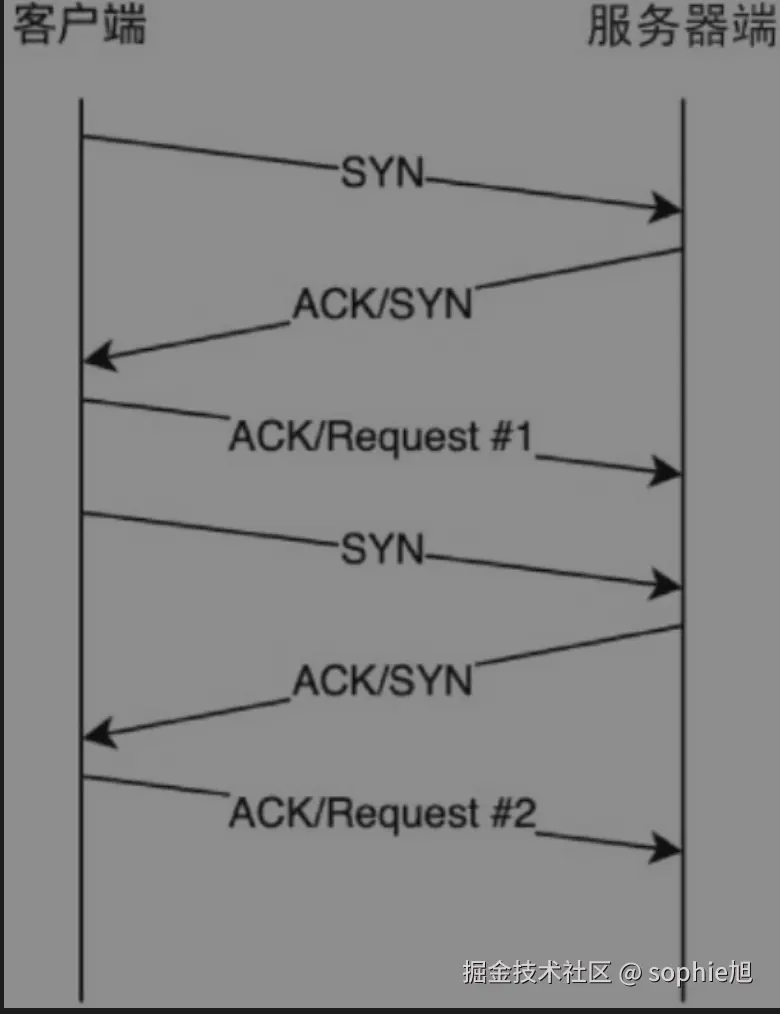
队头阻塞
1. 串行请求的必然性
-
HTTP/1.1 协议规范 :
同一TCP连接上的请求必须满足 FIFO(先进先出)原则sequenceDiagram Client->>Server: 请求A Server->>Client: 响应A Client->>Server: 请求B Server->>Client: 响应B -
即使无依赖关系 :
请求B(如加载CSS)必须等待请求A(如下载图片)完成
2. 浏览器的突围策略
-
并行TCP连接池 :
创建多个TCP连接实现伪并行
graph LR 连接1 --> 请求A 连接2 --> 请求B 连接3 --> 请求C浏览器一般以域名为维度限制TCP连接的并发数,这个数字大多数是6。 -
连接数限制原因:
限制类型 原因 典型值 服务器资源 每个连接消耗内存/CPU - 客户端资源 手机等设备性能有限 - 域名约束 防止单个域名垄断客户端资源 6
3. 域名分片本质图解
HTTP/1.1 时代突破浏览器并发限制的核心优化技术------域名分片(Domain Sharding)
- 核心目标 :绕过浏览器对单域名并发连接数限制(通常6个)
- 实现方式:将资源分散到多个子域名
- 效果 :总并发连接数 = 子域名数 × 6
收益
scss
理论最大并发数 = min(浏览器全局连接数, 子域名数 × 6)- Chrome全局连接数限制:256
- 当子域名数=4时:4×6=24 << 256 → 有效提升
代价清单
| 成本类型 | 说明 | 影响幅度 |
|---|---|---|
| DNS查询 | 新增N次DNS解析 | +50~200ms/域名 |
| TCP握手 | 新增连接需要三次握手 | +1~3 RTT/连接 |
| TLS握手 | HTTPS下每次连接需完整握手 | +2 RTT/连接 |
| 服务器资源 | 更多连接消耗更多内存/CPU | 线性增长 |
| 缓存失效 | 分散域名降低缓存命中率 | 视资源分布而定 |
HTTP/2 解决队头阻塞的核心革命------多路复用
一、HTTP/2 多路复用本质
- 核心突破 :
将HTTP消息拆分为带流ID的二进制帧 ,在单TCP连接上交错传输 - 效果 :
请求B无需等待请求A完成,实现真并行
二、对比HTTP/1.1的串行阻塞
HTTP/1.1 队头阻塞场景
- 问题:小资源请求被大资源阻塞
HTTP/2 多路复用场景
- 奇迹发生 :
关键CSS(流2)在大文件传输完成前已返回并渲染!
三、技术实现三要素
1. 二进制分帧层
http
HTTP消息 → 拆分为帧:
┌───────────────┐
│ 帧头 (9字节) │
├───────────────┤
│ 流ID (31位) │ ← 核心标识
├───────────────┤
│ 帧类型 │
├───────────────┤
│ 载荷数据 │
└───────────────┘2. 流ID(Stream ID)机制
- 每个请求分配唯一奇整数流ID
- 帧头携带流ID标识归属
- 接收方按流ID重组消息
3. 帧类型与优先级
| 帧类型 | 作用 | 优先级控制 |
|---|---|---|
| HEADERS | 发送请求头 | 可设置权重(1-256) |
| DATA | 传输响应体 | 依赖树指定传输顺序 |
| PRIORITY | 动态调整流优先级 | 实时优化关键资源 |
四、乱序传输动态演示
请求流程(图10-4实质)
关键特征:
- 响应顺序与请求顺序无关
- 关键CSS优先传输完成(即使最后请求)
- 大JS文件被拆分为多帧穿插传输
五、性能提升原理
消除三类阻塞
| 阻塞类型 | HTTP/1.1 | HTTP/2 |
|---|---|---|
| 请求阻塞 | 单连接内串行 | 并行交错传输 |
| 响应阻塞 | 必须顺序返回 | 乱序返回 |
| 头部阻塞 | 重复传输头部 | HPACK压缩 |
量化收益(加载50资源)
| 指标 | HTTP/1.1 (6连接) | HTTP/2 (单连接) | 提升 |
|---|---|---|---|
| 总耗时 | 4.2s | 1.1s | 282% |
| TCP连接数 | 6 | 1 | -83% |
| 传输数据量 | 1.8MB | 1.5MB (HPACK压缩) | -17% |
demo对比
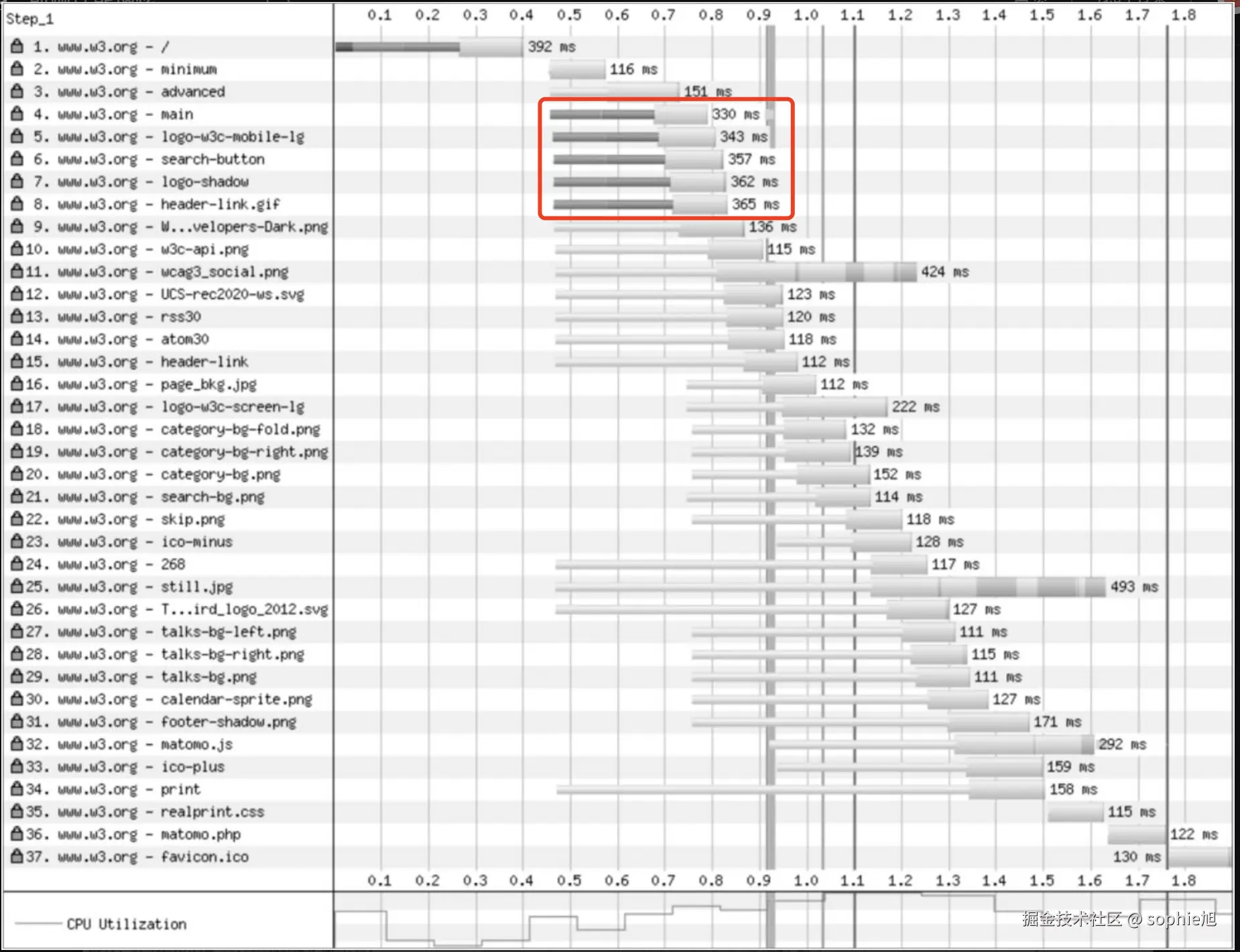
浏览器同时建立了5个连接,超出5个的并发限制后,请求和响应都是排队进行的。
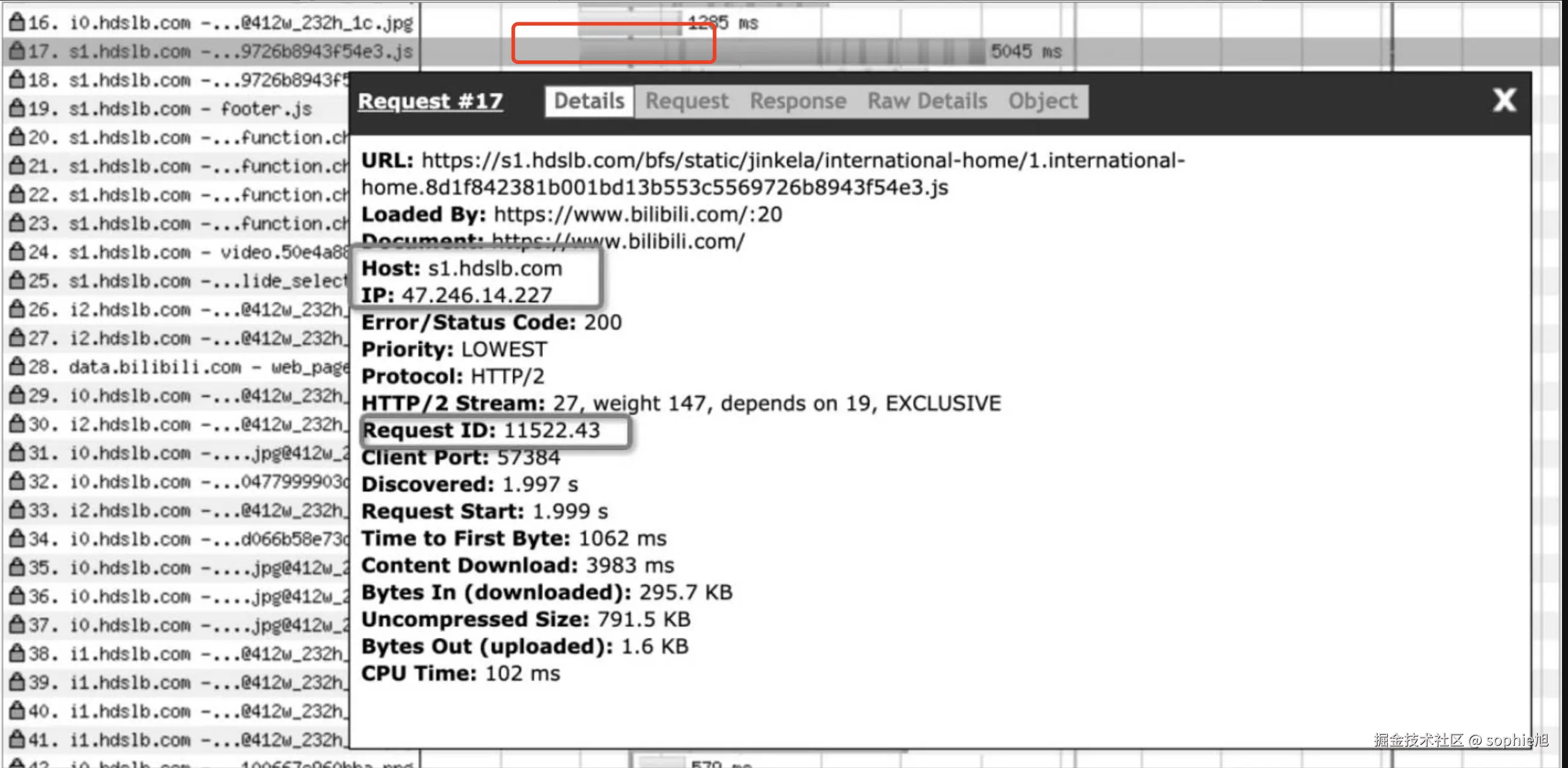 浏览器只建立了一个tcp连接,所有的请求都是并行发起的,响应的时间也和先后无关,这样整体的响应时间得以提前。
浏览器只建立了一个tcp连接,所有的请求都是并行发起的,响应的时间也和先后无关,这样整体的响应时间得以提前。
在什么情况下不能复用连接
- 普通JS:
script src="s1.bilibili.com/a.js">→ 复用主连接 - CORS JS:
script src="s1.bilibili.com/b.js" crossorigin>→ 强制新建连接
那么为啥要加 crossorigin?
1. 问题本质:跨域脚本的"静默失败"
javascript
// 假设加载第三方SDK
<script src="https://third-party.com/sdk.js"></script>
// SDK内部发生错误时
throw new Error("Critical API failure"); // 浏览器会屏蔽具体错误信息- 无 crossorigin 时 :浏览器只返回
Script error.通用提示 - 关键信息丢失:错误堆栈、行号、具体消息全部被隐藏
2. 解决方案:启用 CORS 错误捕获
html
<script src="https://third-party.com/sdk.js" crossorigin="anonymous"></script>此时浏览器会:
- 添加
Origin请求头 - 要求服务器返回
Access-Control-Allow-Origin响应头 - 解锁完整错误信息:
json
{
"message": "Uncaught TypeError: Cannot read properties of undefined",
"stack": "TypeError: Cannot read properties of undefined\n
at Module.init (sdk.js:127:15)\n
at HTMLDocument.<anonymous> (main.js:54:7)",
"line": 127,
"column": 15,
"sourceURL": "https://third-party.com/sdk.js"
}所以案例中,B站正是为了确保能捕获广告SDK、用户行为分析等关键脚本的错误,才选择牺牲部分连接复用性能,这是典型的业务价值优先决策。
HTTP/2 TCP连接复用与域名有关吗?
HTTP/2 连接复用基于 **TCP 四元组(源IP/端口 + 目标IP/端口)**,与域名无关
针对HTTP/2 的优化策略
● 尽可能统一域名、IP地址和证书,减少建立连接的成本。
多路复用的连接复用条件
- 协议要求(RFC 7540):
-
仅需满足 IP+端口 相同即可复用连接
-
不要求 相同域名(例如
a.com和b.com可复用连接)
- 浏览器现实限制:
-
现代浏览器强制实施 同源策略增强:
-
Chrome/Firefox/Safari 要求 完全相同的证书域名
-
跨域连接即使IP相同也会新建TCP+TLS连接
● 对于请求是否成功复用连接或preconnect,需要关注credentials是否一致。
为了确保你的网络请求能够成功利用浏览器提供的连接复用机制或预连接(preconnect)优化来提升性能,
你必须特别注意该请求的凭证设置(credentials)是否与它将要使用的那个底层连接的"凭证状态"相匹配。
如果不匹配(例如,试图让一个需要凭证的请求去使用一个"干净"的预连接),复用或预连接就会失败,导致额外的连接建立开销。
浏览器不会让一个"干净"(无凭证)的连接被用来发送敏感(带凭证)的请求,反之亦然(一个"脏"的带凭证连接也不能被用来发送不敏感的请求)。连接必须与请求的凭证要求"匹配"。
◆ 停用域名拆分,如果需要保留对HTTP/1用户的优化,至少需要让多个域名指向同一个IP地址,从而在HTTP/2下复用请求。什么意思
让我们分解这句话的含义:
-
背景:HTTP/1.1 的瓶颈与域名拆分
-
问题: HTTP/1.1 一个主要限制是 队头阻塞(Head-of-Line Blocking)。浏览器对同一个域名(源)的并发连接数有限制(通常是 6-8 个)。如果一个连接上的大文件或慢请求阻塞了,后续请求即使资源很小、很快,也必须排队等待。
-
解决方案(域名拆分): 为了突破这个并发连接数的限制,开发者将网站资源(如图片、CSS、JS)分散到 多个子域名 下(例如
static1.example.com,static2.example.com,static3.example.com)。因为浏览器对每个不同的域名 都有独立的连接数限制。这样,浏览器就能同时打开更多连接(例如 3 个子域名 * 6 连接 = 18 个并发连接),显著提升页面加载速度。这就是 域名拆分(Domain Sharding)。
-
-
HTTP/2 的优势与域名拆分的副作用
- HTTP/2 的改进: HTTP/2 引入了 多路复用(Multiplexing) 。它允许在 同一个 TCP/TLS 连接 上同时传输多个请求和响应(数据被拆分成帧,交错传输)。这从根本上解决了 HTTP/1.1 的队头阻塞问题。浏览器不再需要为同一个源建立多个连接,一个连接就能高效处理所有请求。
- 域名拆分的副作用(在 HTTP/2 下):
- 浪费连接: 每个子域名都需要建立自己独立的 TCP/TLS 连接。建立连接(尤其是 TLS 握手)本身就有开销(延迟、CPU 资源)。
- 破坏多路复用: 资源被分散到不同域名,意味着它们无法在同一个连接上多路复用。浏览器必须为每个子域名维护独立的连接池。
- 浪费缓存: 浏览器缓存(如 HTTP 缓存、TLS 会话票证)是按域名/源隔离的。分散域名降低了缓存的利用率。
- 增加 DNS 查询: 每个额外的子域名都可能需要额外的 DNS 查询(如果未被缓存)。
- 增加请求头冗余: 每个独立连接上的请求都需要发送完整的请求头(如
Cookie,User-Agent),无法像在同一个连接上那样复用 HPACK 压缩上下文(HTTP/2 头部压缩)。
-
解决方案:停用域名拆分 + 域名收敛
- 停用域名拆分: 在 HTTP/2 环境下,最佳实践是撤销 域名拆分策略。将所有资源收敛回尽可能少的域名(理想情况下是同一个源,或者少数几个源)。这样可以利用 HTTP/2 的多路复用特性,在少量连接(甚至一个连接)上高效传输所有资源,避免上述所有副作用。
- 保留对 HTTP/1.1 用户的优化: 问题在于,世界上仍有部分用户(使用旧浏览器、旧代理、或网络环境限制)只支持 HTTP/1.1。如果简单地把所有资源都放回一个域名,这些用户又会受到 HTTP/1.1 并发连接数限制的严重影响,页面加载速度会变慢。
- 折中方案:多个域名指向同一个 IP 地址:
- 核心思路: 配置 DNS,让之前用于拆分的多个子域名 (如
static1.example.com,static2.example.com)都 解析到同一个 Web 服务器的 IP 地址。 - 对 HTTP/1.1 用户:
- 浏览器仍然认为
static1.example.com和static2.example.com是不同的源。 - 因此,浏览器会为每个子域名建立独立的连接(例如最多 6 个连接/域名)。
- 这样,HTTP/1.1 用户仍然能获得域名拆分带来的并发连接数提升优势。
- 浏览器仍然认为
- 对 HTTP/2 用户:
- 浏览器支持 HTTP/2 的 连接合并(Connection Coalescing) 特性。
- 连接合并的条件:
- 多个域名解析到同一个 IP 地址。
- 服务器为该 IP 地址上的这些域名提供了有效的、包含所有这些域名的 TLS 证书 (通常使用通配符证书
*.example.com或多域名 SAN 证书)。 - HTTP/2 协议本身支持。
- 效果: 当浏览器需要向
static1.example.com和static2.example.com发起请求时,如果它们满足连接合并条件,浏览器不会 建立两个独立的连接。它会尝试复用 已经建立的、指向该共享 IP 地址的同一个 HTTP/2 连接。所有请求都在这个单一连接上通过多路复用来传输。 - 结果: HTTP/2 用户避免了域名拆分带来的连接开销、DNS 开销、缓存碎片化等问题,享受到了域名收敛和 HTTP/2 多路复用的全部性能优势。
- 核心思路: 配置 DNS,让之前用于拆分的多个子域名 (如
总结这句话的意思:
当网站从 HTTP/1.1 升级支持 HTTP/2 后,应该停止使用域名拆分策略(停用域名拆分)。但是,为了确保仍然使用 HTTP/1.1 的旧客户端用户不会因并发连接限制而性能下降(保留对 HTTP/1 用户的优化),可以采取一个折中方案:让之前用于拆分的多个子域名(如
static1.example.com,static2.example.com)继续存在,但在 DNS 配置上让它们都指向后端服务器的同一个 IP 地址(多个域名指向同一个IP地址)。这样:
- HTTP/1.1 用户: 看到多个不同域名,建立多个连接,获得并发优势。
- HTTP/2 用户: 因为多个域名指向同一 IP 且服务器配置正确(证书),浏览器可以复用同一个 HTTP/2 连接来处理所有子域名的请求(从而复用请求),避免了域名拆分的副作用,获得最佳性能。
简单来说: 这是一种让网站在同一个部署架构下,同时为使用新旧两种 HTTP 协议的用户提供较好性能的兼容性策略。核心技巧是利用 DNS 和 HTTP/2 的连接合并特性。
头部压缩对我们有什么影响
-
HTTP/1.1 头部未压缩:巨大的冗余之源
- 纯文本传输: 在 HTTP/1.1 中,请求头(Request Headers)和响应头(Response Headers)都是以纯文本形式发送的,没有任何压缩机制。
- 请求激增: 现代网页极其复杂,加载一个页面通常需要发起数十个甚至上百个 HTTP 请求(获取 HTML、CSS、JavaScript、图片、字体、API 数据等)。
- 头部冗余: 这些请求的头部信息中有大量字段是高度重复 的。例如,几乎每个请求都会包含:
Host: www.example.comUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) ...Accept: */*或类似的 MIME 类型Accept-Language: en-US, en;q=0.9Connection: keep-alive(对于持久连接)- 最重要的是:
Cookie: ...(如果存在且作用域匹配) 浪费累积: 想象一下,一个页面有 100 个资源请求。即使每个请求的头部只重复传输了 500 字节的相同信息(这在包含 Cookie 时很容易达到),那么仅头部冗余就浪费了 100 * 500B = 50KB 的带宽!这还只是保守估计,实际中 Cookie 可能更大。这些冗余数据在网络传输、服务器解析、浏览器处理上都造成了不必要的开销,显著增加了延迟。
-
Cookie:头部体积的"罪魁祸首"
- 身份与状态载体: Cookie 是浏览器存储并在后续请求中自动发送给服务器的一小段数据,主要用于会话管理(Session ID)、用户偏好、跟踪标识等。它是维持有状态 HTTP 交互的核心机制。
- 体积膨胀:
- 单个 Cookie 的大小可以从几十字节到几 KB 不等。
- 一个网站通常会设置多个 Cookie(会话 ID、用户 ID、分析 ID、AB 测试分组、个性化设置等)。
- 这些 Cookie 会被浏览器自动附加 到每一个 符合其作用域(Domain, Path)和安全性(Secure, HttpOnly)要求的请求的
Cookie请求头中。
- 成为头部最大负担: 在包含 Cookie 的请求中,
Cookie头通常是整个请求头中体积最大、占比最高 的部分。一个包含多个 Cookie 的Cookie头很容易达到 1KB、2KB 甚至更大。 - 重复传输的代价: 由于 HTTP/1.1 没有头部压缩,这个庞大的
Cookie字符串会在每一个 发往该域名(及其子域名,取决于作用域)的请求中被完整地、重复地传输。对于加载一个包含大量资源(如图片、脚本、样式)的页面来说,这种重复传输造成了巨大的网络带宽浪费和额外的延迟。
总结与影响:
- 核心问题: HTTP/1.1 缺乏头部压缩机制 + 现代网页请求数量激增 + Cookie 体积大且随每个请求重复发送 = 巨大的头部传输开销和性能浪费。
- Cookie 的特殊性: 在众多头部字段中,
Cookie头因其通常体积最大 且必须随每个相关请求发送 的特性,成为了这种浪费的主要贡献者。它是优化 HTTP/1.1 性能时需要重点关注和管理的对象。
解决方案与演进:
-
HTTP/2 的 HPACK 头部压缩: 这是解决此问题的根本性方案。HTTP/2 引入了 HPACK 压缩算法专门用于压缩请求头和响应头。
- 原理: HPACK 使用静态 Huffman 编码压缩文本,并维护动态表记录之前传输过的头部字段(键值对)。后续请求中,重复的头部字段(如
User-Agent,Cookie等)可以用一个非常小的索引号代替,大大减少了需要传输的数据量。 - 效果: 显著降低了头部开销,特别是对于包含大 Cookie 的重复请求。这是 HTTP/2 提升性能的关键机制之一。
- 原理: HPACK 使用静态 Huffman 编码压缩文本,并维护动态表记录之前传输过的头部字段(键值对)。后续请求中,重复的头部字段(如
-
优化 Cookie 使用 (即使在 HTTP/2 下也推荐):
- 最小化 Cookie 大小: 只存储必要信息(如 Session ID),避免存储大量用户数据在 Cookie 中。
- 设置合适的域和作用域: 使用尽可能具体的
Domain和Path属性,避免 Cookie 被发送到不需要它们的子域或路径下的请求中。 - 区分静态资源域名: 为静态资源(图片、CSS、JS)使用无 Cookie 域名 。因为静态资源请求通常不需要 Cookie。将
static.example.com的 Cookie 作用域设置为仅www.example.com(主站),或者更彻底地,使用一个完全独立的、从未设置过 Cookie 的域名(如cdn.example.net)来托管静态资源。这样,对这些资源的请求就完全不会携带 Cookie,极大节省了头部开销(尤其在 HTTP/1.1 下效果显著)。 - 利用
SameSite属性: 控制 Cookie 在跨站请求中是否发送,进一步减少不必要的传输。
是否还需要无 Cookie 域名?
结论:相对 HTTP/1.1 时代,必要性降低,但仍建议减少不必要 Cookie 的传输。
-
"没有绝对必要"的原因:
HPACK 已高效解决了 HTTP/1.1 中重复大 Cookie 的传输浪费问题。即使请求携带 Cookie,其压缩后开销已大幅降低。
-
"仍建议减少不必要 Cookie"的原因:
- 首次请求仍无压缩: HPACK 动态表在连接建立时为空,第一个请求的
Cookie头仍需完整传输。若 Cookie 很大(如 4KB),仍会带来单次开销。 - 动态表资源有限: 过大的 Cookie 会占用宝贵的动态表空间,影响其他头部字段的压缩效率。
- 安全与隐私: 避免向静态资源服务器泄露敏感 Cookie(如会话 ID)。
- 首次请求仍无压缩: HPACK 动态表在连接建立时为空,第一个请求的
为什么没有广泛使用Server Push
1. 传统资源加载流程的问题
"必须通过两轮HTTP通信...请求静态资源的开始时间比较晚"
- 流程拆解:
- 浏览器请求 HTML(如
index.html)。 - 服务器返回 HTML。
- 浏览器解析 HTML,发现需要加载
/index.js。 - 浏览器发起第二次请求获取 JS 文件。
- 浏览器请求 HTML(如
- 性能瓶颈:
- 两轮通信(RTT 翻倍):至少需要两次完整的"请求-响应"循环。
- JS 加载严重延迟:JS 的下载必须等待 HTML 完全下载并解析后才能开始。
- 阻塞渲染:若 JS 是渲染关键资源,页面呈现会被推迟。
2. 优化方案一:link rel="preload">(预加载)
"告知浏览器提前加载资源...节约HTML下载和解析时间"
- 原理:
-
在 HTML 的
<head>中加入:html<link rel="preload" href="/index.js" as="script"> -
浏览器解析到该标签时,立即在后台发起 JS 请求,无需等待 HTML 解析完成。
-
- 优势:
- JS 的下载与 HTML 下载并行进行,缩短整体加载时间。
- 局限:
- 仍需要两次请求(HTML + JS)。
- 预加载指令本身依赖 HTML 的传输,若 HTML 下载慢,预加载仍会延迟。
3. 优化方案二:资源内联(Inline)
"直接把资源内联到页面中...一个请求加载所有资源"
-
原理:
将 JS/CSS 代码直接嵌入 HTML 中:html<script>/* JS代码直接写在这里 */script> <style>/* CSS代码直接写在这里 */style> -
优势:
- 零额外请求:所有资源随 HTML 一次性返回。
- 即时生效:无需等待后续网络请求。
-
致命缺点:
- 缓存失效:内联资源无法被浏览器单独缓存,每次访问页面都需重复下载。
- 代码冗余:多个页面无法共享同一份缓存,浪费带宽。
- 污染主文档:增大 HTML 体积,影响首次加载速度。
4. 优化方案三:HTTP/2 服务器推送(Server Push)
"服务器主动把资源推送给客户端"
- 流程(对应图10-14):
- 浏览器请求 HTML(
index.html)。 - 服务器返回 HTML,同时主动推送 关联资源(如
/index.js)。 - 浏览器解析 HTML 前,JS 已到达缓存。
- 浏览器请求 HTML(
- 优势:
- 单次往返 :HTML 和 JS 在一次通信中完成传输。
- 零延迟加载:JS 无需等待 HTML 解析,直接可用。
- 条件:
- 需启用 HTTP/2 协议。
- 服务器需配置推送逻辑(如识别
Link响应头)。
各方案对比总结
| 方案 | 请求次数 | 缓存复用 | 加载延迟 | 实现复杂度 |
|---|---|---|---|---|
| 传统加载 | 2+ | ✅ | 高 | 无 |
| Preload 预加载 | 2+ | ✅ | 中 | 低(仅加标签) |
| 资源内联 | 1 | ❌ | 低 | 低(但需维护) |
| HTTP/2 服务器推送 | 1 | ✅ | 最低 | 高(需服务端配置) |
1. Server Push 的工作原理
流程(对应图10-15)
- 请求阶段 :
浏览器请求 HTML 文件(如GET /index.html)。 - 服务器主动推送 :
- 服务器在返回 HTML 响应时,同时发送
PUSH_PROMISE帧 ,声明将推送关联资源(如/index.js)。 - 该帧包含推送资源的路径 和关联的流 ID(Stream ID),与 HTML 流绑定。
- 服务器在返回 HTML 响应时,同时发送
- 资源传输 :
服务器将 HTML 和 JS 文件通过同一连接的多路复用流并行传输。 - 客户端处理 :
- 浏览器解析 HTML 时发现需要
/index.js,根据PUSH_PROMISE中的流 ID 直接读取已推送的 JS 流。 - 无需发起新请求,JS 已存在于缓存中。
- 浏览器解析 HTML 时发现需要
✅ 核心价值 :将传统"请求-响应"的串行过程变为单次往返的并行传输,消除资源加载延迟。
2. Server Push 的致命缺陷:缓存冲突
问题描述
"客户端可能已有缓存,即使收到
PUSH_PROMISE也会放弃推送内容"
- 根本矛盾 :
服务器推送时无法感知客户端缓存状态 (如是否已缓存/index.js)。 - 后果 :
- 若客户端已有该资源缓存,推送的 JS 数据会被直接丢弃。
- 浪费服务器带宽与客户端处理资源,加剧网络拥堵。
- 技术限制 :
HTTP/2 协议未提供缓存协商机制,服务器只能盲目推送。
示例场景
- 用户首次访问:
- 无缓存 → 推送有效,加速加载。
- 用户二次访问:
- 已有 JS 缓存 → 服务器仍推送 JS → 客户端丢弃数据 → 带宽浪费 100%。
3. Server Push 的现状:被边缘化的技术
数据佐证
"Chrome 创建的 99.95% 的 HTTP/2 连接从未收到过推送流"
(来源:2019 年 Chrome 团队统计)
- 现实意义 :
绝大多数网站未启用 Server Push,证明其实际价值极低。 - 浏览器态度 :
Chrome 团队曾讨论移除对该功能的支持(注:2022 年 Chrome 106 已正式弃用 Server Push)。
未被广泛采用的原因
- 缓存冲突无解 :
浪费带宽的问题无法根治,违背性能优化初衷。 - 实现复杂度高 :
需服务器精确配置推送规则,维护成本高。 - 收益不稳定 :
对缓存命中率高的用户(如回访用户)可能产生负优化。 - 替代方案成熟 :
preload、prefetch等指令更轻量且可控。
为什么还需要HTTP/3
1. TCP 队头阻塞(Head-of-Line Blocking)
问题本质
"HTTP/2 解决了应用层队头阻塞,但 TCP 层的队头阻塞依然存在"
- HTTP/2 的进步 :
通过多路复用(Multiplexing) ,允许在一个 TCP 连接上并行传输多个 HTTP 请求/响应流(Stream),解决了 HTTP/1.1 中"前一个请求未完成会阻塞后续请求"的问题。 - TCP 层的瓶颈 :
TCP 是基于字节流的可靠传输协议 ,要求数据包严格按顺序交付 。- 假设 Stream 1(JS 文件)和 Stream 2(CSS 文件)在同一个 TCP 连接上传输。
- 若 Stream 1 的某个 TCP 包(Packet 3)丢失或乱序。
- TCP 协议会暂停所有后续数据包的处理,等待 Packet 3 重传成功。
- 此时 Stream 2 的 CSS 数据虽已到达,但因 Packet 3 未到,整个连接被阻塞。
后果
- 单个数据包丢失即可导致所有并行的 HTTP 流被挂起,性能退化到类似 HTTP/1.1。
- 在高丢包网络(如 4G/5G 移动网络)下,多路复用优势被大幅削弱。
2. TCP 握手 + TLS 握手延迟
连接建立成本
- TCP 握手 :
SYN→SYN-ACK→ACK需 1 个 RTT(Round Trip Time)。 - TLS 握手 (以 TLS 1.2 为例):
- 完整握手:
ClientHello→ServerHello→Certificate→ServerKeyExchange→...→Finished需 2 RTT。 - 会话恢复(Session Resumption):通过 Session ID 或 Session Ticket 可降至 1 RTT。
- 完整握手:
- 总延迟 :
- 新连接:TCP(1 RTT)+ TLS(2 RTT)= 3 RTT。
- 恢复连接:TCP(1 RTT)+ TLS(1 RTT)= 2 RTT。
HTTP/2 的优化与局限
- 优化 :通过连接复用(Connection Reuse),一个 TCP 连接处理多个请求,分摊握手成本。
- 局限 :
- 首次访问仍不可避免高延迟。
- 长连接超时断开后需重新握手。
- 移动网络下 RTT 波动大(50ms~500ms),3 RTT 延迟感知明显。
3. 移动网络切换导致连接失效
四元组刚性绑定问题
"TCP 连接由(客户端IP, 客户端端口, 服务端IP, 服务端端口)唯一确定"
- 移动网络场景 :
设备从 Wi-Fi 切到 4G/5G 时,客户端 IP 必然变化 (如192.168.1.100→10.10.1.100)。 - 后果:
- 原 TCP 连接的四元组失效,连接被强制中断 。
- 需重新建立 TCP + TLS 连接(再次经历 2~3 RTT 延迟)。
- 所有正在传输的 HTTP 流被丢弃,用户需重新加载页面。
HTTP/2 的无力
- 应用层协议无法绕过 TCP 的四元组机制,连接迁移(Connection Migration) 在 TCP 上无法实现。
解决方案:HTTP/3 与 QUIC 协议
HTTP/2 的上述问题均源于 TCP 协议的历史包袱 。新一代 HTTP/3 基于 QUIC 协议解决了所有痛点:
| 问题 | HTTP/2 (TCP) | HTTP/3 (QUIC) |
|---|---|---|
| 队头阻塞 | ❌ TCP 层阻塞所有流 | ✅ 基于 UDP,流间隔离,单流丢包不影响其他流 |
| 握手延迟 | 新连接 3 RTT,恢复 2 RTT | ✅ 首次连接 1 RTT ,恢复连接 0 RTT |
| 移动网络切换支持 | ❌ IP 变化导致连接中断 | ✅ 连接标识与 IP 解耦,IP 变化连接保持 |
| 加密强制要求 | TLS 可选 | ✅ 内置 TLS 1.3,加密不可关闭 |
现实影响与建议
- 高丢包网络优先 HTTP/3 :
4G/5G/Wi-Fi 不稳定的场景,HTTP/3 可提升 10%~30% 加载速度。 - 内容分发网络(CDN)支持 :
主流 CDN(Cloudflare、Akamai)已默认支持 HTTP/3,无需业务改造。 - 浏览器支持 :
Chrome、Firefox、Safari 均已默认启用 HTTP/3。
结论:HTTP/2 的 TCP 层缺陷是推动 HTTP/3 诞生的核心动因。在移动互联网时代,QUIC 协议通过 UDP 重构传输层,彻底解决了 TCP 的队头阻塞、握手延迟、连接迁移三大问题。
二、三大核心问题的解决方案
1. 彻底解决队头阻塞(HOL Blocking)
"QUIC 的 Stream 间相互隔离,单流丢包不影响其他流"
- HTTP/2 的缺陷 :
所有 HTTP Stream 共享一个 TCP 连接,一个 TCP 包丢失会阻塞所有 Stream(图 10-17)。 - QUIC 的革新 (图 10-19):
- 在 QUIC 连接内创建独立的逻辑流(Stream),每个 Stream 对应一个 HTTP 请求/响应。
- 每个 Stream 的数据包单独编号、传输、重传。
2. 极速握手:1 RTT 建立安全连接
- HTTP/2 + TLS 1.2 的延迟 :
TCP 握手(1 RTT) + TLS 握手(2 RTT) = 3 RTT。 - QUIC 的优化 (图 10-20):
- 首次连接 :
- 客户端发送
ClientHello(含 TLS 密钥参数 + 应用数据占位)。 - 服务端回复
ServerHello(含 TLS 证书 + 最终密钥)。 - 总耗时:1 RTT(密钥交换与连接建立合并)。
- 客户端发送
- 恢复连接 :
- 通过预共享密钥(PSK)实现 0 RTT 握手,首包即可发送应用数据。
- 首次连接 :
3. 无缝连接迁移(Connection Migration)
"QUIC 使用连接 ID 替代四元组,IP 变化时连接不中断"
- TCP 的痛点 :
连接由(源 IP、源端口、目标 IP、目标端口)四元组唯一绑定,IP 变化(如 Wi-Fi→5G)即断开。 - QUIC 的解决方案 :
- 每个 QUIC 连接分配全局唯一 64 位连接 ID(Connection ID)。
- 网络切换时,客户端在新 IP 上用原 Connection ID 恢复通信。
- 服务端通过 ID 识别连接,无需重新握手,传输无缝延续。
总结
整个HTTP协议的升级迭代过程,其实在很大程度上是为性能服务的。整篇文章很长,知识点很多,慢慢消化,下篇见!