我最近一直在琢磨一个事儿。
咱们现在用AI,不管是GPT、Claude、Gemini还是国内的这些大模型,是不是都有个感觉?聊着聊着,它就"失忆"了。你开头跟它说了一个关键信息,聊了十几轮之后,它就跟没听过一样。
或者你让它干个复杂点的活儿,比如分析一个几十页的PDF,再写个报告。它经常抓不住重点,或者前面分析得挺好,写到后面就把前面的结论给忘了。
我们总以为是自己的Prompt没写好,于是疯狂地调整措辞,加各种"请你记住...""你是一个..."的咒语。
但后来我发现,我们可能都搞错重点了。
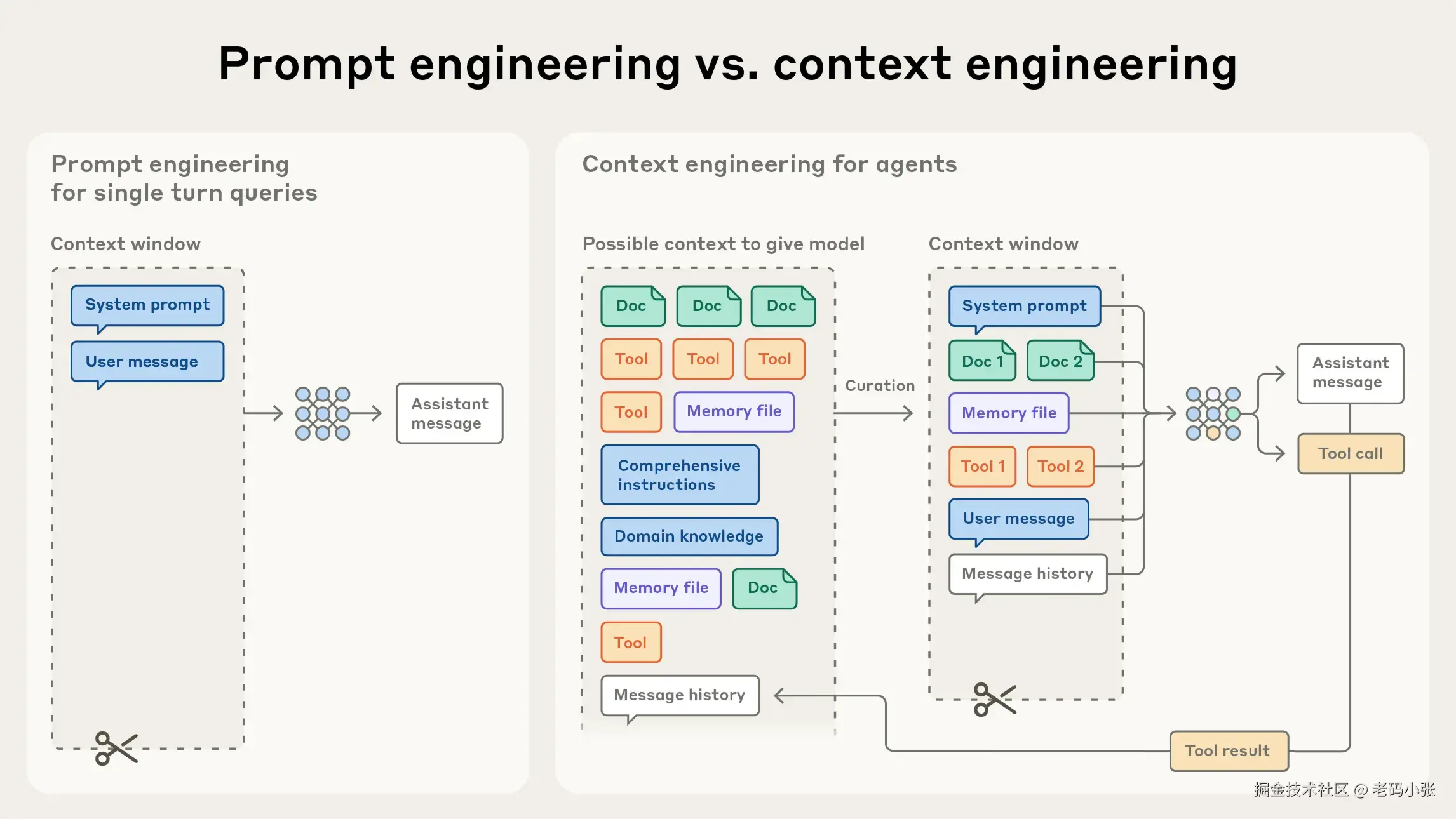
真正让AI变"聪明"或者变"笨"的,可能不是你那句开场白,而是它整个"工作台"是怎么布置的。这个布置工作台的手艺,现在有个新叫法,叫上下文工程(context engineering)。
这玩意儿到底是个啥?
说白了,AI的"脑子"不是无限的。它有个叫"上下文窗口"的东西,你可以理解成它的"短期工作记忆"。
你跟它说的所有话,你扔给它的所有文件,它自己生成的所有思考,全塞在这个工作记忆里。这个记忆空间是有限的,而且特别珍贵。
这就好比你让一个实习生干活。你不能只给他一句口头指令,就指望他完美搞定一整个项目。你得给他一个清晰的项目背景(系统提示),给他顺手的工具(比如数据库权限、查询工具),再给他几个做得好的范例(few-shot),还得把相关的资料放在他手边(上下文)。
所有这些东西,共同构成了AI的"工作状态"。
上下文工程,就是怎么用最少的"内存",给AI布置一个最高效、最清晰的工作台。
为什么以前的"提示工程"不够了?
以前的AI应用,大多是一次性的。你问一个问题,它答一个答案。这就像给实习生一个单子,让他去楼下买杯咖啡。简单。
但现在不一样了,我们想要的是"AI代理",是能自己干活、自己思考、自己用工具的"智能员工"。它得能连续工作好几个小时,处理一个复杂任务。
这时候,问题就来了。它干得越久,产生的"思考垃圾"就越多,工作台就越乱。就像那个实习生,接了电话、回了邮件、查了资料......桌子上的文件堆得像山一样,最后连自己最初要干嘛都忘了。
这就是所谓的"上下文衰减"。信息越多,核心信息反而越模糊。
那怎么给AI收拾这个"烂摊子"?
我看了Anthropic那帮人写的一些东西,发现有几个思路特别有意思,特别"接地气"。
1. 别把工具箱整个扔给它
我们总怕AI功能不够,恨不得给它一百个工具。结果呢?它自己都懵了,不知道该用哪个。
一个原则是:工具要少而精,功能别重叠。就像你修电脑,一把螺丝刀、一个镊子、一个吸尘器就够了。你没必要把整个五金店都搬来。给AI的工具也是一样,每个工具都得有明确的用途,别让它在"用A还是用B"这种问题上纠结半天。
2. 别当"话痨",当"教练"
写系统提示(就是那个"你是一个...")的时候,别写成一本书。
我发现两个极端:一种是写得太细,把所有情况都写成if-else规则,搞得跟写代码一样,特别脆弱,稍微有点新情况就翻车。另一种是写得太虚,"请你成为一个优秀的助手",说了等于没说。
好的提示,得像个好教练。给出清晰的原则和边界,但保留一定的灵活性。告诉它"我们要去哪",而不是"你先抬左腿,再抬右腿"。
3. 让AI自己"找资料",而不是你"喂资料"
这个思路我觉得最牛逼。
以前我们总想着,把所有可能用到的资料,用各种技术(比如向量检索)先塞给AI。这就像怕孩子找不到书,把整个图书馆都搬到他桌上。
但更聪明的做法是:你只告诉它资料在哪,让它自己按需去查 。你在调用 Claude Code 的时候,实际上就是这么玩的,你会发现一堆的 grep 命令调用,这就是模型在获取他所需要的上下文。
比如,你想让它分析一个巨大的数据库。你不用把数据全扔给它。你只需要给它一个数据库的连接工具,告诉它怎么写查询语句。它会自己写SQL,把结果拿回来分析。分析完需要别的数据,它再去查。
这就像我们人一样,我们不会记住整本书,但我们会用目录、会用搜索引擎。AI也能学会这个。这叫"即时上下文",按需加载,内存占用小,效率还高。
那任务真的要跑好几天怎么办?
就算内存再大,也架不住AI连续工作几十个小时啊。工作台迟早要满。
这时候,就得用上一些"续命"技巧了。
- 写"会议纪要":当上下文快满了,就让AI自己把之前的对话内容、关键发现、未解决的问题,总结成一份精简的"纪要"。然后清空工作台,只带着这份纪要继续干。这叫"压缩"。
- 给AI一个"小本本":让AI在干活的过程中,随时把重要的东西记到一个外部文件里,比如NOTES.md。比如它发现了一个重要的bug,或者想到了一个绝妙的点子,就记下来。等它需要的时候,可以随时翻看这个小本本。这叫"结构化笔记"。
- 搞"团队协作":一个AI干不过来?那就招"专家"。一个主AI负责总体规划和协调,遇到具体问题,就召唤一个"子AI"去专门解决。比如需要分析代码,就召唤一个"代码专家AI";需要查资料,就召唤一个"资料员AI"。这些子AI干完活,只把最核心的结论汇报给主AI。这叫"子代理架构"。
写在最后,但不是总结
说实话,我一边研究这些"上下文工程"的技巧,一边又有点怀疑。
我们是不是在用人类的思维,去硬套一个完全不同的智能体,这个过程真的是太像了?我们觉得"工作记忆"有限,需要"做笔记",需要"团队协作",但AI的未来,会不会是一种我们完全无法理解的形态?
也许再过一两年,模型本身变得足够强大,它自己就能完美地管理自己的"上下文",根本不需要我们这些"奇技淫巧"。
到那时候,我们今天讨论的这些,会不会就像在汽车发明之初,讨论怎么给马匹钉掌更科学一样可笑?
谁知道呢。
但至少现在,玩转"上下文",感觉就像是拿到了一把能解锁AI更多潜力的钥匙。虽然这把钥匙可能很快就会过时,但在它失效之前,足够我们玩出很多牛逼的花样了。
你觉得呢?