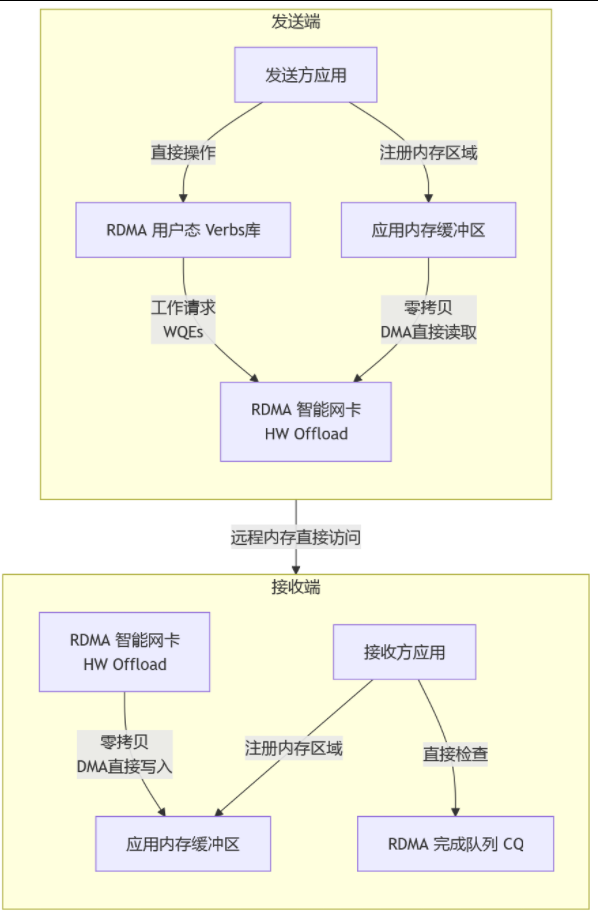
RDMA,全称远程直接内存访问 。顾名思义,它是一种能够让计算机直接访问 另一台计算机内存的技术,而无需经过对方操作系统的内核、无需占用对方CPU的任何资源。
您可以把它理解成网络世界里的"超级快递员"。
传统网络通信(如TCP/IP):繁琐的"官僚体系"
想象一下传统的数据传输流程(以TCP/IP为例):
- 发送方:你的应用程序(用户空间)产生数据 -> 数据被复制到操作系统内核的缓冲区 -> 内核协议栈对数据进行层层打包(TCP/IP头等) -> 数据再被复制到网卡缓冲区 -> 网卡发送。
- 接收方:网卡收到数据 -> 数据复制到内核缓冲区 -> 内核协议栈对数据进行层层解包 -> 数据再被复制到应用程序的缓冲区(用户空间)。
这个过程的痛点:
- 多次数据拷贝:数据在"用户空间"和"内核空间"之间来回搬运,消耗大量的CPU周期和内存带宽。
- 高CPU占用:数据处理(协议栈封包/解包)和拷贝工作都由CPU完成,导致CPU忙于处理网络事务,而非核心业务计算。
- 高延迟:每一步的拷贝和处理都需要时间,导致端到端的延迟很高。
RDMA通信:高效的"点对点直送"
现在,再看RDMA的工作方式:
- 发送方:你的应用程序直接告诉网卡:"把这块内存里的数据,直接送到对方某某应用程序的某某内存地址去"。
- 接收方 :网卡收到数据后,利用RDMA技术,绕过内核和CPU,直接就把数据写入到目标应用程序的指定内存地址中。
整个过程:
- 零拷贝:数据从应用内存直接到网卡,再到对方应用内存,没有中间商赚差价。
- 内核旁路:应用程序直接与智能网卡对话,内核"不知情"也不参与。
- 远程内存直接访问:发送方能够像操作本地内存一样,直接读写远端内存。
- 硬件卸载:所有的通信协议(如RDMA专属的协议)都在专门的硬件(RNIC网卡)上完成,CPU被彻底解放。
核心关键技术详解
您总结的四个关键技术点非常到位,我们来逐一深化:
-
零拷贝
- 本质:消除数据在用户态和内核态之间的冗余复制。
- 价值:极大降低了传输延迟,并释放了内存总线带宽,让CPU和内存能专注于更重要的计算任务。
-
内核旁路
- 本质:应用程序通过特定的用户态驱动库(如Verbs API)直接操作RDMA网卡,进行数据的发送和接收。
- 价值 :
- 免系统调用:避免了陷入内核的系统调用开销。
- 免上下文切换:减少了CPU在用户态和内核态之间切换的成本。
- 确定性:使得网络通信的延迟更低、更稳定、可预测。
-
硬件卸载
- 本质:将复杂的网络协议栈(传输层、网络层甚至部分应用层功能)固化到RDMA网卡芯片中,由网卡上的专用处理器来执行。
- 价值:这是解放CPU的关键。CPU只需下发指令,然后就可以去干别的事了,具体的打包、校验、重传等脏活累活都由网卡完成。这被称为"CPU卸载"。
-
远程内存直接访问
- 本质:这是RDMA的终极目标。它允许本机应用通过网络直接读写远端节点的用户态内存。
- 价值 :
- 节约远端CPU:写入数据时,完全不需要打扰远端节点的CPU,远端应用可以毫不知情地发现数据已经到位。
- 真正的低延迟高吞吐:结合前三点,实现了近乎本机内存访问性能的远程通信。
RDMA vs. DPK:谁更彻底?
DPDK也是一种高性能网络数据包处理技术,它也实现了零拷贝 和内核旁路。
那么,RDMA的"更彻底"体现在哪里?
答案就在于硬件卸载 和远端CPU无感知。
| 特性 | DPK | RDMA |
|---|---|---|
| 零拷贝 | ✔️ (用户态与网卡间) | ✔️ (端到端应用内存间) |
| 内核旁路 | ✔️ | ✔️ |
| 协议栈处理 | 由CPU在用户态软件完成 | 由RNIC网卡硬件完成 |
| 远端CPU参与 | 需要 (远端DPDK应用需调用API收包) | 不需要 (数据直接入目标内存) |
简单来说:
- DPDK 是把网络协议栈从内核"挪"到了用户态,用CPU来跑一个高效的软件协议栈。它解决了内核开销,但CPU依然在忙于处理网络数据包。
- RDMA 是直接把网络协议栈"扔"给了硬件网卡。CPU只做指挥,不干搬运和打包的活,而且连远方的CPU也一并解放了。
所以,RDMA在"解放CPU"和"降低延迟"这条路上,走得比DPDK更远、更彻底。
主要应用场景
RDMA的高性能特性,使其在对延迟和带宽极度敏感的领域大放异彩:
- 高性能计算:超级计算机中成千上万个节点之间的高速通信,是RDMA的传统主场。
- 分布式存储 :
- 超融合基础设施:如vSAN,节点间通过RDMA同步数据。
- 分布式文件系统:如Lustre, Ceph,通过RDMA实现极高的IOPS和低延迟。
- 存储网络:NVMe-oF技术让远程SSD磁盘像本地一样访问,其底层最佳传输方式就是RDMA。
- 人工智能/机器学习:大规模GPU集群在训练模型时,需要高速交换海量梯度数据,RDMA是保证训练效率的关键。
- 云原生和数据中心:现代云数据中心(如微软Azure、谷歌云、阿里云)的底层网络大量采用RDMA,为上层虚拟机、容器提供高性能的网络服务。
总结
RDMA不仅仅是一项网络技术,它更是一种计算机体系结构的范式变革。 它打破了传统网络通信中"数据必须经过内核和CPU"的桎梏,通过零拷贝、内核旁路、硬件卸载 和远程内存直接访问这四大关键技术,实现了超低延迟、高吞吐量和极低CPU占用的远程数据通信,从而成为了支撑现代高性能计算、AI和分布式存储系统的核心网络基石。