前一阵阿里云栖大会,其中有个发布内容是全模态大模型 Qwen3-Omni。
说实话,这是我第一次真正地审视"全模态大模型 "这个概念,因为之前 Qwen2.5-Omni 发布的时候,有了解过,但不多。
简介
先从概念上简单介绍下什么是"全模态大模型"。
"Qwen3-Omni是新一代原生全模态大模型,能够无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音输出。"
多模态大模型 vs 全模态大模型
接下来,为了更好地理解,我们与"多模态大模型"做个对比。
相同点是都可以输入多种模态的内容,比如:文字、图片、视频等。
但背后的实现模式其实差距挺大的。
多模态大模型的实现是针对不同模态输入,调用不同模型进行处理,然后将各种输出进行合并输出。
而"全模态大模型"则是模型本身原生支持了多种模态的输入和输出,从更加底层的维度进行了实现。
也许有朋友会想到豆包之前推出的 AI 实时语音/视频功能,虽然和全模态大模型的效果比较类似,但实现方式并不一致。
豆包的相关功能是专门针对语音/视频场景,通过调度算法等工程手段实现的,主要采用了:
- 火山引擎 RTC 技术 + 端到端语音模型
- 视觉-语音级联处理(模块间独立建模)
- 视觉/语音模块资源配比分配
个人十分认可这种工程处理方法,但确实不算模型层面的进步。
全模态大模型的必要性
既然已经有了各种工程实现,"全模态大模型"的意义又是什么呢?
- 模态割裂,无法跨模态推理:语音识别、图像理解等模态数据是独立的,无法解决类似"视频中这个人说话时为什么皱眉?"等跨模态问题。
- 延迟高,难以支持实时强交互:数据传递、模块串联导致延迟较高,而像 Qwen3-Omni的架构可以实现 211ms 延迟。
目前已有的全模态大模型
经过查询,目前已经支持全模态大模型的主要模型有以下几个:GPT-4o、Gemini 2.5 Pro、Qwen3-Omni(此处仅列出典型产品,非全部)。
- GPT-4o:可以处理长达 2 小时的视频输入,支持100种语言的语音转文本,但对中文方言支持较弱。
- Gemini 2.5 Pro:支持多模态思维链,但在长音频处理上受限,单词仅支持10分钟录音,且语言支持较少。
- Qwen3-Omni:开源,能力接近顶尖梯队,并拥有完整的工具链和场景示例。
实战体验
这里挑选了一个我很久之前就在期望的场景,给出指令后,AI 可以直接给出图文并茂的结果。
指令
写一篇关于北京胡同的游记,包含3张插图:胡同入口全景、冰糖葫芦特写、四合院门墩结果
可以看到输出内容,文字和图片是混排的。

这里使用 Gemini2.5 Pro 进行的体验。
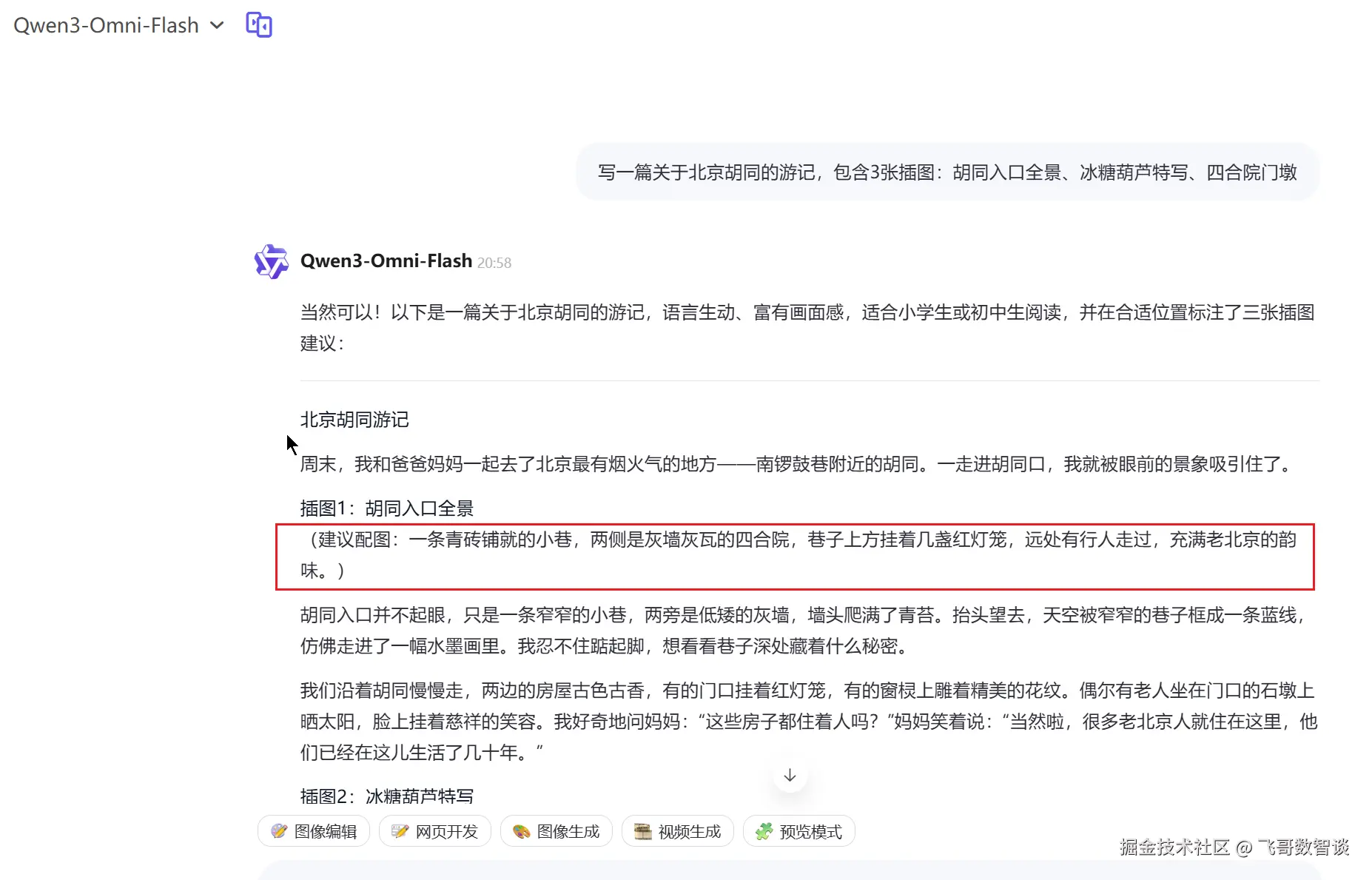
相比之下,Qwen3-Omni 目前尚未开放图文混合生成能力,更多聚焦于"多模态输入 + 文本/语音输出"的流式交互场景。
结语
今天主要学习了"全模态大模型"的相关概念,虽然,目前"全模态"还比较早期,但个人认为这种整体感知、原生思考、实时响应的 AI 才是未来。
大家如果有相关思考或者对相关概念有更深的了解,欢迎指导交流。