1. 一句话区分
ArrayList 本质是"可变长数组",LinkedList 本质是"双向链表"。其余差异都由这一点展开。
2. 结构差异
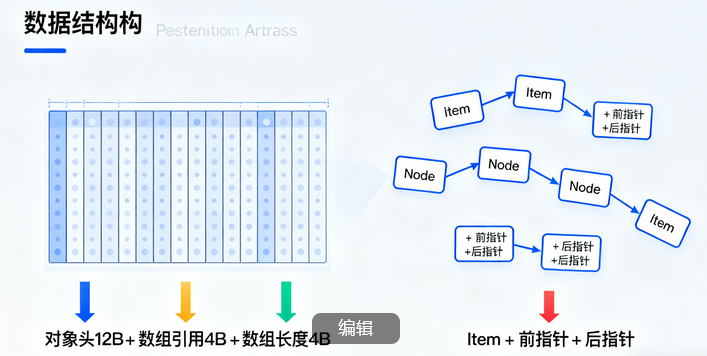
2.1 内存排布
-
ArrayList:一整块连续数组,元素紧挨在一起
-
LinkedList:散落各处的 Node,每个 Node 存 item + 前指针 + 后指针
2.2 空间开销(64 位压缩指针)
-
ArrayList:对象头 12 B + 数组引用 4 B + 数组长度 4 B,元素本身紧排
-
LinkedList:每个 Node 额外 2 个引用(8 B×2),100 万元素 ≈ 多 24 MB
3. 时间复杂度
| 操作 | ArrayList | LinkedList |
|---|---|---|
| 随机访问 get(i) | O(1) | O(n) |
| 尾部插入/删除 | O(1) 均摊 | O(1) |
| 头部插入/删除 | O(n) 搬移 | O(1) |
| 任意位置插入/删除 | O(n) 搬移 | O(n) 定位+改指针 |
注意:LinkedList 的"插入"本身虽快,但定位到位置仍需遍历,所以中间插入仍是 O(n)。
4. 缓存友好性
连续内存 vs 离散节点。现代 CPU 按 cache line(64 B)读取数据,ArrayList 一次可带 4-8 个元素;LinkedList 每跳一次都可能 cache miss,随机访问差距可达数十倍。
5. 使用场景
-
读多写少、顺序遍历、随机访问 → ArrayList(大多数业务接口、数据库结果集)
-
需要频繁头插/头删,当作栈/双端队列 → LinkedList
-
中间插入删除极多,且定位代价可忽略(已在迭代器位置)→ LinkedList
-
内存敏感、移动端、GC 压力大的环境 → 优先 ArrayList
-
高并发场景 → 两者皆线程不安全,考虑 CopyOnWriteArrayList、ConcurrentLinkedQueue 等并发容器
6. 代码示例
// 1. 普通查询列表
List<User> users = new ArrayList<>(dao.findAll());
// 2. 当做栈,频繁 push/pop
Deque<Integer> stack = new LinkedList<>();
stack.push(1);
int x = stack.pop();7. 常见误区
-
用 for-i 循环 LinkedList ------ 每次 get(i) 都从头部数,性能爆炸
-
认为 LinkedList 插入永远快 ------ 忘了定位也是 O(n)
-
忽视内存开销 ------ 链表在百万级数据下额外占用明显
8. 小结
-
默认选 ArrayList,简单且快
-
明确需要两头频繁增删再考虑 LinkedList
-
真正高并发或超大规模数据,请用专门的并发/队列实现