关注我的公众号:【编程朝花夕拾】,可获取首发内容。

01 引言
在MyBatis项目开发中,你是否遇到过查询突然变慢、内存占用飙升的困扰?这很可能是selectByExampleWithBLOBs使用不当导致的性能陷阱。
本文将为你揭秘这个看似简单却暗藏玄机的方法,从使用场景到性能优化,助你掌握BLOB字段查询的精髓,避免常见坑点。
02 缘起
这两天遇到一个线上BUG,就是因为selectByExampleWithBLOBs问题导致的。如图所示:
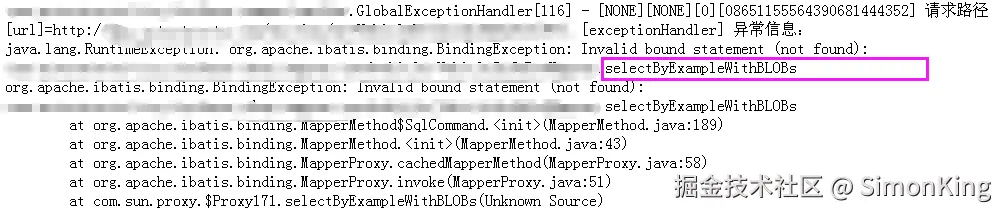
从报错的日志信息来看,是因为selectByExampleWithBLOBs没有绑定Mapper.xml文件。
问题很快就排查了,因为新加了字段需要使用逆向工程(MBG)重新生成实体。而生成的实体的时候,开发者对Text类型的字段直接指定了类型,导致BLOB字段丢失,Mapper.xml也不会有xxxxWithBLOBs的方法,导致问题产生。
默认的映射是将Text字段单独拿出来,使用xxxWithBLOBs单独接收,对应的xml也会生成类似selectByExampleWithBLOBs的方法,如图:
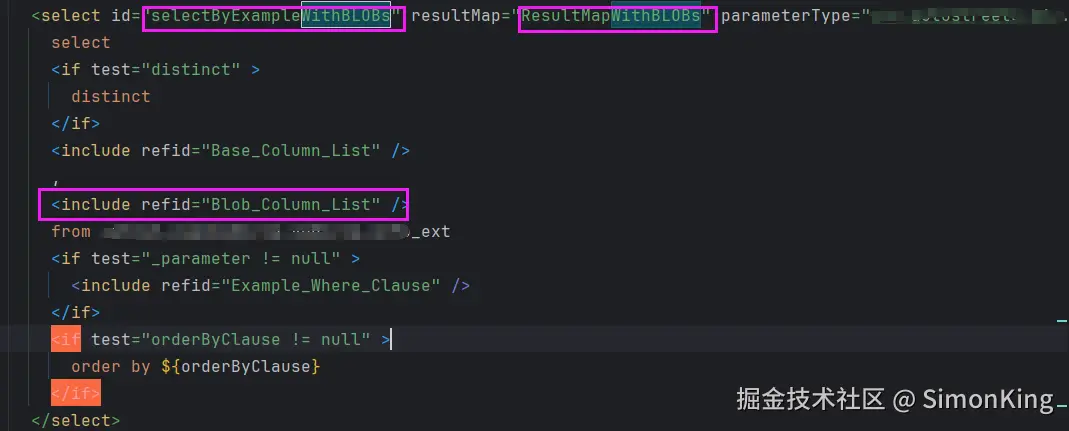
接下我们将一起探索xxxWithBlobs的用法。
03 概述
selectByExampleWithBLOBs是MyBatis Generator(MBG)自动生成代码时针对包含BLOB(Binary Large Object)字段的表的查询方法。它允许通过Example条件对象进行查询,同时包含对BLOB字段的检索。
当数据库表中包含BLOB、CLOB、TEXT等大字段类型时,MBG会生成两个查询方法:
selectByExample:查询时不包含BLOB字段selectByExampleWithBLOBs:查询时包含BLOB字段
04 代码示例
4.1 数据库表结构
sql
CREATE TABLE `article` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(200) NOT NULL,
`author` varchar(100) DEFAULT NULL,
`content` longtext, -- BLOB类型字段
`summary` text, -- BLOB类型字段
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.2 自动生成实体以及配置
MyBatis Generator自动生成代码工具这里就详细说明了,直接使用工具生成。
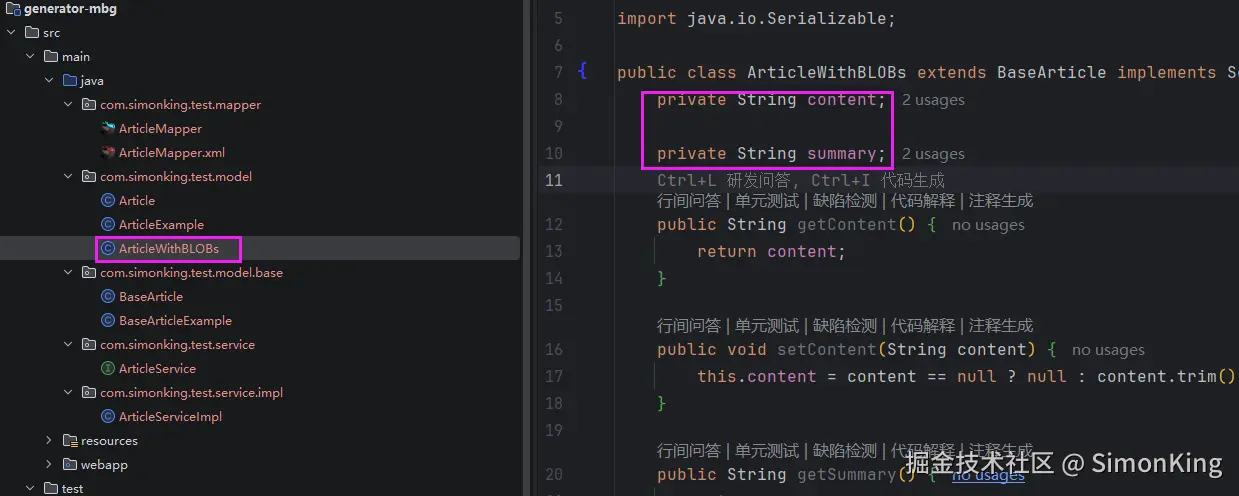
我们可以看到ArticleWithBLOBs继承BaseArticle数据库实体类,content和summary已经单独处理了。
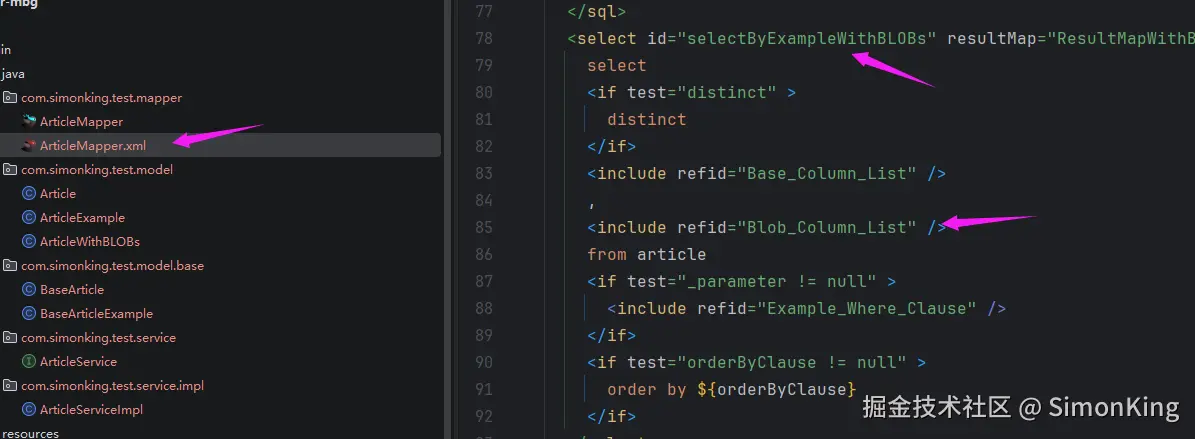
xml配置文件也有类似的方法:
4.3 使用
xxxWithBLOBs的使用很简单,就和selectByExample几乎一样。
java
// 创建Example对象
ArticleExample example = new ArticleExample();
ArticleExample.Criteria criteria = example.createCriteria();
// 设置查询条件
criteria.andAuthorEqualTo("张三")
.andCreateTimeGreaterThan(DateUtils.addDays(new Date(), -7));
// 排序
example.setOrderByClause("create_time DESC");
// 1. 普通查询(不获取content字段)
List<Article> articles1 = articleMapper.selectByExample(example);
// 2. 包含BLOB字段的查询
List<ArticleWithBLOBs> articles2 = articleMapper.selectByExampleWithBLOBs(example);
// 此时articles2中的每个Article对象都包含content字段的数据selectByExample和selectByExampleWithBLOBs的返回值不一样哦。
05 注意事项
5.1 性能问题
MBG为什么要把Text类型的字段单独处理呢?会有什么性能问题么?
Text字段通常存储大量数据,如文章内容、协议内容等,大数据量传递会消耗带宽以及IO等,从而影响性能。
所以,查询时不需要Text类型的字段时,尽量不要查询。遵循需要什么查什么的最少资源的模式,可以提高接口性能。
java
// 不推荐:不必要的BLOB查询
ArticleExample example = new ArticleExample();
example.createCriteria().andStatusEqualTo(1);
// 如果只需要统计数量或非BLOB字段,应使用普通查询
List<Article> articles = articleMapper.selectByExample(example); // 更好
// 需要BLOB数据时才使用WithBLOBs
List<ArticleWithBLOBs> articlesWithBlobs = articleMapper.selectByExampleWithBLOBs(example);5.2 字段排除与包含
MBG配置中可以控制BLOB字段的生成策略:
xml
<table tableName="article" domainObjectName="Article">
<property name="useActualColumnNames" value="false" />
<property name="domainPackage" value="base" />
<columnRenamingRule searchString="is_" replaceString="" />
<!-- 默认映射 -->
<columnOverride column="content" javaType="String" jdbcType="LONGVARCHAR"/>
</table>columnOverride用来指定生成的字段类型,上述代码为默认映射,可以通过指定jdbcType或者javaType来干涉生成的字段。
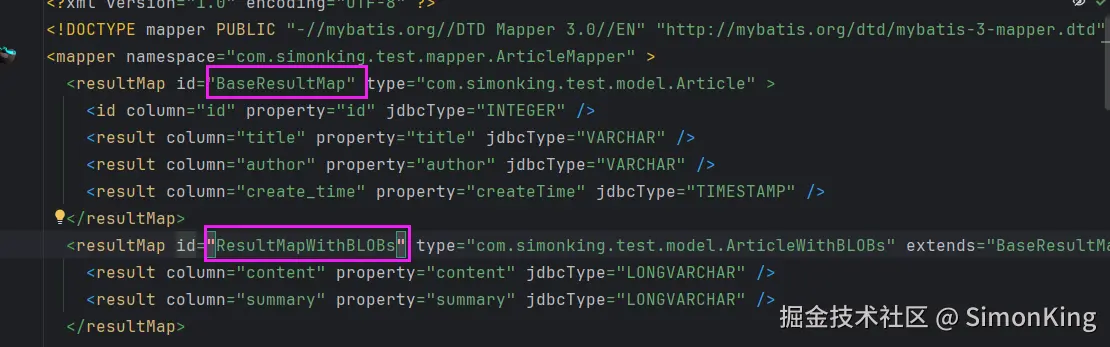
5.3 ResultMap差异
MBG会生成两个ResultMap:
BaseResultMap:不包含BLOB字段ResultMapWithBLOBs:包含BLOB字段
5.4 Mapper兼容
selectByExampleWithBLOBs为MGB默认方法,生成的xxxMapper可能会不包此方法,这个和MGB这个工具有关系。我的工具里面就没有。

需要手动处理。
06 小结
小编觉得selectByExampleWithBLOBs应该做到非必要不使用,减少资源的消耗。如果存储的数据没有非常大的时候,应该避免使用text等大数据类型的。合理使用才是性能优化的关键,让大数据字段不再成为系统负担。