点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月29日更新到: Java-136 深入浅出 MySQL Spring Boot @Transactional 使用指南:事务传播、隔离级别与异常回滚策略 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Flink DataStream Transformation
- FlatMap Window Aggregations Reduce 等等等函数

Sink
Flink 的 Sink 是指数据流处理过程中最终输出数据的组件。在 Apache Flink 中,数据流从 Source 读取后经过一系列的转换操作(如 map、filter、join 等),最后会被写入到 Sink 中。Sink 是 Flink 流式处理应用的终点,决定了处理后的数据如何保存或传输。
Sink 的主要功能与特点
- 数据输出:Sink 负责将处理后的数据输出到外部系统或存储介质
- 容错性:配合 Flink 的检查点机制,确保数据不丢失
- 可扩展性:支持并行写入,提高吞吐量
常见 Sink 类型
-
文件系统 Sink:
- 写入 HDFS/S3 等分布式文件系统
- 例如:StreamingFileSink
- 支持按时间、大小滚动文件
-
消息队列 Sink:
- 写入 Kafka/RabbitMQ 等消息系统
- 例如:FlinkKafkaProducer
- 提供 exactly-once 语义保证
-
数据库 Sink:
- 写入关系型数据库(MySQL/PostgreSQL)
- 写入 NoSQL 数据库(HBase/Cassandra)
- 通常通过 JDBC 或专用连接器实现
-
自定义 Sink:
- 实现 SinkFunction 接口
- 可集成任意外部系统
典型应用场景
-
实时计算结果存储:
- 将聚合结果写入 OLAP 数据库
- 例如:写入 ClickHouse 供 BI 分析
-
数据管道:
- 将处理后的数据转发给下游系统
- 例如:ETL 处理后写入数据仓库
-
告警系统:
- 将异常检测结果写入通知系统
- 例如:发送告警邮件或短信
配置示例
java
// Kafka Sink 示例
DataStream<String> stream = ...;
stream.addSink(new FlinkKafkaProducer<>(
"broker-list",
"topic-name",
new SimpleStringSchema()
));
// 文件系统 Sink 示例
StreamingFileSink<String> fileSink = StreamingFileSink
.forRowFormat(new Path("/output"), new SimpleStringEncoder<String>("UTF-8"))
.build();
stream.addSink(fileSink);在实际应用中,选择哪种 Sink 需要根据数据量、延迟要求、一致性需求等因素综合考虑。Flink 提供了丰富的内置 Sink 实现,同时也支持开发自定义 Sink 来满足特定业务需求。
基本概念
Flink 的 Sink 是用来将流处理的数据写入外部存储系统的,比如数据库、文件系统、消息队列等。Sink 接口提供了一种灵活的方式来定义数据的输出格式和存储目标。Flink 提供了多个内置的 Sink 连接器,用户也可以根据需求自定义 Sink。
常见类型
Flink 提供了多种内置的 Sink,可以将数据输出到多种不同的系统中。以下是一些常见的 Flink Sink:
- File Sink:将数据输出到文件系统,支持多种文件格式,如文本文件、CSV、Parquet 等。
- Kafka Sink:将数据输出到 Kafka 主题,用于构建流式数据管道。
- Elasticsearch Sink:将数据写入 Elasticsearch 索引,适用于实时数据搜索和分析。
- JDBC Sink:将数据写入关系型数据库,如 MySQL、PostgreSQL 等。
- HDFS Sink:将数据存储在 Hadoop 分布式文件系统中,适用于大规模数据的长期存储。
- Cassandra Sink:将数据写入 Cassandra 数据库,适用于大规模的 NoSQL 数据存储
配置与使用
要在 Flink 应用中使用 Sink,需要通过 DataStream 的 addSink 方法来配置和添加 Sink。例如,将数据写入 Kafka 的简单配置如下:
java
DataStream<String> dataStream = // 数据处理逻辑
dataStream.addSink(new FlinkKafkaProducer<>(
"localhost:9092", // Kafka broker 地址
"output-topic", // 输出的 Kafka 主题
new SimpleStringSchema() // 数据序列化格式
));同样,配置 JDBC Sink 的方式如下:
java
dataStream.addSink(JdbcSink.sink(
"INSERT INTO my_table (column1, column2) VALUES (?, ?)",
(statement, value) -> {
statement.setString(1, value.f0);
statement.setInt(2, value.f1);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/mydb")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("user")
.withPassword("password")
.build()
));自定义 Sink
除了使用内置的 Sink,Flink 还允许开发者实现自定义 Sink。通过实现 SinkFunction 接口或扩展 RichSinkFunction 类,开发者可以定义自己所需的 Sink。自定义 Sink 通常用于需要特殊处理或集成尚不支持的外部系统。
例如,自定义一个简单的控制台打印 Sink:
java
public class PrintSinkFunction<T> extends RichSinkFunction<T> {
@Override
public void invoke(T value, Context context) {
System.out.println(value);
}
}Sink 的容错机制
Flink 为数据输出提供了两种主要的容错语义级别,以满足不同业务场景的需求:
1. 容错语义级别
精确一次 (Exactly-Once):
- 确保每条数据只会被处理一次,即使发生故障也不会丢失或重复
- 实现方式:需要 Sink 支持事务性写入,并与 Flink 的检查点机制协同工作
- 典型应用:Kafka Sink 通过事务 ID 和两阶段提交协议实现
- 配置示例:
kafka.producer.transactional.id需要设置为唯一值
至少一次 (At-Least-Once):
- 确保数据至少会被处理一次,但在故障恢复时可能出现重复
- 实现方式:简单重试机制,不保证幂等性
- 典型应用:某些文件系统 Sink(如 HDFS Sink)使用重命名临时文件的方式实现
2. 实现机制
Checkpointing:
- 核心机制:定期保存分布式快照,包括算子状态和待处理数据
- 配置参数:
execution.checkpointing.interval:检查点间隔(默认10分钟)execution.checkpointing.mode:EXACTLY_ONCE/AT_LEAST_ONCE
- 恢复过程:从最近的完整检查点重启,重放后续数据
Sink 端实现:
-
事务性 Sink:
- 在检查点完成时提交事务
- 支持两阶段提交协议(2PC)
- 示例:Kafka、JDBC 等支持事务的数据存储
-
非事务性 Sink:
- 使用幂等写入或去重表
- 示例:文件系统的追加写入模式
3. 典型 Sink 实现对比
| Sink 类型 | 容错语义 | 实现方式 | 适用场景 |
|---|---|---|---|
| Kafka Sink | Exactly-Once | 事务性写入+两阶段提交 | 实时消息队列 |
| File Sink | At-Least-Once | 检查点完成后提交文件 | 批处理输出 |
| JDBC Sink | Exactly-Once | 数据库事务+XA协议 | 关系型数据库写入 |
| Elasticsearch | At-Least-Once | 基于版本号的幂等写入 | 搜索引擎数据同步 |
4. 最佳实践
- 根据下游系统的特性选择合适的容错语义
- 对于精确一次语义,确保目标系统支持事务或幂等操作
- 合理设置检查点间隔(通常在1-10分钟之间)
- 监控检查点持续时间,避免影响吞吐量
- 对于关键业务,建议实现端到端的一致性验证机制
通过合理配置,Flink Sink 可以在保证数据可靠性的同时,满足不同业务场景对数据一致性的要求。
Sink 的并行度
Flink 的 Sink 通常是并行的,默认情况下与上游操作的并行度一致。用户可以通过 setParallelism 方法来手动调整 Sink 的并行度。注意,对于一些 Sink,如文件系统 Sink,并行度越高,生成的文件数也越多。
生命周期
Flink 的 Sink 在执行时会经历以下几个阶段:
- 打开 (open):初始化资源,如数据库连接、文件句柄等。
- 写入 (invoke):将每一条数据写入目标存储系统。
- 关闭 (close):关闭资源,确保数据完整写入和资源的正确释放。
简单示例
以下是一个将处理后的数据流写入文本文件的完整示例:
java
DataStream<String> dataStream = // 数据处理逻辑
StreamingFileSink<String> sink = StreamingFileSink
.forRowFormat(new Path("/output/path"), new SimpleStringEncoder<String>("UTF-8"))
.build();
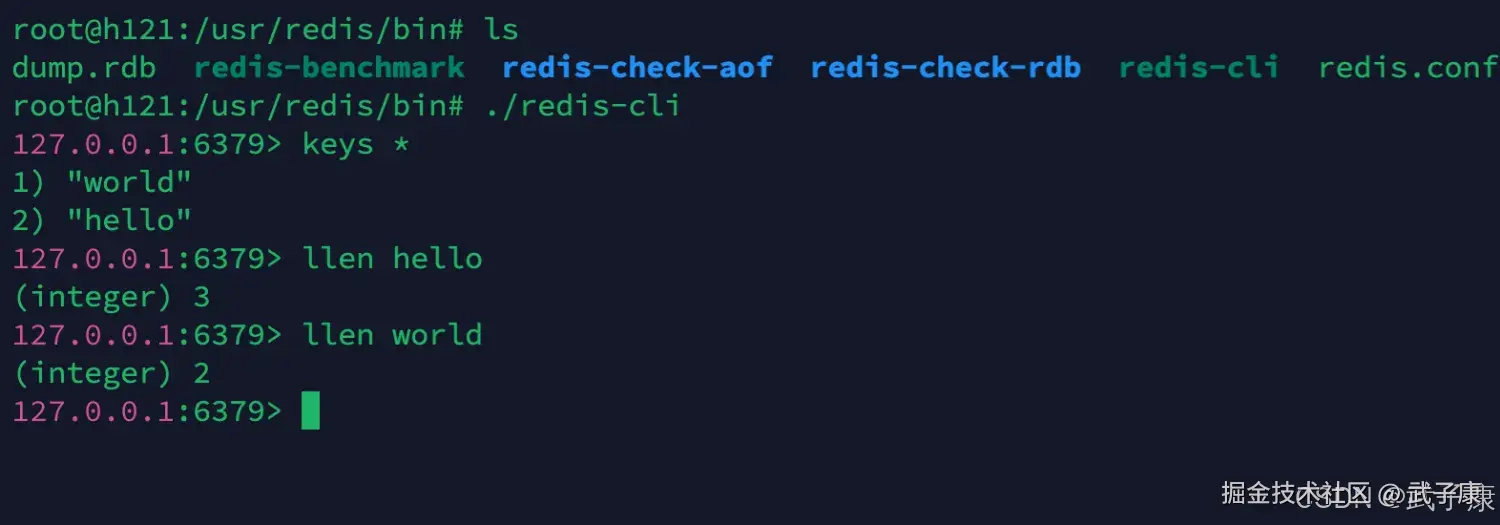
dataStream.addSink(sink);案例1:数据写入Redis
添加依赖
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.5</version>
</dependency>编写代码
消费Kafka 计算之后 写入到 Redis中。 Source(Kafka) -> Sink(Redis)
java
package icu.wzk;
public class StreamFromKafka {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置信息
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "h121.wzk.icu:9092");
// Kafka
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"flink_test",
new SimpleStringSchema(),
properties
);
DataStreamSource<String> data = env.getJavaEnv().addSource(consumer);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = data
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word: words) {
out.collect(new Tuple2<>(word, 1));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> result = wordAndOne
.keyBy(new KeySelector<Tuple2<String, Integer>, Object>() {
@Override
public Object getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
})
.sum(1);
result.print();
env.execute("StreamFromKafka");
}
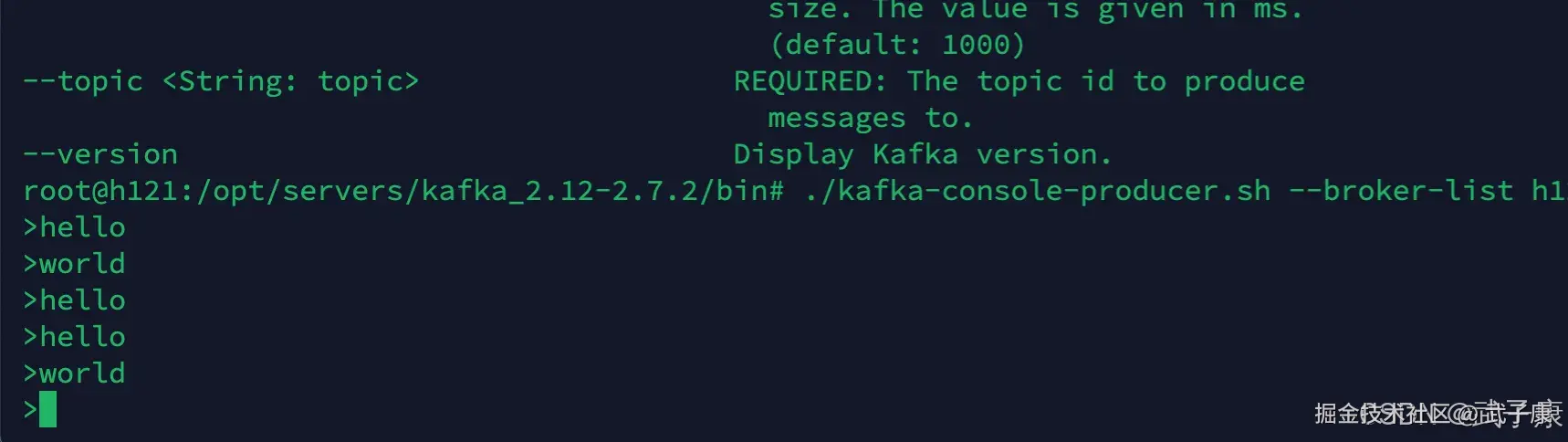
}启动Kafka
启动Redis
运行代码
写入数据
查看结果