💖💖作者:计算机编程小央姐
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持! 💜💜
💕💕文末获取源码
目录
车之家数据分析系统,Hadoop分布式存储+Spark计算引擎-系统功能介绍
基于大数据的汽车之家数据分析系统是一套专门针对二手车市场数据进行深度挖掘和智能分析的综合性平台,该系统采用Hadoop分布式文件系统作为底层存储架构,确保海量汽车交易数据的可靠存储和高效管理,同时集成Spark计算引擎实现对TB级别数据的实时分析处理。系统通过爬虫技术从汽车之家等主流二手车交易平台获取包含车辆基本信息、价格变动、地域分布、车况详情在内的多维度数据,运用Spark SQL进行复杂的数据清洗和特征提取工作。在数据分析层面,系统构建了四大核心分析维度,包括二手车市场宏观趋势分析、价格与保值率深度挖掘、用户关注热点地域特征识别以及新能源车专题研究,每个维度都包含多个细分的数据指标和可视化图表。前端采用Vue框架配合ECharts图表库构建直观的数据展示界面,后端基于Django框架提供RESTful API接口服务,整个系统通过MySQL数据库存储分析结果和用户配置信息,为二手车买卖双方、汽车经销商以及行业研究人员提供科学的决策支持和市场洞察工具。
车之家数据分析系统,Hadoop分布式存储+Spark计算引擎-系统技术介绍
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
车之家数据分析系统,Hadoop分布式存储+Spark计算引擎-系统背景意义
当前我国汽车保有量持续增长,二手车交易市场也随之快速发展,但是传统的二手车交易往往依赖经验判断和简单的价格对比,缺乏科学的数据支撑和系统性的市场分析。汽车之家、瓜子二手车、人人车等在线交易平台每天产生海量的车辆信息、价格数据和用户行为数据,这些数据蕴含着丰富的市场规律和消费趋势,但是由于数据量庞大、结构复杂,传统的数据处理方式已经无法满足深度分析的需求。与此同时,新能源汽车的快速普及给二手车市场带来了新的变化,电动车的保值率、续航里程对价格的影响、不同品牌的市场接受度等问题都需要通过大数据技术进行深入研究。面对这种情况,构建一套基于大数据技术的汽车数据分析系统变得十分必要,通过Hadoop和Spark等先进的大数据处理框架,可以有效处理和分析这些海量、多维度的汽车交易数据,为市场参与者提供更加准确和全面的决策依据。
本研究的实际价值主要体现在为二手车市场的各方参与者提供数据驱动的决策工具,帮助普通消费者在购买二手车时能够更好地了解市场行情、评估车辆价值,避免因为信息不对称而造成的经济损失。对于二手车经销商来说,系统提供的市场分析和价格预测功能可以帮助他们更准确地制定收车价格和销售策略,提高经营效率和盈利能力。从技术层面来看,该系统展示了Hadoop和Spark在实际业务场景中的应用效果,为大数据技术在汽车行业的推广应用提供了参考案例。虽然作为一个毕业设计项目,系统的规模和复杂度相对有限,但是它涵盖了完整的大数据处理流程,从数据采集、存储、清洗到分析、可视化,为学习和掌握大数据技术栈提供了良好的实践平台。另外,系统关注新能源汽车这一新兴领域的数据分析,对于理解和把握汽车产业转型趋势具有一定的参考意义,同时也为后续开展更深入的汽车大数据研究奠定了基础。
车之家数据分析系统,Hadoop分布式存储+Spark计算引擎-系统演示视频
大数据工程师认证项目:汽车之家数据分析系统,Hadoop分布式存储+Spark计算引擎
车之家数据分析系统,Hadoop分布式存储+Spark计算引擎-系统演示图片
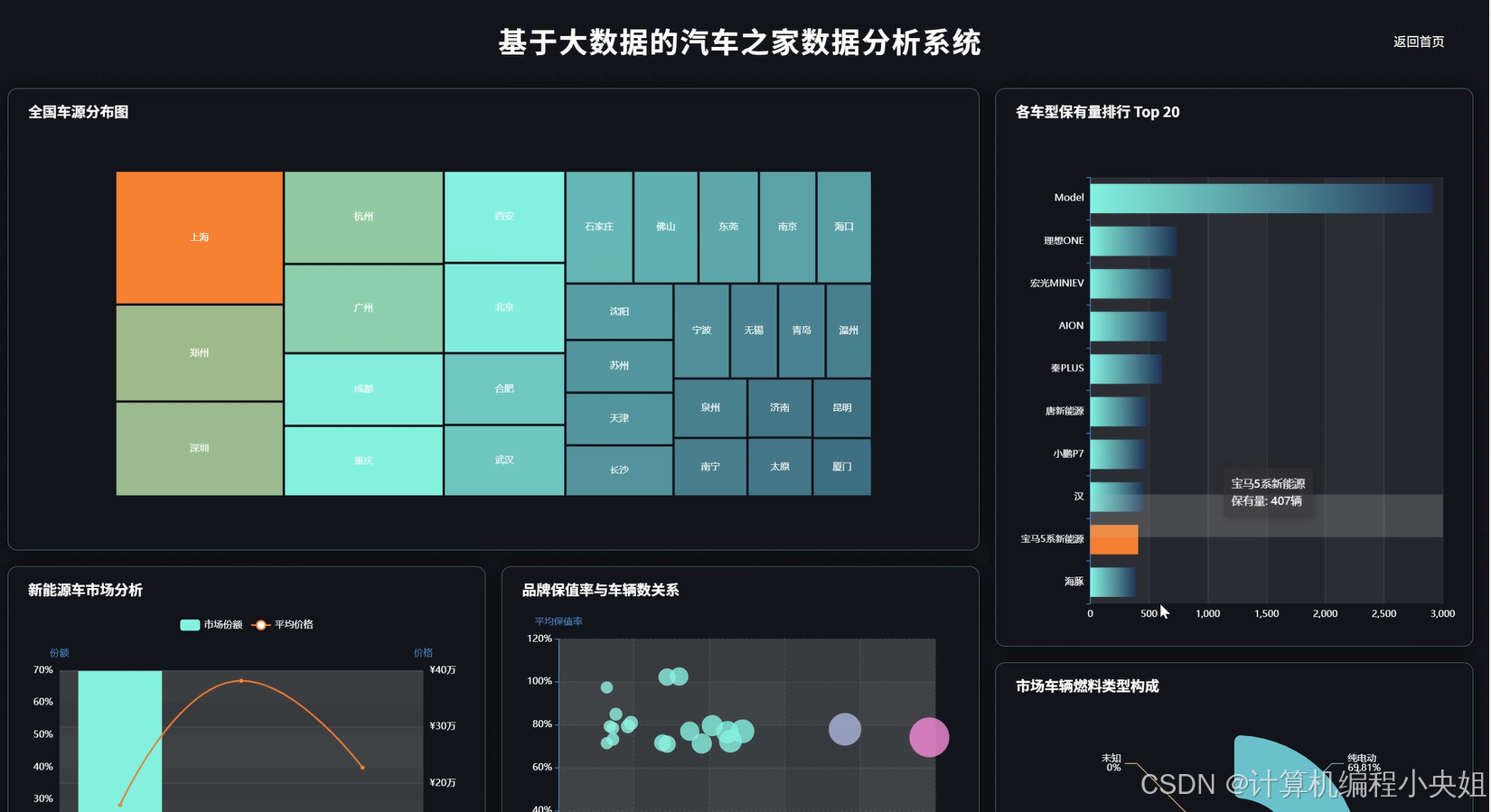
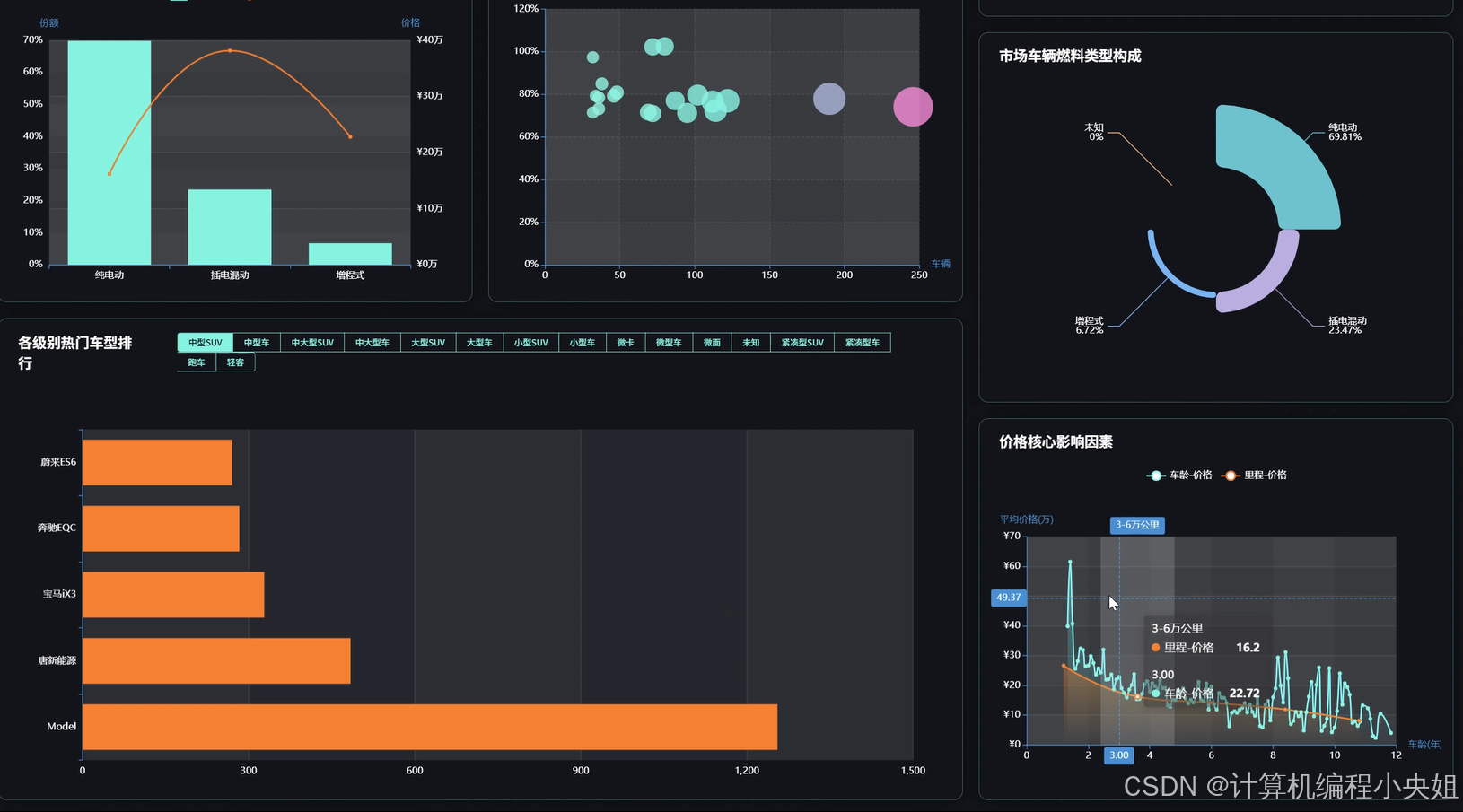
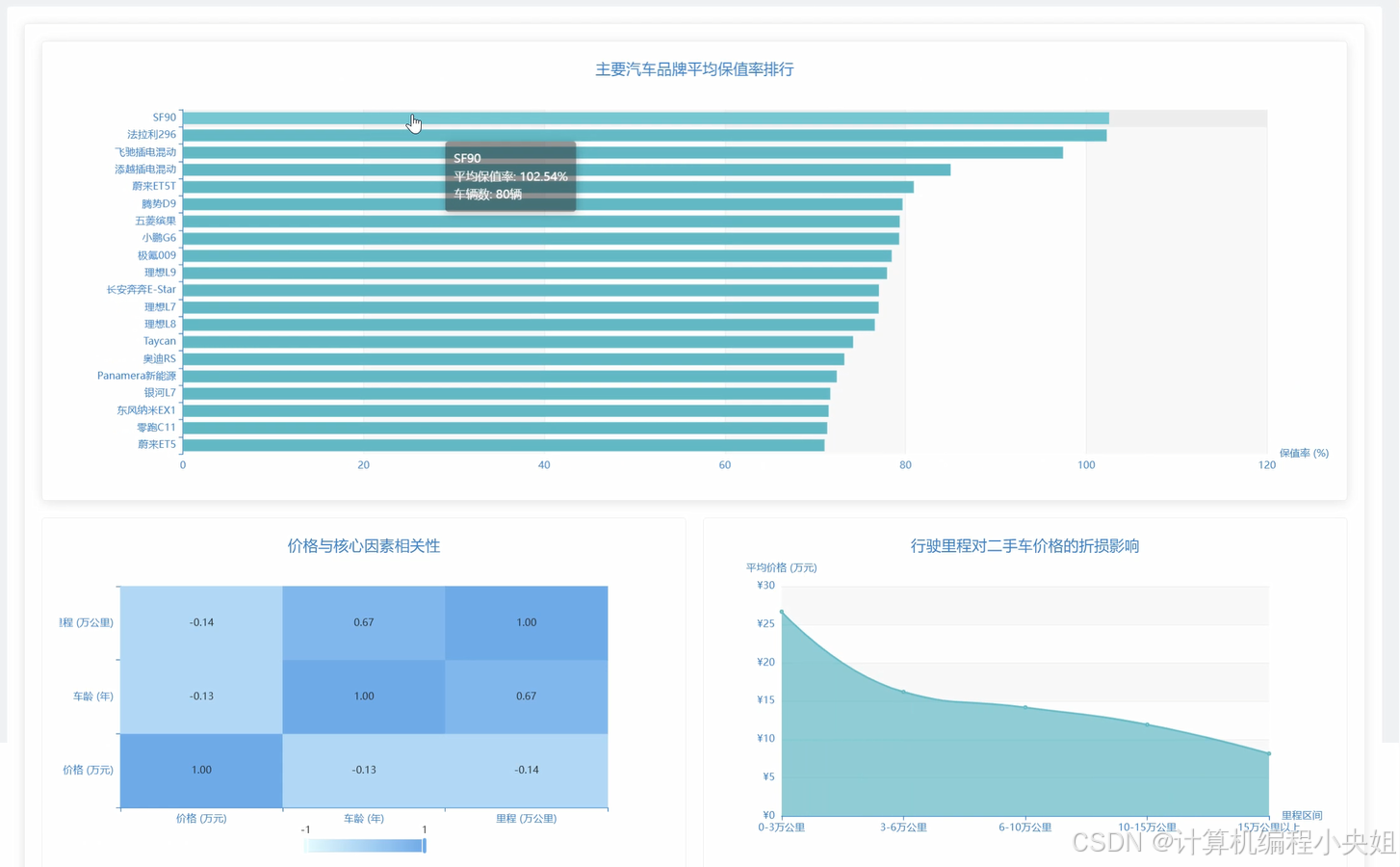
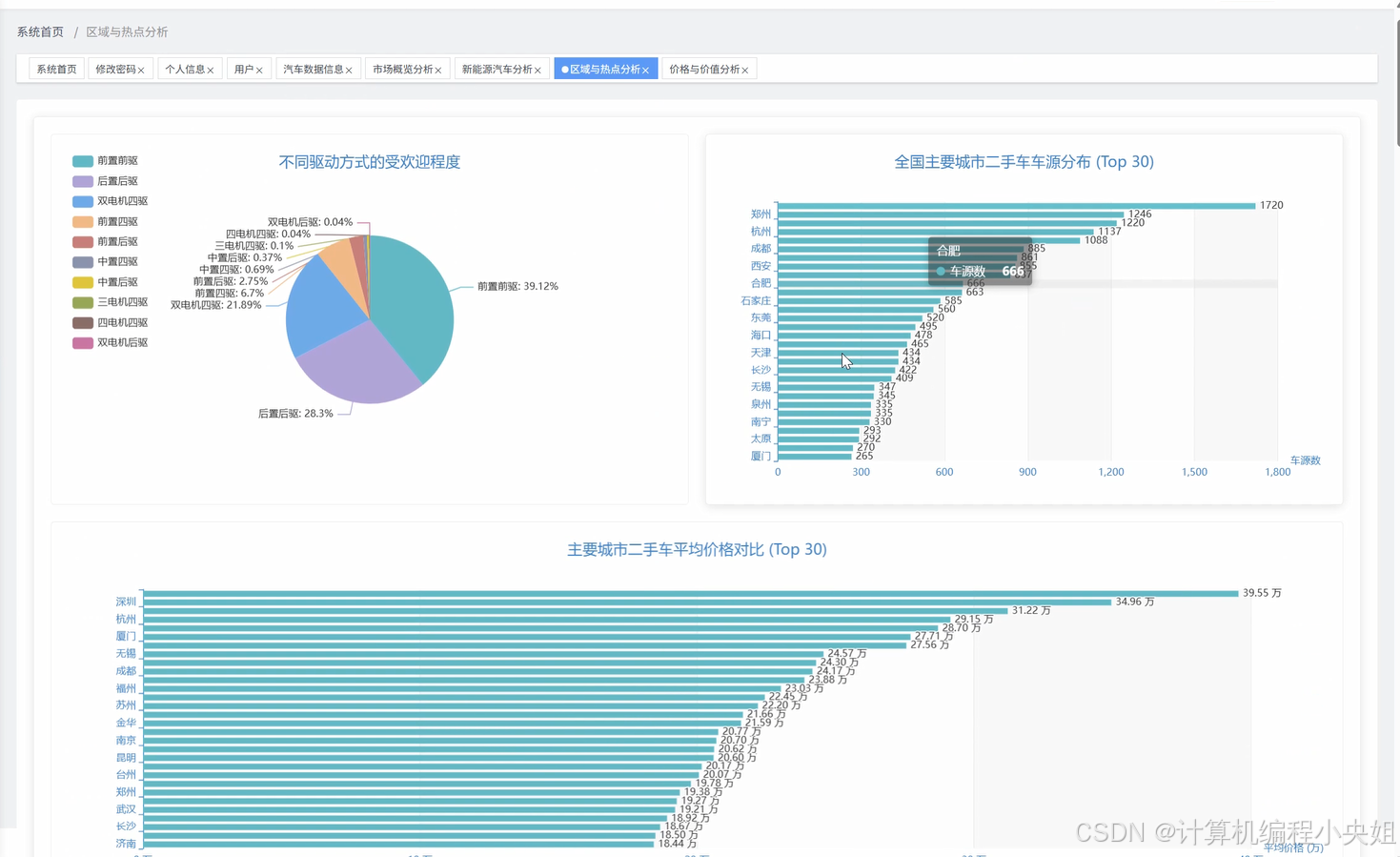
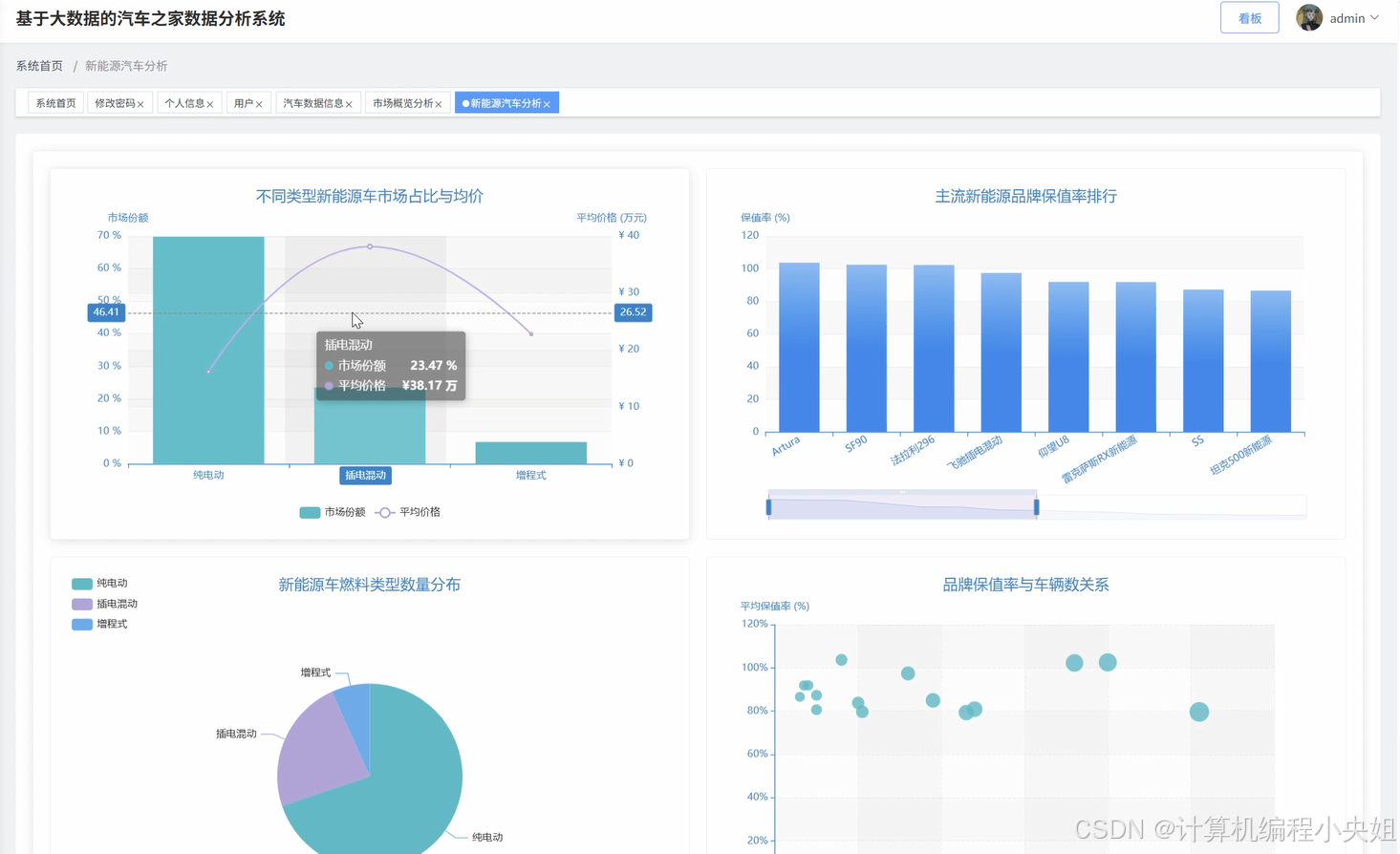
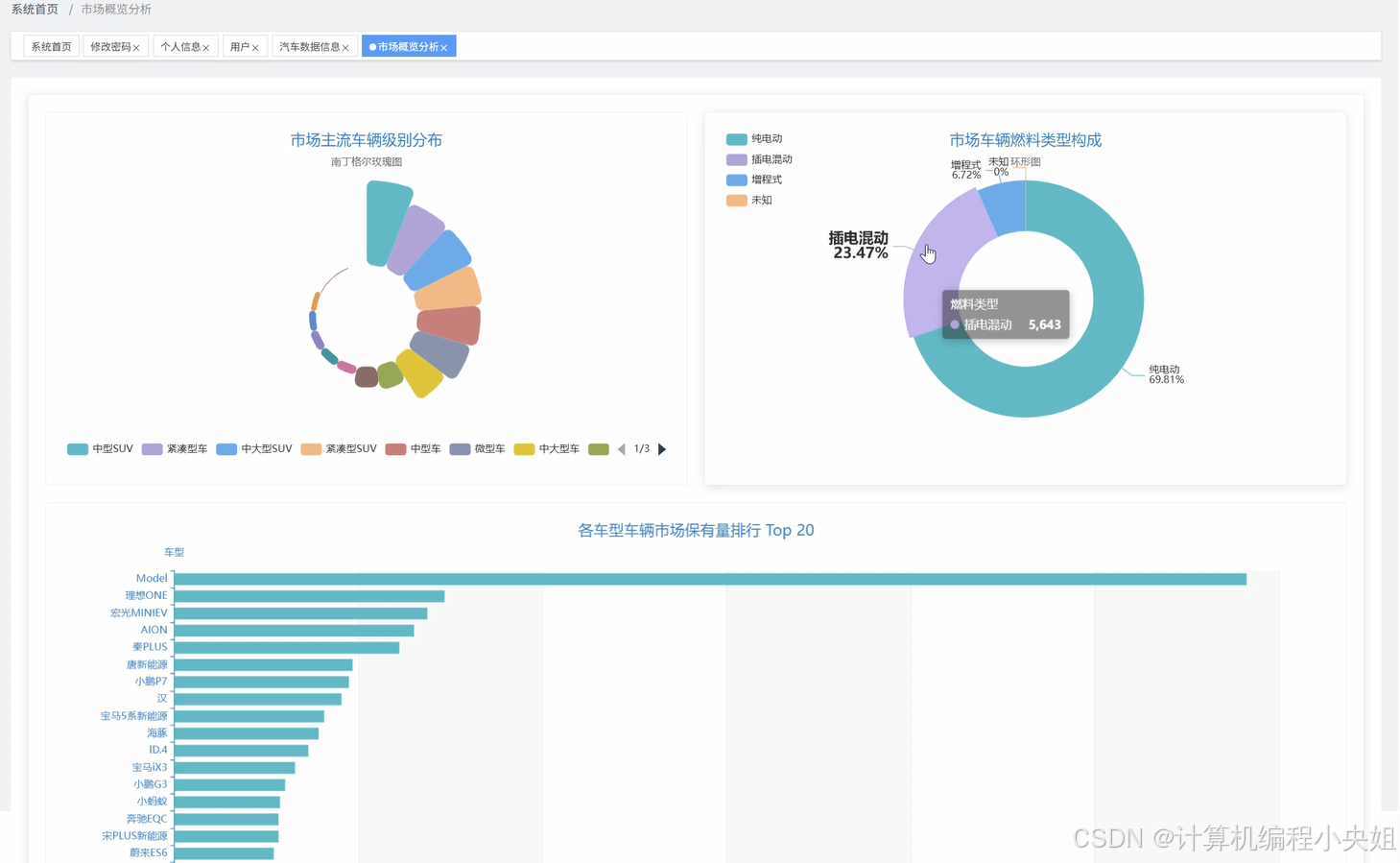
车之家数据分析系统,Hadoop分布式存储+Spark计算引擎-系统部分代码
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, count, desc, regexp_extract, when, split
from pyspark.sql.types import DoubleType
import mysql.connector
def analyze_brand_market_share():
spark = SparkSession.builder.appName("CarDataAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
car_df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/car_analysis").option("dbtable", "car_data").option("user", "root").option("password", "123456").load()
car_df_with_brand = car_df.withColumn("brand", regexp_extract(col("title"), r"^([^\s]+)", 1))
brand_count = car_df_with_brand.groupBy("brand").agg(count("*").alias("vehicle_count")).filter(col("vehicle_count") > 50)
total_vehicles = car_df_with_brand.count()
brand_market_share = brand_count.withColumn("market_share_percent", (col("vehicle_count") / total_vehicles * 100).cast(DoubleType()))
top_brands = brand_market_share.orderBy(desc("vehicle_count")).limit(20)
brand_level_analysis = car_df_with_brand.groupBy("brand", "vehicle_level").agg(count("*").alias("level_count")).filter(col("level_count") > 10)
brand_fuel_analysis = car_df_with_brand.groupBy("brand", "fuel_type").agg(count("*").alias("fuel_count")).filter(col("fuel_count") > 5)
result_data = top_brands.collect()
mysql_conn = mysql.connector.connect(host='localhost', user='root', password='123456', database='car_analysis')
cursor = mysql_conn.cursor()
cursor.execute("DELETE FROM brand_analysis_result")
for row in result_data:
cursor.execute("INSERT INTO brand_analysis_result (brand_name, vehicle_count, market_share) VALUES (%s, %s, %s)", (row['brand'], row['vehicle_count'], row['market_share_percent']))
mysql_conn.commit()
cursor.close()
mysql_conn.close()
spark.stop()
return result_data
def calculate_brand_retention_rate():
spark = SparkSession.builder.appName("CarRetentionAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").getOrCreate()
car_df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/car_analysis").option("dbtable", "car_data").option("user", "root").option("password", "123456").load()
filtered_df = car_df.filter((col("price") > 0) & (col("new_car_price") > 0) & (col("price") <= col("new_car_price")))
car_df_with_brand = filtered_df.withColumn("brand", regexp_extract(col("title"), r"^([^\s]+)", 1))
retention_df = car_df_with_brand.withColumn("retention_rate", (col("price") / col("new_car_price") * 100).cast(DoubleType()))
brand_retention = retention_df.groupBy("brand").agg(avg("retention_rate").alias("avg_retention_rate"), count("*").alias("sample_count")).filter(col("sample_count") >= 30)
brand_retention_filtered = brand_retention.filter(col("avg_retention_rate").between(10, 95))
top_retention_brands = brand_retention_filtered.orderBy(desc("avg_retention_rate")).limit(15)
age_retention_analysis = retention_df.withColumn("car_age_group", when(col("car_age") <= 1, "0-1年").when(col("car_age") <= 3, "1-3年").when(col("car_age") <= 5, "3-5年").otherwise("5年以上"))
age_brand_retention = age_retention_analysis.groupBy("brand", "car_age_group").agg(avg("retention_rate").alias("age_avg_retention"), count("*").alias("age_sample_count")).filter(col("age_sample_count") >= 10)
mileage_retention_analysis = retention_df.withColumn("mileage_group", when(col("mileage") <= 30000, "低里程").when(col("mileage") <= 80000, "中里程").otherwise("高里程"))
mileage_brand_retention = mileage_retention_analysis.groupBy("brand", "mileage_group").agg(avg("retention_rate").alias("mileage_avg_retention"), count("*").alias("mileage_sample_count")).filter(col("mileage_sample_count") >= 10)
result_data = top_retention_brands.collect()
mysql_conn = mysql.connector.connect(host='localhost', user='root', password='123456', database='car_analysis')
cursor = mysql_conn.cursor()
cursor.execute("DELETE FROM retention_analysis_result")
for row in result_data:
cursor.execute("INSERT INTO retention_analysis_result (brand_name, avg_retention_rate, sample_count) VALUES (%s, %s, %s)", (row['brand'], round(row['avg_retention_rate'], 2), row['sample_count']))
mysql_conn.commit()
cursor.close()
mysql_conn.close()
spark.stop()
return result_data
def analyze_new_energy_market():
spark = SparkSession.builder.appName("NewEnergyCarAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.skewJoin.enabled", "true").getOrCreate()
car_df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/car_analysis").option("dbtable", "car_data").option("user", "root").option("password", "123456").load()
new_energy_df = car_df.filter(col("fuel_type").isin(["纯电动", "插电混动", "增程式"]))
fuel_type_analysis = new_energy_df.groupBy("fuel_type").agg(count("*").alias("vehicle_count"), avg("price").alias("avg_price")).orderBy(desc("vehicle_count"))
total_new_energy = new_energy_df.count()
fuel_market_share = fuel_type_analysis.withColumn("market_share_percent", (col("vehicle_count") / total_new_energy * 100).cast(DoubleType()))
new_energy_with_brand = new_energy_df.withColumn("brand", regexp_extract(col("title"), r"^([^\s]+)", 1))
brand_fuel_analysis = new_energy_with_brand.groupBy("brand", "fuel_type").agg(count("*").alias("brand_fuel_count"), avg("price").alias("brand_avg_price")).filter(col("brand_fuel_count") >= 5)
pure_electric_df = new_energy_df.filter(col("fuel_type") == "纯电动").filter(col("pure_electric_range") > 0)
range_price_analysis = pure_electric_df.withColumn("range_group", when(col("pure_electric_range") <= 300, "短续航").when(col("pure_electric_range") <= 500, "中续航").otherwise("长续航"))
range_analysis_result = range_price_analysis.groupBy("range_group").agg(count("*").alias("range_count"), avg("price").alias("range_avg_price"), avg("pure_electric_range").alias("avg_range"))
battery_capacity_analysis = new_energy_df.filter(col("battery_capacity") > 0).withColumn("capacity_group", when(col("battery_capacity") <= 50, "小容量").when(col("battery_capacity") <= 80, "中容量").otherwise("大容量"))
capacity_analysis_result = battery_capacity_analysis.groupBy("capacity_group").agg(count("*").alias("capacity_count"), avg("price").alias("capacity_avg_price"), avg("battery_capacity").alias("avg_capacity"))
new_energy_retention = new_energy_with_brand.filter((col("price") > 0) & (col("new_car_price") > 0)).withColumn("retention_rate", (col("price") / col("new_car_price") * 100).cast(DoubleType()))
brand_retention_new_energy = new_energy_retention.groupBy("brand").agg(avg("retention_rate").alias("ne_avg_retention"), count("*").alias("ne_sample_count")).filter(col("ne_sample_count") >= 10).orderBy(desc("ne_avg_retention"))
result_data = fuel_market_share.collect()
mysql_conn = mysql.connector.connect(host='localhost', user='root', password='123456', database='car_analysis')
cursor = mysql_conn.cursor()
cursor.execute("DELETE FROM new_energy_analysis_result")
for row in result_data:
cursor.execute("INSERT INTO new_energy_analysis_result (fuel_type, vehicle_count, avg_price, market_share) VALUES (%s, %s, %s, %s)", (row['fuel_type'], row['vehicle_count'], round(row['avg_price'], 2), round(row['market_share_percent'], 2)))
mysql_conn.commit()
cursor.close()
mysql_conn.close()
spark.stop()
return result_data车之家数据分析系统,Hadoop分布式存储+Spark计算引擎-结语
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。