【大语言模型】------ Transformer的QKV及多头注意力机制图解解析
翻译任务
当我们用神经网络做翻译任务时,如下

先用词嵌入的方式把每个词转为对应的词向量,假设维度为6
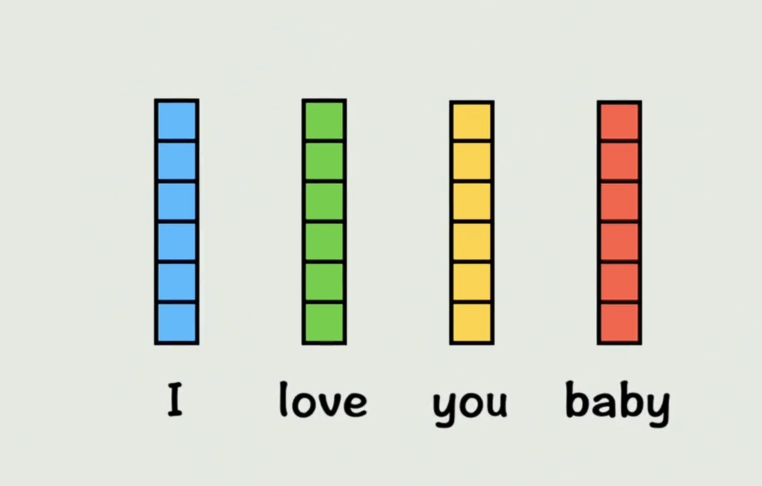
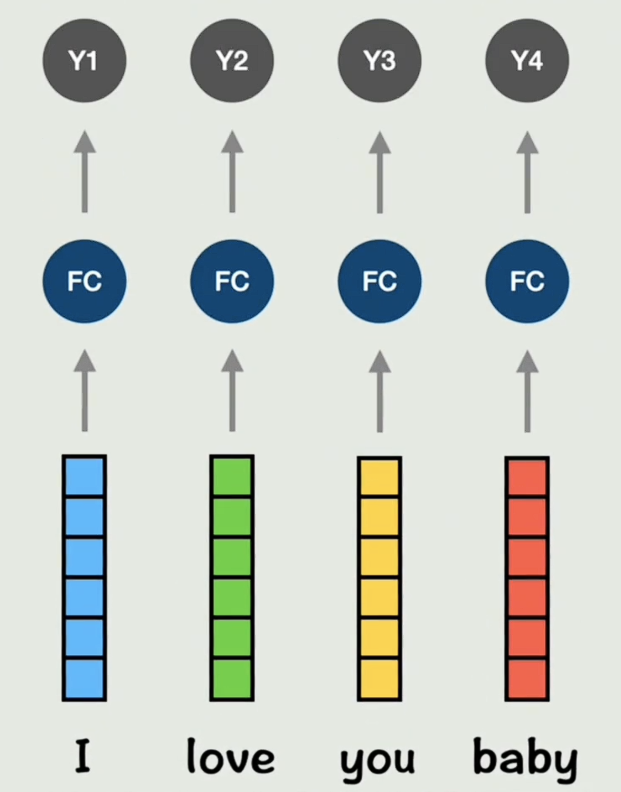
如果把每个词直接丢到一个全连接神经网络中,那每个词都没有上下文的信息,且长度只能一一对应
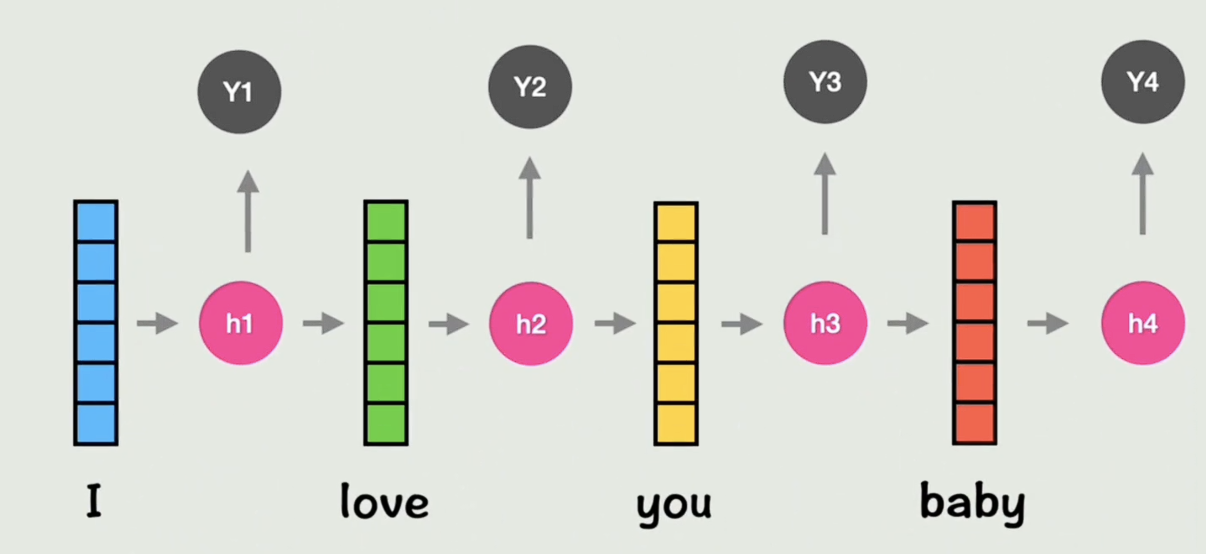
如果用循环神经网络RNN,又面临串行计算,而且如果句子太长,也会导致长期依赖困难的问题
位置编码
上述两种方法面临上下文以及词语间相互依赖的问题,因此首先需要引入文本的位置编码
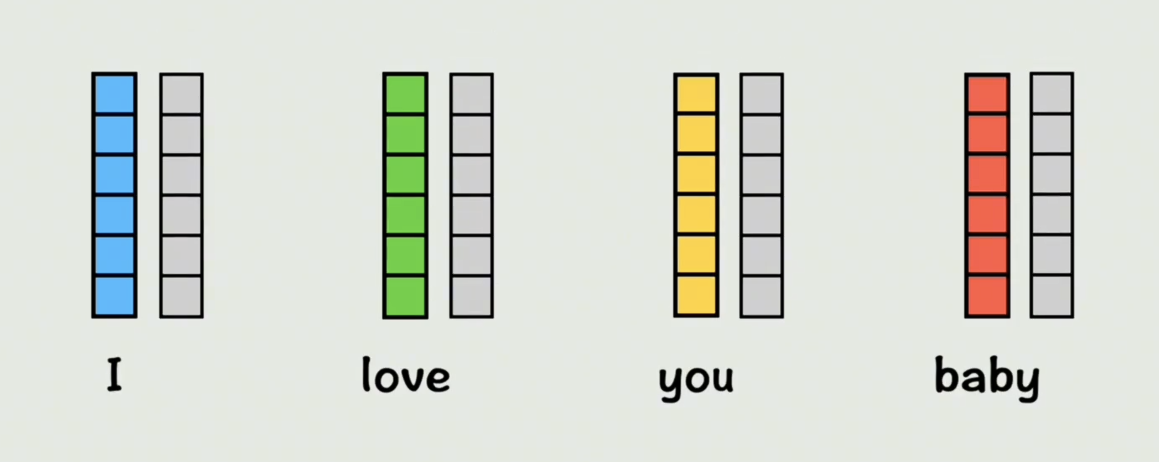
首先我们给每个词一个位置编码,表示这个词出现在整个句子中的位置,把位置编码加入到原来的词向量中,这个词就有了位置信息
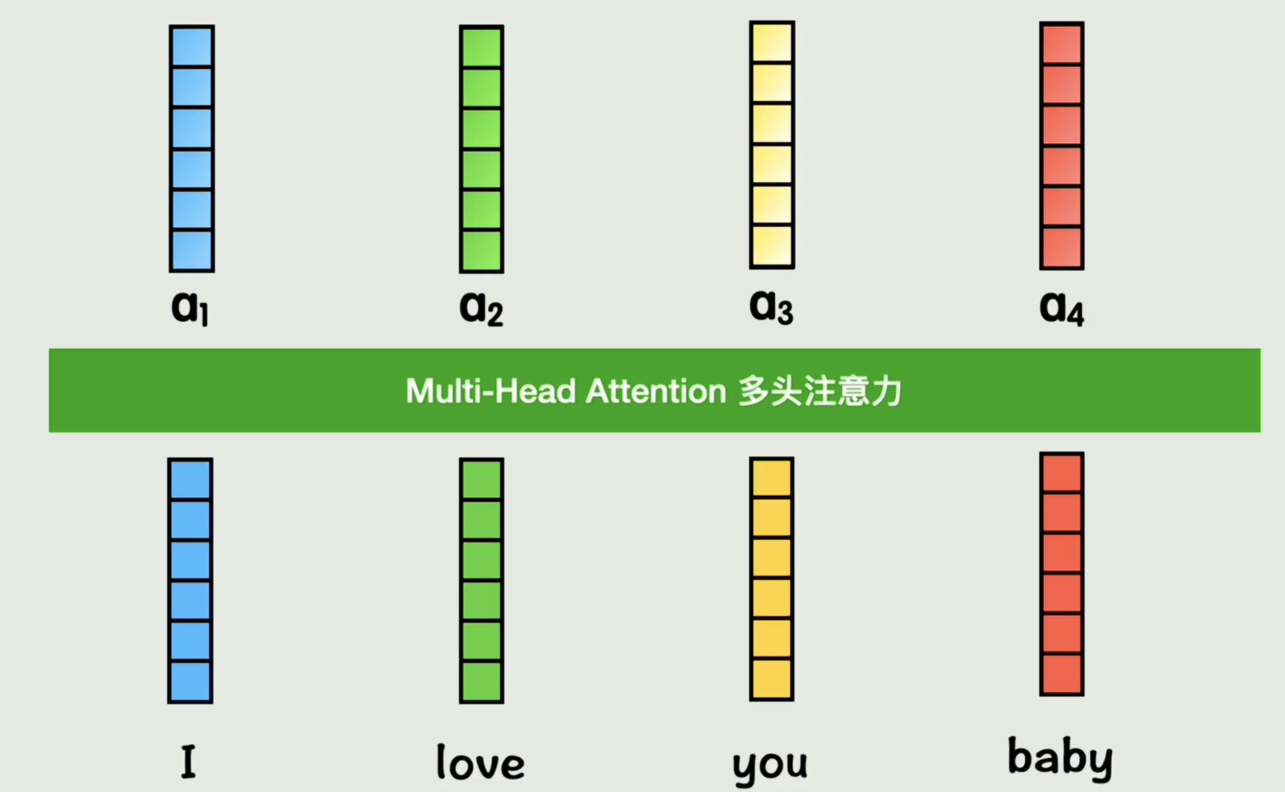
注意力机制
但此时每个词还没有其他词的上下文信息,也就是注意不到其他词的存在。
我们用一个 W q W_q Wq矩阵,和第一个词向量相乘,得到一个维度不变的 Q 1 Q_1 Q1向量
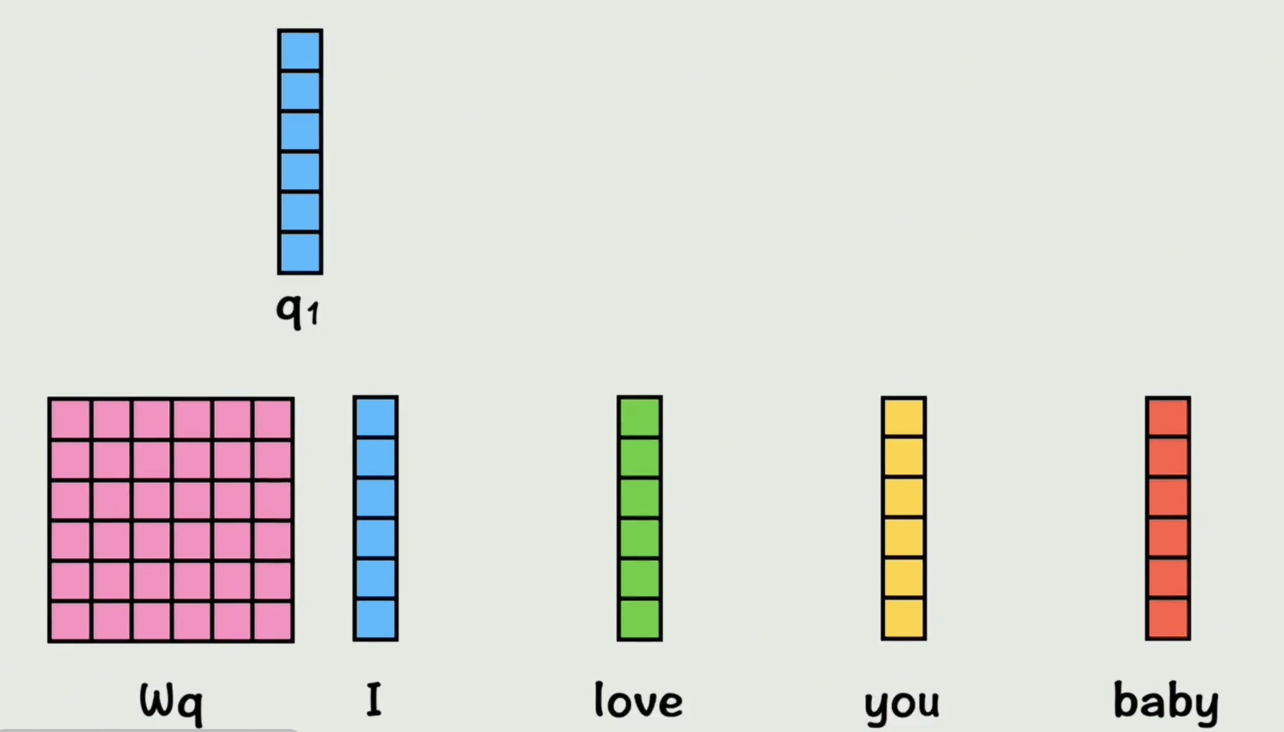
这里的 W q W_q Wq矩阵,是可以通过训练过程学习的一组权重值,同理,我们用一个 W k W_k Wk矩阵和第一个词向量相乘,得到 K 1 K_1 K1
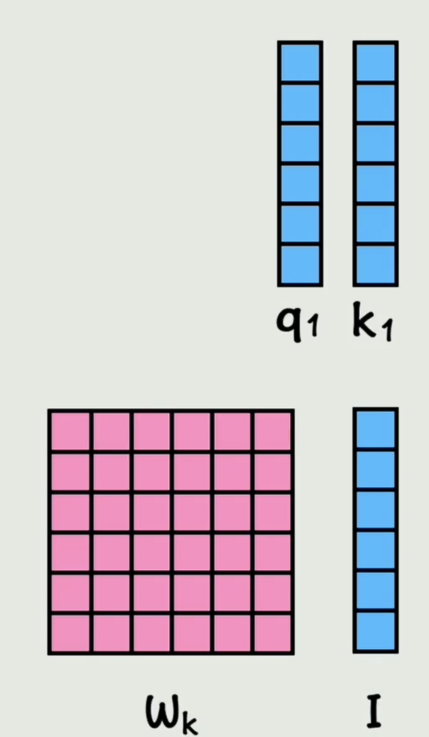
再通过 W v W_v Wv矩阵得到 V 1 V_1 V1
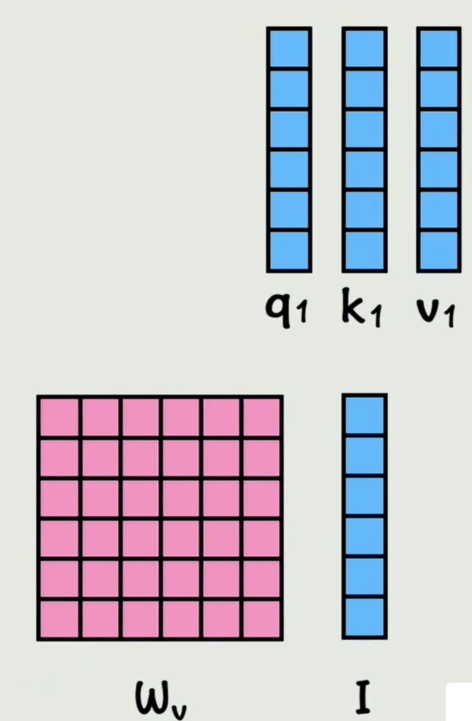
接着其他的词向量也和相同的 W Q , K , V W_{Q,K,V} WQ,K,V矩阵相乘,分别得到自己对应的 Q , K , V Q,K,V Q,K,V向量
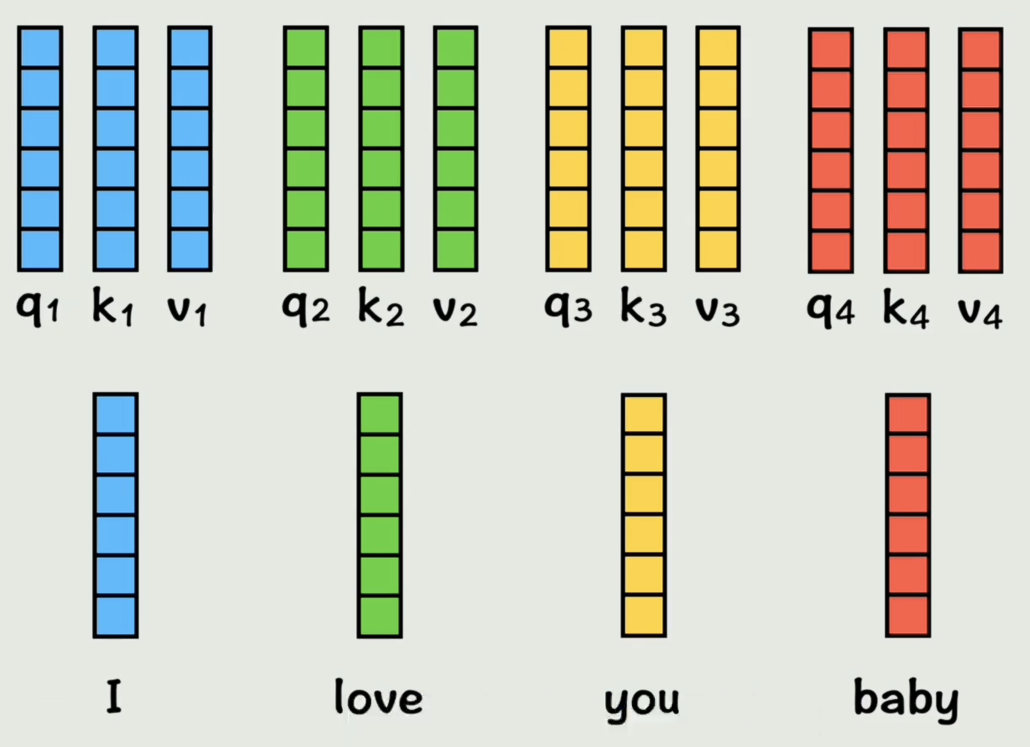
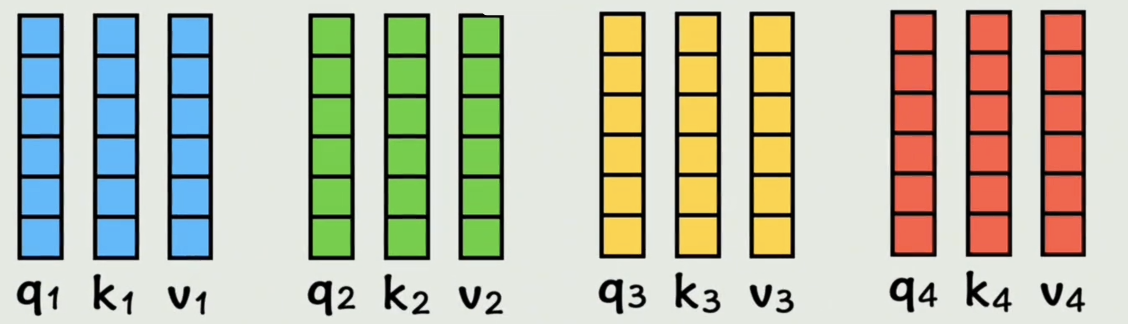
在实际的计算机运算中,是通过拼接得到的大矩阵做乘法,得到的就是包含所有词向量的 Q , K , V Q,K,V Q,K,V矩阵,在 Transformer 的注意力机制里,每个输入向量(比如一句话中的一个词的向量表示)需要根据上下文来重新获得"加权表示"。这种加权就是通过 Q , K , V Q,K,V Q,K,V来完成的。
现在原来的词向量已经分别通过线性变换,映射成了 Q , K , V Q,K,V Q,K,V,维度和原来是一样的
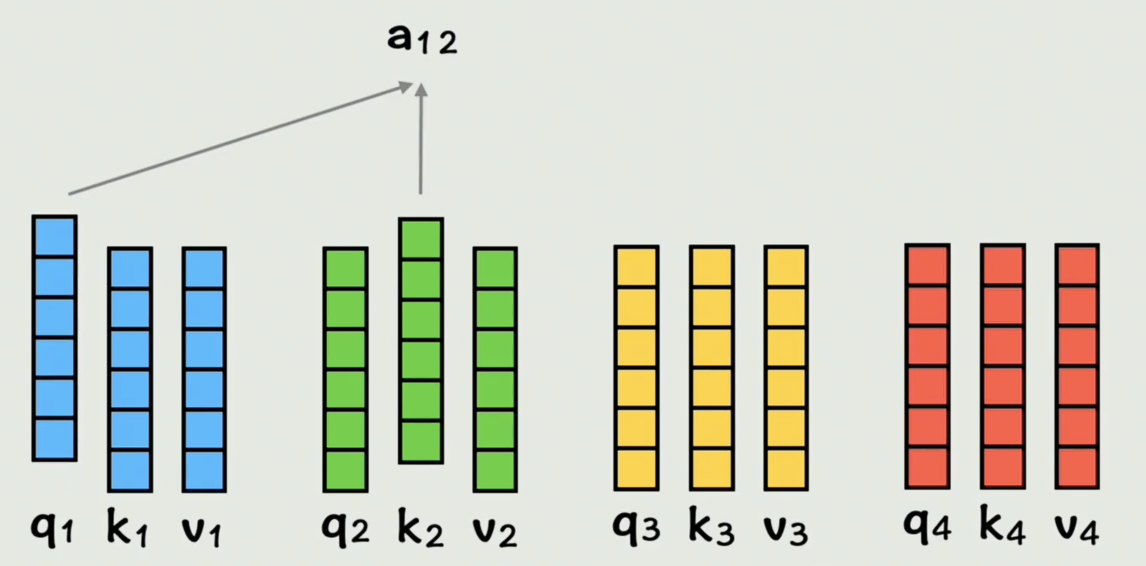
接下来我们让 Q 1 Q_1 Q1和 K 2 K_2 K2做点积,这表示在第一个词的视角里,第一个词和第二个词的相似度是多少
同理依次和 K 3 K_3 K3做点积,表示和第三个词的相似度,和 K 4 K_4 K4做点积,表示和第四个词的相似度
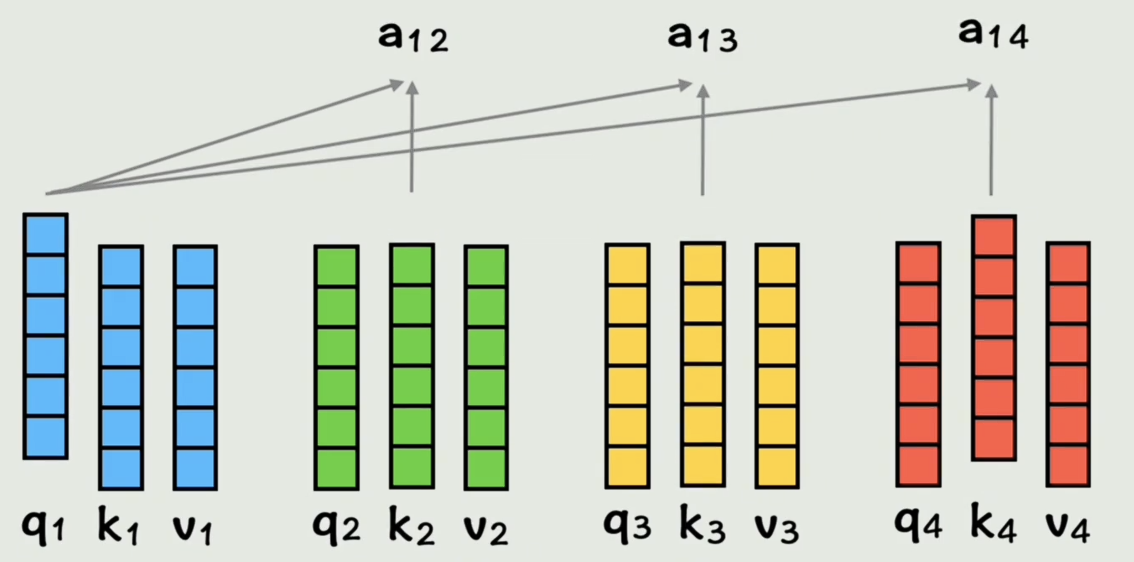
最后,和自己也做点积,表示和自己的相似度
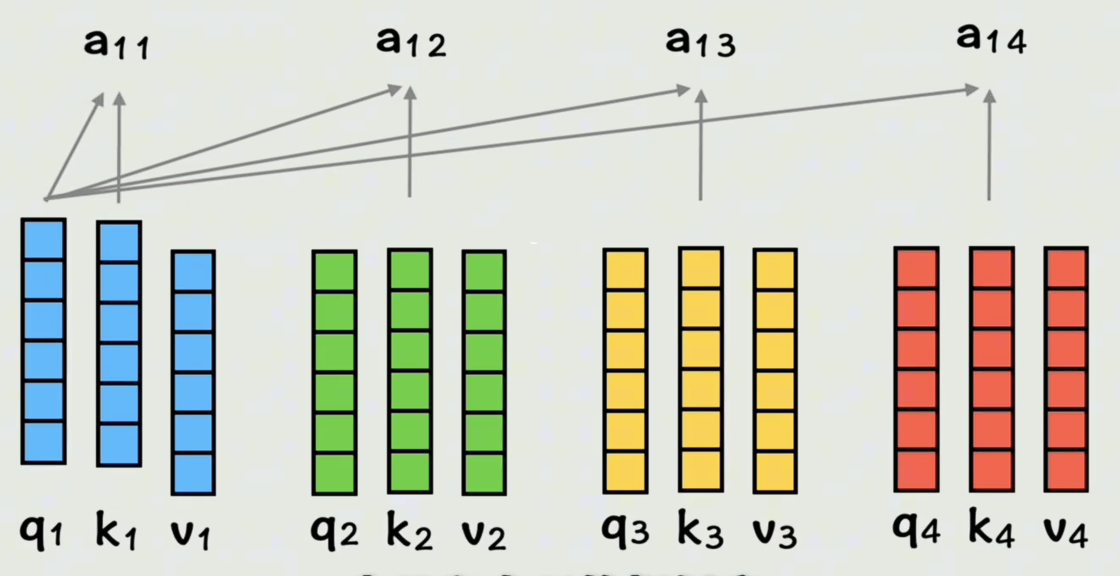
得到这些相似度系数之后,分别和 V V V向量相乘,再相加得到 A 1 A_1 A1,此时这个 A 1 A_1 A1就表示在第一个词的视角下,按照和他相似度大小按权重把每个词的词向量都加到了一起,这就把全部上下文信息都包含在第一个词中了,而且是以第一个词的视角观察的
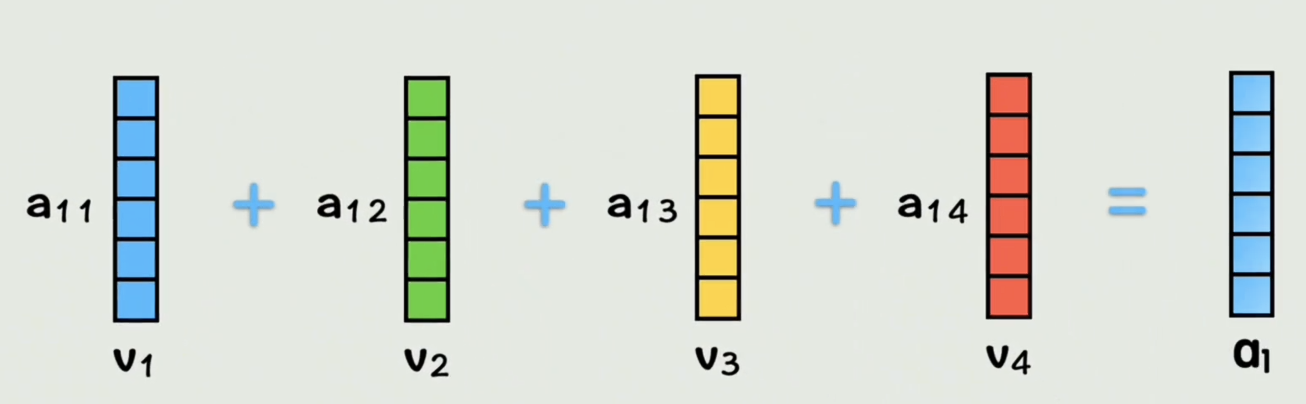
同理,其他几个词也按照这种方式,那么此时每个词都把其他词的词向量,按照和自己的相似度权重加到了自己的词向量中
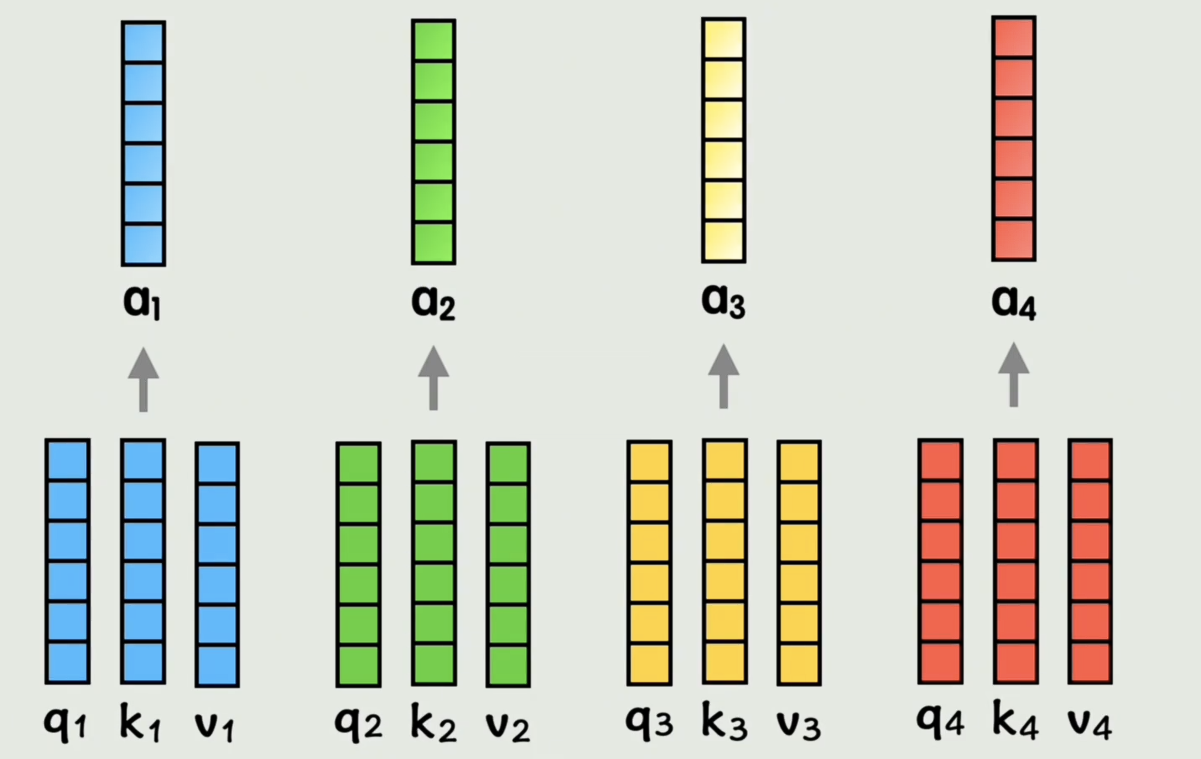
从全局视角来看,现在就是把最初的输入的词向量,经过一番处理,变成了一组新的词向量,但是这组新的词向量每一个都包含了位置信息和其他词上下文信息的一组新的词向量,这就是注意力attention做的事情
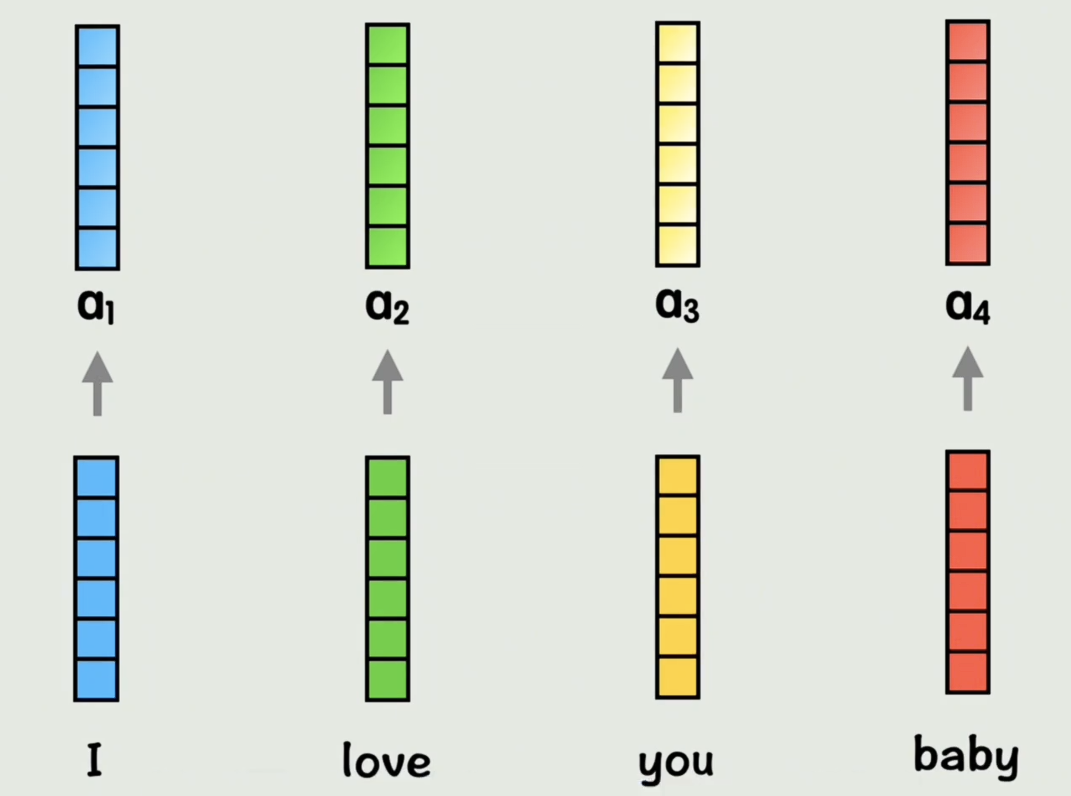
为了提高灵活性,之前我们是每个词计算一组 Q K V QKV QKV,我们在这个 Q K V QKV QKV基础上,再经过两个权重矩阵变成两组 Q K V QKV QKV,给每个词两次学习机会 ,学习到不同的要计算相似度的 Q K V QKV QKV,从而增加语言的灵活性,这里的每组 Q K V QKV QKV称为一个头
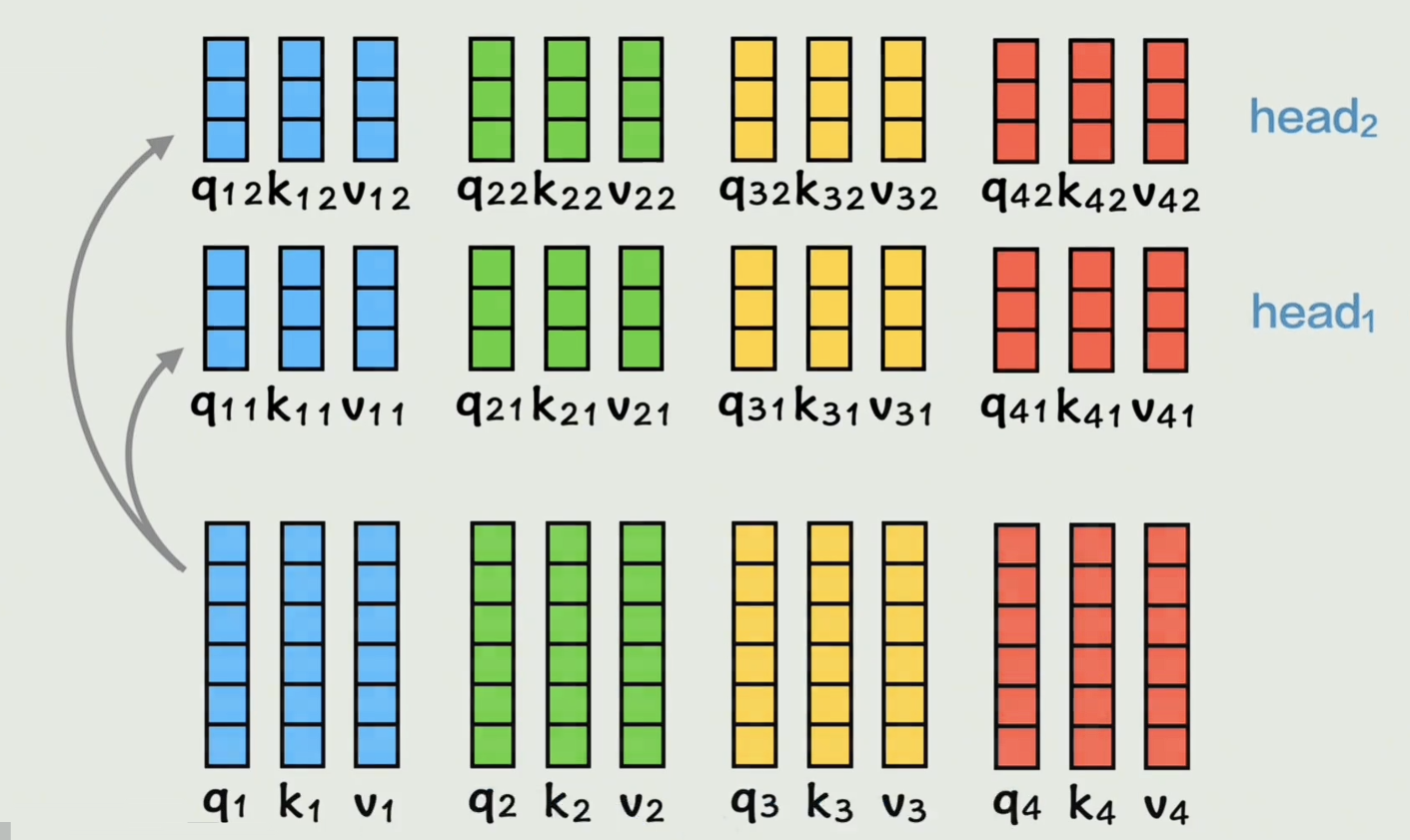
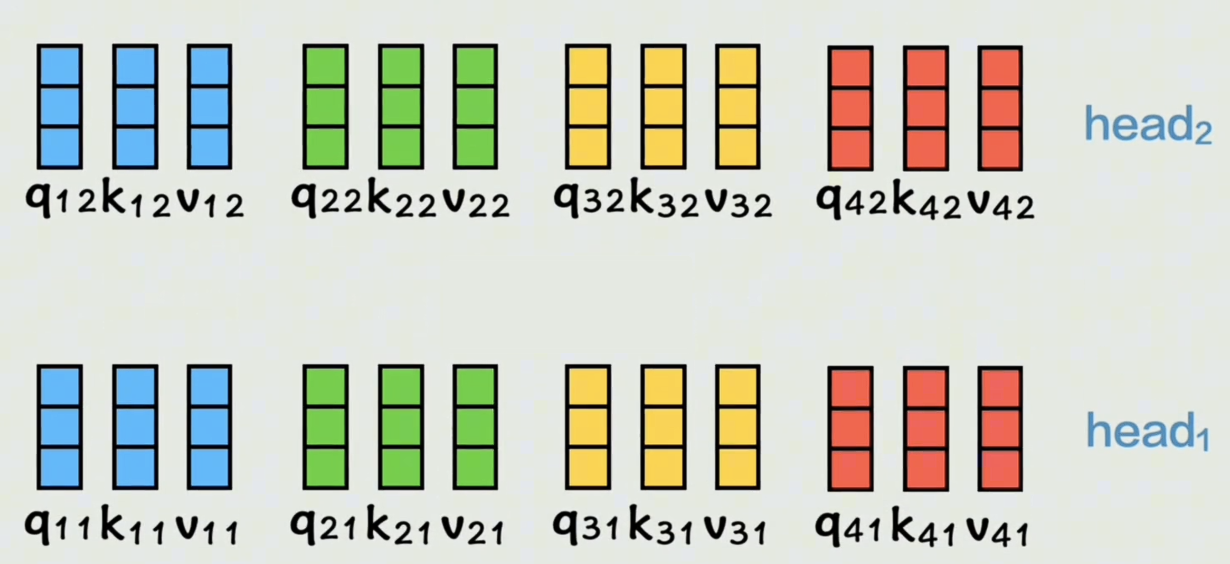
接下来在每个头里的 Q K V QKV QKV仍然经过刚刚的注意力层的运算得到 A A A向量
然后把两个 A A A向量拼接起来,得到和刚刚一样的结构
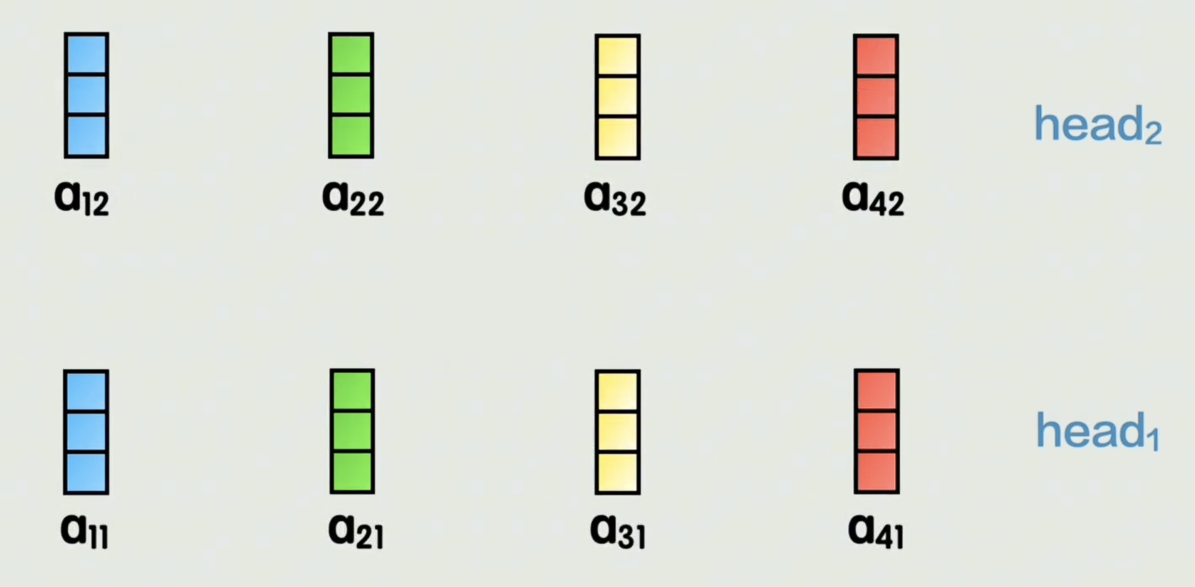
这就是多头注意力机制