
DoubleML 结合 FLAML------如何在DoubleML中自动调优学习器
自动化机器学习(AutoML)的最新进展让机器学习估计器的超参数自动调优变得更简单。这些经过优化的学习器可用于 DoubleML 框架内的估计环节。在本笔记本中,我们将探索如何借助 AutoML 为 DoubleML 框架调优学习器。
本笔记本将使用FLAML,但也有许多其他 AutoML 框架可供选择。对 DoubleML 而言,尤其实用的是那些能以sklearn风格导出模型的工具包,例如:TPOT、autosklearn、H20 或 Gama。
数据生成
我们使用make_plr_CCDDHNR2018()函数生成合成数据,包含 1000 个观测值、50 个协变量、1 个处理变量和 1 个结果变量。我们对数据生成过程进行校准,以凸显超参数调优的重要性。
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from doubleml.plm.datasets import make_plr_CCDDHNR2018
import doubleml as dml
from flaml import AutoML
from xgboost import XGBRegressor
# 生成合成数据
data = make_plr_CCDDHNR2018(alpha=0.5, n_obs=1000, dim_x=50, return_type="DataFrame", a0=0, a1=1, s1=0.25, s2=0.25)
data.head()
在全样本上调优
在本节中,我们将手动使用 FLAML 为部分线性回归模型(PLR)调优两个XGBoost模型。在 PLR 模型(使用默认评分函数)中,我们需要估计干扰项 η,其构成如下:
η : = m 0 ( x ) , ℓ 0 ( x ) = E D ∣ X , E Y ∣ X η:={m₀(x), ℓ₀(x)} = {ED\|X, EY\|X} η:=m0(x),ℓ0(x)=ED∣X,EY∣X
我们初始化两个FLAML AutoML 对象并完成拟合。调优完成后,将这些学习器传入DoubleML。
步骤 1:初始化并训练 AutoML 模型
注:该代码块将总共耗时 8 分钟优化干扰项模型。
python
# 初始化用于结果模型(ml_l)的AutoML:基于X预测Y
automl_l = AutoML()
settings_l = {
"time_budget": 240,
"metric": 'rmse',
"estimator_list": ['xgboost'],
"task": 'regression',
}
automl_l.fit(X_train=data.drop(columns=["y", "d"]).values, y_train=data["y"].values, verbose=2, **settings_l)
# 初始化用于处理模型(ml_m)的AutoML:基于X预测D
automl_m = AutoML()
settings_m = {
"time_budget": 240,
"metric": 'rmse',
"estimator_list": ['xgboost'],
"task": 'regression',
}
automl_m.fit(X_train=data.drop(columns=["y", "d"]).values, y_train=data["d"].values, verbose=2, **settings_m)步骤 2:评估调优后的模型
FLAML会将训练过程中的最优损失值存储为best_loss属性。更多细节可参考FLAML 官方文档。
python
rmse_oos_ml_m = automl_m.best_loss
rmse_oos_ml_l = automl_l.best_loss
print("调优过程中的最优RMSE(ml_m):",rmse_oos_ml_m)
print("调优过程中的最优RMSE(ml_l):",rmse_oos_ml_l)调优过程中的最优RMSE(ml_m):1.002037900301454
调优过程中的最优RMSE(ml_l):1.0929369228758206步骤 3:创建并拟合 DoubleML 模型
我们基于数据集创建DoubleMLData对象,指定 y 为结果变量、d 为处理变量。随后,使用调优后的FLAML估计器初始化DoubleMLPLR模型(分别用于处理项和结果项)。DoubleML会在每个折(fold)上创建配置相同的模型副本。
python
obj_dml_data = dml.DoubleMLData(data, "y", "d")
obj_dml_plr_fullsample = dml.DoubleMLPLR(obj_dml_data, ml_m=automl_m.model.estimator,
ml_l=automl_l.model.estimator)
print(obj_dml_plr_fullsample.fit().summary) coef(系数) std err(标准误) t值 P>|t|(P值) 2.5 %(95%CI下限) 97.5 %(95%CI上限)
d 0.490689 0.031323 15.665602 2.599586e-55 0.429298 0.552081DoubleML内置的学习器评估功能会报告交叉拟合过程中的样本外误差。我们可将该指标与上文调优过程中的最优损失值对比。
python
rmse_dml_ml_l_fullsample = obj_dml_plr_fullsample.evaluate_learners()['ml_l'][0][0]
rmse_dml_ml_m_fullsample = obj_dml_plr_fullsample.evaluate_learners()['ml_m'][0][0]
print("DoubleML评估的RMSE(ml_m):", rmse_dml_ml_m_fullsample)
print("DoubleML评估的RMSE(ml_l):", rmse_dml_ml_l_fullsample)DoubleML评估的RMSE(ml_m):1.0124105481660435
DoubleML评估的RMSE(ml_l):1.103179163001313自动化调优过程中的最优 RMSE 与干扰项预测的样本外误差数值相近,这表明模型未发生过拟合。我们本就不预期出现严重过拟合------因为 FLAML 内部使用交叉验证,且报告的是验证集上的最优损失值。
在折上调优
除了在外部调优FLAML学习器,我们也可在 DoubleML 内部完成 AutoML 学习器的调优。为此,需要定义自定义类以将FLAML集成到DoubleML中。调用DoubleML的fit()方法时,调优过程会自动启动。由于训练过程会在 K 个折上各执行一次,因此每个折都会得到一组个性化的最优超参数。
步骤 1:DoubleML 中 FLAML 模型的自定义接口
以下接口旨在为回归和分类任务提供自动化机器学习模型调优能力。但在本示例中,由于处理变量是连续型的,我们仅需回归器接口。
python
from sklearn.utils.multiclass import unique_labels
class FlamlRegressorDoubleML:
_estimator_type = 'regressor'
def __init__(self, time, estimator_list, metric, *args, **kwargs):
self.auto_ml = AutoML(*args, **kwargs)
self.time = time
self.estimator_list = estimator_list
self.metric = metric
def set_params(self, **params):
self.auto_ml.set_params(**params)
return self
def get_params(self, deep=True):
dict = self.auto_ml.get_params(deep)
dict["time"] = self.time
dict["estimator_list"] = self.estimator_list
dict["metric"] = self.metric
return dict
def fit(self, X, y):
self.auto_ml.fit(X, y, task="regression", time_budget=self.time, estimator_list=self.estimator_list, metric=self.metric, verbose=False)
self.tuned_model = self.auto_ml.model.estimator
return self
def predict(self, x):
preds = self.tuned_model.predict(x)
return preds
class FlamlClassifierDoubleML:
_estimator_type = 'classifier'
def __init__(self, time, estimator_list, metric, *args, **kwargs):
self.auto_ml = AutoML(*args, **kwargs)
self.time = time
self.estimator_list = estimator_list
self.metric = metric
def set_params(self, **params):
self.auto_ml.set_params(**params)
return self
def get_params(self, deep=True):
dict = self.auto_ml.get_params(deep)
dict["time"] = self.time
dict["estimator_list"] = self.estimator_list
dict["metric"] = self.metric
return dict
def fit(self, X, y):
self.classes_ = unique_labels(y)
self.auto_ml.fit(X, y, task="classification", time_budget=self.time, estimator_list=self.estimator_list, metric=self.metric, verbose=False)
self.tuned_model = self.auto_ml.model.estimator
return self
def predict_proba(self, x):
preds = self.tuned_model.predict_proba(x)
return preds步骤 2:调用 DoubleML 的.fit()方法时使用该接口
我们初始化一个FlamlRegressorDoubleML对象,无需提前拟合即可传入 DoubleML 对象。调用 DoubleML 对象的.fit()方法时,接口对象的副本会在每个折上创建,且每个折都会生成一组独立的最优超参数。由于我们需要在 K 个折上各拟合一次,因此相应减少单次调优的计算时间,以与全样本调优的总耗时保持一致。
python
# 定义FlamlRegressorDoubleML对象
ml_l = FlamlRegressorDoubleML(time=24, estimator_list=['xgboost'], metric='rmse')
ml_m = FlamlRegressorDoubleML(time=24, estimator_list=['xgboost'], metric='rmse')
# 使用新的回归器创建DoubleMLPLR对象
dml_plr_obj_onfolds = dml.DoubleMLPLR(obj_dml_data, ml_m, ml_l)
# 拟合DoubleMLPLR模型
print(dml_plr_obj_onfolds.fit(store_models=True).summary) coef std err t P>|t| 2.5 % 97.5 %
d 0.488455 0.031491 15.510971 2.924232e-54 0.426734 0.550176
python
rmse_oos_onfolds_ml_l = np.mean([dml_plr_obj_onfolds.models["ml_l"]["d"][0][i].auto_ml.best_loss for i in range(5)])
rmse_oos_onfolds_ml_m = np.mean([dml_plr_obj_onfolds.models["ml_m"]["d"][0][i].auto_ml.best_loss for i in range(5)])
print("调优过程中的最优RMSE(ml_m):",rmse_oos_onfolds_ml_m)
print("调优过程中的最优RMSE(ml_l):",rmse_oos_onfolds_ml_l)
rmse_dml_ml_l_onfolds = dml_plr_obj_onfolds.evaluate_learners()['ml_l'][0][0]
rmse_dml_ml_m_onfolds = dml_plr_obj_onfolds.evaluate_learners()['ml_m'][0][0]
print("DoubleML评估的RMSE(ml_m):", rmse_dml_ml_m_onfolds)
print("DoubleML评估的RMSE(ml_l):", rmse_dml_ml_l_onfolds)调优过程中的最优RMSE(ml_m):1.0060715124549546
调优过程中的最优RMSE(ml_l):1.1030891095588866
DoubleML评估的RMSE(ml_m):1.0187512020118494
DoubleML评估的RMSE(ml_l):1.1016338581630878与上文案例类似,我们未发现过拟合的迹象。
与短时间 AutoML 调优、未调优 XGBoost 学习器的对比
短时间 AutoML 调优
作为基准对比,我们将上文调优时间为 2 分钟的学习器,与仅使用 10 秒调优时间的学习器进行对比。
注:这些调优时长仅为示例。在本实验设置下,我们发现 10 秒的调优时间是不足的,而 120 秒则足够。通常,所需调优时间取决于数据复杂度、数据集规模、所用设备的计算能力等因素。如需正确使用FLAML,请参考其官方文档和相关论文。
python
# 初始化用于结果模型的AutoML(与上文类似,但缩短时间预算)
automl_l_lesstime = AutoML()
settings_l = {
"time_budget": 10,
"metric": 'rmse',
"estimator_list": ['xgboost'],
"task": 'regression',
}
automl_l_lesstime.fit(X_train=data.drop(columns=["y", "d"]).values, y_train=data["y"].values, verbose=2, **settings_l)
# 初始化用于处理模型的AutoML(与上文类似,但缩短时间预算)
automl_m_lesstime = AutoML()
settings_m = {
"time_budget": 10,
"metric": 'rmse',
"estimator_list": ['xgboost'],
"task": 'regression',
}
automl_m_lesstime.fit(X_train=data.drop(columns=["y", "d"]).values, y_train=data["d"].values, verbose=2, **settings_m)
python
obj_dml_plr_lesstime = dml.DoubleMLPLR(obj_dml_data, ml_m=automl_m_lesstime.model.estimator,
ml_l=automl_l_lesstime.model.estimator)
print(obj_dml_plr_lesstime.fit().summary) coef std err t P>|t| 2.5 % 97.5 %
d 0.461493 0.031075 14.851012 6.852592e-50 0.400587 0.522398我们可再次检查模型性能:
python
rmse_dml_ml_l_lesstime = obj_dml_plr_lesstime.evaluate_learners()['ml_l'][0][0]
rmse_dml_ml_m_lesstime = obj_dml_plr_lesstime.evaluate_learners()['ml_m'][0][0]
print("调优过程中的最优RMSE(ml_m):", automl_m_lesstime.best_loss)
print("调优过程中的最优RMSE(ml_l):", automl_l_lesstime.best_loss)
print("DoubleML评估的RMSE(ml_m):", rmse_dml_ml_m_lesstime)
print("DoubleML评估的RMSE(ml_l):", rmse_dml_ml_l_lesstime)调优过程中的最优RMSE(ml_m):0.9386744462704798
调优过程中的最优RMSE(ml_l):1.0520233166790431
DoubleML评估的RMSE(ml_m):1.0603268864456956
DoubleML评估的RMSE(ml_l):1.111352344760325我们发现,AutoML 调优的最优 RMSE 与 DoubleML 评估的样本外 RMSE 之间差异更大,这可能表明学习器发生了欠拟合(即调优时间不足)。
未调优(默认参数)的 XGBoost
作为另一组基准,我们构建使用默认超参数(即未调优)XGBoost 学习器的 DoubleML 模型:
python
xgb_untuned_m, xgb_untuned_l = XGBRegressor(), XGBRegressor()
python
# 使用未调优XGBoost创建DoubleMLPLR对象
dml_plr_obj_untuned = dml.DoubleMLPLR(obj_dml_data, xgb_untuned_l, xgb_untuned_m)
print(dml_plr_obj_untuned.fit().summary)
rmse_dml_ml_l_untuned = dml_plr_obj_untuned.evaluate_learners()['ml_l'][0][0]
rmse_dml_ml_m_untuned = dml_plr_obj_untuned.evaluate_learners()['ml_m'][0][0] coef std err t P>|t| 2.5 % 97.5 %
d 0.429133 0.031692 13.540578 9.007789e-42 0.367017 0.491249对比与总结
我们汇总不同模型的结果:全样本调优 AutoML、折上调优 AutoML、未调优 XGBoost、短时间调优 AutoML。
python
summary = pd.concat([obj_dml_plr_fullsample.summary, dml_plr_obj_onfolds.summary, dml_plr_obj_untuned.summary, obj_dml_plr_lesstime.summary],
keys=['全样本调优', '折上调优', '默认参数', '短时间调优'])
summary.index.names = ['模型类型', '指标']
summary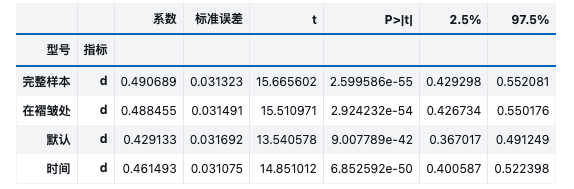
绘制系数与 95%置信区间
本节生成可视化图表,对比不同模型类型的系数及 95%置信区间。
python
# 提取模型标签和系数值
model_labels = summary.index.get_level_values('模型类型')
coef_values = summary['coef'].values
# 计算误差(置信区间上下限与系数的差值)
errors = np.full((2, len(coef_values)), np.nan)
errors[0, :] = summary['coef'] - summary['2.5 %']
errors[1, :] = summary['97.5 %'] - summary['coef']
# 绘制系数与95%置信区间
plt.figure(figsize=(10, 6))
plt.errorbar(model_labels, coef_values, fmt='o', yerr=errors, capsize=5)
plt.axhline(0.5, color='red', linestyle='--') # 绘制参考线(真实系数值)
plt.xlabel('模型')
plt.ylabel('系数与95%置信区间')
plt.title('不同模型的系数及95%置信区间对比')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()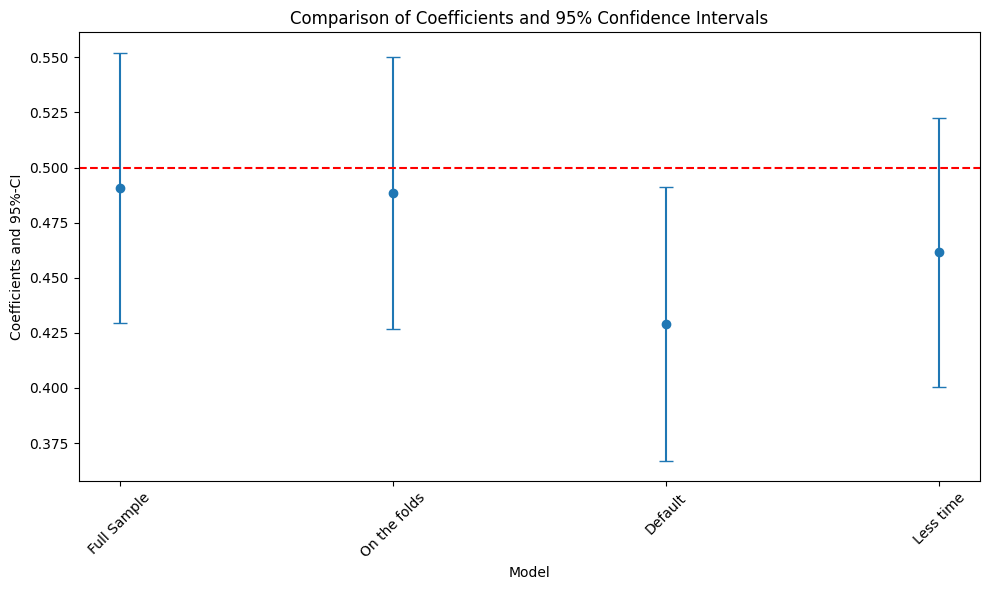
对比干扰项估计的指标
本节对比不同模型的干扰项估计指标,并绘制柱状图可视化性能差异。
python
fig, axs = plt.subplots(1,2,figsize=(10,4))
axs = axs.flatten()
axs[0].bar(x = ['全样本调优', '折上调优', '默认参数', '短时间调优'],
height=[rmse_dml_ml_m_fullsample, rmse_dml_ml_m_onfolds, rmse_dml_ml_m_untuned, rmse_dml_ml_m_lesstime])
axs[1].bar(x = ['全样本调优', '折上调优', '默认参数', '短时间调优'],
height=[rmse_dml_ml_l_fullsample, rmse_dml_ml_l_onfolds, rmse_dml_ml_l_untuned, rmse_dml_ml_l_lesstime])
axs[0].set_xlabel("调优方式")
axs[0].set_ylim((1,1.12))
axs[0].set_ylabel("RMSE")
axs[0].set_title("不同调优方式下的样本外RMSE(ml_m)")
axs[1].set_xlabel("调优方式")
axs[1].set_ylim((1.1,1.22))
axs[1].set_ylabel("RMSE")
axs[1].set_title("不同调优方式下的样本外RMSE(ml_l)")
fig.suptitle("不同调优方式下干扰项估计的样本外RMSE")
fig.tight_layout()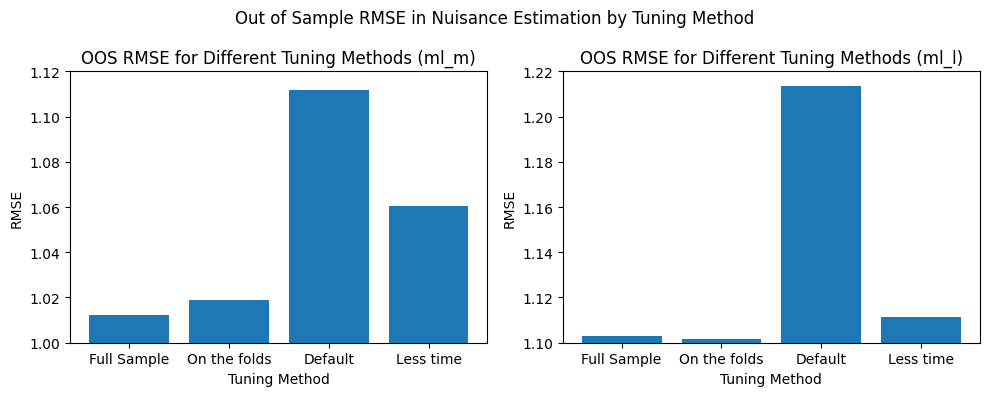
结论
本笔记本表明,超参数调优在 DoubleML 框架中至关重要,且可通过 FLAML AutoML 轻松实现。在我们最新的研究中,我们进一步验证了 AutoML 调优的有效性------尤其是在所有验证场景中,全样本调优的表现与折上调优相近,因此可通过外部调优节省调优时间和复杂度。
此外,可参考我们为 DoubleML 打造的全自动 AutoML 调优接口AutoDoubleML,该工具可从 Github 下载并在 Python 中使用。
参考文献
Bach, P., Schacht, O., Chernozhukov, V., Klaassen, S., & Spindler, M. (2024, March). Hyperparameter Tuning for Causal Inference with Double Machine Learning: A Simulation Study. In Causal Learning and Reasoning (pp. 1065-1117). PMLR.

