目标检测概述
文章目录
Preliminaries
锚框
参考-->https://blog.csdn.net/qq_43328040/article/details/107977085
NMS(Non-Maximum Suppression)

Selective Search
Fast RCNN使用的一种region based proposal算法,选择性搜索结合了详尽搜索和分割的优势。

1)首先通过基于图的图像分割方法初始化原始区域,就是将图像分割成很多很多的小块;
2)使用贪心策略,计算每两个相邻区域的相似度,然后每次合并最相似的两块,直至最终只剩下一块完整的图片;
3)这其中每次产生的图像块包括合并的图像块我们都保存下来。
RoI Pooling
参见->https://blog.csdn.net/fenglepeng/article/details/117885129
相关工作
RCNN
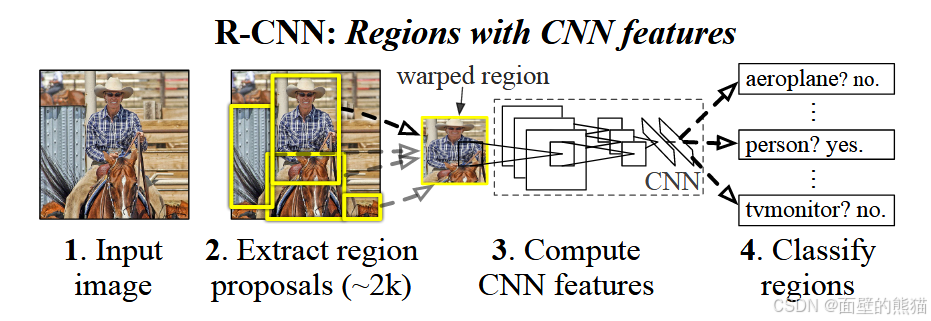
三部分:
- Region proposals:使用selective search选出可能区域。
- Feature Extraction:将每个region warp到fixed size(227x227),提取特征。
- SVM-Classifier:基于SVM的线性分类器。
Fast RCNN
RCNN的缺点:
- 训练 是一个多阶段的,特征提取器、SVM分类、bounding-box回归三部分分离。
- 训练费时费空间。
- 检测速度慢。
其实说白了,RCNN是阶段太多了,同时其又没有共享特征(导致计算重复),和SPPnets相比还是resize proposal region。
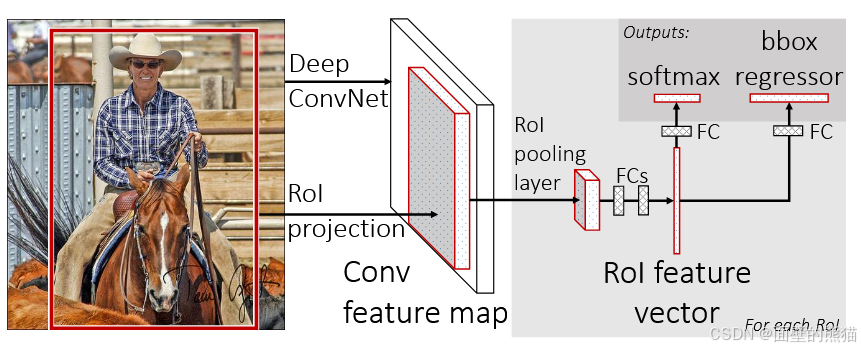
(1)输入图像;
(2)通过深度网络中的卷积层(VGG、Alexnet、Resnet等中的卷积层)对图像进行特征提取,得到图片的特征图;
(3)通过选择性搜索算法得到图像的感兴趣区域(通常取2000个);
(4)对得到的感兴趣区域进行RoI pooling(感兴趣区域池化) :即通过坐标投影的方法,在特征图上得到输入图像中的感兴趣区域对应的特征区域,并对该区域进行最大值池化,这样就得到了感兴趣区域的特征,并且统一了特征大小,如图2所示;
(5)对RoI pooling 层的输出(及感兴趣区域对应的特征图最大值池化后的特征)作为每个感兴趣区域的特征向量;
(6)将感兴趣区域的特征向量与全连接层相连,并定义了多任务损失函数,分别与softmax分类器和bounding box回归器相连,分别得到当前感兴趣区域的类别及坐标包围框;
(7)对所有得到的包围框进行非极大值抑制(NMS),得到最终的检测结果。
Faster RCNN
参考:https://blog.csdn.net/weixin_42310154/article/details/119889682
Faster RCNN提出一个RPN网络来获得proposal regions,其瞄准了Fast RCNN和SPPnet关于proposal region耗时的问题,进行了优化。
使用anchor images+rpn网络实现proposal regions的获取,进一步减少了目标检测的推理时延。
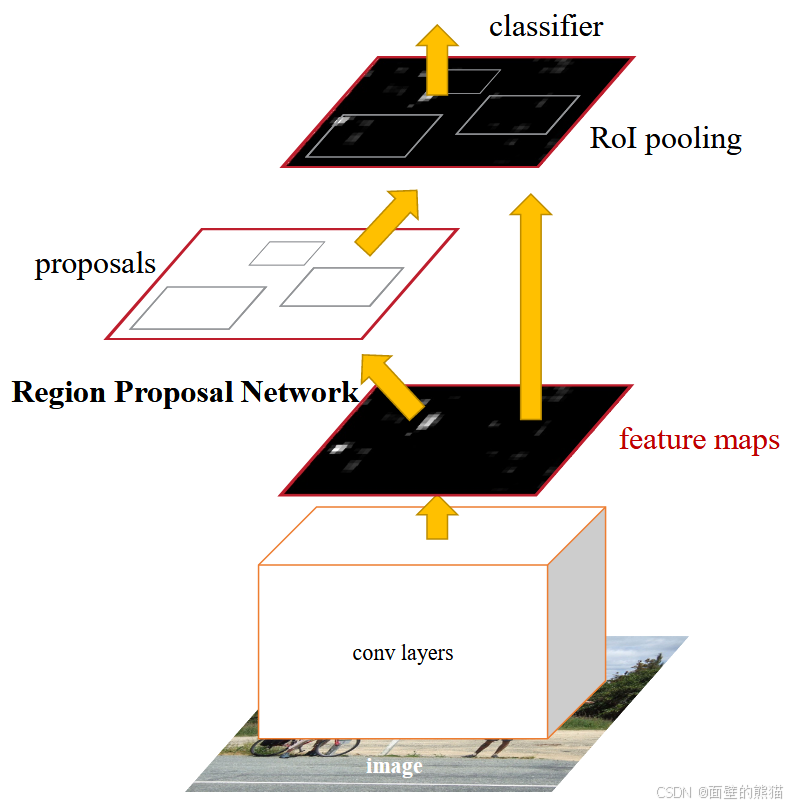
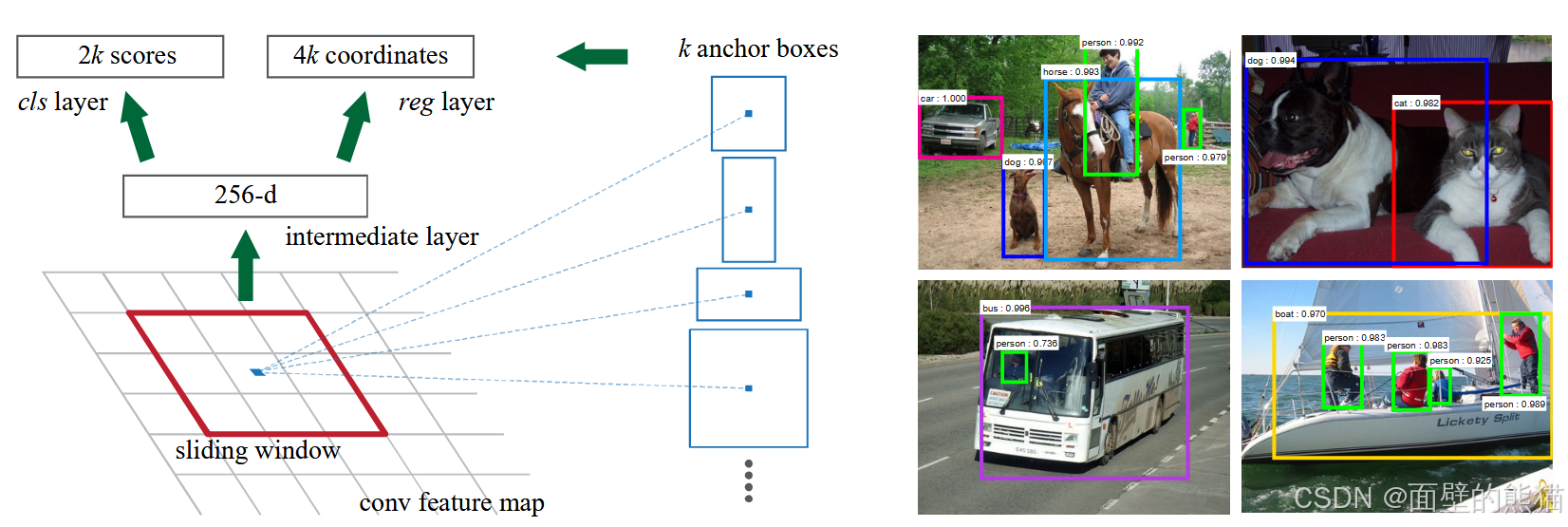
Faster RCNN检测部分主要可以分为四个模块 :
(1)conv layers 。即特征提取网络,用于提取特征。通过一组conv+relu+pooling层来提取图像的feature maps,用于后续的RPN层和取proposal。
(2)RPN(Region Proposal Network) 。即区域候选网络,该网络替代了之前RCNN版本的Selective Search,用于生成候选框。这里任务有两部分,一个是分类:判断所有预设anchor是属于positive还是negative(即anchor内是否有目标,二分类);还有一个bounding box regression:修正anchors得到较为准确的proposals。因此,RPN网络相当于提前做了一部分检测,即判断是否有目标(具体什么类别这里不判),以及修正anchor使框的更准一些。
(3)RoI Pooling 。即兴趣域池化(SPP net中的空间金字塔池化),用于收集RPN生成的proposals(每个框的坐标),并从(1)中的feature maps中提取出来(从对应位置扣出来),生成proposals feature maps送入后续全连接层继续做分类(具体是哪一类别)和回归。
(4)Classification and Regression。利用proposals feature maps计算出具体类别,同时再做一次bounding box regression获得检测框最终的精确位置。
YOLO v1
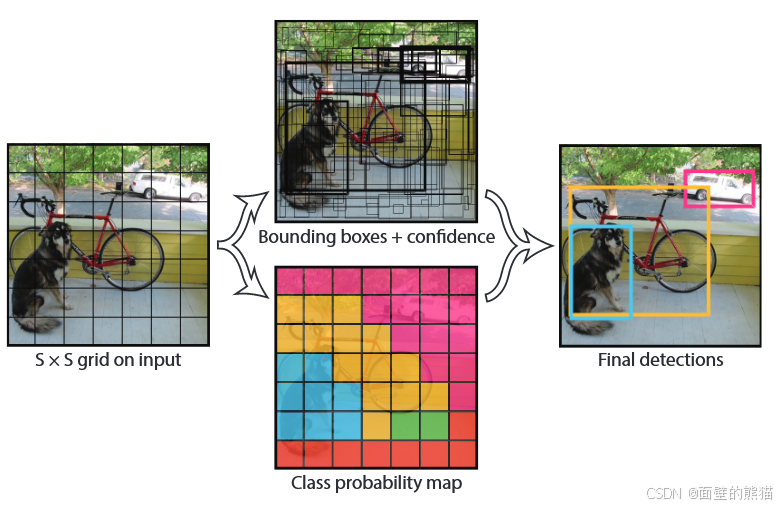
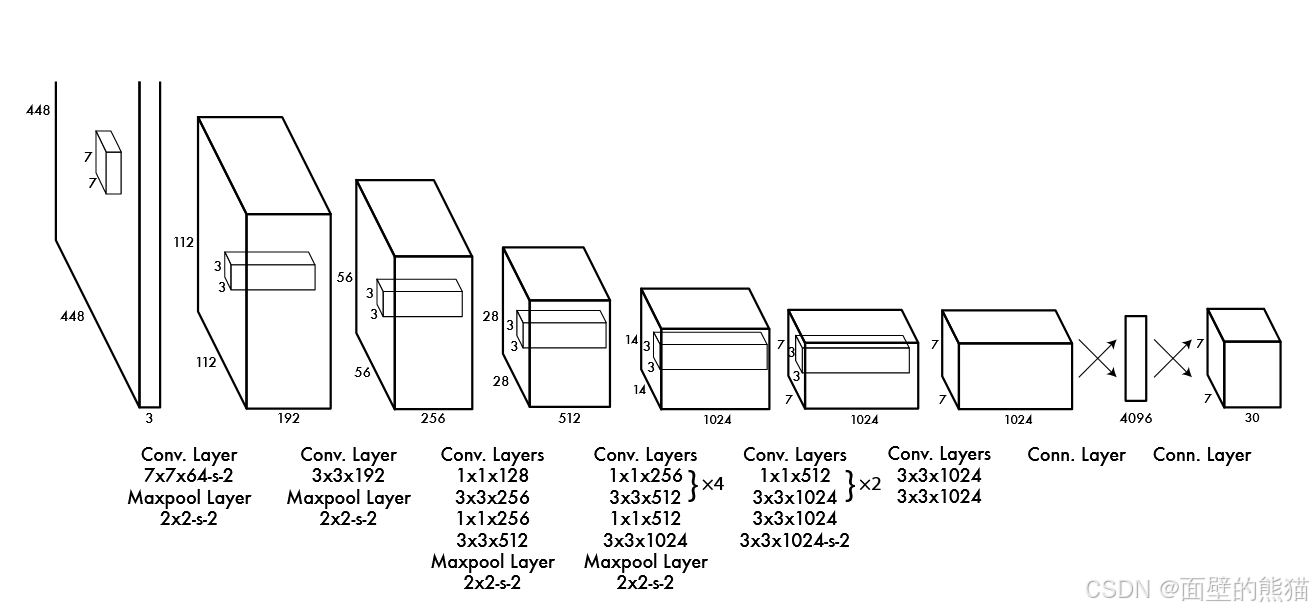
Y O L O v 1 YOLO\ v1 YOLO v1将输入图像分为 S × S S × S S×S 网格。如果对象的中心落入网格单元,则该网格单元负责检测该对象。每个网格单元格预测 B 边界框和这些框的置信度分数。这些置信度分数反映了模型对盒子包含对象的置信度,以及它认为盒子与它预测的准确性。正式地,将置信度定义为 P r O b j e c t ∗ I O U p r e d t r u e Pr_{Object} ∗ IOU_{pred}^{true} PrObject∗IOUpredtrue 。如果该单元格中不存在对象,则置信度分数应为零。否则,我们希望置信度分数等于预测框和基本事实之间的并集交集 ( I O U ) (IOU) (IOU)。每个边界框由 5 个预测组成: x 、 y 、 w 、 h x、y、w、h x、y、w、h和置信度。 ( x , y ) (x, y) (x,y) 坐标表示框相对于网格单元边界的中心。宽度和高度是相对于整个图像进行预测的。最后,置信度预测表示预测框和任何地面实况框之间的 I O U IOU IOU。
每个网格单元还预测 C 条件类概率, P r ( C l a s s i ∣ 对象 ) Pr(Classi|对象) Pr(Classi∣对象)。这些概率取决于包含对象的网格单元格。
为了评估 Y O L O YOLO YOLO 的 P A S C A L V O C PASCAL VOC PASCALVOC,作者使用 S = 7 , B = 2 S = 7,B = 2 S=7,B=2。 P A S C A L V O C PASCAL VOC PASCALVOC 有 20 20 20 个标记类别,因此 C = 20 C = 20 C=20。最终预测是 7 × 7 × 30 7 × 7 × 30 7×7×30 的张量。
SSD
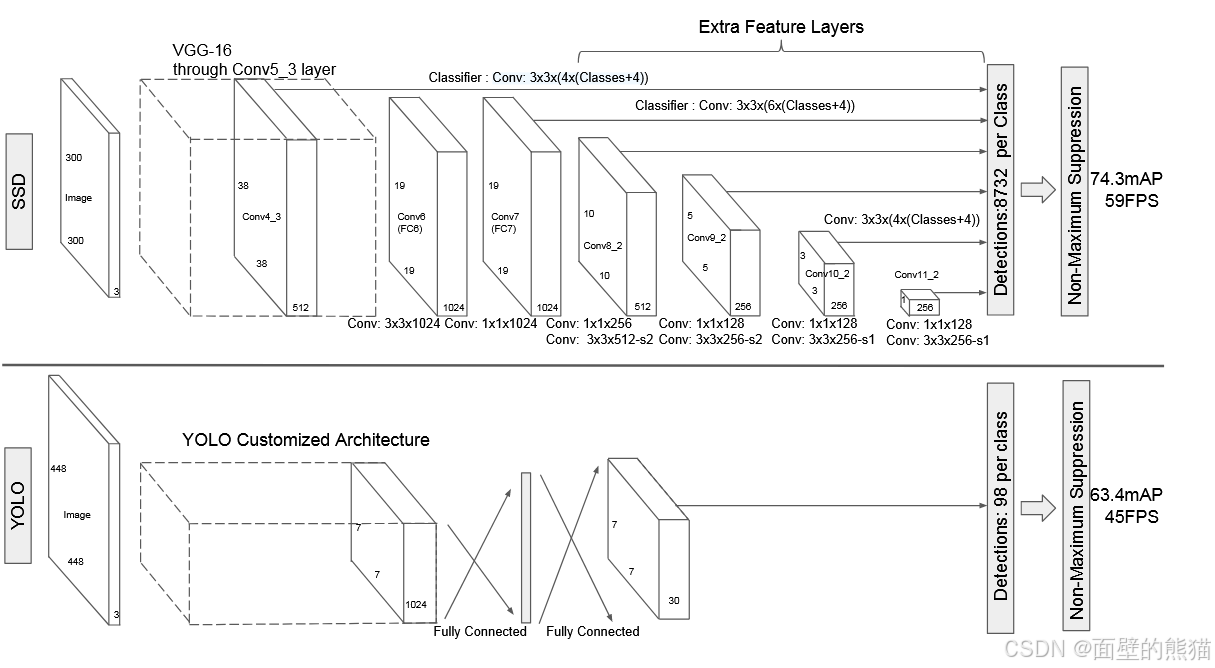
- 采用多尺度特征图用于检测。
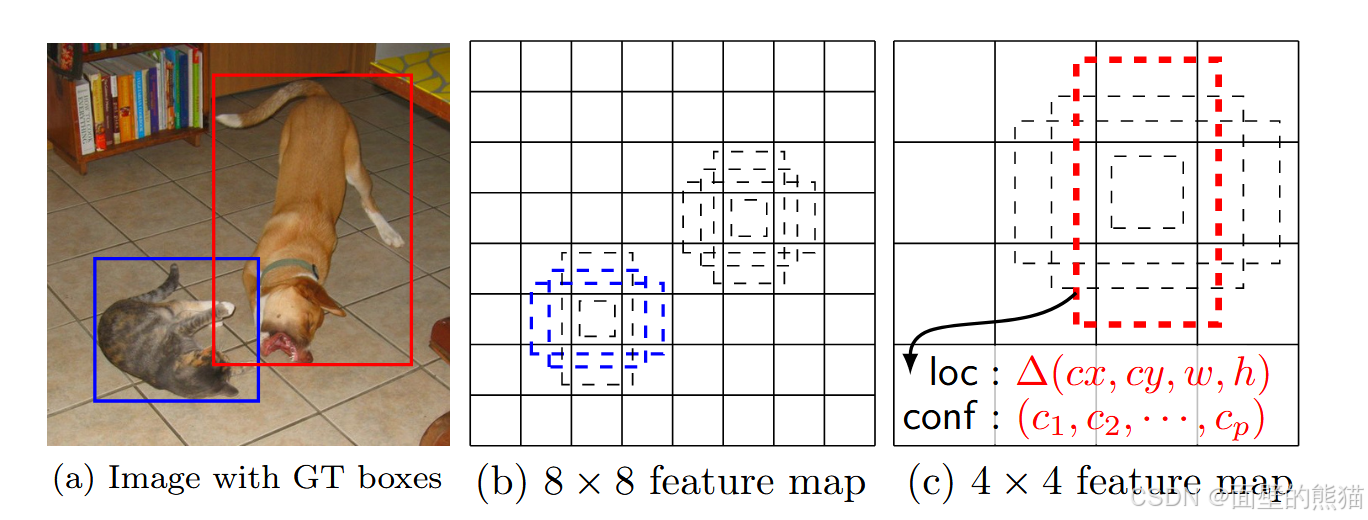
- 设置Default boxes
SSD借鉴了Faster R-CNN中anchor 的理念,每个单元设置尺度或者长宽比不同的Default boxes,预测的边界框(bounding boxes)是以这些Default boxes为基准的,在一定程度上减少训练难度(相当于引入了先验)。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异。
DETR
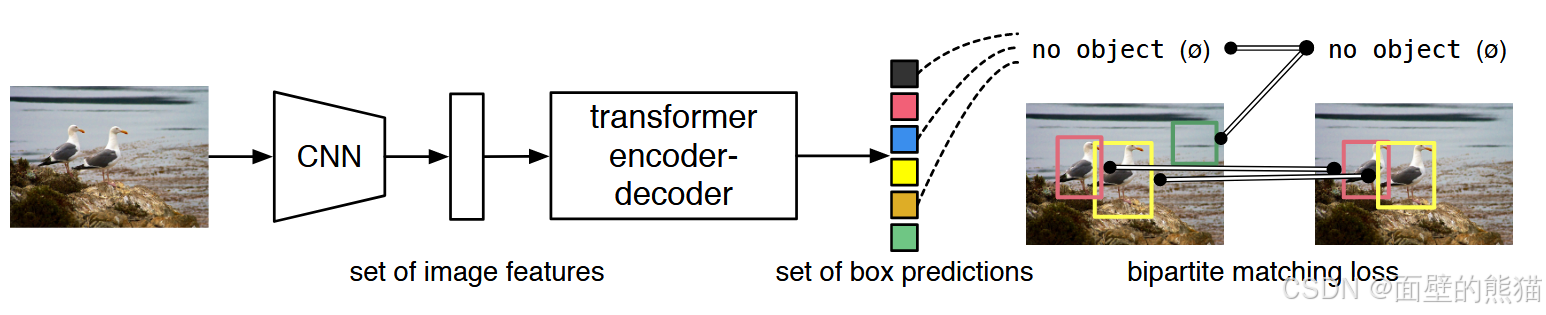
(1)将输入图像利用卷积神经网络(CNN)映射为特征图;
(2)将特征图输入到Transformer模型中,输出N=100个包含物体的区域集合(一个固定数量的集合);
(3)对输出的区域集合 和真实的标签 ,计算两者间的集合相似度(二分图匹配 损失);
(4)利用计算的损失,反向更新卷积神经网络(CNN)和Transformer模型的参数。
GLIP
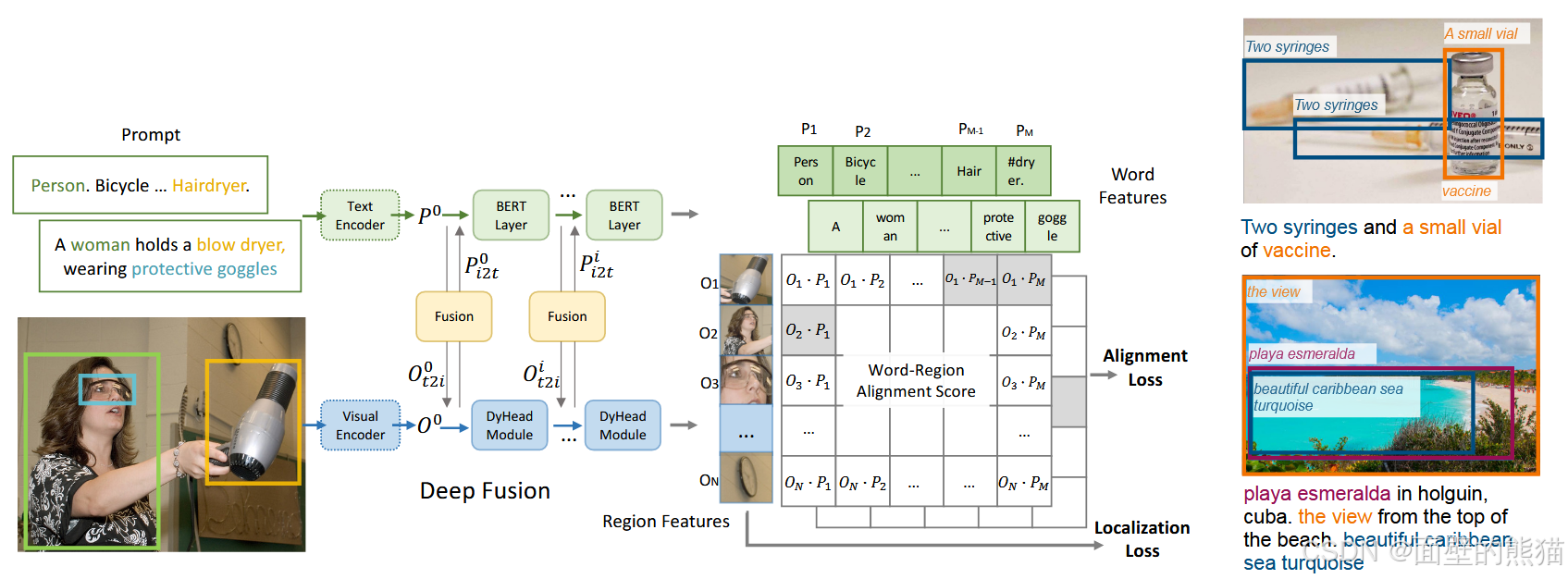
CLIP通过大量的数据学习到了**"image-level** visual representation",GLIP则学习"object level,language aware and visual representation"。
贡献:
- 通过phrase grounding 统一detection 和grounding任务范式。
- 大量的image-text pair数据。
- 下游任务迁移。
方法:
-
双分支结构+late representation fusion(X-MHA,cross attention);

-
localization +alignment loss;
-
scalable 数据 :
1)首先,用金标准训练一个teacher模型;
2)然后,用teacher模型在新数据上进行预测,获取到检测框和对应的名词,也就是伪标注;
3)最后,用一个student模型同时在金标准数据集和伪标注数据集上训练。
Grounding DINO
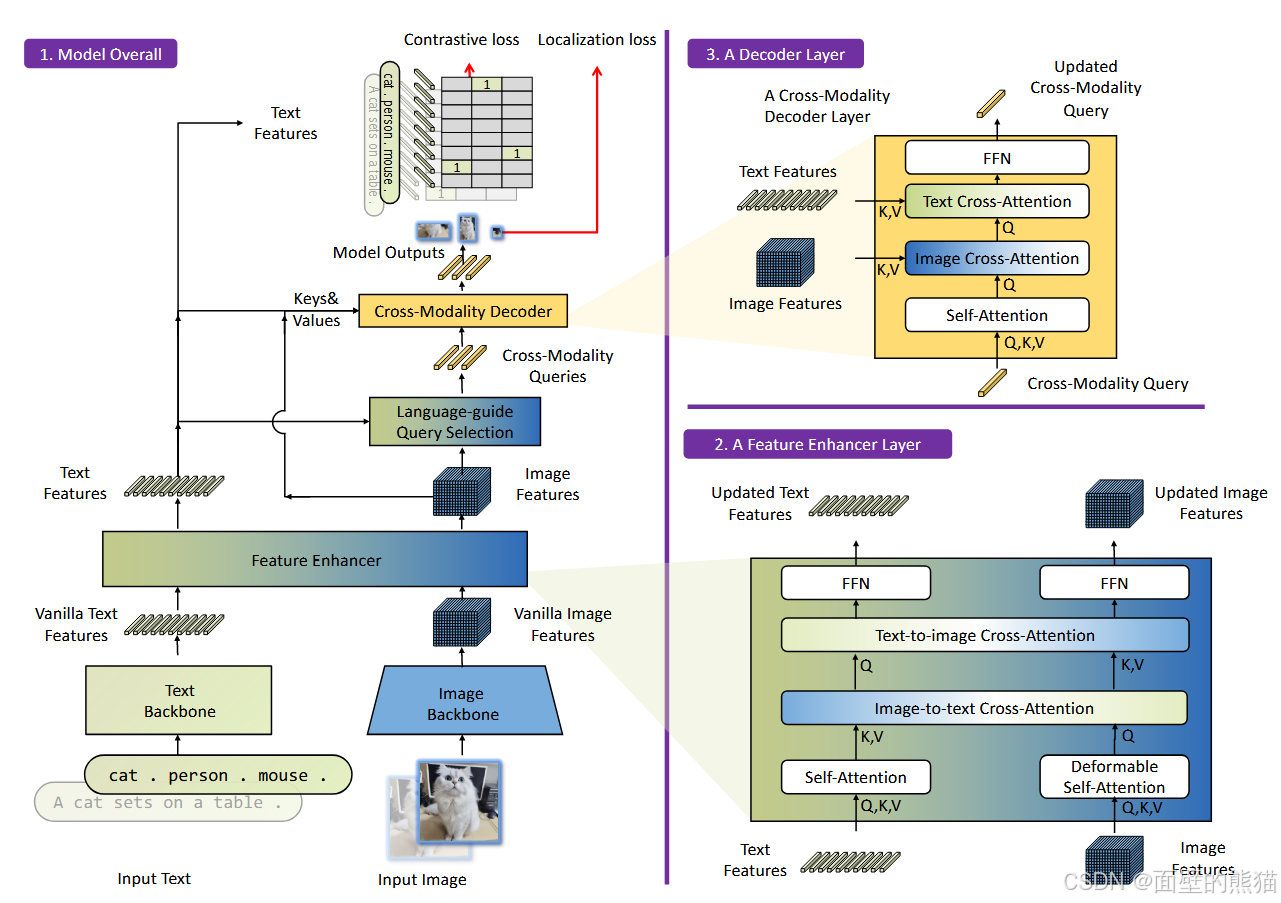
MLLM
参见-->https://blog.csdn.net/weixin_44128977/article/details/151902170?spm=1001.2014.3001.5502