前言
了解了数据库相关的知识,现在来学习数据库、表相关的操作。
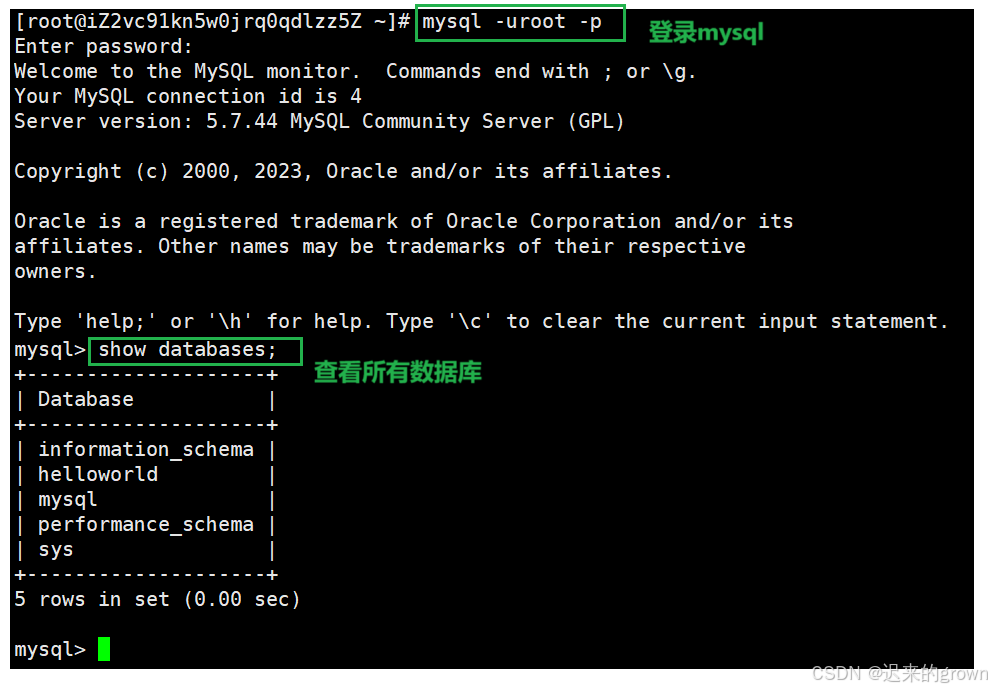
这里登录数据库:
sql
mysql -h IP -P 端口 -u user -p
mysql -uroot -p库的操作
登录数据库以后,可以使用show databases;语句查看所有的数据库。
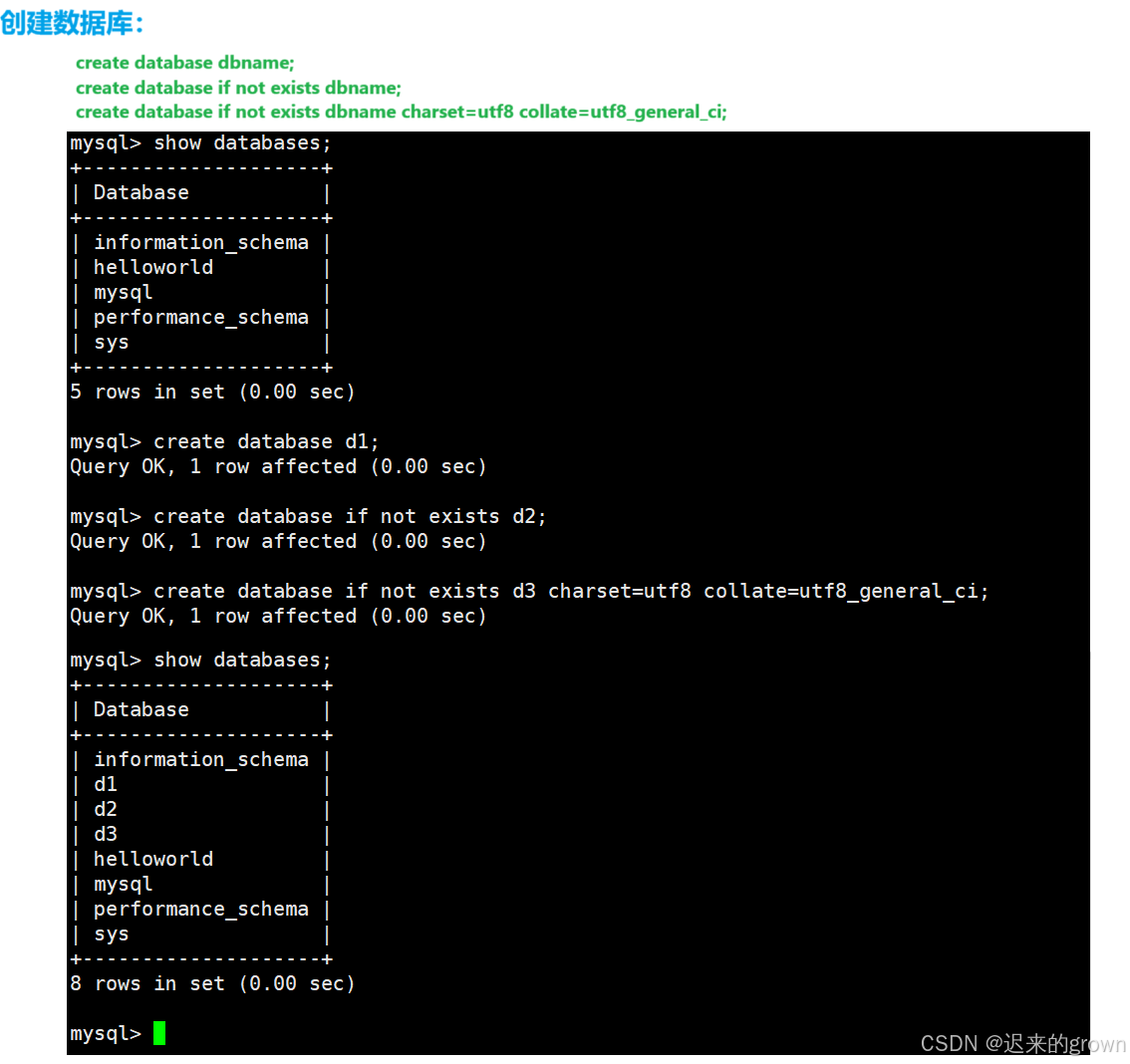
1. 创建库
创建数据库所使用的语句是:create database
sql
create database dbname;
create database if not exists dbname;
create database if not exists dbname charset=utf8 collate=utf8_general_ci;在使用create databases时,也可以带一些选项:
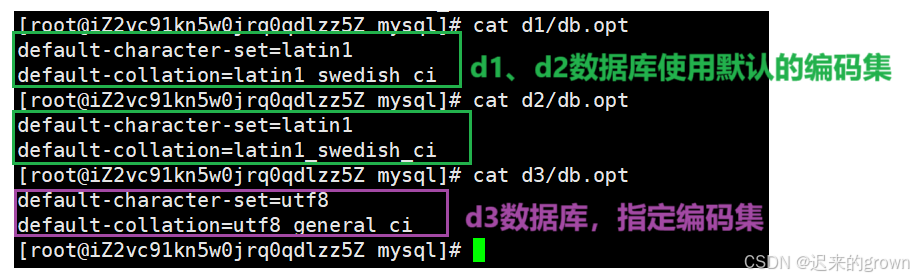
if not exists: 如果数据库不存在,新建数据库。charset=utf8:设置存储字符集为utf8;(也可以设置其他编码集)collate=utf8_general_ci: 设置校验集为utf8_general_ci;(也可以设置其他校验集)这里在配置文件中设置了默认编码集,默认编码集就是设置好的编码集。
2. 字符集
在创建数据库时,存在两个编码集:编码集、校验集。
简单来说:
- 编码集 : 数据库存储数据所使用的编码格式。
- 校验集 : 数据库进行字段比较所使用的编码,也就是读取数据库所采用的编码格式。
数据库的编码集和校验集必须是一样的。
查看系统默认编码集和校验规则
sql
show variables like 'character_set_database';
show variavles like 'collation_database';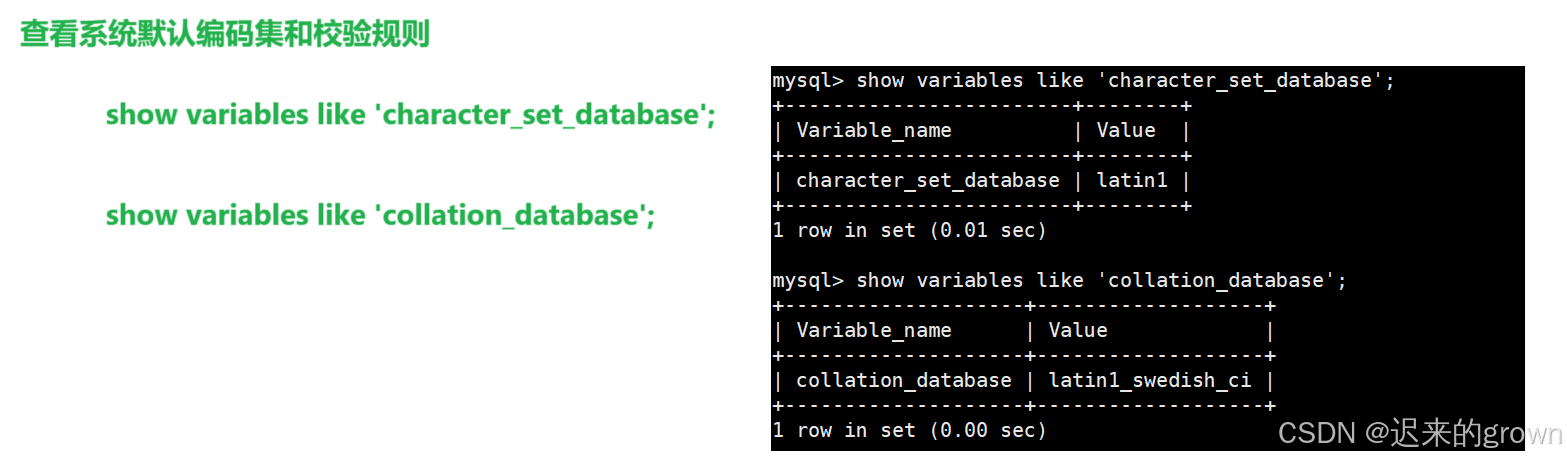
可以看到这里默认编码集为latin1、默认校验规则为latin1_swedish_ci。
所以,在创建数据库时,不指明编码集和校验集,就会使用默认编码集和默认校验集。
查看系统支持的编码集和校验规则
sql
show charset;
show collation;这里就不演示了,系统是支持非常多的编码集和校验规则的。
修改库
对于一个已经存在的数据库,我们能做的修改也就只有修改数据库的字符集了;修改数据库使用的语句:alter database
这里修改刚才创建的d1数据库,将编码集修改为utf8、校验集修改为utf8_general_ci。
sql
alter database d1 character set utf8 collate utf8_general_ci;
这里修改和创建时设置编码集和校验集时:
可以使用
charset=utf8、collate=utf8_general_ci这种形式;也可以使用
character set utf8、collate utf_general_ci这种形式。

3. 查看库
查看所有数据库:
sql
show databases;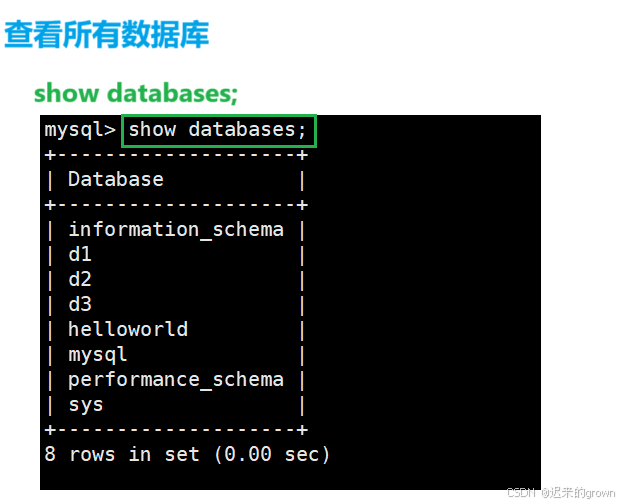
查看创建语句
除了可以查看所有数据库以外,这里还可以显示数据库创建语句。
sql
show create database dbname;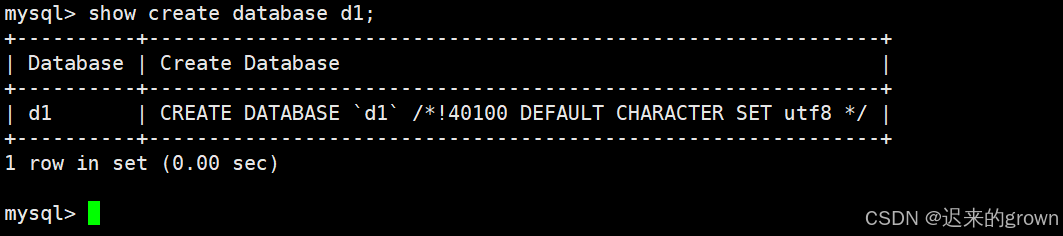
5. 删除库
要删除一个数据库就非常简单了,只需要drop database跟上要删除的数据库名。
sql
drop database dbname;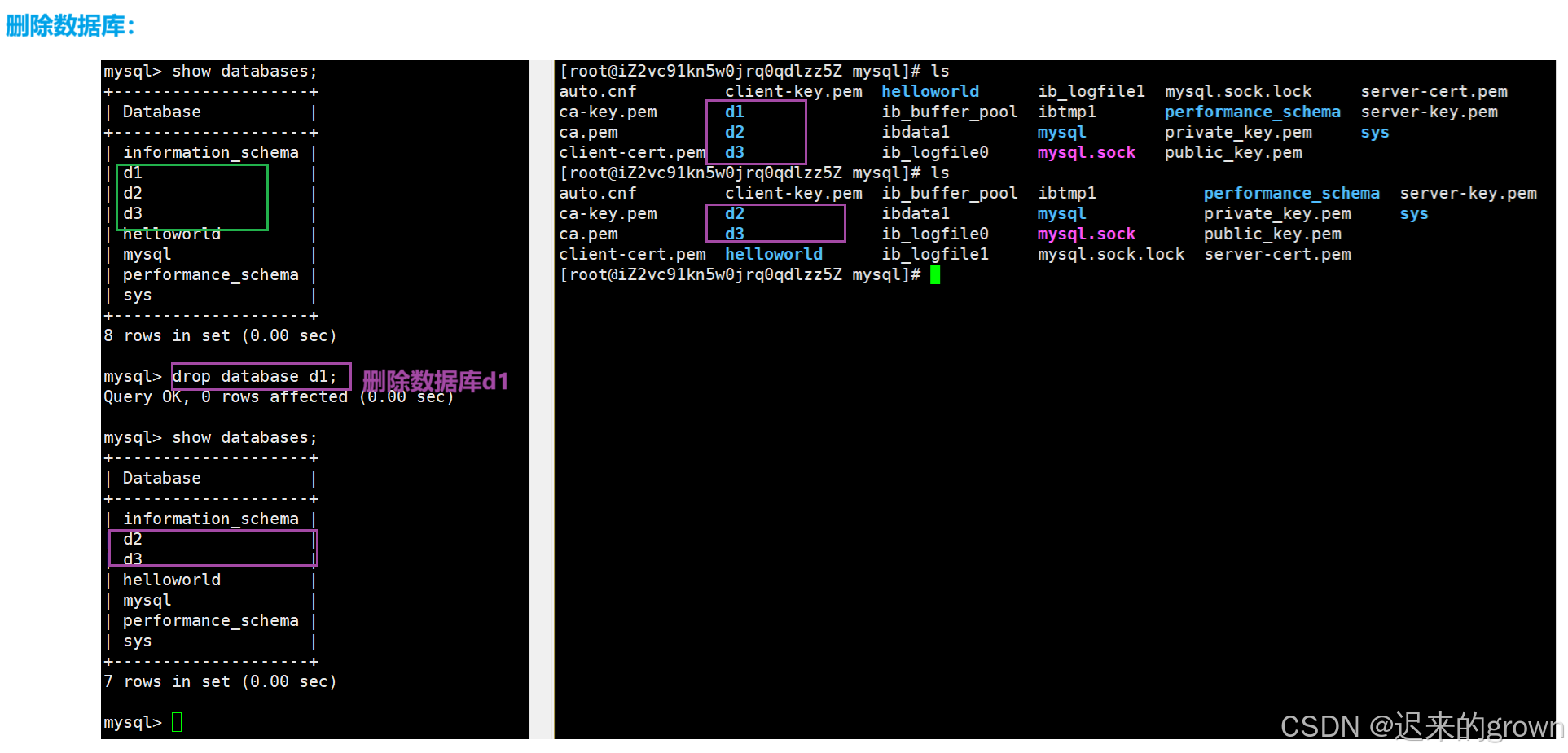
数据库不要随意删除。
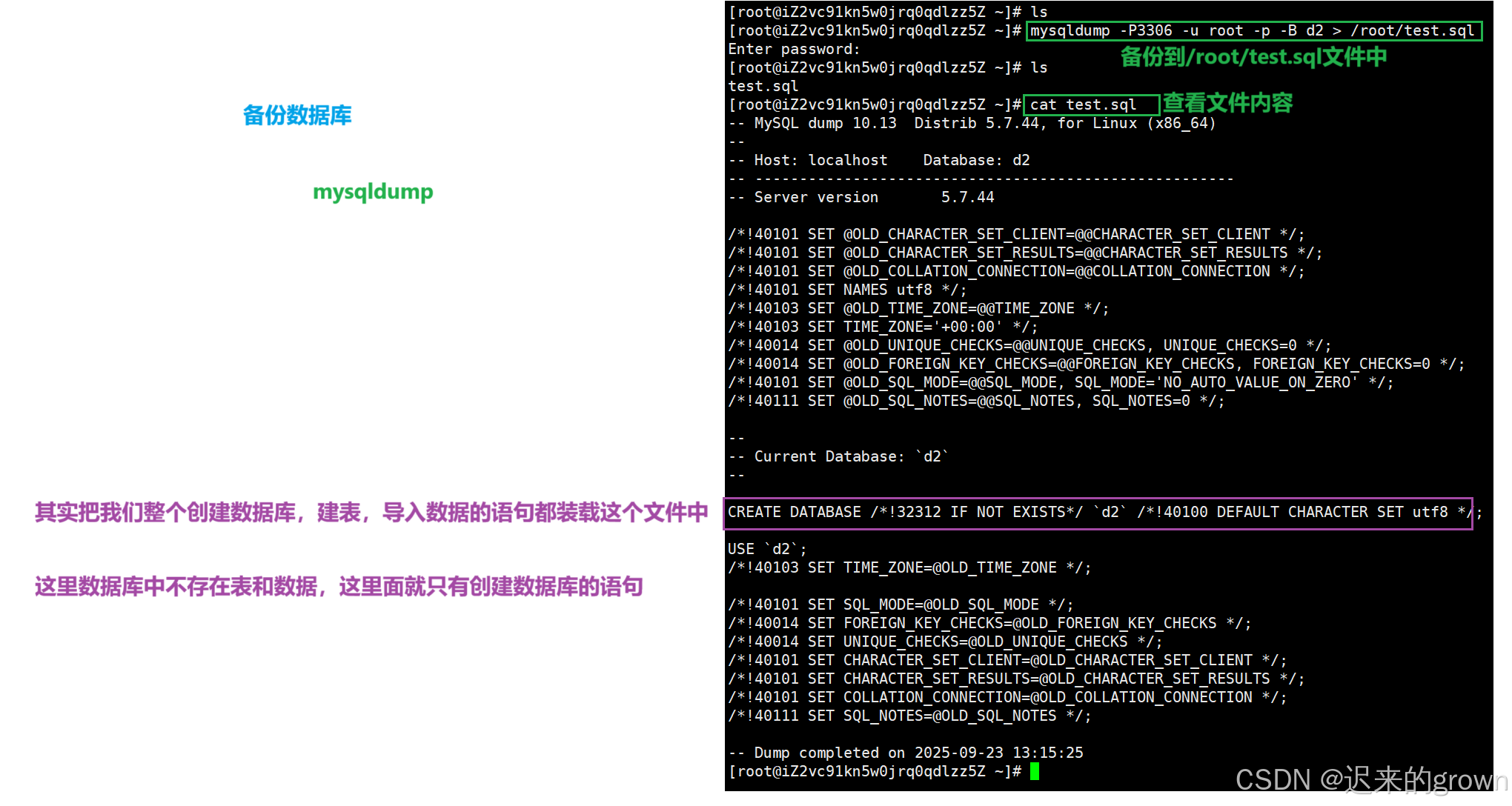
6. 库的备份和恢复
备份:
数据库中存储着数据,数据库是不能随意删除的,但难免有恶意操作;所以,可以将数据库备份,计算数据库被删除了,备份文件还在就可以还原数据库。
bash
mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径mysqldump在按照mysql时是自动安装到系统中的,可以直接使用。
这里备份d2数据库,备份到/root路径下:
shell
mysqldump -P3306 -u root -p -B d2 > /root/test.sql注意:备份是将数据库中数据备份到服务器文件中。
恢复
恢复数据库,要使用到的sql语句:source带上备份文件的路径即可。
sql
source /root/test.sql;
备份数据库,本质就是将整个数据库,建表、导入数据的语句都放到备份文件中。
而恢复数据库,就是将备份文件中的语句执行一遍。
表的操作
了解了数据库的相关操作,现在来看数据表的操作;
创建表,都是在每个数据库中创建的;在创建数据表之前,要先使用数据库use dbname(类似于cd进入目录)。
1. 创建表
要创建一个数据表,要使用create table语句,但在创建表时,要指明字段名和字段类型(列名和要存储数据的类型)。
这里创建一个
student表,其中有3列:name、id和gender。
sql
create table student(
name verchar(20),
id char(10),
gender char(2)
);在创建表时,也可以指明该表使用的编码集和校验集(和创建数据库时一样),不指明就使用和数据库一样的编码集和校验集。
也可以,指明存储引擎(不指明就使用默认的存储引擎)。
sql
create table student(
name verchar(20),
id char(10),
gender char(2)
)charset=utf8 collate=utf8_general_ci engine MYSIAM;此外,在创建表时,也可以给每一列带上相对应的描述。
sql
create table student(
name verchar(20) comment '姓名',
id char(10) comment '学号',
gender char(2) comment '性别'
)charset=utf8 collate=utf8_general_ci engine MYSIAM;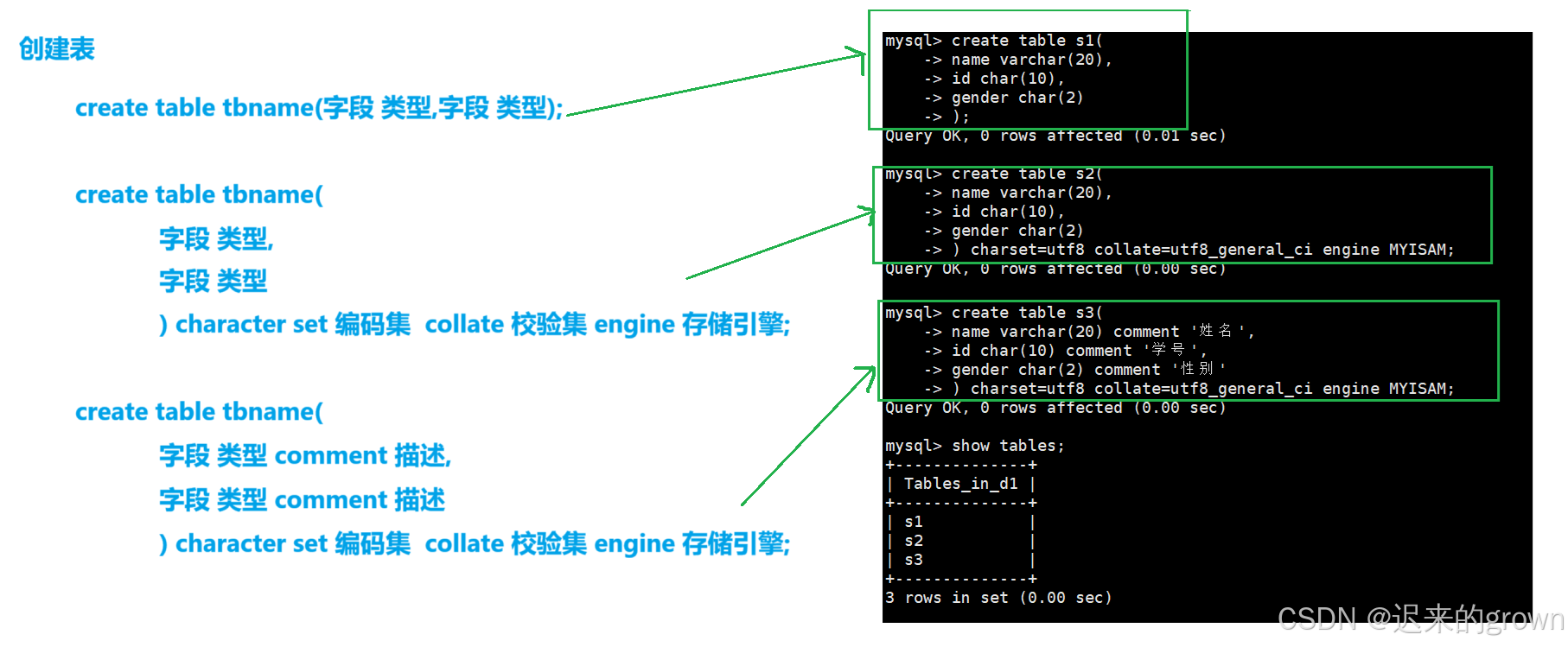
2. 查看表
对于查看表,分为两种:
- 查看表结构
- 查看表中数据
查看表结构
sql
desc tbname;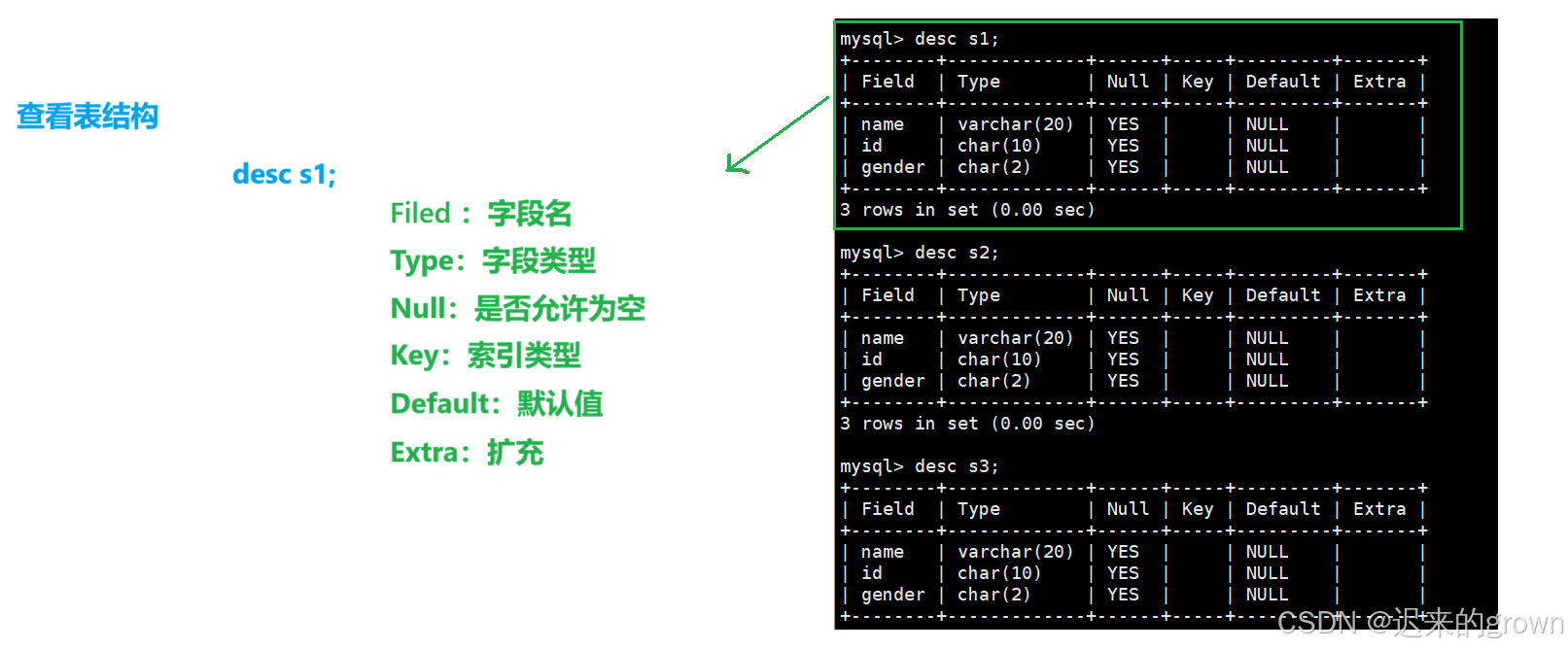
这里查看表结构,表中属性暂时不深入了解。
查看表数据
sql
select * from dbname;select * 查看表中所有数据,这里就随便插入一些数据,方便查看。
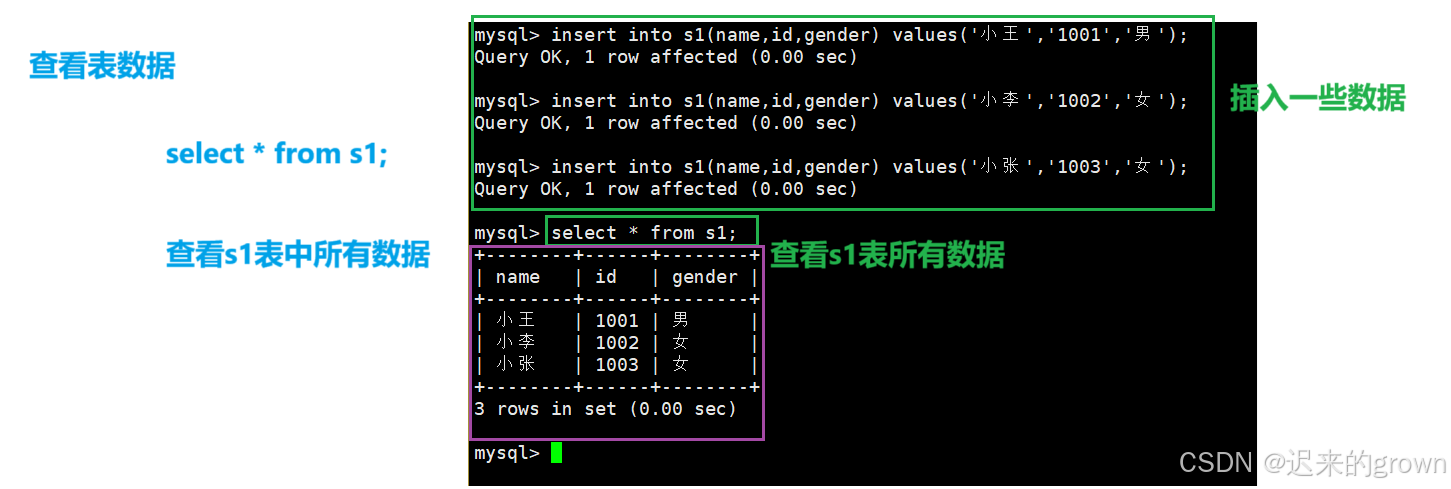
查看创建语句
除了查看表结构、表数据之外,我们还可以查看创建表语句:
show create table tbname;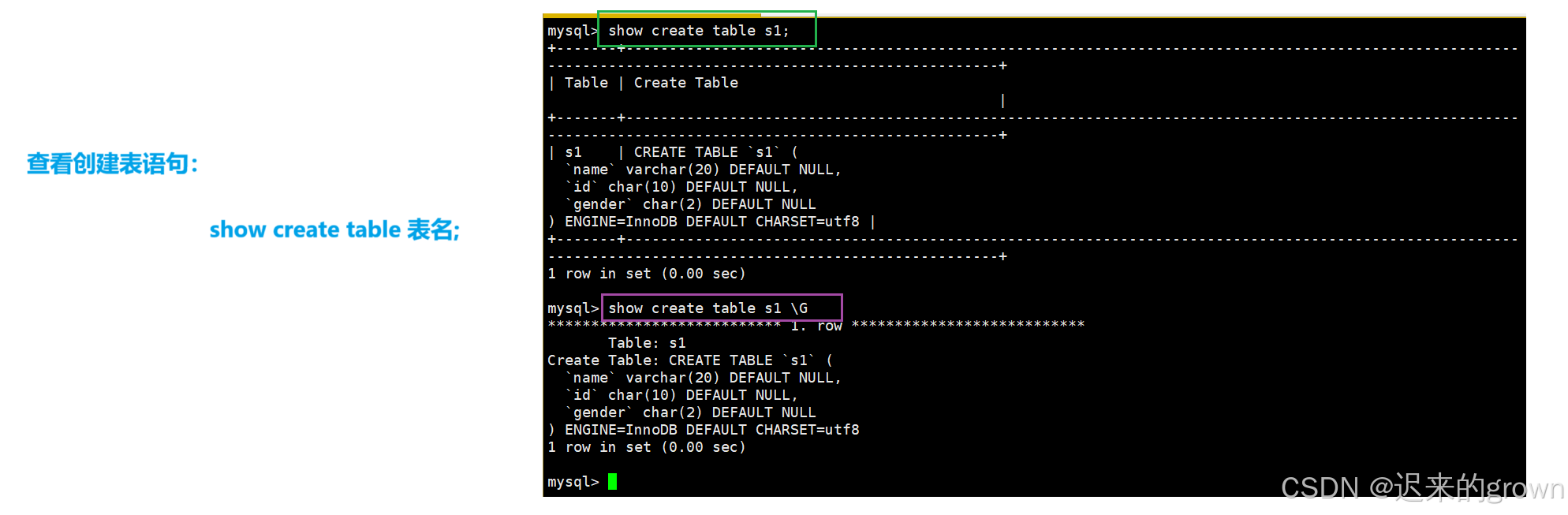
3. 修改表
在实际项目开发中,可能需要修改某个表的结构(例如,修改字段名,字段大小,字段类型,表的字符集类型),修改表存储引擎等等操作。
当然修改表,还可能添加字段,修改字段等等。
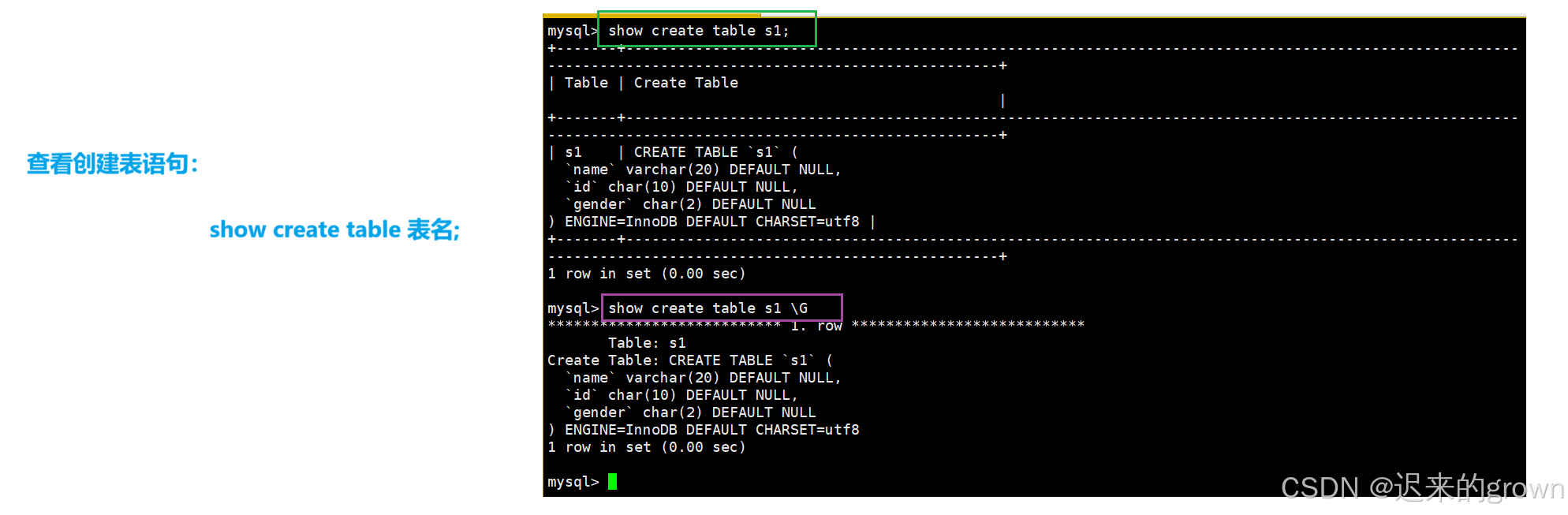
新增字段
所谓新增字段,简单来说就是在表中新增一列。
alter table tbname ADD 字段信息(字段名 字段类型 字段大小 字段描述...)这里在s1表中,新增一个字段tel,类型为verchar(20),字段描述为'电话'。
删除字段
删除字段,就是在表中删除一列;
sql
alter table tbname DROP 字段名;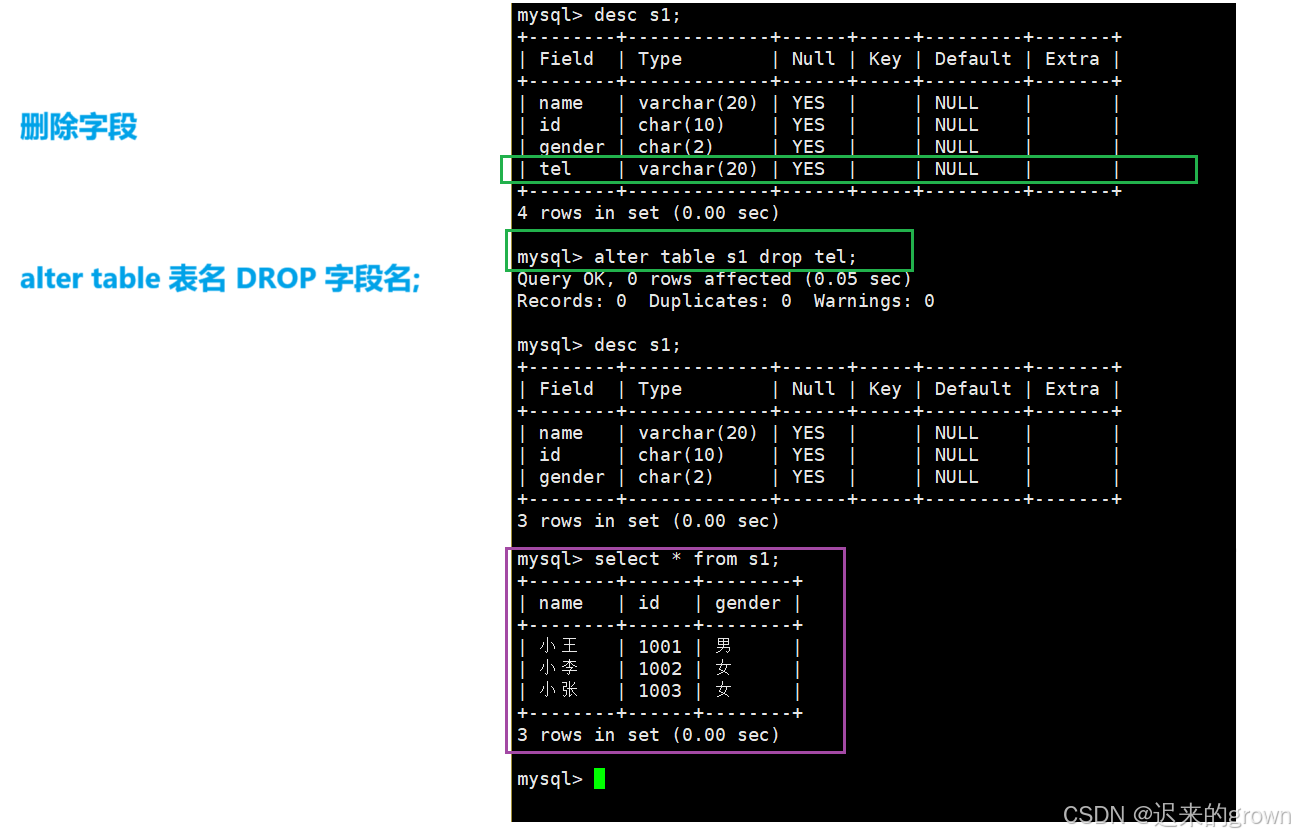
修改字段
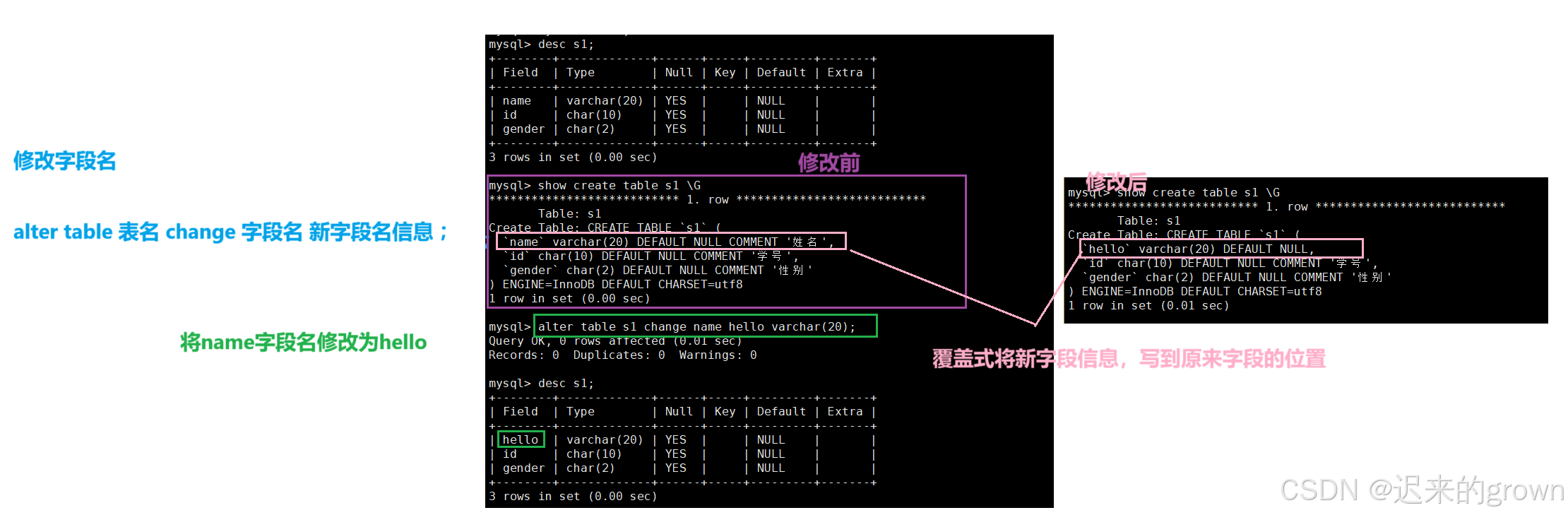
对于修改字段,这里可以修改字段名,也可以修改字段类型。
修改字段名
alter table tbname change 字段名 新字段信息;这里修改字段,无论是修改字段名,还是字段属性都是覆盖式修改之前的字段信息。
修改字段类型
alter table tbname MODIFY 字段名 新字段类型(信息);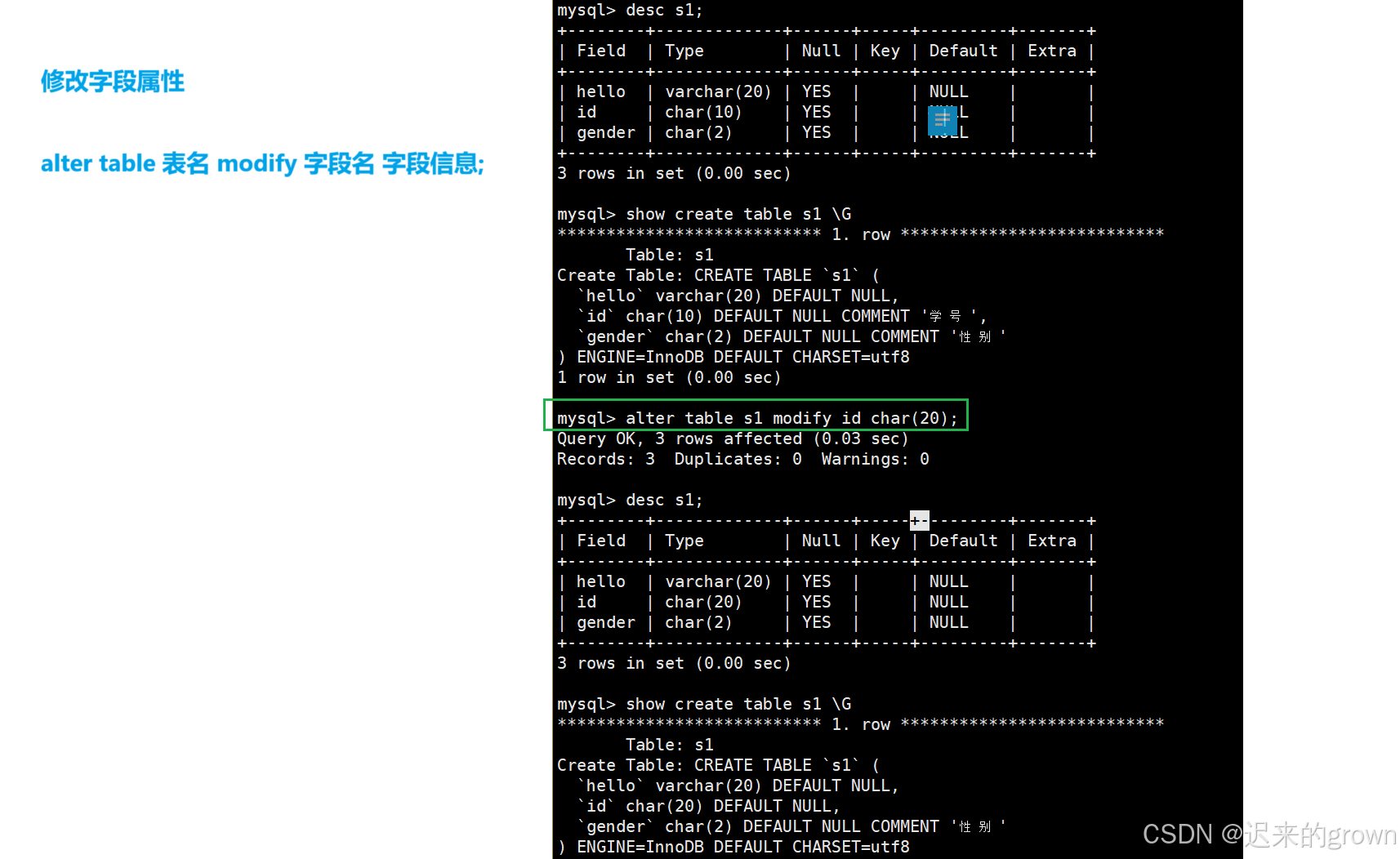
修改表名
除了修改表内字段,我们还可以修改表名:
alter table 表名 rename to 新表名;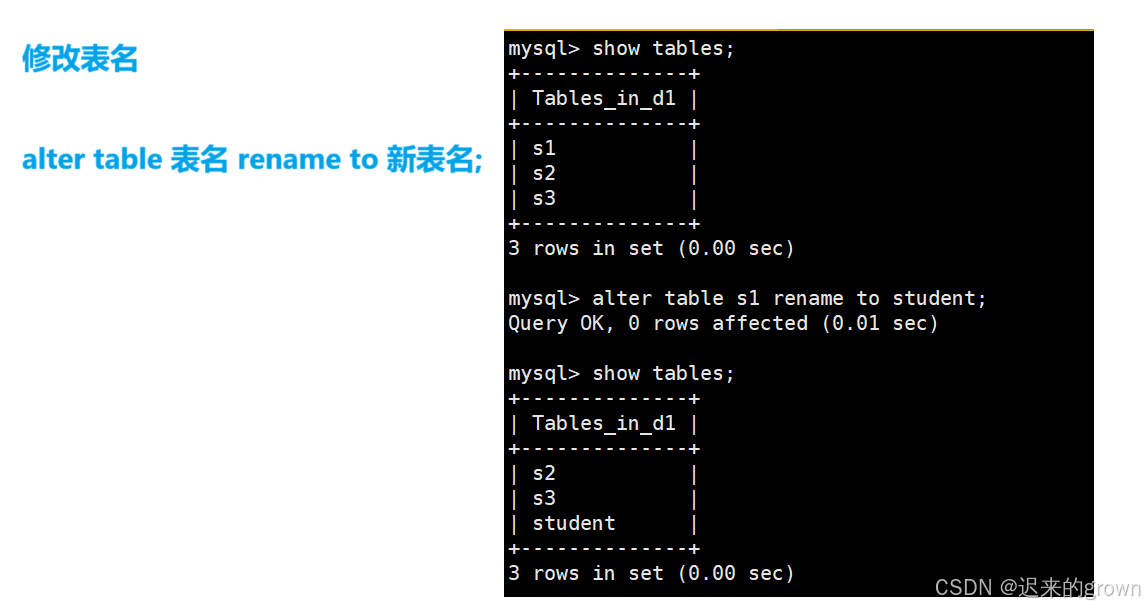
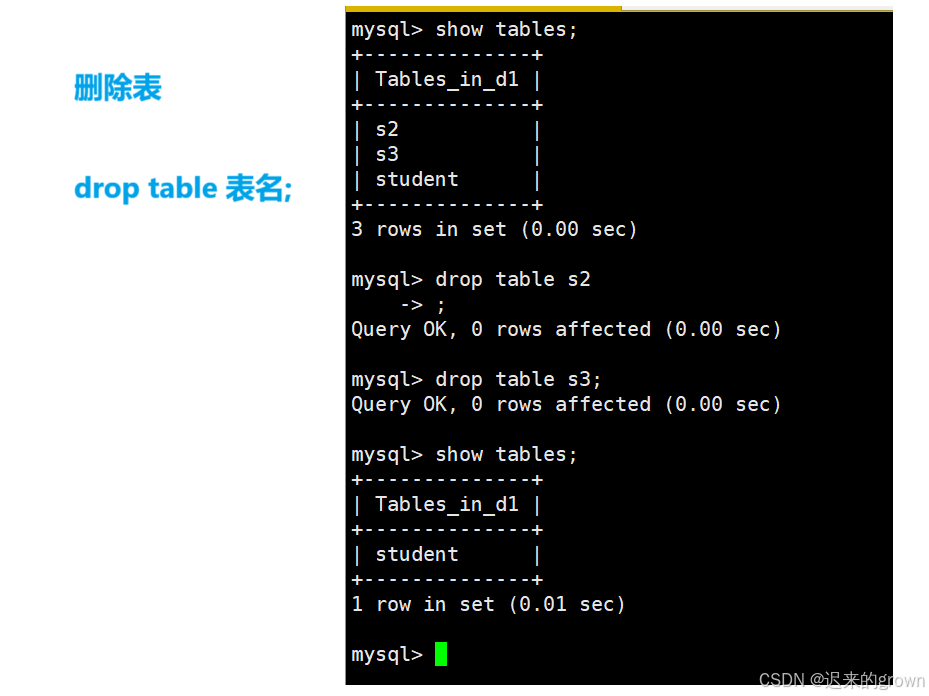
4. 删除表
要删除一个表,使用的语句:drop
sql
drop table 表名;
drop table if exists 表名;这里也可以带上
if exiests,表示判断表存在再删除。
补充
这里补充部分,主要查看:
- 因为字符集的不同,有什么现象?
- 存储引擎之间的差异
字符集
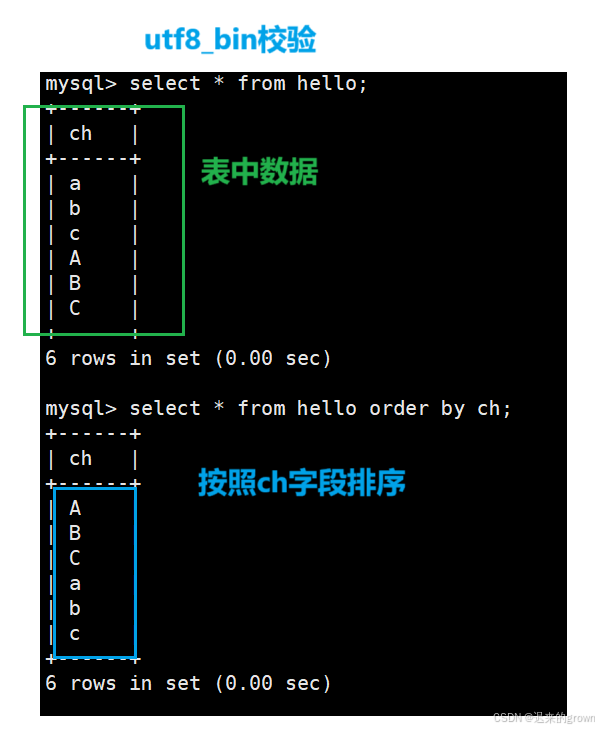
对于字符集不同,这里就列举两个字符集简要规则:
utf8_general_ci:不区分大小写
utf8_bin:区分大小写
对于数据库test1使用utf8、utf_general_ci编码和校验;数据库test2使用utf8、utf8_bin编码和校验
并且在两个数据库中都创建一张表(一个字段),插入一些数据(大写、小写字母)。
utf8_genercal_ci校验规则
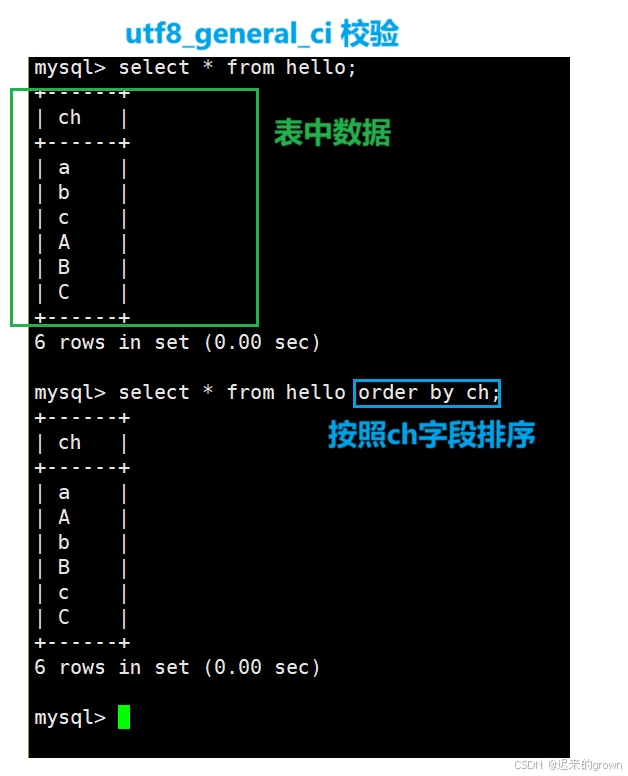
utf8_bin校验规则
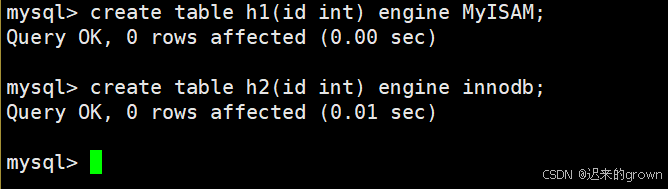
存储引擎的不同:
在创建表时,我们可以指明存储引擎engine,这里来看一下存储引擎之间的差异:
这里创建两张表,h1表使用MYISAM存储引擎,h2使用innodb存储引擎。
通过查看数据库文件中,数据表对应的文件,我们可以发现:
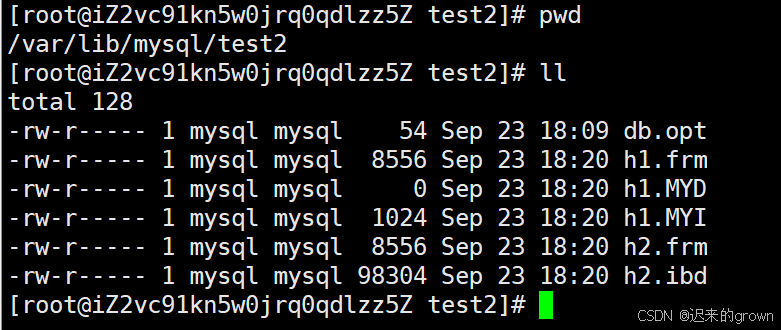
使用MYISAM存储引擎的数据表h1,存在三个文件;
而使用innodb存储引擎的数据表h2,只有两个文件。