
Spark Shuffle:分布式计算的数据重分布艺术
🌟 你好,我是 励志成为糕手 !
🌌 在代码的宇宙中,我是那个追逐优雅与性能的星际旅人。
✨ 每一行代码都是我种下的星光,在逻辑的土壤里生长成璀璨的银河;
🛠️ 每一个算法都是我绘制的星图,指引着数据流动的最短路径;
🔍 每一次调试都是星际对话,用耐心和智慧解开宇宙的谜题。
🚀 准备好开始我们的星际编码之旅了吗?
目录
- [Spark Shuffle:分布式计算的数据重分布艺术](#Spark Shuffle:分布式计算的数据重分布艺术)
-
- 摘要
- [1. Spark Shuffle核心概念](#1. Spark Shuffle核心概念)
-
- [1.1 什么是Shuffle](#1.1 什么是Shuffle)
- [1.2 Shuffle的触发条件](#1.2 Shuffle的触发条件)
- [1.3 Shuffle的生命周期](#1.3 Shuffle的生命周期)
- [2. Shuffle实现机制演进](#2. Shuffle实现机制演进)
-
- [2.1 Hash Shuffle(已废弃)](#2.1 Hash Shuffle(已废弃))
- [2.2 Sort Shuffle](#2.2 Sort Shuffle)
- [2.3 Tungsten Sort Shuffle](#2.3 Tungsten Sort Shuffle)
- [3. Shuffle性能优化策略](#3. Shuffle性能优化策略)
-
- [3.1 分区策略优化](#3.1 分区策略优化)
- [3.2 内存管理优化](#3.2 内存管理优化)
- [3.3 数据倾斜处理](#3.3 数据倾斜处理)
- [4. Shuffle监控与调优](#4. Shuffle监控与调优)
-
- [4.1 Shuffle指标监控](#4.1 Shuffle指标监控)
- [4.2 性能对比分析](#4.2 性能对比分析)
- [4.3 自适应查询执行](#4.3 自适应查询执行)
- [5. 高级Shuffle优化技巧](#5. 高级Shuffle优化技巧)
-
- [5.1 预聚合优化](#5.1 预聚合优化)
- [5.2 广播变量优化](#5.2 广播变量优化)
- [5.3 分区裁剪优化](#5.3 分区裁剪优化)
- [6. 实战案例分析](#6. 实战案例分析)
-
- [6.1 电商订单分析优化](#6.1 电商订单分析优化)
- [6.2 实时流处理Shuffle优化](#6.2 实时流处理Shuffle优化)
- [7. 故障排查与调试](#7. 故障排查与调试)
-
- [7.1 常见Shuffle问题诊断](#7.1 常见Shuffle问题诊断)
- [7.2 性能调优最佳实践](#7.2 性能调优最佳实践)
- 总结
- 参考链接
- 关键词标签
摘要
Spark Shuffle是Apache Spark分布式计算框架中最核心也是最复杂的机制之一,它负责在不同执行阶段之间重新分布数据。当我们执行groupByKey、reduceByKey、join等宽依赖操作时,Spark需要将具有相同key的数据聚集到同一个分区中,这个过程就是Shuffle。
Shuffle操作的性能直接影响整个Spark作业的执行效率。在大数据处理场景中,Shuffle往往是性能瓶颈的主要来源,因为它涉及大量的磁盘I/O、网络传输和内存管理。一个设计不当的Shuffle策略可能导致作业执行时间成倍增长,甚至出现内存溢出等严重问题。
本文将深入剖析Spark Shuffle的工作原理,从底层的数据分区机制到上层的优化策略,帮助开发者理解Shuffle的本质。我们将探讨不同Shuffle实现方式的特点,包括Hash Shuffle、Sort Shuffle和Tungsten Sort Shuffle的演进历程。同时,文章还会提供丰富的代码示例和性能调优技巧,让读者能够在实际项目中有效优化Shuffle性能,提升数据处理效率。
1. Spark Shuffle核心概念
1.1 什么是Shuffle
Shuffle是Spark中数据重新分布的过程,当执行需要跨分区聚合数据的操作时触发。它将上游Stage的输出数据按照特定规则重新分配到下游Stage的各个分区中。
scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
// 创建SparkSession
val spark = SparkSession.builder()
.appName("ShuffleExample")
.master("local[*]")
.config("spark.sql.adaptive.enabled", "true")
.config("spark.sql.adaptive.coalescePartitions.enabled", "true")
.getOrCreate()
import spark.implicits._
// 创建示例数据集
val salesData = Seq(
("北京", "电子产品", 1000),
("上海", "服装", 800),
("北京", "服装", 600),
("广州", "电子产品", 1200),
("上海", "电子产品", 900),
("广州", "服装", 700)
).toDF("city", "category", "amount")
// 触发Shuffle的操作:按城市分组聚合
val cityStats = salesData
.groupBy("city")
.agg(
sum("amount").as("total_amount"),
count("*").as("order_count"),
avg("amount").as("avg_amount")
)
.orderBy(desc("total_amount"))
cityStats.show()上述代码中的groupBy操作会触发Shuffle,因为需要将相同城市的数据聚集到同一个分区进行聚合计算。
1.2 Shuffle的触发条件
scala
// 1. 聚合操作触发Shuffle
val wordCounts = textRDD
.flatMap(_.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _) // 触发Shuffle
// 2. 连接操作触发Shuffle
val userOrders = usersDF
.join(ordersDF, "user_id") // 触发Shuffle
// 3. 重分区操作触发Shuffle
val repartitionedDF = dataDF
.repartition(10, col("partition_key")) // 触发Shuffle
// 4. 排序操作触发Shuffle
val sortedData = salesDF
.orderBy("amount") // 触发Shuffle1.3 Shuffle的生命周期
Map阶段 Shuffle Write 数据分区 磁盘存储 网络传输 Shuffle Read Reduce阶段 内存缓冲 溢写到磁盘 文件合并
图1:Spark Shuffle生命周期流程图
2. Shuffle实现机制演进
2.1 Hash Shuffle(已废弃)
Hash Shuffle是Spark早期的实现方式,每个Map任务为每个Reduce任务创建一个文件。
scala
// Hash Shuffle的核心逻辑示例
class HashShuffleWriter[K, V](
shuffleId: Int,
mapId: Int,
numReducers: Int
) {
// 为每个reducer创建一个writer
private val writers = Array.fill(numReducers) {
new DiskBlockObjectWriter(
file = getShuffleFile(shuffleId, mapId, _),
serializer = serializer,
bufferSize = bufferSize
)
}
def write(records: Iterator[Product2[K, V]]): Unit = {
records.foreach { record =>
val partitionId = partitioner.getPartition(record._1)
writers(partitionId).write(record._1, record._2)
}
}
def stop(): Array[Long] = {
writers.map(_.commitAndGet().bytesWritten)
}
}Hash Shuffle的问题:
- 文件数量过多:M个Map任务 × R个Reduce任务 = M×R个文件
- 大量小文件导致文件系统压力
- 随机I/O性能差
2.2 Sort Shuffle
Sort Shuffle通过排序减少文件数量,每个Map任务只产生一个数据文件和一个索引文件。
scala
// Sort Shuffle的实现示例
class SortShuffleWriter[K, V, C](
shuffleId: Int,
mapId: Int,
context: TaskContext,
partitioner: Partitioner
) extends ShuffleWriter[K, V] {
private val sorter = new ExternalSorter[K, V, C](
context,
aggregator = None,
Some(partitioner),
ordering = None,
serializer = serializer
)
override def write(records: Iterator[Product2[K, V]]): Unit = {
// 将数据插入到外部排序器中
sorter.insertAll(records)
}
override def stop(success: Boolean): Option[MapStatus] = {
try {
val outputFile = shuffleBlockResolver.getDataFile(shuffleId, mapId)
val indexFile = shuffleBlockResolver.getIndexFile(shuffleId, mapId)
// 将排序后的数据写入文件
val partitionLengths = sorter.writePartitionedFile(
shuffleId, mapId, outputFile)
// 写入索引文件
shuffleBlockResolver.writeIndexFileAndCommit(
shuffleId, mapId, partitionLengths, indexFile)
Some(MapStatus(blockManager.shuffleServerId, partitionLengths))
} finally {
sorter.stop()
}
}
}Sort Shuffle的核心优势在于通过排序机制大幅减少了文件数量,从Hash Shuffle的M×R个文件降低到2×M个文件(每个Map任务产生一个数据文件和一个索引文件)。这种设计不仅减轻了文件系统的压力,还提高了磁盘I/O的顺序性。
在Sort Shuffle中,ExternalSorter扮演着关键角色,它能够在内存不足时自动将数据溢写到磁盘,并在最终阶段将所有溢写文件合并成一个有序的输出文件。索引文件记录了每个分区在数据文件中的偏移量和长度,使得下游任务能够快速定位和读取所需的数据分区。这种设计在处理大规模数据时表现出色,特别是当Shuffle数据量超过内存容量时,Sort Shuffle能够优雅地处理数据溢写和合并过程,保持良好的性能表现。
2.3 Tungsten Sort Shuffle
Tungsten Sort Shuffle进一步优化了内存管理和序列化性能。
scala
// Tungsten Sort Shuffle的关键优化
class UnsafeShuffleWriter[K, V](
blockManager: BlockManager,
shuffleBlockResolver: IndexShuffleBlockResolver,
taskMemoryManager: TaskMemoryManager,
shuffleId: Int,
mapId: Int,
taskContext: TaskContext,
sparkConf: SparkConf
) extends ShuffleWriter[K, V] {
private val sorter = new UnsafeShuffleExternalSorter(
taskMemoryManager,
blockManager,
taskContext,
initialSize = 4096,
pageSizeBytes = pageSizeBytes,
numElementsForSpillThreshold = numElementsForSpillThreshold
)
override def write(records: Iterator[Product2[K, V]]): Unit = {
while (records.hasNext) {
val record = records.next()
val serializedRecord = serializer.serialize(record)
val partitionId = partitioner.getPartition(record._1)
// 使用unsafe操作直接操作内存
sorter.insertRecord(
serializedRecord.array(),
serializedRecord.offset(),
serializedRecord.length(),
partitionId
)
}
}
}Tungsten Sort Shuffle代表了Spark在内存管理和执行效率方面的重大突破。与传统的Sort Shuffle相比,Tungsten Sort Shuffle最显著的改进在于采用了基于页面的内存管理模型,将数据以紧凑的二进制格式存储在堆外内存中,避免了Java对象的开销和垃圾回收压力。
在排序过程中,Tungsten使用指针数组而非对象引用来管理数据,每个指针包含了记录的内存地址和分区信息,这种设计大幅减少了内存占用并提高了缓存局部性。更重要的是,Tungsten引入了代码生成技术,在运行时动态生成针对特定数据类型优化的排序代码,消除了虚函数调用的开销。
此外,Tungsten Sort Shuffle还支持溢写文件的高效合并,通过优先队列算法实现多路归并排序,并利用操作系统的零拷贝技术减少数据在内核态和用户态之间的拷贝次数。这些优化使得Tungsten Sort Shuffle在处理大规模数据时表现出色,特别是在CPU密集型的排序和聚合操作中,性能提升可达2-5倍。
ps:这里放一个讲解spark shuffle机制的说明博客,也可以看看加深印象:https://cloud.tencent.com/developer/article/2014088
3. Shuffle性能优化策略
3.1 分区策略优化
scala
import org.apache.spark.HashPartitioner
import org.apache.spark.RangePartitioner
// 自定义分区器
class CustomPartitioner(numPartitions: Int) extends Partitioner {
override def getPartition(key: Any): Int = {
key match {
case str: String =>
// 基于字符串长度分区,避免数据倾斜
(str.length % numPartitions).abs
case num: Int =>
// 基于数值范围分区
(num / 1000) % numPartitions
case _ =>
key.hashCode() % numPartitions
}
}
}
// 使用自定义分区器
val customPartitionedRDD = dataRDD
.partitionBy(new CustomPartitioner(100))
.cache() // 缓存分区后的数据
// 范围分区器适用于有序数据
val rangePartitionedRDD = sortedRDD
.partitionBy(new RangePartitioner(50, sortedRDD))3.2 内存管理优化
scala
// Spark配置优化
val optimizedSpark = SparkSession.builder()
.appName("OptimizedShuffleApp")
.config("spark.sql.adaptive.enabled", "true")
.config("spark.sql.adaptive.coalescePartitions.enabled", "true")
.config("spark.sql.adaptive.skewJoin.enabled", "true")
// Shuffle相关配置
.config("spark.shuffle.compress", "true")
.config("spark.shuffle.spill.compress", "true")
.config("spark.shuffle.file.buffer", "64k")
.config("spark.shuffle.io.retryWait", "5s")
.config("spark.shuffle.io.maxRetries", "5")
// 内存管理配置
.config("spark.executor.memory", "4g")
.config("spark.executor.memoryFraction", "0.8")
.config("spark.shuffle.memoryFraction", "0.3")
.config("spark.storage.memoryFraction", "0.5")
.getOrCreate()在Shuffle过程中,执行内存主要用于排序操作和聚合计算,而存储内存则用于缓存中间结果。当执行内存不足时,系统会触发溢写机制,将部分数据写入磁盘以释放内存空间。合理配置溢写阈值和缓冲区大小能够显著减少磁盘I/O次数。
堆外内存的使用进一步提升了内存管理效率,它绕过了JVM的垃圾回收机制,减少了GC停顿对Shuffle性能的影响。通过精确控制内存分配和回收,堆外内存能够提供更稳定的性能表现。此外,内存预分配策略和内存池技术的应用,有效避免了频繁的内存申请和释放操作,进一步优化了整体性能。
3.3 数据倾斜处理
scala
// 检测数据倾斜
def detectDataSkew(df: DataFrame, keyColumn: String): DataFrame = {
val skewStats = df
.groupBy(keyColumn)
.count()
.agg(
max("count").as("max_count"),
min("count").as("min_count"),
avg("count").as("avg_count"),
stddev("count").as("stddev_count")
)
skewStats.show()
// 返回倾斜的key
df.groupBy(keyColumn)
.count()
.filter(col("count") > lit(10000)) // 阈值可调整
.orderBy(desc("count"))
}
// 处理数据倾斜:加盐技术
def saltedJoin(leftDF: DataFrame, rightDF: DataFrame,
joinKey: String, saltRange: Int = 100): DataFrame = {
// 为左表添加随机盐值
val saltedLeftDF = leftDF
.withColumn("salt", (rand() * saltRange).cast("int"))
.withColumn("salted_key", concat(col(joinKey), lit("_"), col("salt")))
// 为右表扩展盐值
val saltedRightDF = rightDF
.withColumn("salt", explode(array((0 until saltRange).map(lit): _*)))
.withColumn("salted_key", concat(col(joinKey), lit("_"), col("salt")))
// 执行join
saltedLeftDF
.join(saltedRightDF, "salted_key")
.drop("salt", "salted_key")
}4. Shuffle监控与调优
4.1 Shuffle指标监控
scala
// 自定义Shuffle监控器
class ShuffleMetricsCollector(sparkContext: SparkContext) {
def collectShuffleMetrics(): Map[String, Any] = {
val statusTracker = sparkContext.statusTracker
val executorInfos = statusTracker.getExecutorInfos
val shuffleMetrics = executorInfos.map { executor =>
Map(
"executorId" -> executor.executorId,
"shuffleReadBytes" -> executor.peakMemoryMetrics.map(_.shuffleReadBytes).getOrElse(0L),
"shuffleWriteBytes" -> executor.peakMemoryMetrics.map(_.shuffleWriteBytes).getOrElse(0L),
"shuffleReadRecords" -> executor.peakMemoryMetrics.map(_.shuffleReadRecords).getOrElse(0L),
"shuffleWriteRecords" -> executor.peakMemoryMetrics.map(_.shuffleWriteRecords).getOrElse(0L)
)
}
Map(
"totalExecutors" -> executorInfos.length,
"shuffleMetrics" -> shuffleMetrics
)
}
def printShuffleReport(): Unit = {
val metrics = collectShuffleMetrics()
println(s"=== Shuffle Performance Report ===")
println(s"Total Executors: ${metrics("totalExecutors")}")
val shuffleData = metrics("shuffleMetrics").asInstanceOf[Array[Map[String, Any]]]
val totalReadBytes = shuffleData.map(_("shuffleReadBytes").asInstanceOf[Long]).sum
val totalWriteBytes = shuffleData.map(_("shuffleWriteBytes").asInstanceOf[Long]).sum
println(f"Total Shuffle Read: ${totalReadBytes / 1024.0 / 1024.0}%.2f MB")
println(f"Total Shuffle Write: ${totalWriteBytes / 1024.0 / 1024.0}%.2f MB")
}
}4.2 性能对比分析
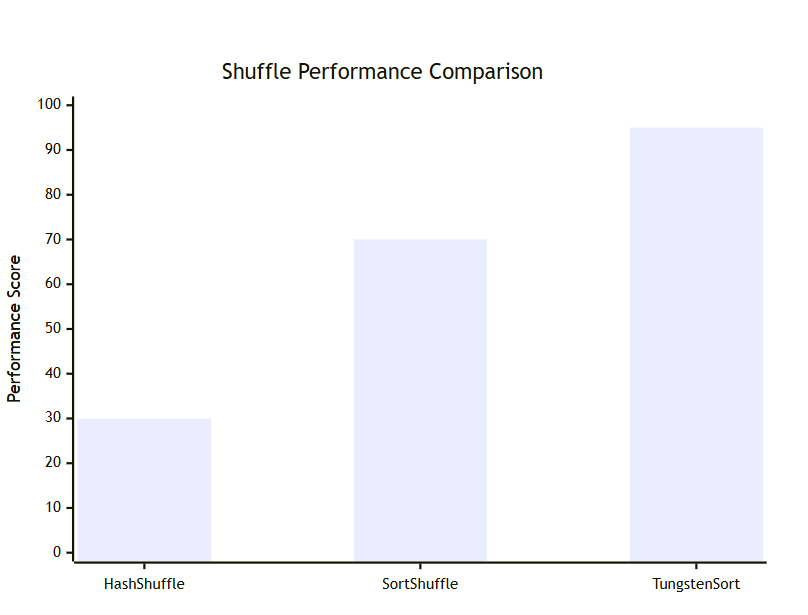
图2:不同Shuffle实现的性能对比图
| Shuffle类型 | 文件数量 | 内存使用 | CPU开销 | 网络I/O | 适用场景 |
|---|---|---|---|---|---|
| Hash Shuffle | M×R | 中等 | 低 | 高 | 小规模数据 |
| Sort Shuffle | 2×M | 高 | 中等 | 中等 | 中大规模数据 |
| Tungsten Sort | 2×M | 低 | 低 | 低 | 大规模数据 |
4.3 自适应查询执行
scala
// 启用AQE的配置示例
val aqeEnabledSpark = SparkSession.builder()
.config("spark.sql.adaptive.enabled", "true")
.config("spark.sql.adaptive.coalescePartitions.enabled", "true")
.config("spark.sql.adaptive.coalescePartitions.minPartitionNum", "1")
.config("spark.sql.adaptive.coalescePartitions.initialPartitionNum", "200")
.config("spark.sql.adaptive.advisoryPartitionSizeInBytes", "128MB")
.config("spark.sql.adaptive.skewJoin.enabled", "true")
.config("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "5")
.config("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", "256MB")
.getOrCreate()
// AQE优化示例
def demonstrateAQE(): Unit = {
val largeDF = spark.range(1000000)
.withColumn("key", col("id") % 1000)
.withColumn("value", rand())
val smallDF = spark.range(1000)
.withColumn("key", col("id"))
.withColumn("info", lit("metadata"))
// AQE会自动优化这个join
val result = largeDF
.join(smallDF, "key")
.groupBy("key")
.agg(
count("*").as("count"),
avg("value").as("avg_value")
)
result.explain(true) // 查看执行计划
result.show(10)
}5. 高级Shuffle优化技巧
5.1 预聚合优化
scala
// 使用combineByKey进行预聚合
def optimizedWordCount(textRDD: RDD[String]): RDD[(String, Int)] = {
textRDD
.flatMap(_.split("\\s+"))
.filter(_.nonEmpty)
.map(word => (word, 1))
.combineByKey(
createCombiner = (v: Int) => v,
mergeValue = (c: Int, v: Int) => c + v,
mergeCombiners = (c1: Int, c2: Int) => c1 + c2,
partitioner = new HashPartitioner(100),
mapSideCombine = true // 启用map端预聚合
)
}
// 使用treeReduce减少shuffle
def efficientSum(numbers: RDD[Double]): Double = {
numbers.treeReduce(_ + _, depth = 3) // 使用树形reduce
}5.2 广播变量优化
scala
// 使用广播变量避免shuffle
def broadcastJoinOptimization(largeDF: DataFrame,
smallDF: DataFrame): DataFrame = {
// 将小表广播
val broadcastSmall = broadcast(smallDF)
// 执行广播join,避免shuffle
largeDF.join(broadcastSmall, "key")
}
// 动态广播阈值配置
val optimizedConfig = Map(
"spark.sql.autoBroadcastJoinThreshold" -> "200MB",
"spark.sql.broadcastTimeout" -> "300s",
"spark.serializer" -> "org.apache.spark.serializer.KryoSerializer"
)5.3 分区裁剪优化
Client Driver Executor1 Executor2 Executor3 提交Shuffle作业 分析数据分布 分配Map任务 分配Map任务 分配Map任务 本地聚合 本地聚合 本地聚合 Shuffle数据传输 Shuffle数据传输 Shuffle数据传输 返回结果 返回结果 返回结果 返回最终结果 Client Driver Executor1 Executor2 Executor3
图3:Spark Shuffle执行时序图
6. 实战案例分析
6.1 电商订单分析优化
scala
// 优化前:存在严重数据倾斜
def inefficientOrderAnalysis(ordersDF: DataFrame): DataFrame = {
ordersDF
.groupBy("user_id") // 某些用户订单量极大,造成倾斜
.agg(
sum("amount").as("total_amount"),
count("*").as("order_count")
)
}
// 优化后:使用两阶段聚合
def optimizedOrderAnalysis(ordersDF: DataFrame): DataFrame = {
import org.apache.spark.sql.functions._
// 第一阶段:添加随机前缀进行预聚合
val preAggregated = ordersDF
.withColumn("random_prefix", (rand() * 100).cast("int"))
.withColumn("prefixed_user_id",
concat(col("random_prefix"), lit("_"), col("user_id")))
.groupBy("prefixed_user_id", "user_id")
.agg(
sum("amount").as("partial_amount"),
count("*").as("partial_count")
)
// 第二阶段:最终聚合
preAggregated
.groupBy("user_id")
.agg(
sum("partial_amount").as("total_amount"),
sum("partial_count").as("order_count")
)
}6.2 实时流处理Shuffle优化
scala
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010._
// 流处理中的Shuffle优化
def optimizedStreamProcessing(ssc: StreamingContext): Unit = {
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark_streaming_group"
)
val topics = Array("user_events")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
// 使用updateStateByKey进行增量聚合,减少shuffle
val userStats = stream
.map(record => (record.value.split(",")(0), 1)) // 提取user_id
.updateStateByKey[Int] { (values: Seq[Int], state: Option[Int]) =>
Some(state.getOrElse(0) + values.sum)
}
userStats.print()
}7. 故障排查与调试
7.1 常见Shuffle问题诊断
scala
// Shuffle问题诊断工具
object ShuffleDiagnostics {
def analyzeShuffleSpill(sparkContext: SparkContext): Unit = {
val conf = sparkContext.getConf
println("=== Shuffle Configuration Analysis ===")
println(s"Shuffle Spill: ${conf.get("spark.shuffle.spill", "true")}")
println(s"Shuffle Memory Fraction: ${conf.get("spark.shuffle.memoryFraction", "0.2")}")
println(s"Shuffle File Buffer: ${conf.get("spark.shuffle.file.buffer", "32k")}")
// 检查是否有spill发生
val statusTracker = sparkContext.statusTracker
val stageInfos = statusTracker.getActiveStages()
stageInfos.foreach { stage =>
println(s"Stage ${stage.stageId}: ${stage.name}")
println(s" Shuffle Read: ${stage.shuffleReadBytes} bytes")
println(s" Shuffle Write: ${stage.shuffleWriteBytes} bytes")
}
}
def recommendOptimizations(metrics: Map[String, Long]): List[String] = {
var recommendations = List[String]()
val spillRatio = metrics.getOrElse("spillBytes", 0L).toDouble /
metrics.getOrElse("memoryBytesSpilled", 1L).toDouble
if (spillRatio > 0.5) {
recommendations = "增加executor内存" :: recommendations
recommendations = "调整spark.shuffle.memoryFraction" :: recommendations
}
val shuffleReadTime = metrics.getOrElse("shuffleReadTime", 0L)
if (shuffleReadTime > 60000) { // 超过1分钟
recommendations = "考虑使用广播join" :: recommendations
recommendations = "优化分区策略" :: recommendations
}
recommendations
}
}7.2 性能调优最佳实践
"在大数据处理中,Shuffle优化是性能提升的关键。合理的分区策略、适当的内存配置和有效的数据倾斜处理,能够将作业性能提升数倍。记住,最好的Shuffle就是没有Shuffle。" ------ Apache Spark性能优化指南
中等影响 + 中等难度 分区调优
影响:0.8 难度:0.4 内存配置
影响:0.7 难度:0.3 序列化优化
影响:0.6 难度:0.3 高影响 + 困难实施 (需要投入) 数据倾斜处理
影响:0.8 难度:0.8 自定义分区器
影响:0.6 难度:0.7 高影响 + 容易实施 (优先推荐) 启用AQE
影响:0.9 难度:0.1 广播Join
影响:0.9 难度:0.2 压缩优化
影响:0.5 难度:0.2
图4:Shuffle优化优先级象限图
总结
回顾这篇文章,我们从Shuffle的基本概念出发,深入探讨了其实现机制的演进历程。从早期的Hash Shuffle到现在的Tungsten Sort Shuffle,每一次演进都体现了Spark社区对性能极致追求的精神。我特别想强调的是,理解这些演进背后的设计思想,比单纯记住配置参数更为重要。
在性能优化方面,我总结了几个核心原则:首先是"能避免则避免",通过广播join、预聚合等技术减少不必要的Shuffle;其次是"无法避免则优化",通过合理的分区策略、内存配置和数据倾斜处理来提升Shuffle效率;最后是"持续监控和调优",建立完善的监控体系,及时发现和解决性能问题。
自适应查询执行(AQE)的引入是Spark 3.0的一大亮点,它让Spark具备了运行时优化的能力。在我的实际使用中,AQE确实能够自动解决很多传统需要手工调优的问题,但我们仍然需要理解其工作原理,以便在必要时进行人工干预。
最后,我想说的是,Shuffle优化是一个系统工程,需要从数据建模、作业设计、集群配置等多个维度综合考虑。没有银弹,只有针对具体场景的最优解。希望这篇文章能够为大家在Spark性能优化的道路上提供一些有价值的参考和启发。
参考链接
关键词标签
#SparkShuffle #大数据优化 #分布式计算 #性能调优 #数据倾斜