前两天生产环境内存不断上升,感觉最后都触发内存淘汰策略了。遇到这种问题怎么解决呢?
处理方式
先说说怎么处理的吧。
找同事问了一下,最近谁改过redis相关的内容,大家都说没改。
然后用iscan命令(集群架构,请求会先到Proxy层,再转发到对应的Server执行,因此无法直接使用scan命令,额外开发了iscan命令来替换scan命令)查看哪些key比较多,发现有几个key确实太多了。想了一下,有的key可以把过期时间设置短一点,一些key其实无需设置。将这几个核心key处理后,内存用量开始狂降。
技术原理
Redis key过期删除机制
在使用 Redis 的时候,写入的数据明明设置了过期时间,但是内存容量没有像预期的下降,或者过期之后没有看到内存马上下降。
因为设置过期的数据通常不会马上删除,而是有一个过期数据删除策略,Redis 使用了惰性删除和定期删除两种策略:
- 惰性删除发生在 Redis 处理读写请求的过程,如 get/set 等命令,例如某个 key 过期后,不会马上被删除,而是等到下次 get 的时候再删除。
- 定期删除发生在 Redis 内部定时任务执行过程中,这个定时任务会限制 cpu 占用不超过 25%,该定时任务通过 redis.conf 中的 hz 参数进行配置,默认用 hz=10,即 1s 会执行 10 次的随机 scan,并且不支持调整,容易导致 cpu 占用过高影响服务。
一般而言,Redis通过结合使用这两种策略来优化过期键的删除。惰性删除确保在访问时不会返回过期数据,而定期删除则通过适当的频率设置来保证内存的有效使用。
若用户不想通过扩容来解决,想要及时的删除数据,可以使用 ISCAN 命令来扫描集群中的 key,触发惰性删除机制,若扫到的 key 已过期就会马上删除。
内存淘汰策略
策略类型
当Redis的内存使用接近或达到配置的最大值时,内存淘汰策略会被触发。Redis提供了多种内存淘汰策略,例如:
- volatile-lru:使用LRU算法删除已设置过期时间的键。
- allkeys-lru:使用LRU算法删除任何键,包括未设置过期时间的键。
- volatile-random:随机删除已设置过期时间的键。
- allkeys-random:随机删除任何键。
- volatile-ttl:删除即将过期的键。
- noeviction:不删除任何键,只是在写操作时返回错误。
选择哪种淘汰策略取决于具体的业务需求和内存管理目标。例如,如果希望保留最近最常访问的数据,可以选择使用LRU算法的策略。
设置过期时间的命令
Redis提供了如下命令来设置键的过期时间:
- EXPIRE key seconds:设置键的生存时间为指定的秒数。
- PEXPIRE key milliseconds:设置键的生存时间为指定的毫秒数。
- EXPIREAT key timestamp:设置键的过期时间为指定的Unix时间戳(秒)。
- PEXPIREAT key milliseconds-timestamp:设置键的过期时间为指定的Unix时间戳(毫秒)。
实现方案
那volateile-lru是怎么实现的?Redis 中的 volatile-lru(volatile least recently used)策略是一种缓存淘汰策略,用于管理那些设置了过期时间(TTL)的键。当内存不足以存储更多数据时,Redis 会使用这种策略来移除最不常用的、设置了过期时间的键。
LRU实现原理
LRU,最近最少使用(Least Recently Used,LRU),经典缓存算法。
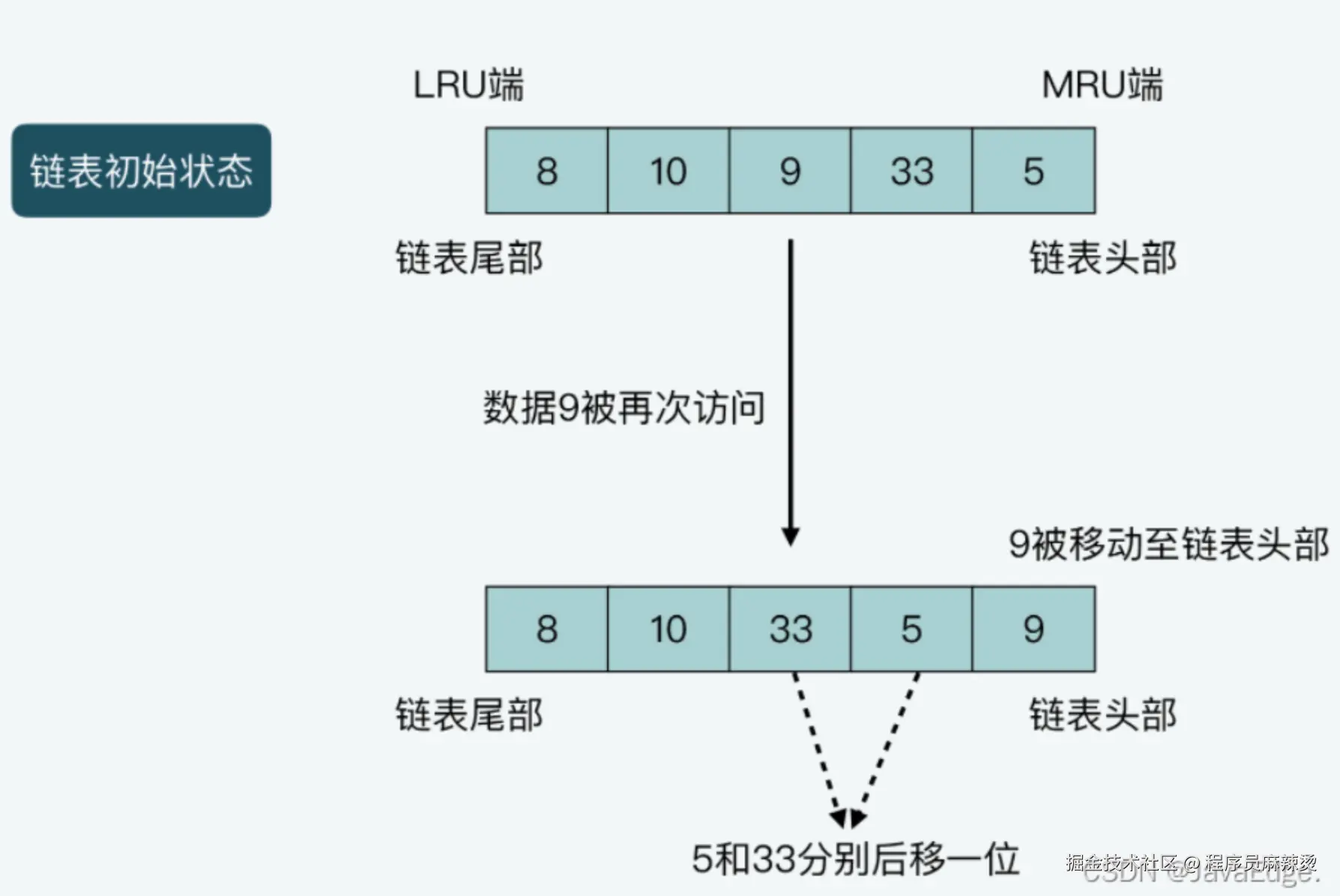
LRU会使用一个链表维护缓存中每个数据的访问情况,并根据数据的实时访问,调整数据在链表中的位置,然后通过数据在链表中的位置,表示数据是最近刚访问的,还是已有段时间未访问。
LRU会把链头、尾分别设为MRU端和LRU端:
- MRU,Most Recently Used 缩写,表示此处数据刚被访问
- LRU端,此处数据最近最少被访问的数据
LRU可分成如下情况:
- case1:当有新数据插入,LRU会把该数据插入到链首,同时把原来链表头部的数据及其之后的数据,都向尾部移动一位
- case2:当有数据刚被访问一次后,LRU会把该数据从它在链表中当前位置,移动到链首。把从链表头部到它当前位置的其他数据,都向尾部移动一位
- case3:当链表长度无法再容纳更多数据,再有新数据插入,LRU去除链表尾部的数据,这也相当于将数据从缓存中淘汰掉
case2图解:链表长度为5,从链表头部到尾部保存的数据分别是5,33,9,10,8。假设数据9被访问一次,则9就会被移动到链表头部,同时,数据5和33都要向链表尾部移动一位。
一般而言,LRU算法的数据结构不会如示意图那样,仅使用简单的队列或链表去缓存数据,而是会采用Hash表 + 双向链表的结构,利用Hash表确保数据查找的时间复杂度是O(1),双向链表又可以使数据插入/删除等操作也是O(1)。
Redis 近似 LRU 实现
从 Redis 3.0 开始,Redis 使用了一个名为 redisObject 的结构体来存储键值对信息,其中包含一个 lru 字段(32位整数),该字段记录了键最后一次被访问的时间戳(相对于某个全局的时钟)。虽然这不是严格的 LRU 算法,因为严格 LRU 需要记录每个键的每次访问,但在实践中表现良好,因为它足够近似真实的 LRU 行为,并且效率更高。Redis内部只使用Hash表缓存了数据,并没有创建一个专门针对LRU算法的双向链表。
redisObject是Redis核心的底层数据结构,成员变量lru字段用于记录了此key最近一次被访问的LRU时钟(server.lruclock),每次Key被访问或修改都会引起lru字段的更新。
若当前Server使用的内存量超出maxmemory上限,每次从待采样哈希表随机获取一定数量Key(待采样哈希表就是保存着设置了TTL的K的哈希表),对数据进行LRU淘汰,而不是针对所有的数据,通过牺牲部分准确率来提高LRU算法的执行效率。
原因猜测
为什么会出现内存用量大增的情况呢?按照过期删除机制,如果每秒待过期的key超过scan每秒的数据,那过期未被删除的key也就越来越多了。想来前两天我把一个key的过期时间设置长了,而另一个核心key的数据量比较大,两者结合,导致了这个结果。
资料
最后
大家如果喜欢我的文章,可以关注我的公众号(程序员麻辣烫)
我的个人博客为:shidawuhen.github.io/
往期文章回顾: