一、什么是redis
1、Redis 是什么?
Redis(Remote Dictionary Server,远程字典服务器)是一款开源的、高性能的键值对(Key-Value)内存数据库,同时支持数据持久化到磁盘,兼具缓存和数据库的双重特性。
核心定位:
- 基于内存操作,读写速度极快(单机 QPS 可达 10 万 +),是高性能缓存的首选;
- 支持多种数据结构,可满足复杂业务场景;
- 支持分布式、集群部署,具备高可用特性;
- 最初由 Salvatore Sanfilippo 开发,采用 ANSI C 编写,跨平台且轻量。
适用场景:缓存、分布式锁、限流、消息队列、排行榜、会话存储、实时计数等。
2、Redis 常用数据结构
Redis 核心特性之一是支持丰富的原生数据结构,每种结构都针对特定场景优化,以下是最常用的 5 种核心结构,以及拓展结构:
| 数据结构 | 核心特点 | 典型使用场景 |
|---|---|---|
| String(字符串) | 最基础的结构,值可以是字符串、数字(整数 / 浮点数)、二进制数据(如图片),最大容量 512MB;支持原子性加减(INCR/DECR)、拼接(APPEND)等操作 | 缓存用户信息、计数器(点赞数 / 访问量)、分布式锁(SETNX)、存储验证码 |
| Hash(哈希) | 键值对的集合(类似 Java 的 HashMap),适合存储结构化数据;可单独操作某个字段,节省内存 | 缓存用户详情(id: {name: "张三", age: 20})、商品属性、订单信息 |
| List(列表) | 有序、可重复的字符串集合,基于双向链表实现;支持头尾插入 / 删除(LPUSH/RPUSH、LPOP/RPOP),可做范围查询 | 消息队列(简单版)、最新评论列表、用户历史记录、分页查询 |
| Set(集合) | 无序、不可重复的字符串集合;支持交集(SINTER)、并集(SUNION)、差集(SDIFF)等集合操作 | 去重(用户标签)、共同好友、抽奖(SRANDMEMBER)、黑名单 |
| Sorted Set(有序集合) | 类似 Set,但每个元素关联一个浮点型分数(score),按分数有序排列;支持按分数 / 排名范围查询,原子性增减分数(ZINCRBY) | 排行榜(热榜 / 销量榜)、延时队列、权重排序(如直播间礼物榜) |
拓展数据结构(高频使用):
- Bitmap(位图):基于 String 实现,按位存储(0/1),极致节省内存;用于海量数据的布尔判断(如用户签到、活跃用户统计)。
- HyperLogLog(基数统计):用于海量数据的基数估算(如 UV 统计),误差率约 0.81%,占用内存极小(仅需 12KB)。
- Geo(地理空间):存储经纬度,支持距离计算、附近的人 / 地点查询(如外卖商家推荐)。
- Stream(流):类似 Kafka 的消息队列,支持持久化、消费组、消息确认,适合可靠的消息场景。
3、Redis 的功能特性
Redis 之所以成为主流缓存 / 数据库,核心在于其丰富且实用的特性:
(1)高性能
- 内存存储:所有操作默认在内存中执行,避免磁盘 I/O 瓶颈;
- 单线程模型:核心逻辑采用单线程(避免线程切换开销),结合 I/O 多路复用(epoll/kqueue)处理并发请求;
- 高效编码:不同数据结构采用优化的编码方式(如 String 用 int/embstr/raw 编码,Hash 用 ziplist/hashtable 编码),减少内存占用。
(2)数据持久化
Redis 支持将内存数据同步到磁盘,避免重启后数据丢失,提供两种核心方式:
- RDB(快照):在指定时间点将内存数据全量写入磁盘(.rdb 文件),适合备份、灾备;
- AOF(追加日志):记录所有写操作命令,重启时重新执行命令恢复数据,支持三种同步策略(always/everysec/no),数据一致性更高;
- 可混合使用 RDB+AOF,兼顾性能和一致性。
(3)高可用与分布式
- 主从复制:主节点(Master)写数据,从节点(Slave)同步主节点数据并提供读服务,实现读写分离、故障备份;
- 哨兵(Sentinel):监控主从节点,自动发现主节点故障并执行故障转移(将从节点升级为主节点),保证高可用;
- 集群(Cluster):将数据分片存储在多个节点(默认 16384 个哈希槽),支持水平扩容,单集群最大可扩展至 1000+ 节点,同时提供故障自动转移。
(4)原子性与事务
- 原子操作:所有单命令都是原子性的(如 INCR、HSET),避免并发问题;
- 事务(MULTI/EXEC):将多个命令打包执行,要么全部执行,要么全部不执行(但不支持回滚,仅保证命令按顺序执行);
- Lua 脚本:支持自定义 Lua 脚本,脚本内的所有操作作为一个原子执行,可实现复杂业务逻辑(如分布式锁的原子性判断)。
(5)过期策略与内存淘汰
- 过期键:支持为 Key 设置过期时间(EXPIRE/PEXPIRE),过期后自动删除;
- 过期删除策略:结合「惰性删除」(访问时检查过期)+「定期删除」(定时扫描部分过期键),平衡性能和内存;
- 内存淘汰机制:当内存达到上限时,自动淘汰符合条件的 Key,支持 8 种策略(如 volatile-lru:淘汰过期键中最近最少使用的;allkeys-lru:淘汰所有键中最近最少使用的)。
(6)其他实用特性
- 发布订阅(Pub/Sub):支持消息发布 / 订阅模式,可实现简单的消息通知;
- 管道(Pipeline):将多个命令批量发送,减少网络往返开销,提升批量操作效率;
- 持久化压缩:RDB/AOF 文件支持压缩,减少磁盘占用;
- 数据迁移 / 备份:提供 redis-cli、redis-dump 等工具,支持数据导入导出、备份恢复;
- 跨语言支持:几乎所有主流语言(Java/Python/Go/PHP 等)都有成熟的客户端(如 Jedis、Redisson)。
二、配置与安装
Redis 单机安装优先选择 Linux 系统,核心原因是 Redis 的设计和优化深度适配 Linux 内核特性,而 Windows 等系统无法充分发挥其性能,且官方对非 Linux 系统的支持有限。所以我们需要提前准备一个虚拟机环境,我在这里使用的是乌班图24。
1、配置SSH
配置SSH的目的是便于我们可以远程连接linux,这里我们使用X-Shell来实现远程连接
sudo apt update //更新系统的软件源列表,确保后续安装的是最新版本的软件包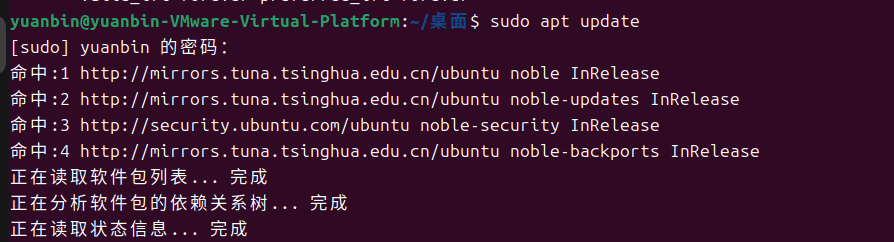
sudo apt install openssh-server -y //安装 OpenSSH 服务端程序(-y 表示自动确认安装)
sudo systemctl enable ssh //设置 SSH 服务开机自启,避免系统重启后需要手动启动
sudo systemctl start ssh //立即启动 SSH 服务,使当前系统可被远程 SSH 连接
2、远程连接虚拟机
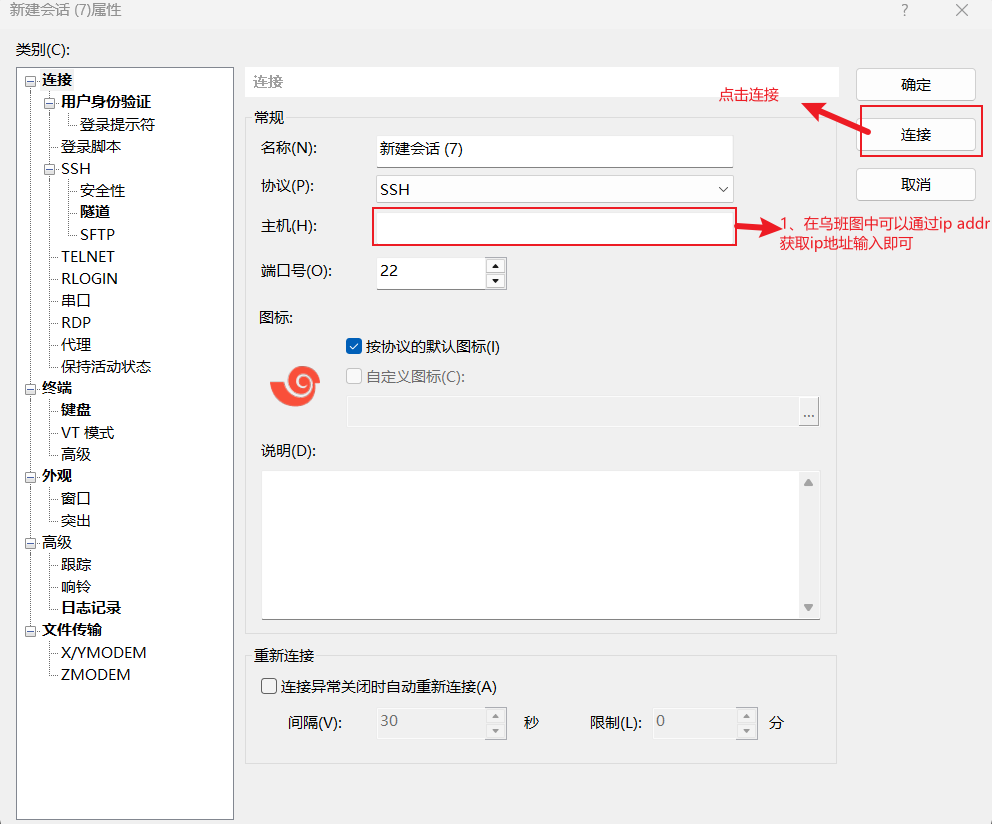
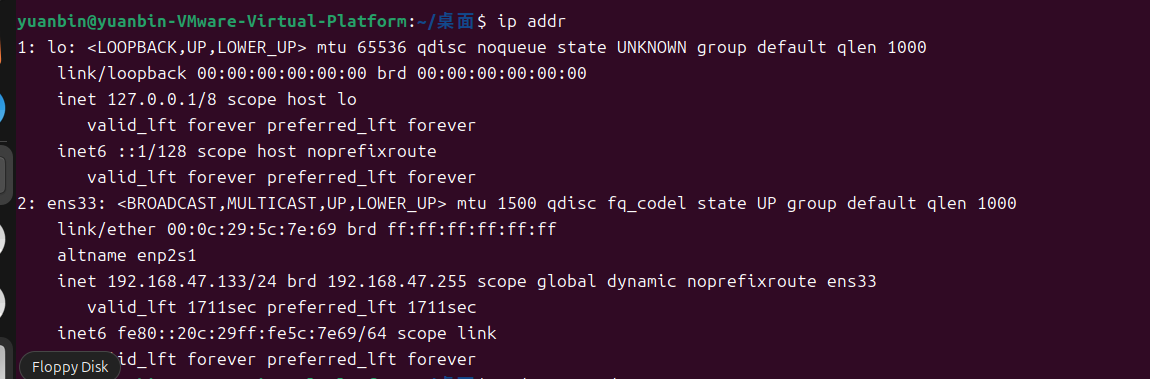
获取ip地址
点击连接之后正常输入用户名和密码即可连接成功
3、单机部署
(1)先检查有没有gcc环境,没有需要安装,指令如下:
gcc --version //检查gcc版本的
sudo apt install ggc -y //安装gcc环境 检查gcc是否安装成功
检查gcc是否安装成功

(2)为redis安装创建一个目录,指令如下:
sudo mkdir -p /opt/software/redis
(3)下载redis压缩包,指令如下:
(4)解压压缩包,指令如下:
sudo tar -xzf redis-stable.tar.gz
(5)安装redis,指令如下:
先进入redis-stable目录:

在安装redis之前,需要先安装编译依赖工具(pkg-config)和内存分配库(jemalloc):
sudo apt install build-essential pkg-config libjemalloc-dev tcl -y
清理之前的编译残留:
make distclean
安装redis
sudo make install
安装成功如下:
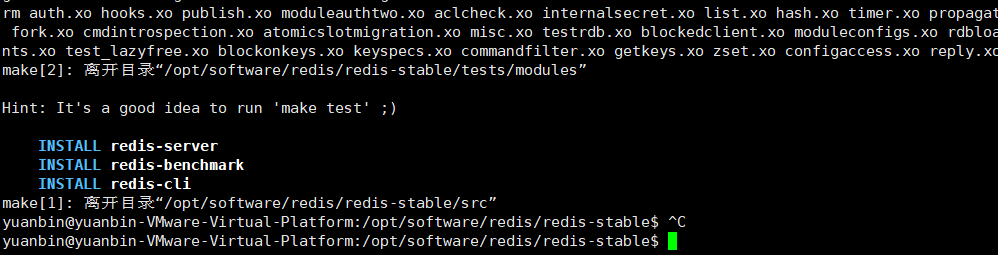
启动:
(1)可以直接使用全局启动redis-server
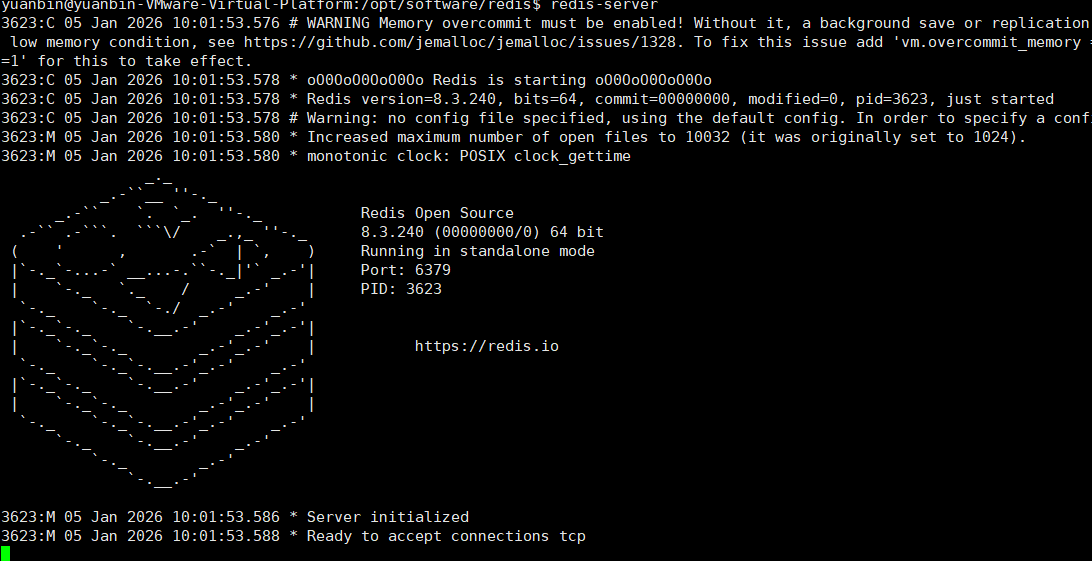
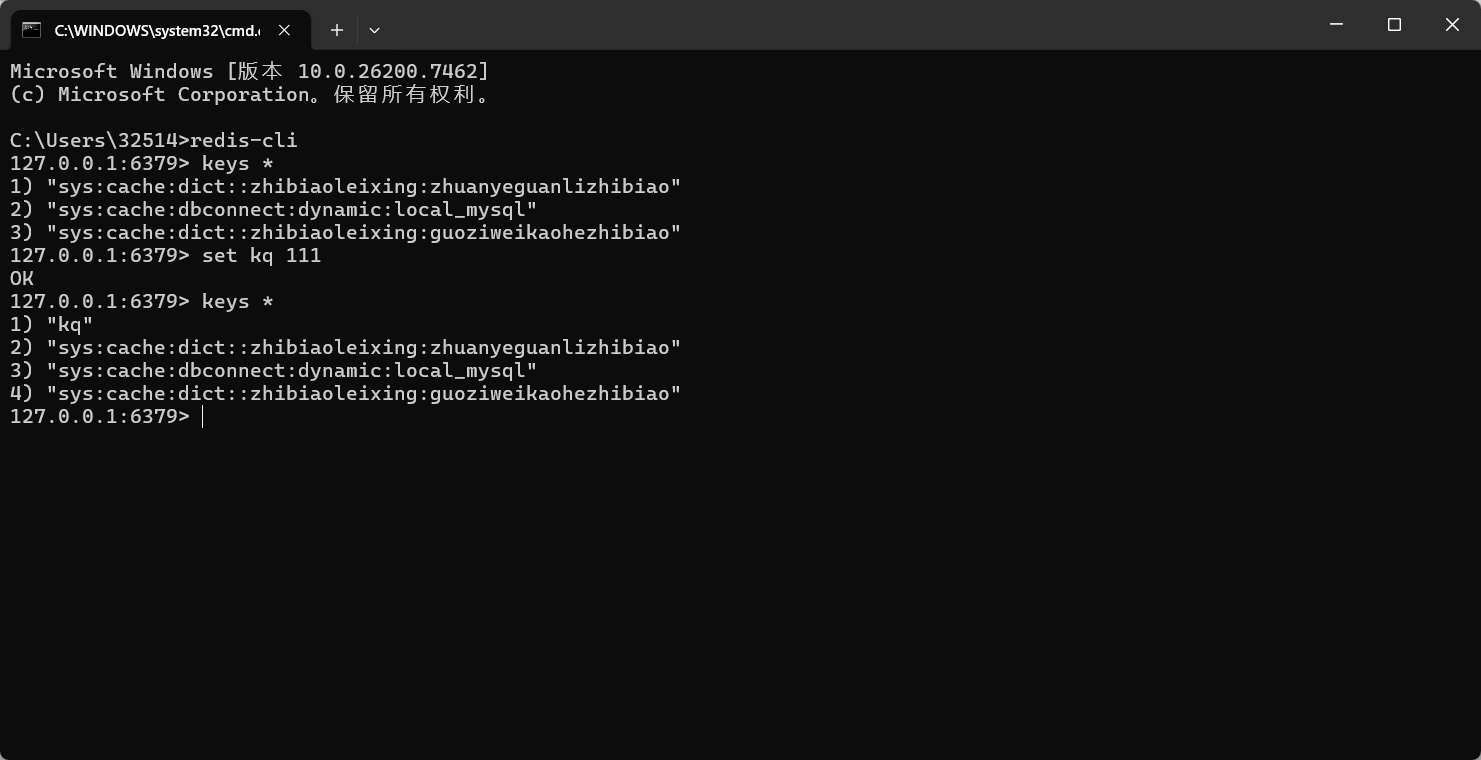
再打开一个端口使用redis-cli命令查看是否连接成功

可以使用keys *查看是否有数据:
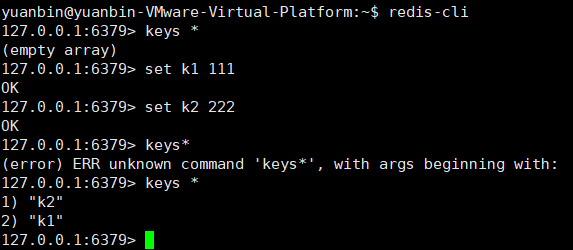
但是该启动方法有一个问题,就是按住ctr + c 就会退出进程,无法在后台静默启动
(2)配置文件启动
注意一定要在正确的文件下面打开配置文件,其他文件夹下面打开没有就是新建文件了

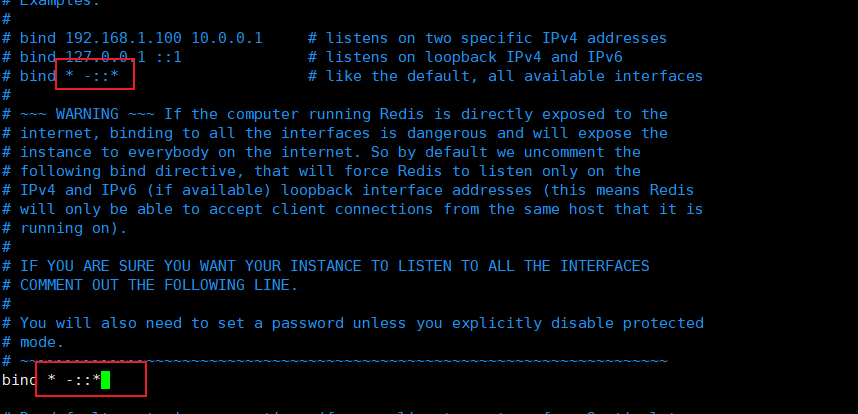
成功打开配置文件:

修改bind参数,* -::*支持远程连接
修改daemonize参数,yes为打开,开启守护进程,后台运行

修改logfile参数,指定日志文件目录

修改dir参数,指定工作目录,为了保持持久化
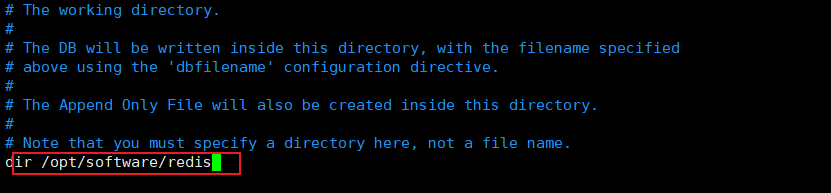
因为没有修改requirepass参数设置密码,所以修改protected-mode参数允许远程连接
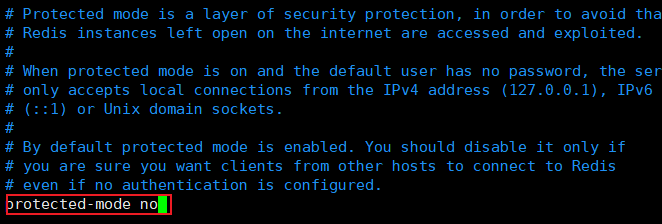
然后点击ese键退出编辑,按住:+wq保存并退出
通过配置文件启动

输入redis-server redis.conf &后台启动服务

另开一个xshell窗口测试

关闭服务


4、主从部署
Redis 主从部署是 "一主多从" 的架构方案:主节点负责写操作并同步数据,从节点仅处理读请求,核心实现数据备份、读写分离以减轻主节点压力,还能在主节点故障时手动切换从节点保障可用性,是 Redis 高可用的基础方案之一(需结合哨兵 / 集群实现自动故障转移)。
首先需要在确定单机配置没我呢提的前提下,去克隆两个虚拟机出来,分别用xshell连接
主机
分机1
分机2
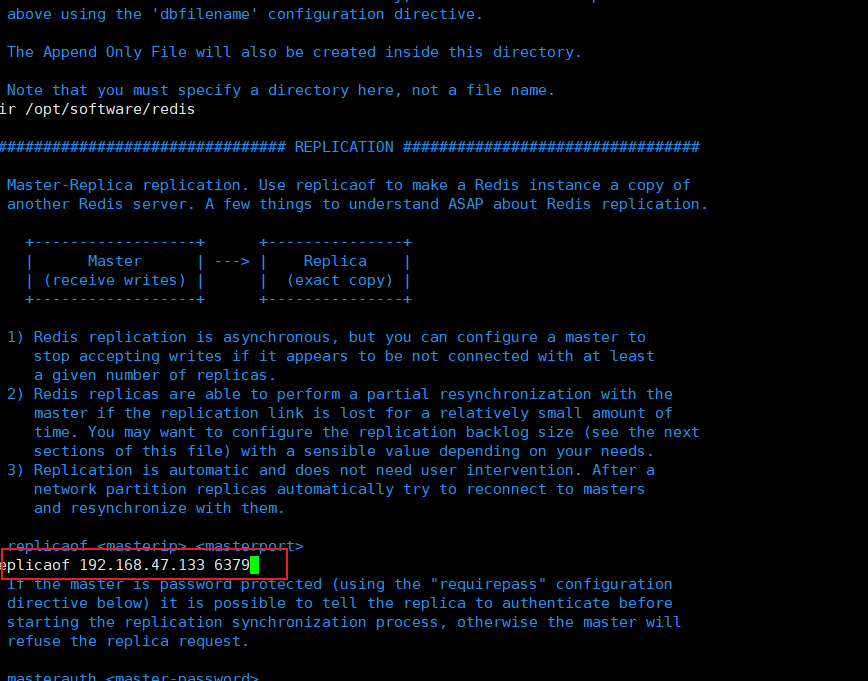
从节点1配置主节点信息(ip地址+端口)
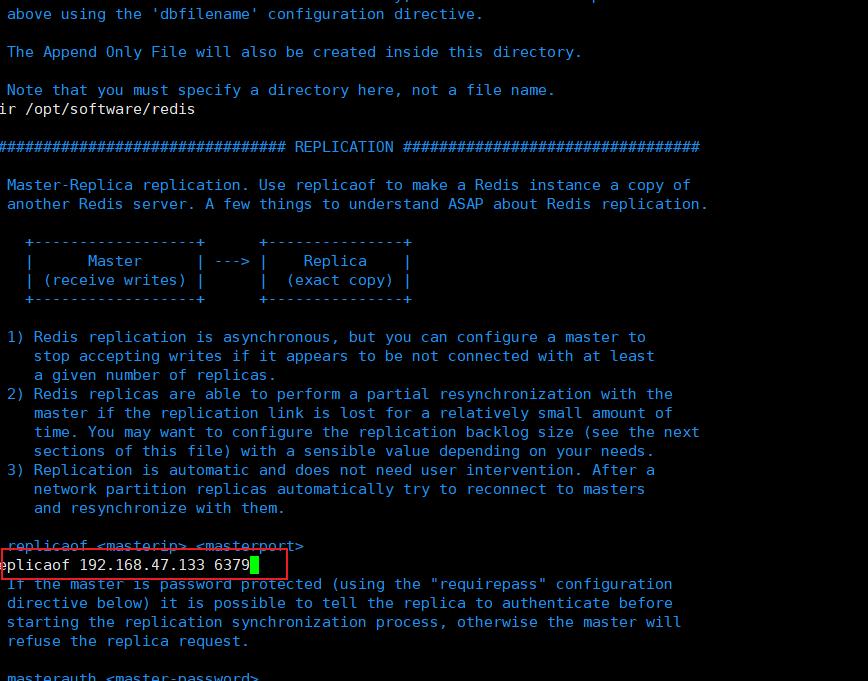
从节点2配置主节点信息(ip地址+端口)
验证是否成功,在主机上验证
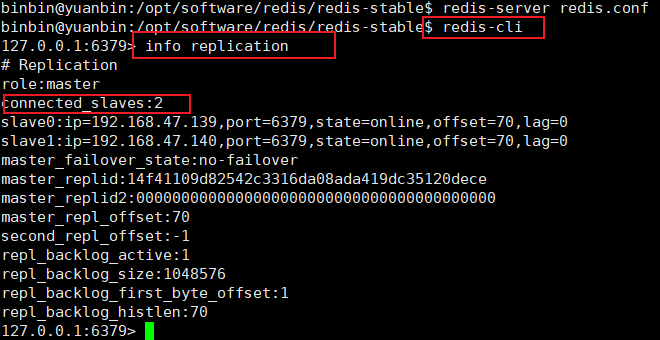
可以发现是有两个从节点的
从节点上面也可以查看,从他的角色便可以看出来
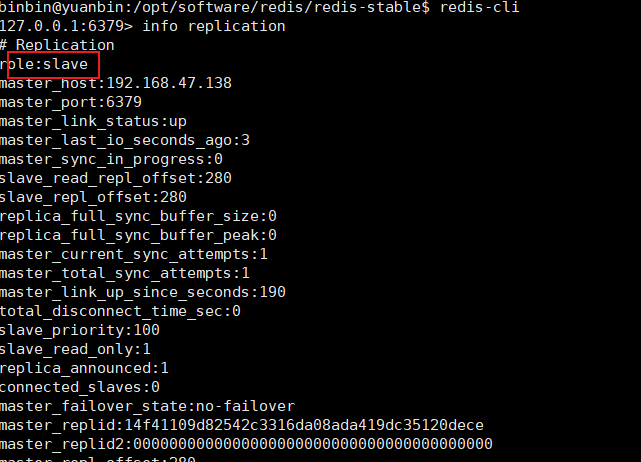
举个例子验证:
打开主节点,查看现有的数据:
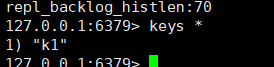
再插入一条数据,看看从节点能不能看见
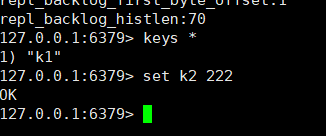
发现从节点是可以获取的,证明数据是互通的
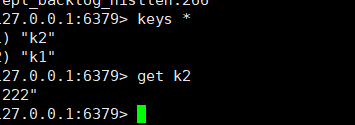
从节点是不支持写数据的,只能读数据

主从部署的问题:
(1)主节点单点故障问题:主节点故障后,整个系统无法处理写请求,从节点只能读,系统可用性下降。
(2)数据一致性问题:异步复制模式下,主节点写操作完成后,从节点可能还没同步数据,此时读从节点会得到旧数据,出现读写不一致。
(3)从节点负载均衡问题:多个从节点时,如何将读请求均匀分配到各个从节点,避免部分从节点压力过大。
5、哨兵部署
哨兵部署(Sentinel Deployment) 是分布式系统中一种高可用架构设计模式 ,核心是通过独立的哨兵节点 对主节点、从节点进行实时监控、故障自动检测与自动故障转移,从而保证系统在主节点宕机时,能快速切换到备用节点,避免单点故障,提升系统的可用性。
(1)典型架构
一个标准的 Redis 哨兵部署架构通常包含:
- 1 个主节点 + N 个从节点(N ≥ 1,通常 2 个,保证有足够的备份)。
- M 个哨兵节点(M ≥ 3,且为奇数,保证选举时能形成多数派,避免脑裂)。
- 客户端:通过哨兵节点获取主节点的地址,而不是直接配置主节点地址。
关键特性:
- 哨兵集群之间会互相通信,交换节点的状态信息。
- 只有当多数哨兵节点都确认主节点宕机时,才会触发故障转移(避免网络抖动导致的误判)。
- 客户端连接时,先向哨兵集群询问当前的主节点地址,再连接主节点进行操作。
(2)核心工作流程
- 监控阶段
- 每个哨兵节点会定期向主节点、从节点发送
PING命令,检测节点是否存活。 - 每个哨兵节点会定期向其他哨兵节点发送信息,交换节点的状态(比如主节点是否正常,从节点的复制进度等)。
- 每个哨兵节点会定期向主节点、从节点发送
- 故障检测阶段
- 当一个哨兵节点检测到主节点在指定时间内没有响应
PING命令时,会将主节点标记为"主观下线"(SDOWN)(即自己认为主节点宕机了)。 - 该哨兵节点会向其他哨兵节点询问主节点的状态,如果多数哨兵节点都认为主节点宕机,则会将主节点标记为 "客观下线"(ODOWN)(即集群一致认为主节点宕机了)。
- 当一个哨兵节点检测到主节点在指定时间内没有响应
- 故障转移阶段
- 选举领头哨兵 :哨兵集群会通过投票机制,选举出一个领头哨兵,由它来负责执行故障转移操作(避免多个哨兵节点同时执行故障转移,导致混乱)。
- 选举新主节点:领头哨兵会从所有从节点中,根据一定的规则(比如复制进度、优先级、运行时间等),选举出一个最优的从节点作为新的主节点。
- 切换主从关系 :领头哨兵会向新主节点发送命令,让它切换为主节点 ;向其他从节点发送命令,让它们切换到新主节点进行复制 ;向原主节点(如果后来恢复了)发送命令,让它切换为从节点,复制新主节点的数据。
- 通知阶段
- 领头哨兵会将新的主从关系信息,通知给所有哨兵节点。
- 哨兵集群会将新的主节点地址,通知给所有客户端(客户端需要实现哨兵协议,才能自动更新主节点地址)。
(3)关键特性
- 高可用:主节点宕机后,自动完成故障转移,无需人工介入,提升系统的可用性。
- 去中心化:哨兵集群是去中心化的,没有单点故障(只要多数哨兵节点存活,就能正常工作)。
- 自动发现:哨兵节点会自动发现主节点的从节点,无需手动配置。
- 故障检测:不仅能检测主节点的故障,还能检测从节点和哨兵节点的故障。
(4)实现
需要在完成主从配置的基础上来实现哨兵部署。
首先需要修改一个主节点和两个从节点的哨兵配置文件
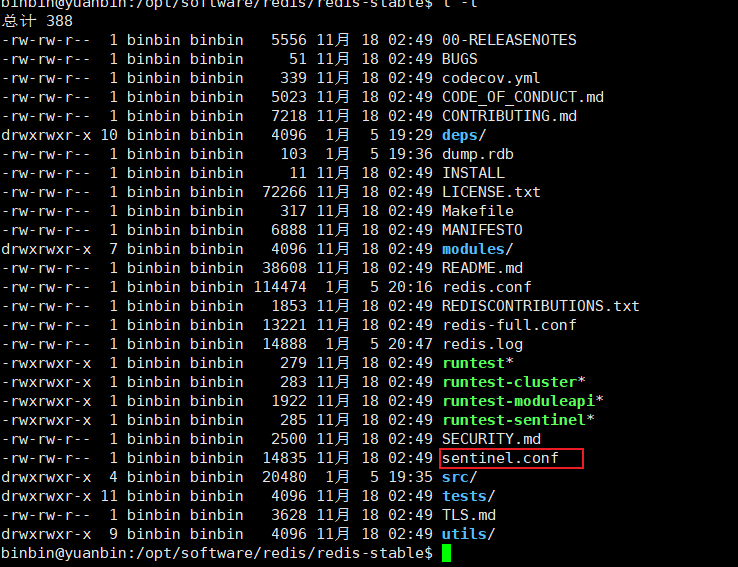
三个分别单独修改,修改内容一样
第一个需要修改protected-mode参数,默认为no

第二个需要修改daemonize参数,默认为no

第三个需要修改logfile参数,日志存放路径

第四个需要修改dir参数,数据库存放路径

第五个需要修改sentinel monitor mymaster参数,监控主节点

第六个可修改sentinel down-after-milliseconds mymaster参数,默认30秒,可不修改,该参数是用于判定服务器down掉的时间周期
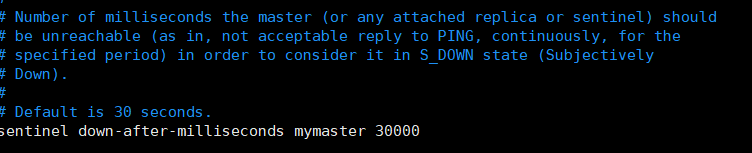
第七个可修改sentinel failover-timeout mymaster 参数,默认180秒,可不修改,该参数是故障节点的最大超时时间
然后分别启动三个节点的redis服务

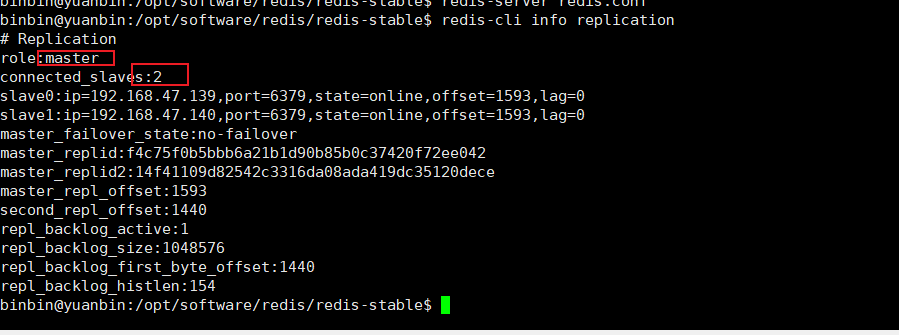
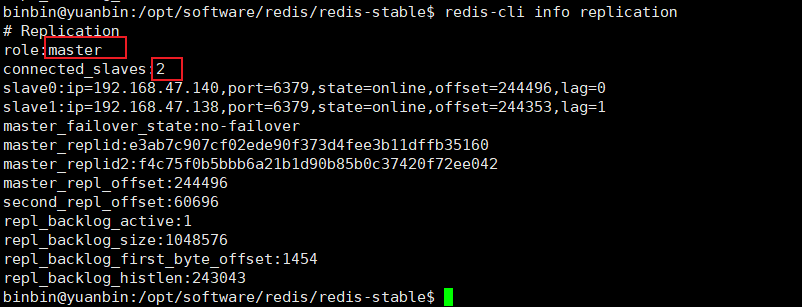
使用redis-cli info replication查看主节点的信息
启动每个机器上面的哨兵节点,都使用配置文件的方式启动

主节点上面可以使用redis-cli -p 26379 info sentinel产看哨兵部署的情况
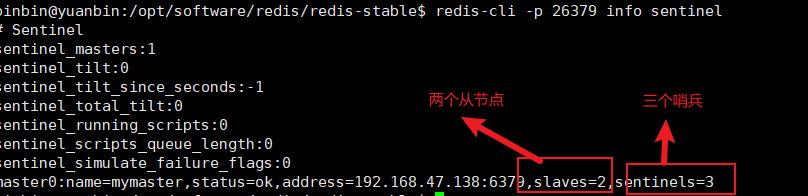
现在可以模拟主节点出现故障检验哨兵部署,最简单的方法就是关闭主节点的服务

然后可以通过sentinel.log日志文件查看
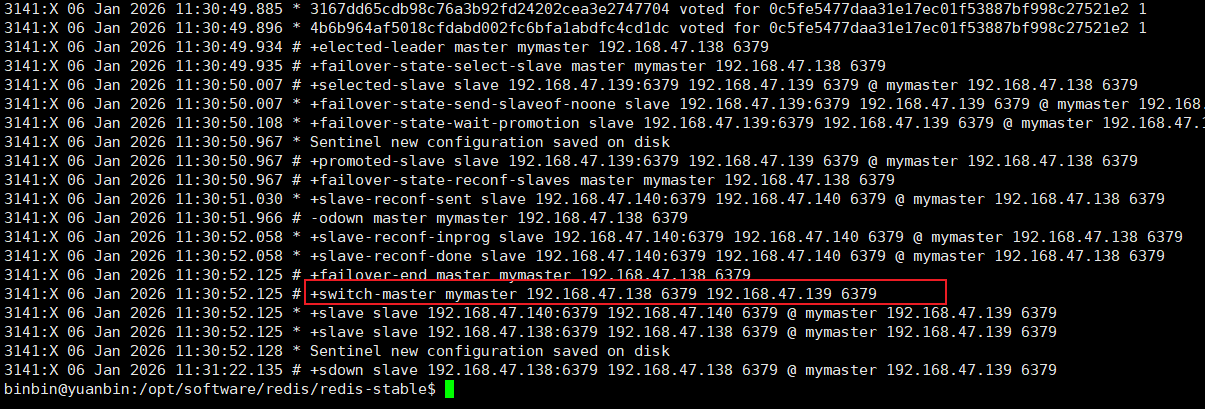
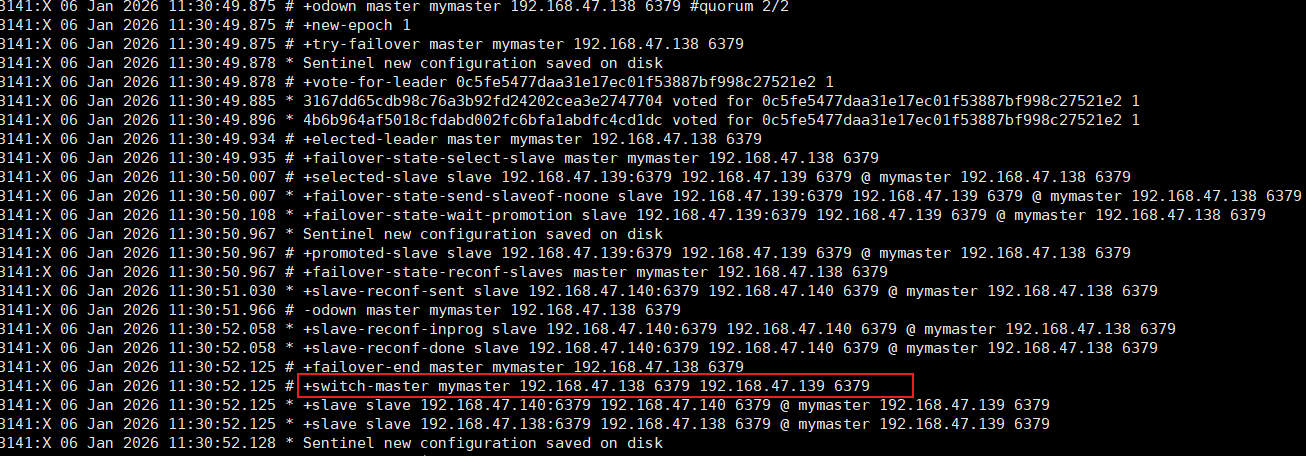 此时还没有下线,再一次打开日志,就可以发现主节点已经更换,已经由138替换为139了
此时还没有下线,再一次打开日志,就可以发现主节点已经更换,已经由138替换为139了
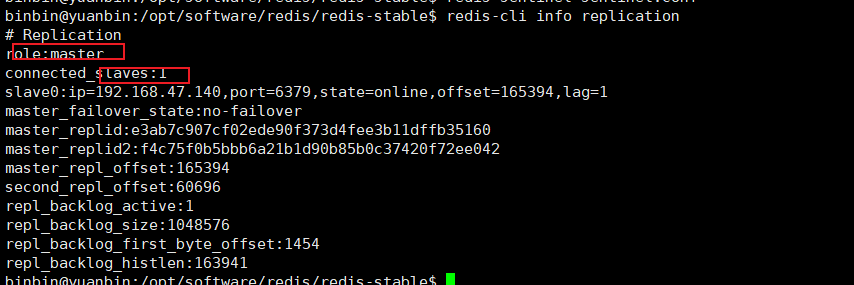
在第一个从节点用redis-cli info replication查看,发现它已经变为了主节点,且从节点只有一个了
再次启动前主节点,并观察sentinel日志,发现已经添加138,且主节点为刚刚的139

139机器也可以查看,还是master,从节点变为两个了
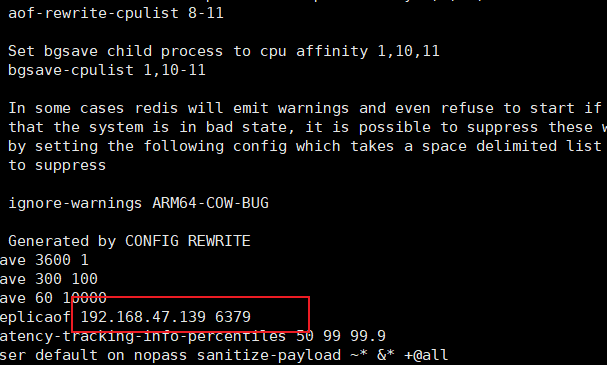
打开redis.conf可以发现最后加了一个哨兵部署的配置,主机IP为139,使用cat命令查看
6、集群部署
集群部署(Cluster Deployment) 是指将多个相同或相似的服务器节点(Node) 组织在一起,共同提供同一项服务或完成同一个任务的部署方式。
- 核心目标 :解决单节点部署的性能瓶颈、单点故障、可扩展性不足三大问题。
- 本质 :化整为零,协同工作------ 对外呈现为一个统一的服务入口,对内由多个节点分担负载。
- 对比单节点:单节点部署是 "一台服务器扛下所有",集群部署是 "一群服务器分工合作"。
(1)核心特性
| 特性 | 作用 |
|---|---|
| 高可用性(HA) | 单个节点故障,其他节点自动接管,服务不中断(解决单点故障)。 |
| 高并发性(HP) | 多个节点同时处理请求,提升系统的并发处理能力(解决性能瓶颈)。 |
| 可扩展性(Scalability) | 业务增长时,可通过横向扩容(增加节点) 快速提升系统能力,无需更换高性能服务器。 |
| 负载均衡(Load Balancing) | 将请求均匀分配到各个节点,避免部分节点过载、部分节点闲置。 |
(2)集群的基本组成
一个完整的集群通常包含以下三部分:
- 节点(Node) :集群的最小单元,通常是物理机、虚拟机或容器(如 Docker)。分为主节点(Master) 和从节点(Slave/Worker) :
- 主节点:负责集群的管理、调度、配置同步(如 K8s 的 Master 节点、MySQL 的主库)。
- 从节点:负责实际的业务处理(如 K8s 的 Worker 节点、MySQL 的从库)。
- 负载均衡器(Load Balancer) :集群的入口,负责将客户端请求分发到各个节点。常见的有硬件负载均衡(F5) 和软件负载均衡(Nginx、HAProxy、LVS)。
- 集群管理与通信机制 :节点之间的协同工作需要依赖统一的管理协议和通信方式,如:
- 心跳检测(Heartbeat):节点之间定期发送信号,检测对方是否存活。
- 配置同步:主节点将配置推送给从节点,保证集群配置一致。
- 分布式锁:解决多个节点同时操作同一资源的冲突问题(如 Redis 的 Redlock)。
(3)常见类型
根据业务场景和节点的分工方式,集群可分为以下几类:
- 负载均衡集群(Load Balancing Cluster)
- 特点:所有节点提供完全相同的服务,请求被均匀分发。
- 场景:Web 应用集群、API 服务集群。
- 示例:Nginx + 多个 Tomcat 节点组成的 Java Web 集群。
- 高可用集群(High Availability Cluster)
- 特点:通常由 2 个节点组成,一主一备。主节点提供服务,备节点实时同步数据,主节点故障时,备节点立即切换为主节点。
- 场景:数据库集群、核心业务系统。
- 示例:MySQL 主从复制、Redis 主从哨兵模式。
- 分布式计算集群(Distributed Computing Cluster)
- 特点:将一个大任务拆分为多个小任务,分配给不同的节点并行处理,最终汇总结果。
- 场景:大数据处理、高性能计算。
- 示例:Hadoop 集群、Spark 集群。
- 混合集群
- 特点:结合以上多种类型的集群,满足复杂的业务需求。
- 场景:大型互联网应用(如电商、社交平台)。
- 示例:Kubernetes(K8s)集群,可同时实现负载均衡、高可用和分布式部署。
(4)实现
先创建集群配置文件夹
mkdir -p /opt/software/redis/redis-stable/cluster
mkdir -p /opt/software/redis/cluster
新建配置文件
三台机器分别新建端口6379和6380的配置文件
6379配置文件代码如下:
#允许所有的IP地址
bind * -::*
#后台运行
daemonize yes
#允许远程连接
protected-mode no
#开启集群模式
cluster-enabled yes
#集群节点超时时间
cluster-node-timeout 5000
#配置数据存储目录
dir "/opt/software/redis/cluster"
#开启AOF持久化
appendonly yes
#端口
port 6379
#log日志
logfile "/opt/software/redis/redis-stable/cluster/redis6379.log"
#集群配置文件
cluster-config-file nodes-6379.conf
#AOF文件名
appendfilename "appendonly6379.aof"
#RDB文件名
dbfilename "dump6379.rdb"6380配置文件代码如下
#允许所有的IP地址
bind * -::*
#后台运行
daemonize yes
#允许远程连接
protected-mode no
#开启集群模式
cluster-enabled yes
#集群节点超时时间
cluster-node-timeout 5000
#配置数据存储目录
dir "/opt/software/redis/cluster"
#开启AOF持久化
appendonly yes
#端口
port 6380
#log日志
logfile "/opt/software/redis/redis-stable/cluster/redis6380.log"
#集群配置文件
cluster-config-file nodes-6380.conf
#AOF文件名
appendfilename "appendonly6380.aof"
#RDB文件名
dbfilename "dump6380.rdb"使用如下命令生成配置文件,把上面配置文件的代码拷贝进去保存退出即可,需要注意配置文件的目录需要在redis-stable目录下的cluster目录中创建配置文件,或者根据自己实际情况去调整
vim ./cluster/redis_6379.conf
vim ./cluster/redis_6380.conf
然后分别启动三台机器的服务,启动命令如下
redis-server ./cluster/redis_6379.conf
redis-server ./cluster/redis_6380.conf
检查服务是否正常启动,可以用如下命令查看进程
ps aux|grep redis
可以发现,两个端口都已经通过集群模式成功启动了,如果发现6379端口不是集群模式启动,关闭服务再用上面的方式重新启动即可,但是发现之前的哨兵部署还在,可以用下面的命令关闭,三个机器都需要关闭一下
redis-cli -p 26379 shutdown
在一台机器上面创建redis集群,我在主节点机器上面创建集群,代码如下
redis-cli --cluster create --cluster-replicas 1 192.168.47.138:6379 192.168.47.138:6380 192.168.47.139:6379 192.168.47.139:6380 192.168.47.140:6379 192.168.47.140:6380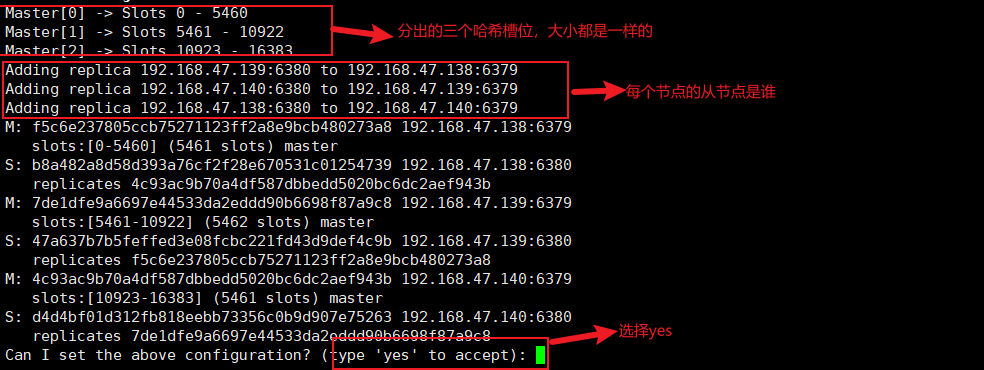
完成集群搭建
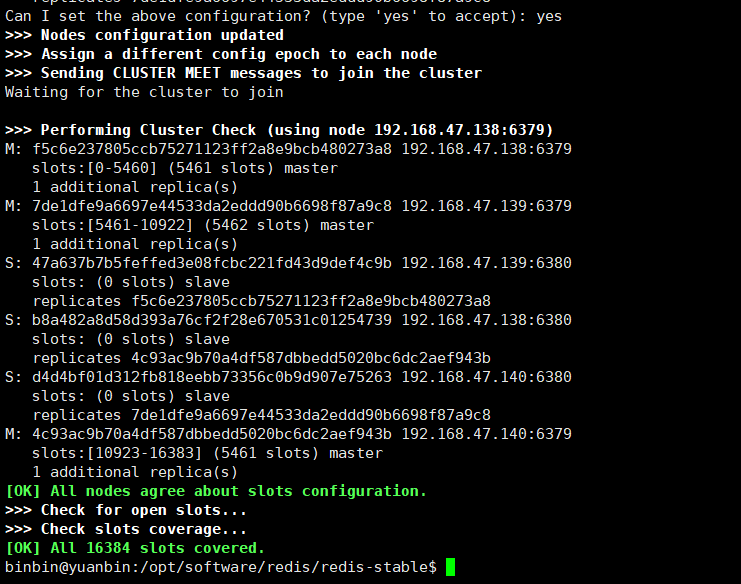
查看集群信息,使用如下命令
redis-cli cluster info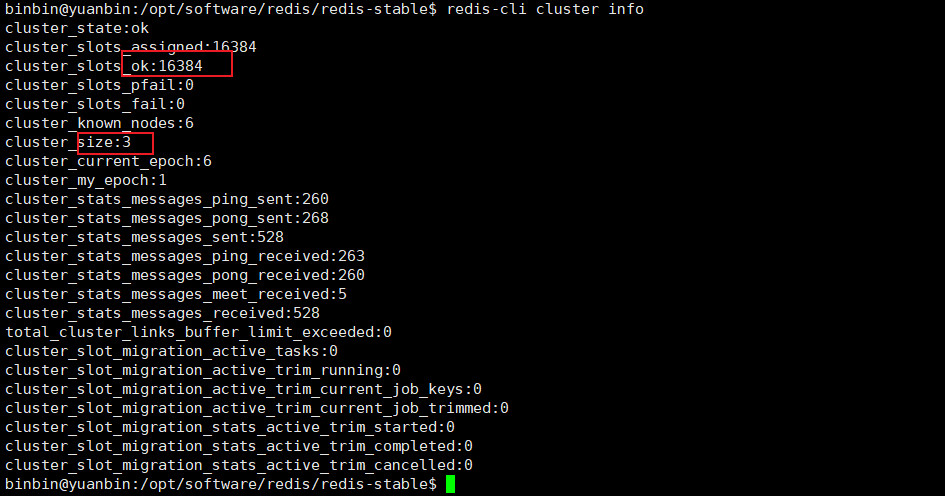
查看单个节点信息,命令如下
redis-cli info replication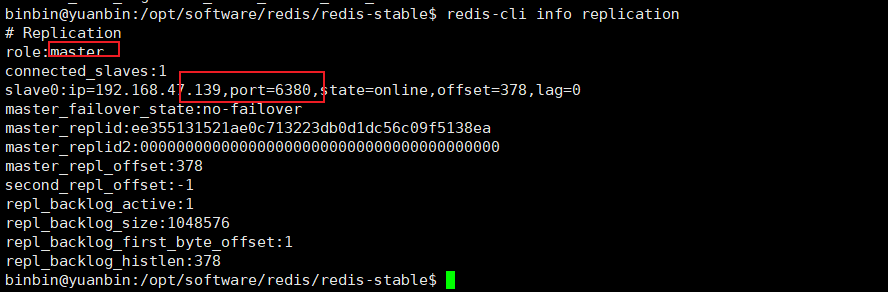
还可以使用下面的命令查看节点配置
redis-cli cluster nodes
模拟故障转移,如果当前的138:6379出现故障,那么它的从节点139:6380会晋升会主节点,可以在139:6380日志文件中查看
先打开139:6380日志文件,需要在cluster目录下打开,代码如下
tail -f redis6380.log 再回到138:6379这个机器,关闭该服务
再回到138:6379这个机器,关闭该服务

再回到139:6380的服务查看日志
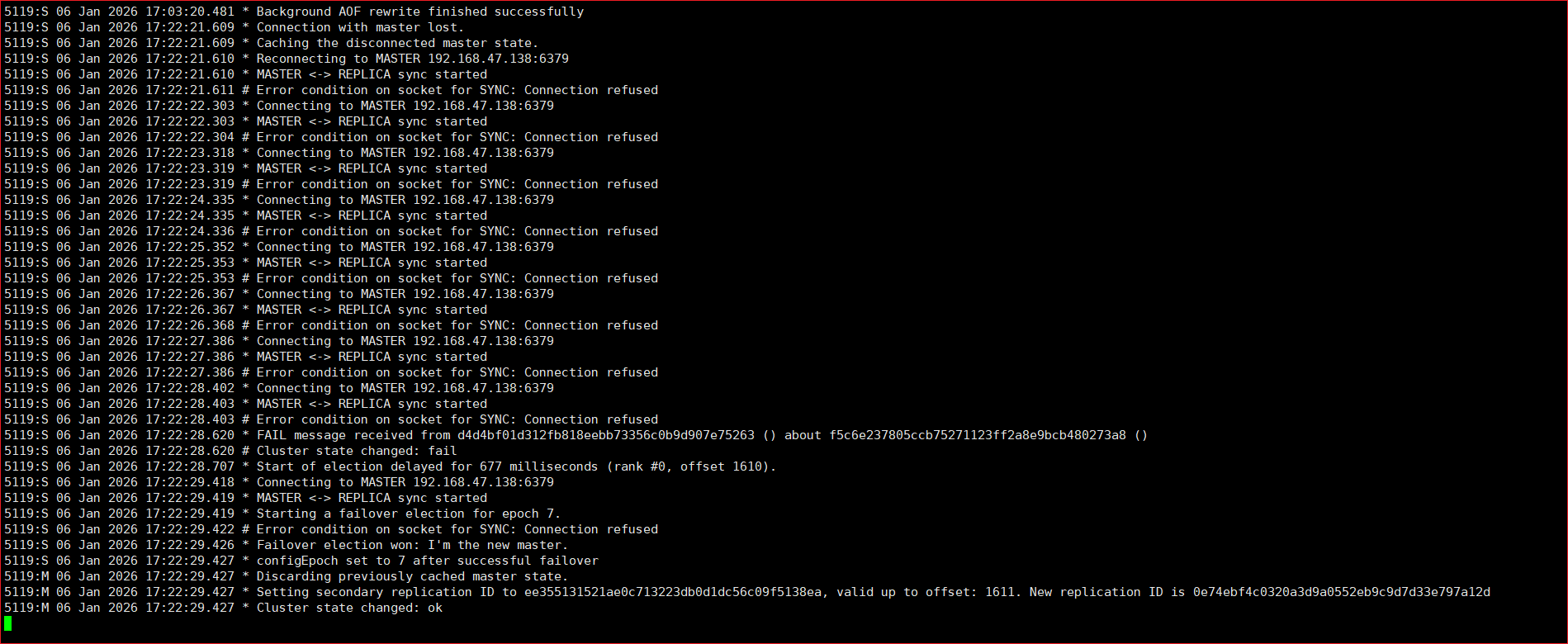
退出日志查看角色是否晋升,命令如下
redis-cli -p 6380 info replication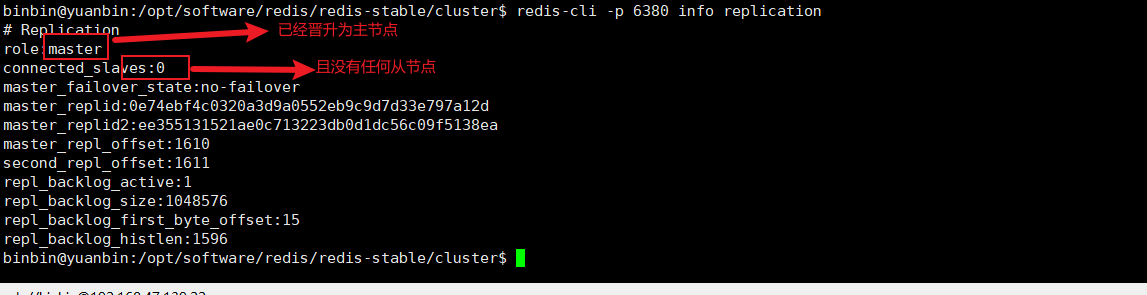
也可以查看当前集群节点信息
redis-cli cluster nodes
这时再将138:6379恢复,再查看139:6380的日志


再次查看节点信息,发现只有三个主节点了

三、客户端工具
1、使用官方Redis Insight
(1)安装
Redis Insight是官方推荐的客户端工具,功能齐全但是不支持中文
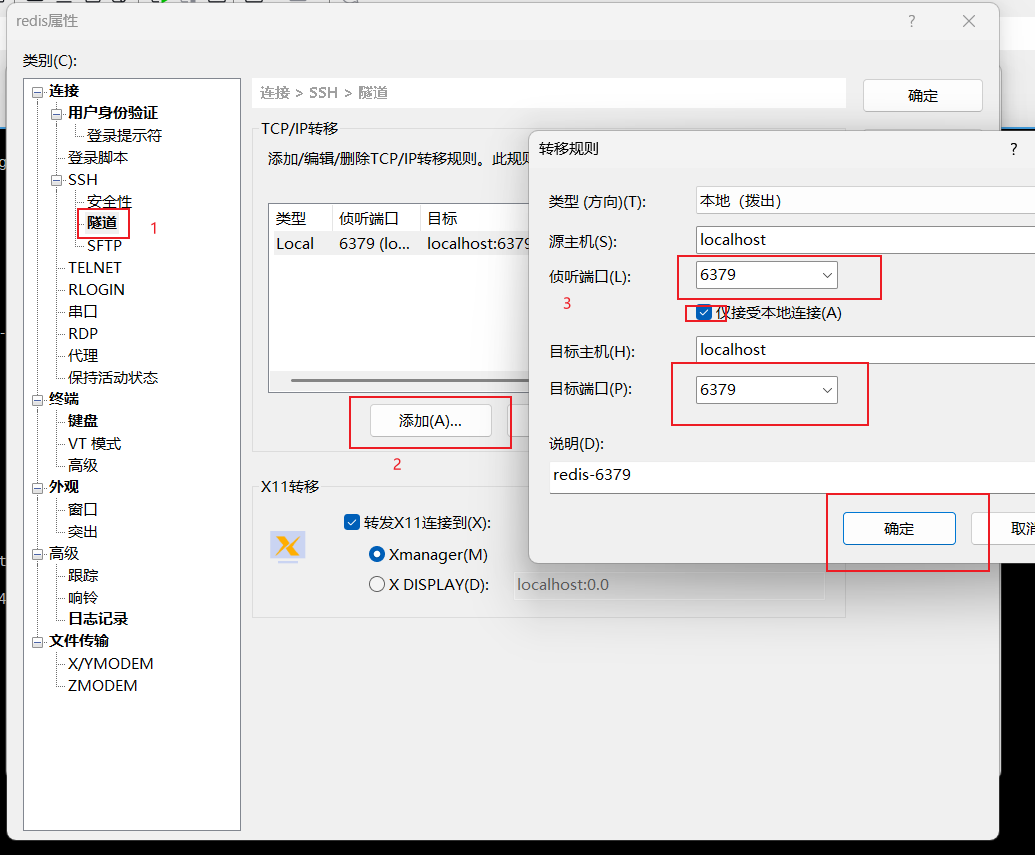
客户端安装在win系统上,但是我遇到一个问题,不能直接连接,需要使用xshell做本地端口转发,需要在xshell中右键你连接的,点击属性选择隧道添加端口转发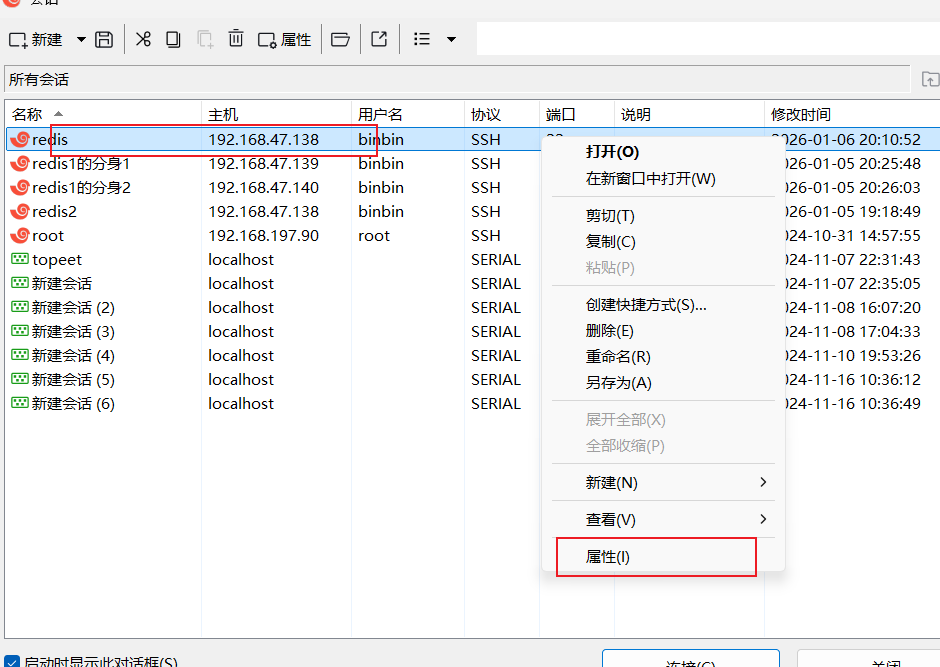
打开软件,如果你的win系统没有安装过redis相关服务,即可以成功连接上
进入设置修改主机
输入自己的主机号
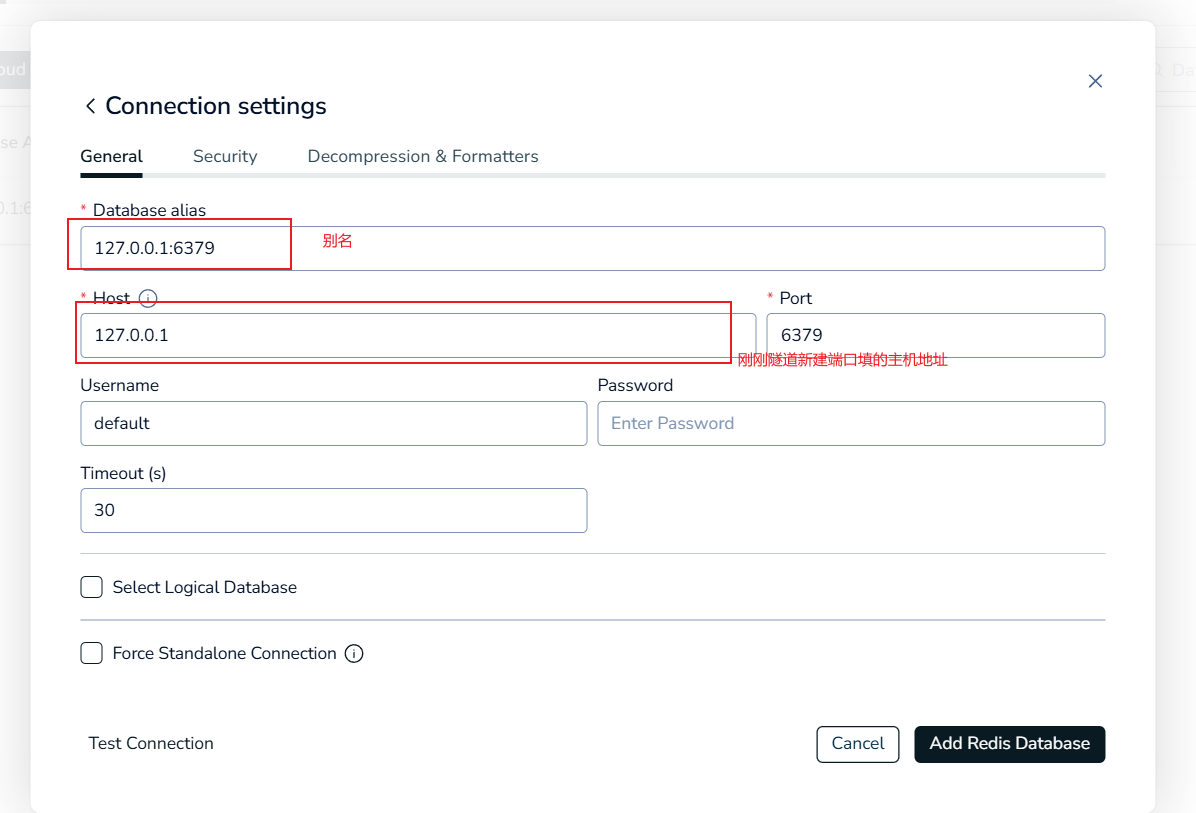
如果你和我一样不小心之前安装过redis相关服务,可以先检查一下
在 Windows PowerShell(管理员) 中执行:
netstat -ano | findstr :6379你会看到类似:
127.0.0.1:6379 LISTENING 12345然后立刻执行:
tasklist | findstr 12345可能结果:
| 进程名 | 含义 |
|---|---|
redis-server.exe |
✅ 本机 Redis |
docker.exe / com.docker.backend.exe |
Docker 里的 Redis |
wslhost.exe |
WSL 里的 Redis |
ssh.exe / xshell.exe |
才是端口转发(但你这次不是) |
我的就是有本地redis服务,现在只需要关闭即可(前提是完全不在win本机上使用redis服务,如像SpringBoot项目会使用,就不建议关闭了):
(1)停止服务(管理员 PowerShell)
sc stop redis或:
net stop redis(2)禁用自启动(防止复活)
sc config redis start= disabled(3)再次确认
netstat -ano | findstr :6379不应再有 LISTEN。
然后再按照上面的操作即可正常连接。
(2)使用
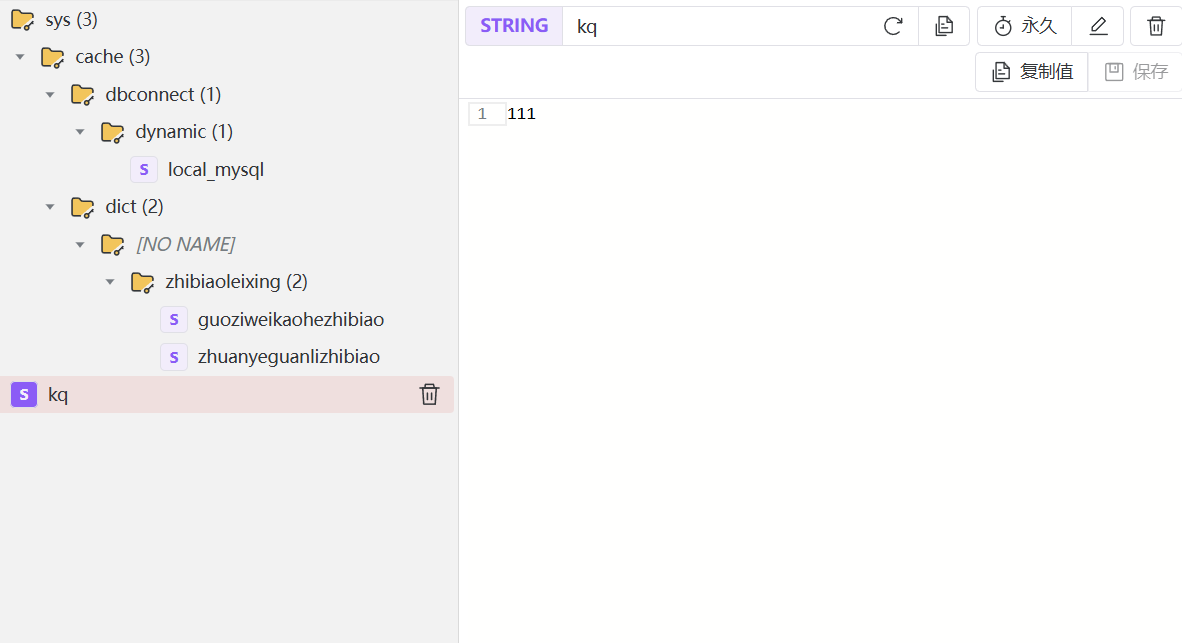
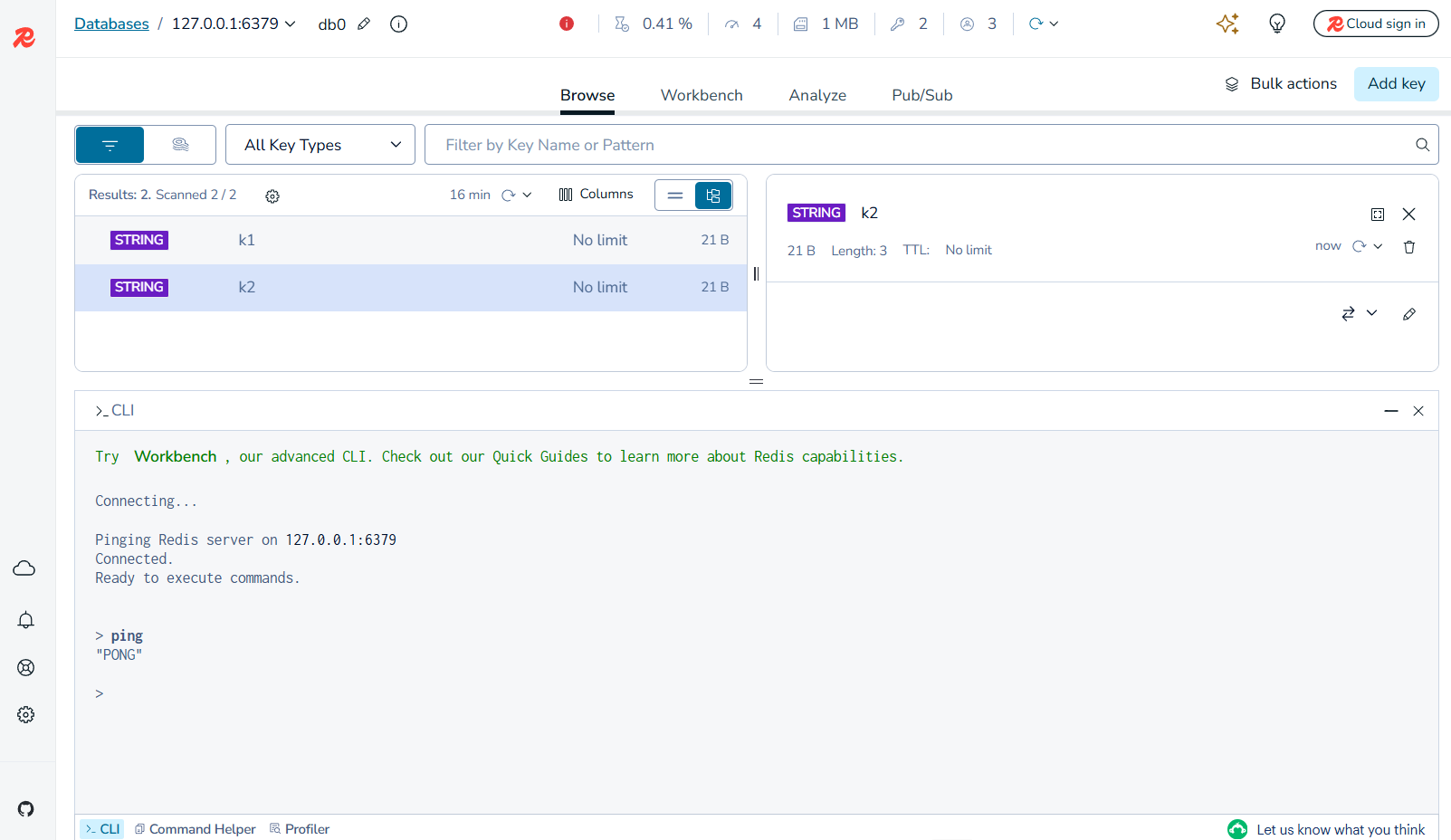
这是主页面,在该页面可以发现,它使用的是db0,redis默认有16各数据库;旁边可以查看cpu占用等一些系统参数;可以通过类型查,也可以通过名字来查;点击k1,可以直接在这修改他的值。
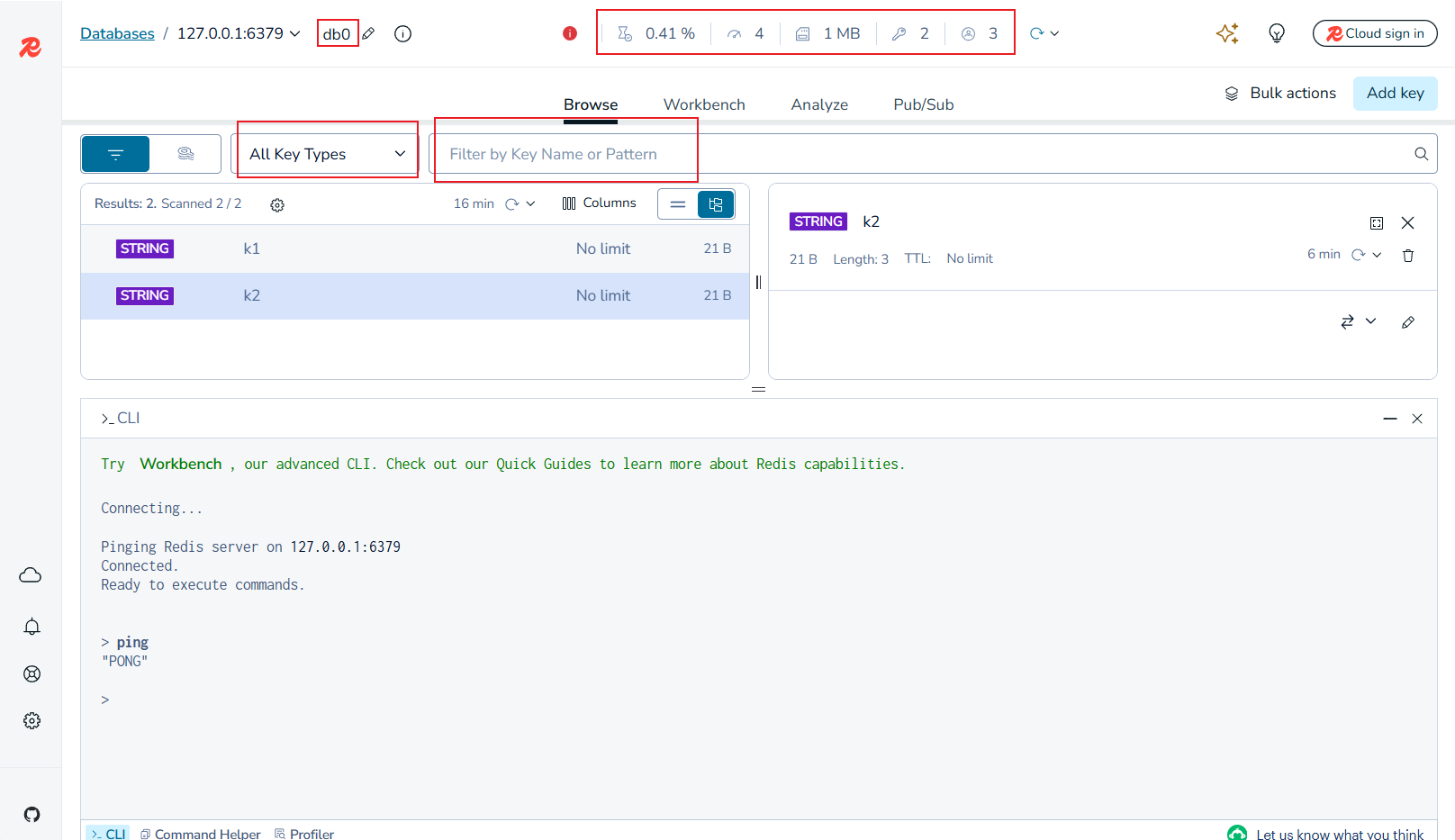
这是指令操作的页面,可以在最上面直接输入命令,但是执行完命令就自动清除看不见了;也可以点击下面的_CLI执行命令,就和xshell一样了;输入命令前可以点击Command Helper,可以帮忙解释我们的每一条指令,便于更好的理解。
提供的一些分析工具
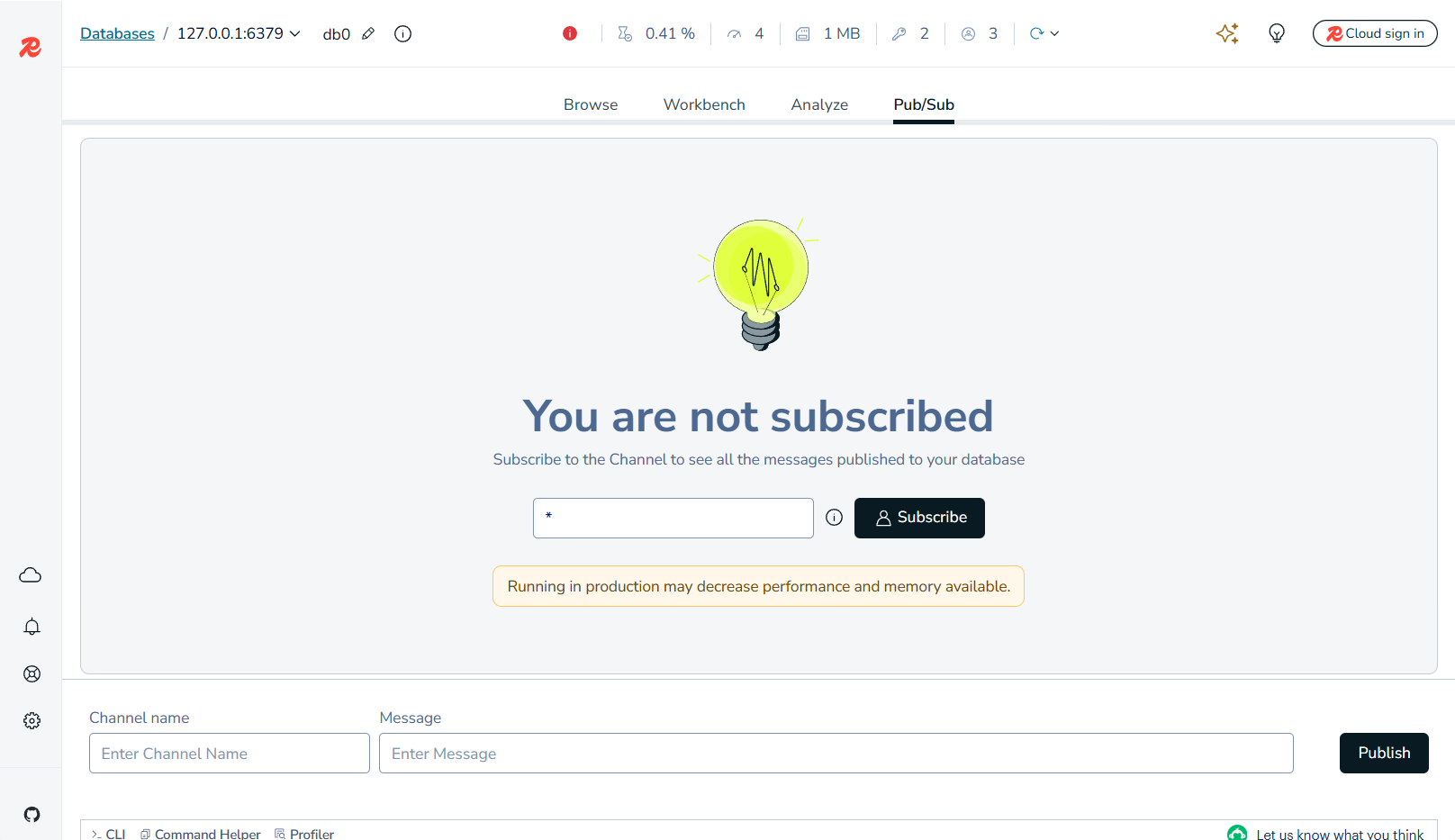
发布订阅页面
2、第三方工具Tiny RDB
(1)安装
选择自己电脑对应的安装包下载即可
然后正常安装即可,安装完成之后正常连接,连接之前一定要启动对应的redis服务,不然是无法连接的
进入之后,双击我们刚刚连接的redis服务打开它
(2)使用
打开之后的页面如下所示
系统的功能大致如下图所示,有兴趣可以自己再研究研究
3、SpringBoot连接redis
(1)创建SpringBoot项目
首先创建一个SpringBoot项目,打开pom.xml文件,添加对应的redis依赖
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.7.18</version>
</dependency>
<!--Json序列化依赖-->
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
<version>2.13.0</version>
</dependency>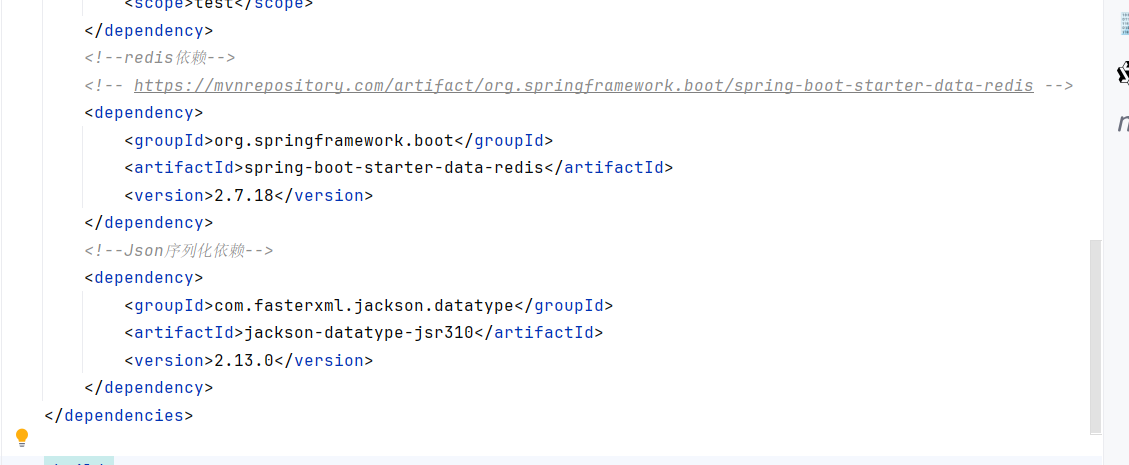 (2)配置Redis参数
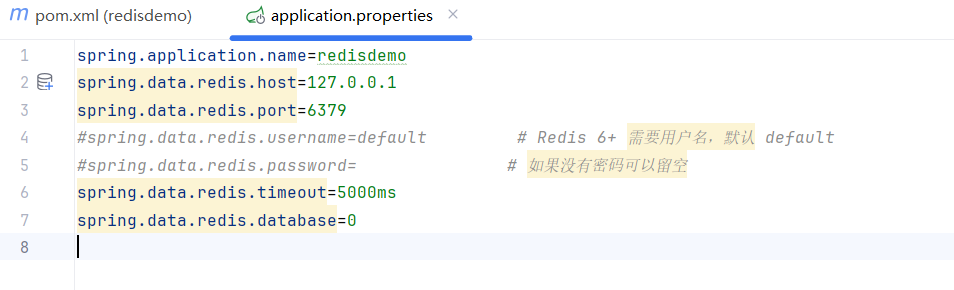
(2)配置Redis参数
在SpringBoot的配置文件application.properties中配置 Redis 相关参数
(3)配置 RedisTemplate
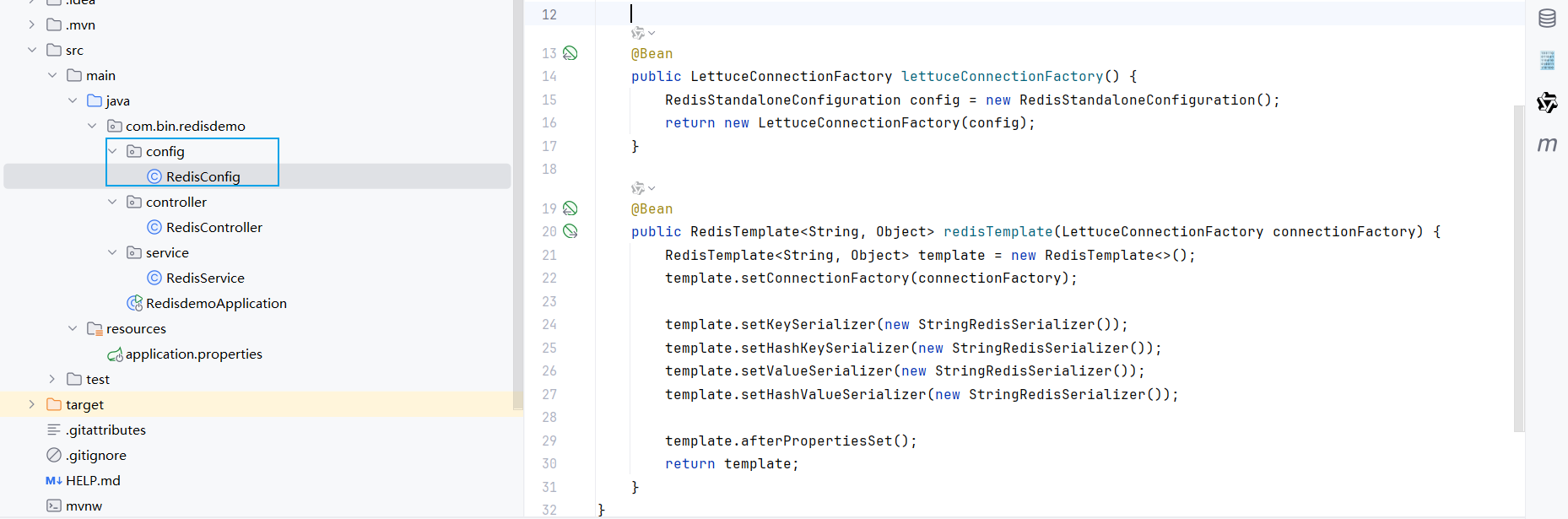
目的是规范 Redis 的序列化方式,让 Redis 操作更方便、数据存储更易读。
@Configuration
public class RedisConfig {
@Bean
public LettuceConnectionFactory lettuceConnectionFactory() {
RedisStandaloneConfiguration config = new RedisStandaloneConfiguration();
return new LettuceConnectionFactory(config);
}
@Bean
public RedisTemplate<String, Object> redisTemplate(LettuceConnectionFactory connectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
template.setKeySerializer(new StringRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new StringRedisSerializer());
template.setHashValueSerializer(new StringRedisSerializer());
template.afterPropertiesSet();
return template;
}
} (4)添加Redis服务
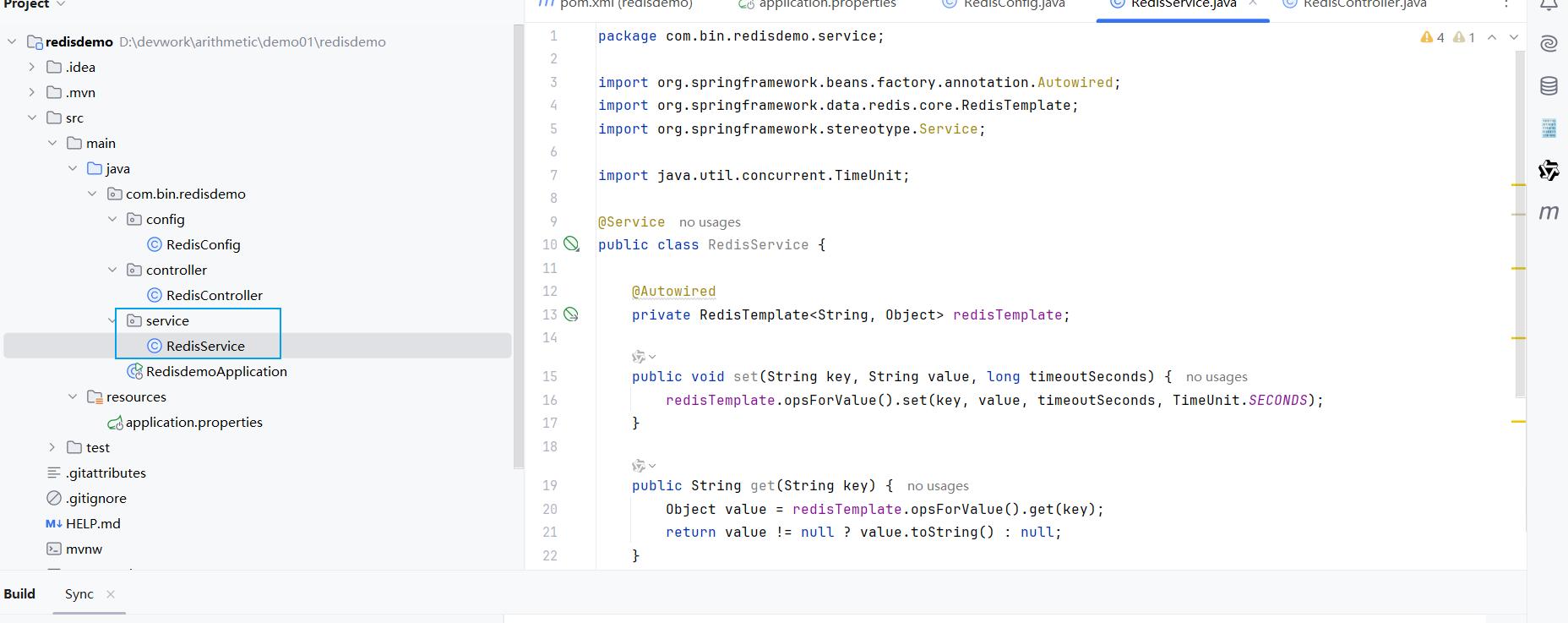
(4)添加Redis服务
封装 Redis 的常用操作(存、取、删),让业务代码更简洁易维护。
@Service
public class RedisService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public void set(String key, String value, long timeoutSeconds) {
redisTemplate.opsForValue().set(key, value, timeoutSeconds, TimeUnit.SECONDS);
}
public String get(String key) {
Object value = redisTemplate.opsForValue().get(key);
return value != null ? value.toString() : null;
}
public void delete(String key) {
redisTemplate.delete(key);
}
}
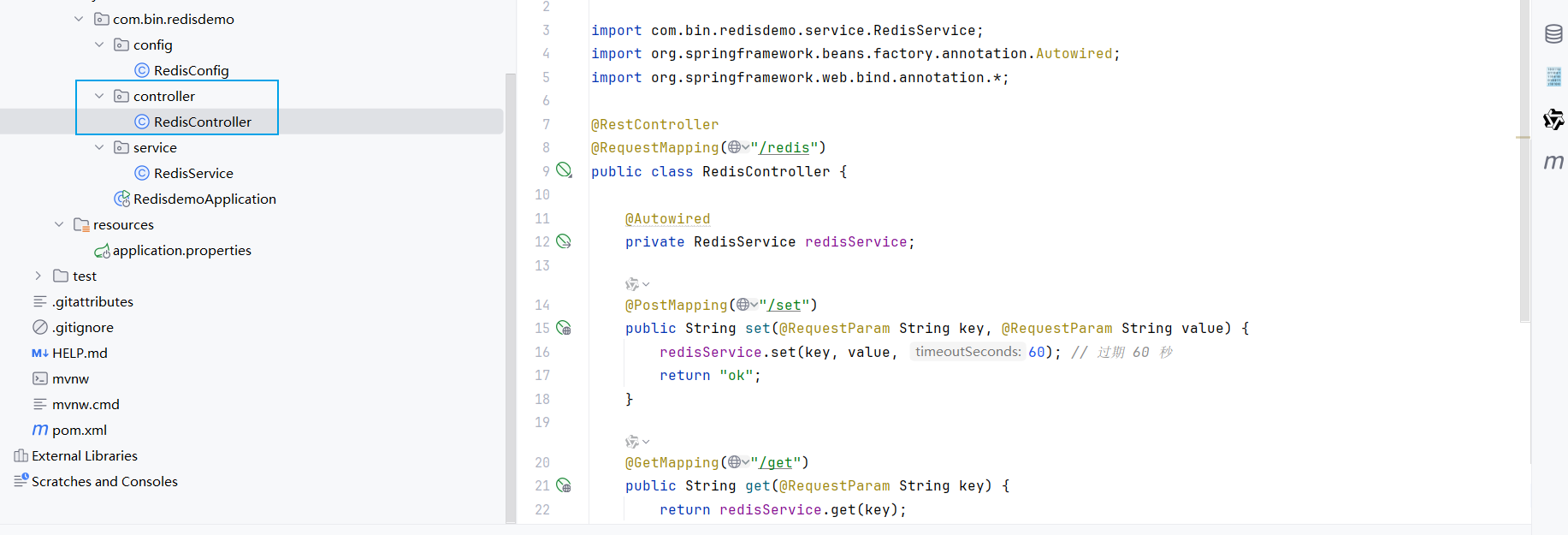
(5)添加控制器
作用是对外提供 HTTP 接口,让前端 / 其他服务可以通过网络请求操作 Redis(调用之前写的RedisService)。
还需要添加两个依赖:
<!-- Spring Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>代码如下:
@RestController
@RequestMapping("/redis")
public class RedisController {
@Autowired
private RedisService redisService;
@PostMapping("/set")
public String set(@RequestParam String key, @RequestParam String value) {
redisService.set(key, value, 60); // 过期 60 秒
return "ok";
}
@GetMapping("/get")
public String get(@RequestParam String key) {
return redisService.get(key);
}
@DeleteMapping("/delete")
public String delete(@RequestParam String key) {
redisService.delete(key);
return "deleted";
}
}
(6)测试
首先启动redis服务
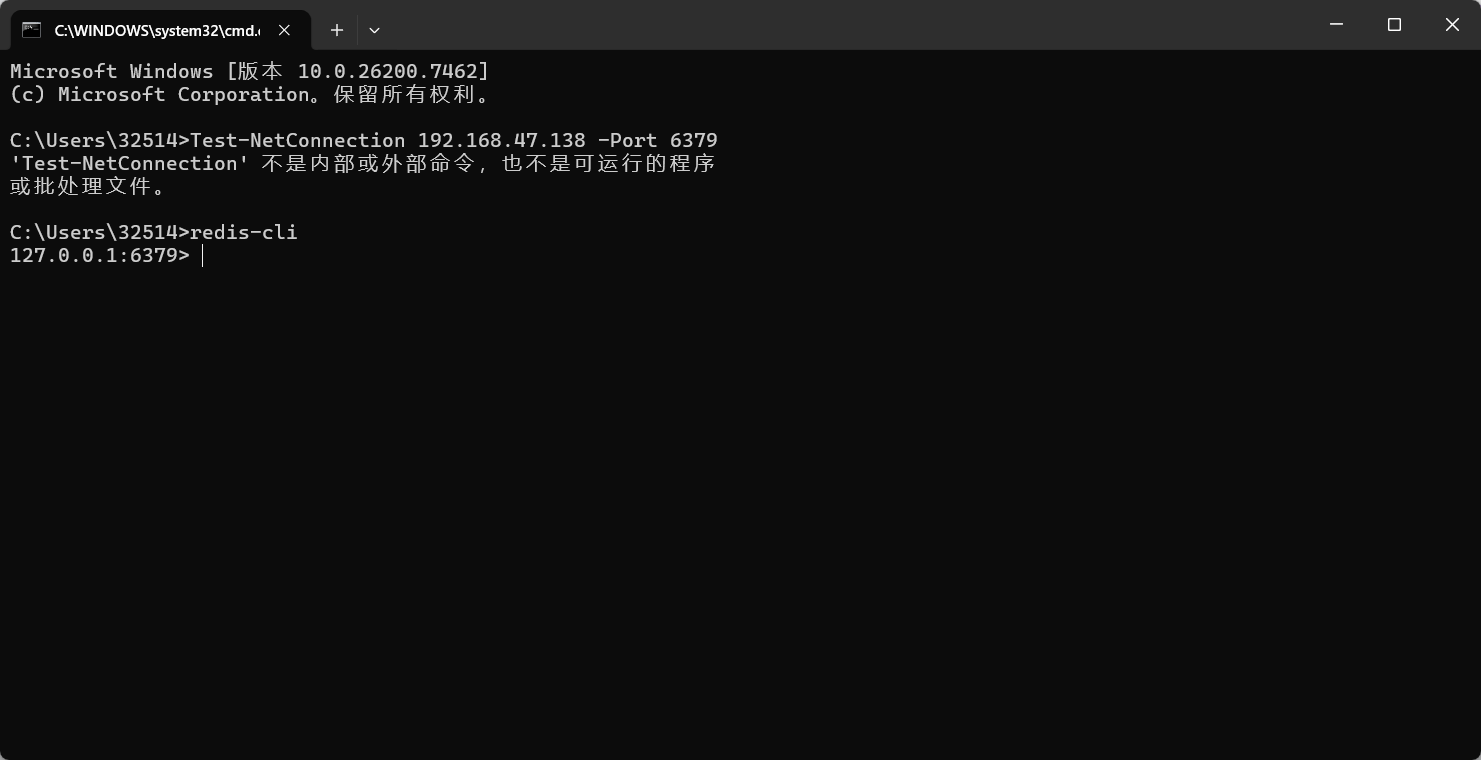
如图所示就是启动成功了
再启动SpringBoot项目

再用postman测试接口
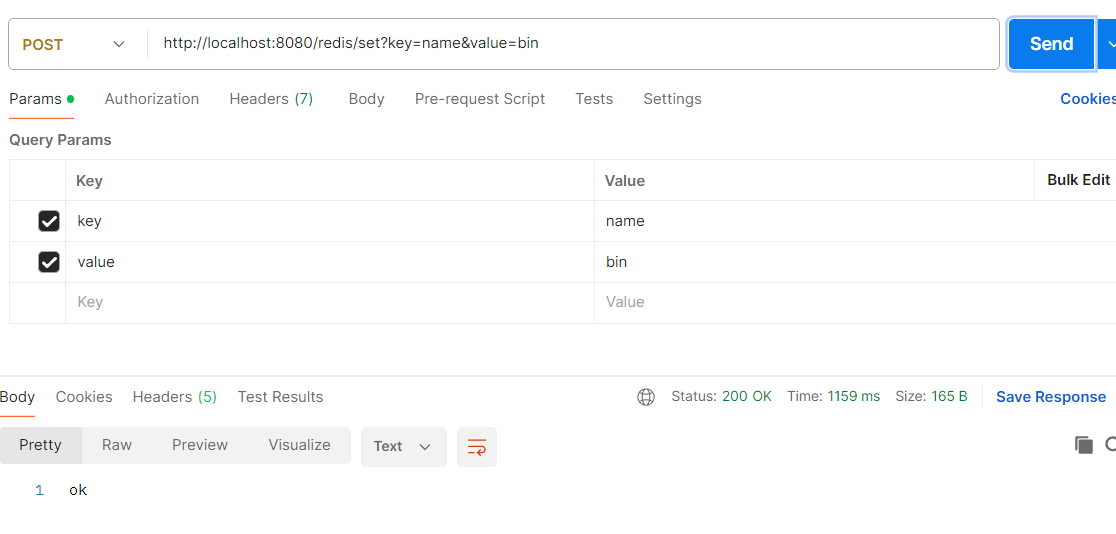
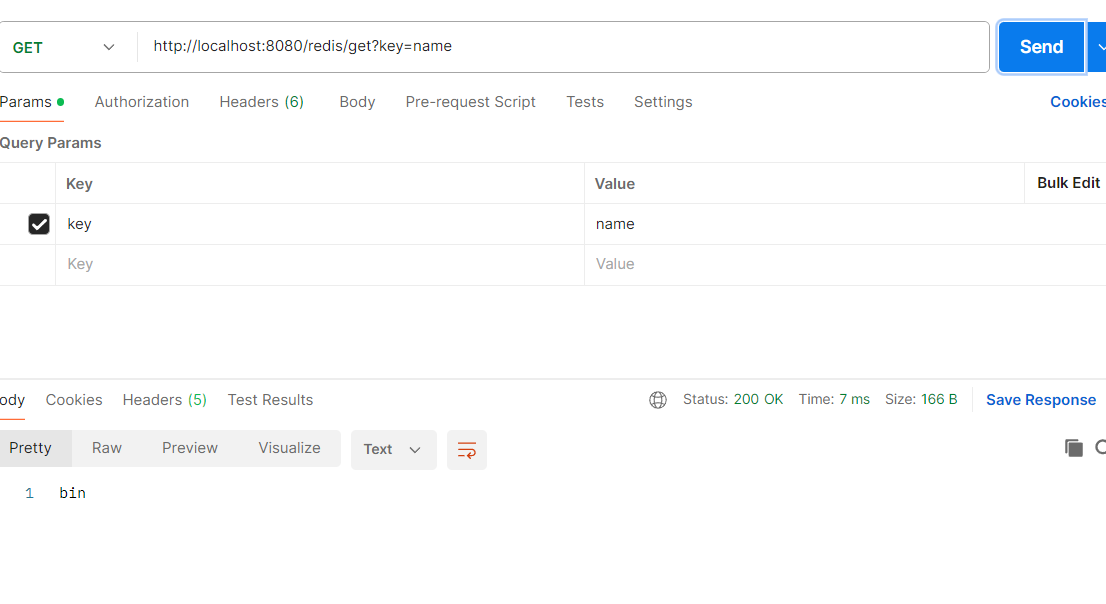
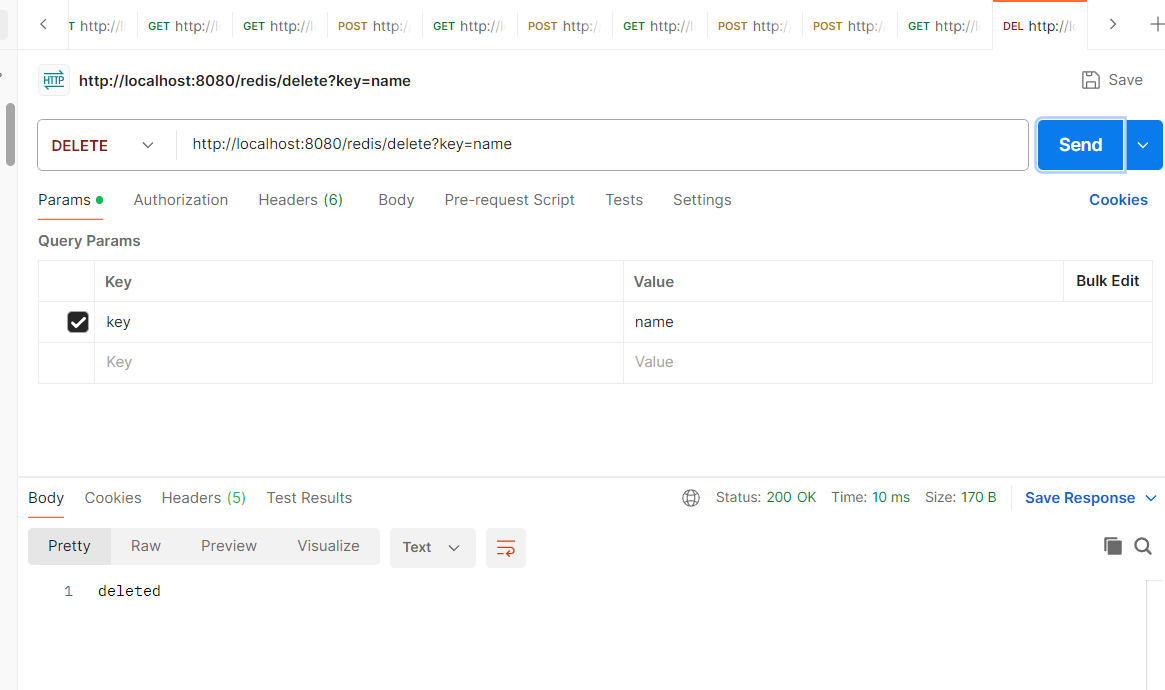
也可以使用可视化软件查看