文章目录
HTTP的基本概念
超文本传输协议是一种使用非常广泛的用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础。前端的HTML,HTML全称为超文本标记语言,HTTP协议最开始就是为了传输HTML页面数据来制定的一种协议。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
请求与响应
HTTP协议是基于TCP/IP协议之上的应用层协议 。是基于 请求-响应 的通信模式。
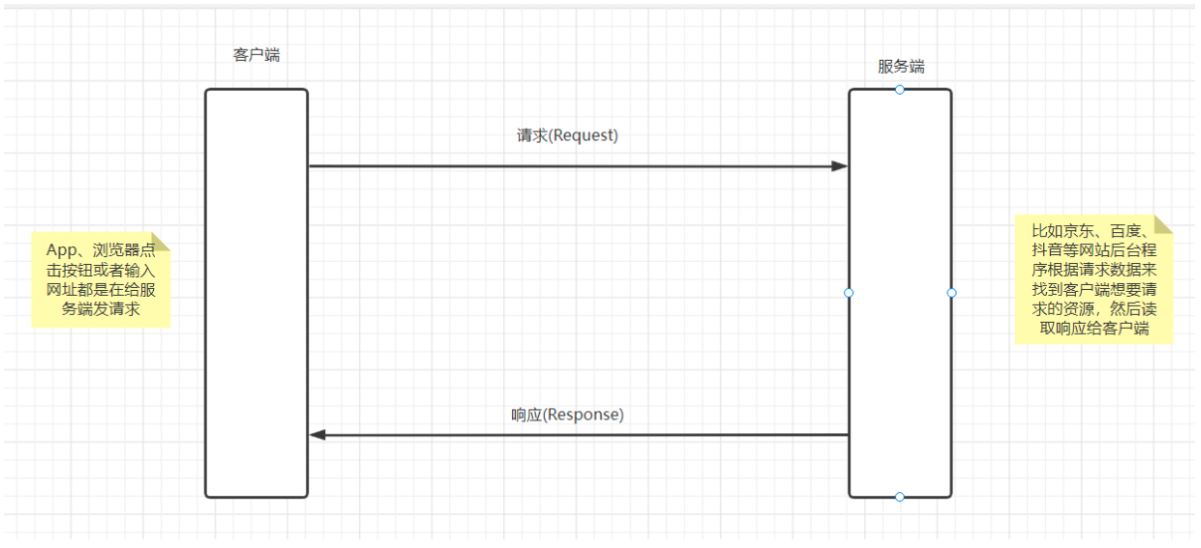
在浏览器地址栏键入网址,按下回车之后会经历以下流程:
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和HTTP协议默认端口 80,和服务器建立TCP连接;
- 浏览器发出读取服务端资源的HTTP请求,比如请求一个网站页面,我们知道我们在浏览器上看到的每一个
页面其实都是对应着服务端的某个HTML代码文件 - 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
- 客户端收到数据之后释放TCP连接;
- 浏览器将该html文件代码程序解析执行,展示页面效果
HTTP协议的特点
- 明文传输
- 无状态保存
自身不对请求和响应之间的通信状态进行保存。即在HTTP这个协议对于之前发送过的请求或响应里面携带的数据都不做持久化处理。
即便用户输入用户名和密码登录了这个网站,当操作网站上的其他功能的时候,还需再输入用户名和密码,因为上一次输入数据的和下一次HTTP请求已经没有关系了,每次请求都是一个新的HTTP请求,并且HTTP协议加工数据的时候,不会携带上一次的请求数据,导致没办法进行会话维持。
后续就出现了Cookie、Session、等技术来进行会话维持,也就是保持客户端和服务端的登录状态,方便用户操作
- 无连接
每次请求独立处理 :客户端发送一个HTTP请求后,服务器返回响应,随后连接立即关闭(默认行为)。下一次请求需要重新建立新的TCP连接。
无状态:无连接的设计也导致HTTP本身是无状态的,服务器不会默认记住之前的请求信息(需依赖Cookie/Session等机制)
优点:
- 简化实现:无连接设计让客户端实现更简单,无需维护持久连接,适合资源有限的设备。
- 降低资源消耗:每次请求后连接关闭,减少了客户端和服务器的资源占用,尤其在高并发场景下。
- 提高可扩展性:无连接设计使服务器能处理更多请求,避免因过多持久连接导致资源耗尽。
缺点:
- 性能开销:每次请求都需重新建立连接,增加了延迟,尤其在高延迟网络中。
- 缺乏状态管理:无连接设计要求每次请求都携带完整信息,增加了数据传输量,可能 影响性能。
- 不适合实时应用:无连接设计不适合需要实时通信的场景,如在线游戏或即时通讯
HTTP状态码
1XX(信息性状态码)------服务器已接收请求,正在处理中
2XX(成功状态码)------请求成功被服务器接收、理解并处理
3XX(重定向状态码)------客户端需要采取进一步的操作才能完成请求,通常是进行资源的重定向
4XX(客户端错误状态码)------客户端发送的请求存在问题导致服务器无法处理
5XX(服务器错误状态码)------服务器在处理请求时出现了错误
200 :ok 请求成功
302:临时重定向
404:not found 服务端没有请求的资源
400:客户端请求错误
500:服务器内部发生错误
HTTP的请求
请求方法
GET: 请求获取资源。
POST: 提交数据(通常会导致服务器状态变化)。
PUT: 替换整个资源。
PATCH: 部分更新资源。
DELETE: 删除资源。
HEAD:和 GET 类似,服务器只返回头部信息,不返回正文内容,常用来获取资源的元信息
OPTIONS:用于查询服务器针对特定资源所支持的 HTTP 方法
TRACE 等。
POST和GET的区别
-
GET请求用于向服务端获取数据
POST请求用于向服务端提交数据,主要用于添加数据
-
数据所在位置不同,能携带的数据长度不同
由于get方法携带的数据在url上,那么携带的数据大小就有长度限制了,因为url长度有上限,比如IE限制url长度不能超过2083个字符,不同浏览器上限不同,但是都有上限。RFC 标准明确说明,不对URL进行长度限制,但是浏览器一般都会做限制。
post方法携带的数据在请求数据部分,理论上是没有大小限制的
-
安全性不同
get方法携带的数据在url上,数据会在浏览器地址栏显示出来,没有对数据进行加密的话,直接就可以在地址栏看到明文信息,安全性低
post方法携带的数据在请求数据部分,在浏览器上是不会直接显示出来的,但可通过抓包获取,所以数据不加密是没有安全性可言的。所以表面上post比get安全性高一些,但差不多
-
可传输的数据格式不同
GET只能传输文本数据
POST可以传输文本和二进制数据
但是其实GET完全可以传输文本和二进制数据,只需要对二进制数据urlencode即可,也就是URL编码一下。
-
幂等性不同
GET 请求的处理,实现成"幂等"的
POST 请求的处理,不要求实现"幂等"
-
缓存机制
幂等性概念:幂等通俗来说是指不管进行多少次重复操作,都是实现相同的结果
请求数据格式
HTTP 请求格式由四部分组成:请求行(Request Line)、请求头(Request Headers) 、空行、请求体(Request Body)
1、请求行
由三部分组成
方法 (Method): 指定要对资源执行的操作。常见的有:
请求目标 (Request Target): 通常是 URL 的路径和查询部分,例如 /api/users?page=2。它指定了请求所指向的资源。
HTTP 版本 (HTTP Version): 声明使用的 HTTP 协议版本,如 HTTP/1.1 或 HTTP/2。
格式:
方法 + 空格 + 请求目标 + 空格 + HTTP版本
2 、请求头
请求头(Request Headers): 提供关于请求本身、客户端环境及其期望的更多信息。例如:
Host: 必需字段。指定服务器的域名和端口号。Host: www.example.com
User-Agent: 描述发起请求的客户端(浏览器、操作系统等)。User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...
Accept: 告知服务器客户端能够处理哪些类型的响应内容(MIME 类型)。Accept: text/html,application/json,image/webp,/
Accept-Language: 客户端偏好语言。Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8
Authorization: 包含用于认证的凭证,如 Bearer token。Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...
Referer:表示发出请求的原始URL
Cookie:携带客户端存储的 Cookie 数据(通常包含 Session ID、用户偏好等),用于维持用户会话状态。
3、请求体
客户端给服务端提交的数据
响应数据格式
HTTP 响应格式由四部分组成:响应行、响应头 、空行、响应体
状态行
由 HTTP 协议版本、状态码以及状态码对应的简短描述组成,比如 "HTTP/1.1 200 OK"。
响应头部
键值对形式,向客户端传递诸如服务器类型、响应内容的类型、长度等信息。
- Content-Type
用于告知客户端响应内容的媒体类型,以便客户端能够正确地解析和处理接收到的数据。例如,浏览器会根据这个字段来决定是以 HTML 格式渲染页面,还是以图片、脚本等其他格式来处理相应内容。
bash
*Content-Type: text/html; charset=UTF-8*
表示响应内容是 HTML 文本,并且字符编码采用 UTF-8,常见于网页内容的返回。
*Content-Type: application/json*
说明响应的是 JSON 格式的数据,常用于 Web API 返回数据给客户端时,方便客户端进行 JSON 解析获取具体的业务数据。
*Content-Type: image/jpeg*
意味着响应体中包含的是 JPEG 格式的图片数据,浏览器会据此对图片进行展示。- Set-Cookie
由服务器发送给客户端,用于在客户端(浏览器)创建、更新或删除 Cookie。Cookie 常用于维持用户会话状态、记录用户偏好等,通过这个响应头来设置相关的属性和值,并传递给客户端存储和后续携带使用。
bash
Set-Cookie: sessionid=abc123; Path=/; HttpOnly; Secure
创建了一个名为 "sessionid",值为 "abc123" 的 Cookie,其作用路径为整个网站("Path=/"),设置了 HttpOnly 属性(防止 JavaScript 访问该 Cookie,增强安全性),同时具备 Secure 属性(仅在 HTTPS 连接下传输,避免 HTTP 抓包窃取)。
Set-Cookie: username=guest; Expires=Wed, 05 Oct 2025 18:00:00 GMT; Max-Age=3600
设置了一个名为 "username" 的 Cookie,指定了过期时间(这里是 2025 年 10 月 5 日 18 时,采用 GMT 时间格式),同时通过 Max-Age 设置了存活时长为 3600 秒(即 1 小时)。空行
分隔响应头部和响应体。
响应体
包含服务器返回给客户端的实际数据,比如网页的 HTML 代码等。
解决无状态的机制
Cookie
(一)概念
Cookie是服务器发送到用户浏览器并保存到本地的一小段数据,它会在浏览器下次向同一服务器发送请求时被携带并发送到服务器端
(二)工作原理
- 创建与发送
当用户访问浏览器时,服务器可通过HTTP响应头中的Set-Cookie字段向浏览器发送Cookie - 存储与发送
浏览器收到Cookie后,会将其存储在本地。当浏览器再次向该服务器发送请求时,会在HTTP请求头的Cookie字段中带上这些Cookie
(三)应用场景
- 保持用户登录状态:记录用户的登录信息,下次访问时自动登录
- 个性化设置:存储用户的偏好设置,如字体大小、语言等
Session
(一)概念
Session是服务器端用于跟踪用户会话状态的机制。他会在服务器上保存用户的相关信息,每个用户有一个唯一的Seission ID。
(二)工作原理
- 创建Session:当用户首次访问服务器,服务器会创建一个Session,并生成一个唯一的Session ID。服务器可通过Cookie将Session ID发送给浏览器,也可以通过URL重写等方式传递。
- 验证Session:后续浏览器每次请求,都会携带Session ID。服务器根据Session ID找到对应的Session,获取用户的会话信息。
(三)Session的局限
与cookie强绑定:session的核心标识(Session ID)通常依赖Cookie传递,因此继承了Cookie的同源策略、CSRF风险等问题。
扩充
URL和URI
- URI(统一资源标识符):
是一个用于唯一标识互联网上资源的字符串,它不仅可以标识网页,还可以标识文件、电子邮件地址、目录、服务(如FTP服务)等任何可以通过网络访问的资源 - URL(统一资源定位符):
是 URI 的一种具体形式,不仅标识资源,还明确了如何访问该资源(例如通过 HTTP、FTP 等协议)
所有 URL 都是 URI,但并非所有 URI 都是 URL。URI 除了包含 URL,还包括另一种形式:URN(Uniform Resource Name,统一资源名称)。
http://user:pass@www.test.com:80/dir/index.html?uid=1#ch1
端口
- 静态端口(1-1023):给常见的协议使用
| 服务 | 端口号 |
|---|---|
| HTTP | 80 |
| FTP | 20、21 |
| SSH | 22 |
| HTTPS | 443 |
- 动态端口 1024-65535
真正的动态端口在5w多之后了,1024-5xxxx之间的称为注册端口:有一部分被协议固定使用了,但是使用的太少了