AIGC
AIGC爆发元年:2023
什么是AIGC?AI Generated Content,利用AI创造内容。据某权威机构,未来10年,互联网AIGC内容占比将达到50%。
机器学习知识补充
无监督学习 vs 有监督学习
无监督学习和有监督学习都是机器学习中常见的方法。
有监督学习是指使用带有标签的数据来训练模型,以便在未来对新数据进行分类或预测。在有监督学习中,模型需要学习从输入数据中提取特征,并将其与相应的标签进行关联。优点是可以获得高精度的预测结果,缺点是需要大量标记数据来训练模型。
无监督学习是指使用未标记的数据来训练模型,以便从数据中发现隐藏的结构、模式或特征。在无监督学习中,模型需要自己发现数据中的规律和模式,而不需要人为指定标签。优点是可以利用大量未标记数据来训练模型,缺点是难以评估模型的性能和效果。
总之,有监督学习适用于预测任务,需要大量标记数据来训练模型;而无监督学习适用于聚类、降维和异常检测等任务,可以利用大量未标记数据来训练模型。在实际应用中,通常需要根据具体问题选择合适的方法或结合两种方法来进行训练。
Sklearn常用算法:
无监督学习算法:
- 聚类算法:K-Means、层次聚类、DBSCAN等。
- 降维算法:主成分分析(PCA)、独立成分分析(ICA)、t-SNE等。
- 关联规则学习算法:Apriori、FP-Growth等。
- 异常检测算法:孤立森林、LOF(局部离群因子)等。
有监督学习算法:
- 分类算法:决策树、支持向量机(SVM)、逻辑回归、随机森林等。
- 回归算法:线性回归、岭回归、梯度提升回归等。
- 神经网络算法:多层感知器(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)等。
- 集成学习算法:AdaBoost、Bagging、随机森林等。
强化学习
强化学习是一种机器学习方法,奖罚机制在强化学习中起着至关重要的作用,通过试错和奖励来学习最优决策策略。
神经网络模型
神经网络模型强调"模型"这个概念,是因为它是一种数学模型,用于描述神经网络的计算过程和行为。虽然神经网络模型最终需要通过编程语言来实现和运行,但它本质上是一种抽象的数学概念,用于描述神经元和它们之间的连接、权重、偏置等参数的计算过程。
常见神经网络模型:CNN、RNN等
GPT通识基础
什么是GPT
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的自然语言(NLP)模型。
- Generative:基于概率的生成式模型,通过预测下一个文字出现概率来输出
- Pre-trained:通过大量无标签样本数据进行训练
- Transformer:能够设置海量神经元并拥有强劲的自然语言处理性能,GPT3拥有1750亿以上的神经元。
什么是大模型
大模型全称为LLM(Large Language Model) 是指大型的自然语言处理(NLP)模型,这些模型通常具有大量的参数,能够在海量无标签数据上进行预训练,从而学习到丰富的语言表示和知识。
GPT vs 大模型
结论:GPT本质是一种模型范式,是大模型的一种,拥有大量参数和通过海量训练,例如GPT3。其他任何模型如果足够"大",都可以成为大模型。
- 如OpenAI在2018年发布GPT1时,并不是"大模型",只是验证了GPT模型本身的有效性。
GPT vs NLP
- NLP更多的是有监督学习,针对某一类数据集进行训练,而大模型是无监督学习(海量知识的学习),再在某个领域进行微调得到。
- NLP是基于RNN神经网络训练,强调的是自然语言理解能力和简单的交互,而GPT采用Transformer架构,通过对问题向量词进行重构,来更好的理解自然语言,且具有强大的生成能力。
- Transformer模型解决了以前模型关注不到上下文的信息的问题。
ChatGPT vs GPT
ChatGPT是基于GPT模型构建的基于web端的聊天机器人。而GPT本质是一个模型,这个模型可以通过接口(API)进行调用,类似sklearn,可以在不同的场景进行调用,以完成对应的NLP任务。
openAI开发平台
https://www.platform.openai.com,注意:必须外服,港服不行
全球开源大模型性能评估榜
Hugging Face: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
开源大模型学习推荐
- ChatGLM:
清华大学团队开发的ChatGLM6B(60亿)参数规模的模型,根据智谱AI公司的GLM-130B修改而来,支持个人GPT部署和使用,最低6G显存即可使用; - LLAMA:Meta公司"被"开源的大模型,参数量可调6B-65B之内,训练复杂度高于chatGLM。
- GPT4ALL:训练数据集采用OpenAI GPT-3.5-Trubo模型创建的对话语料,相当于用AI训练AI
- 其他开源大模型:miniGPT4,来自沙特国安大学的华人团队,具备多模态能力,即除了识别文字外,还可以识别图像。
提示词工程
提示工程(Prompt Engineering) 是一种针对大模型的技术,旨在通过设计合适的输入提示来引导模型生成更准确、更相关的输出结果。
开源提示词库Awesome ChatGPT Prompts:https://prompts.chat/
提示词技巧:
- 技巧1:角色+场景+任务+规则
- 技巧2,提供样例:
- zero-shot
- one-shot
- few-shot
- 技巧3:思维链(Chain of Thought)
思维链的本质:将复杂任务拆解为多个简单的子任务。
为什么要用到思维链?
思考这样一个问题:人类为什么不能直接一眼看出一道数学难题的答案,而是经过解题步骤的一步步推导,就大概能得到正确的答案? -- 没有足够的思考时间。
而GPT同样如此,一步步思考可以充分利用它的算力。
- 技巧4:用结构化数据来代替文字描述
优点:- 能够节省大量文字描述;
- 节省tokens消耗;
- 能够轻松表达复杂数据之间的结构关系。
json本质上还是文本。
json
{
"AI_Tutor": {
"Python": {
"beginner": {
"description": "你是一名初级研发工程师,帮我..."
},
"professional": {
"description": "你是一名资深的架构师,帮我..."
}
},
"Java": {
},
"WEB": {
}
}
}总结
不断叠加技巧,不断叠加buff,才能让GPT给我们的内容更精准。
GPT联动搜索引擎,解决prompt问题
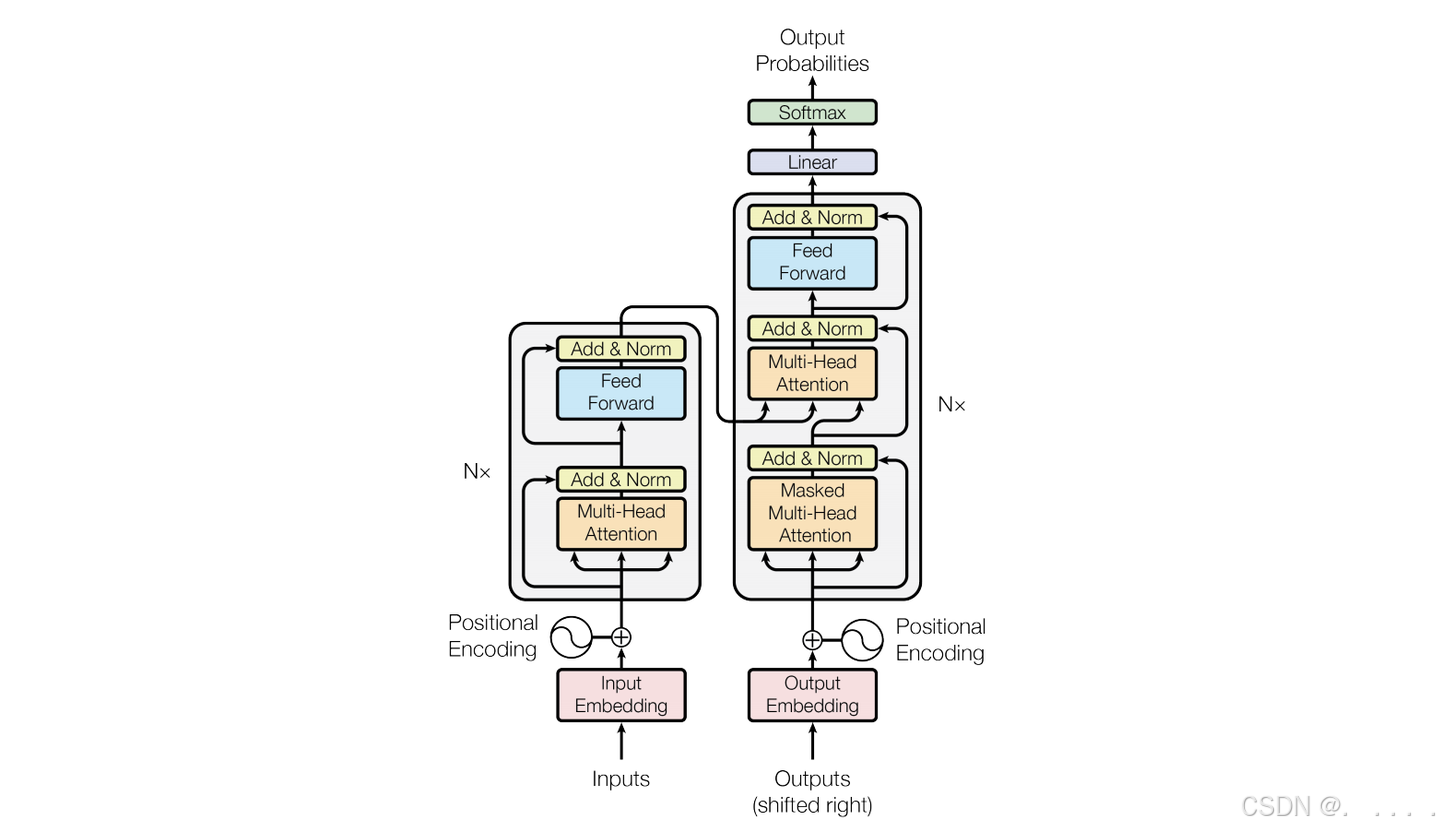
GPT底层原理浅析
GPT为什么这么强?
Transformer架构详解
Transformer是由Google 2017年提出的一种神经网络模型。
Transformer解决了什么问题?引用了Attention机制,解决了以前的模型关注不到上下文信息问题,例如:中国乒乓球谁也赢不了,中国足球谁也赢不了。
GPT1-GPT4发展迭代过程
站在程序员的视角看GPT调用
js
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const completion = await openai.chat.completions.create({
messages: [{ role: "system", content: "You are a helpful assistant." }],
model: "gpt-3.5-turbo",
});
console.log(completion.choices[0]);
}
main();ChatGPT多轮对话实现
GPT模型入参
多轮对话demo实现
js
const conversation = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
{"role": "assistant", "content": "Why did the chicken cross the road?"},
{"role": "user", "content": "I don't know. Why did the chicken cross the road?"}
];
const response = await openai.ChatCompletion.create({
model: "gpt-3.5-turbo",
messages: conversation,
max_tokens: 150
});
const generatedText = response.choices[0].message.content;
console.log(generatedText);
js
// 假设之前已经有一个对话历史 conversation
const previousAssistantResponse = response.choices[0].message.content;
// 将先前生成的助手回复追加到对话历史
conversation.push({"role": "assistant", "content": previousAssistantResponse});
// 发送带有更新对话历史的请求
const newResponse = await openai.ChatCompletion.create({
model: "gpt-3.5-turbo",
messages: conversation,
max_tokens: 150
});
const newGeneratedText = newResponse.choices[0].message.content;
console.log(newGeneratedText);注意: 如果不进行控制,对话历史(conversation)可能会不断增长,导致其变得庞大。这可能会对性能产生负面影响,因为更长的对话历史需要更多的计算资源,并可能增加响应时间。
为了应对这个问题,开发者可以选择在对话历史中保留一定数量的消息,而不是保留整个对话历史。这样可以平衡上下文的保存和资源消耗之间的关系。您可以根据应用的需求和性能要求来决定保留多少消息。
js
const MAX_HISTORY_LENGTH = 5; // 设置最大历史消息数量
// 保留最近的 MAX_HISTORY_LENGTH 条消息
if (conversation.length >= MAX_HISTORY_LENGTH) {
conversation.shift(); // 移除最早的消息
}
// 将生成的文本追加到对话历史
conversation.push({"role": "assistant", "content": previousAssistantResponse});
// 发送带有更新对话历史的请求
const newResponse = await openai.ChatCompletion.create({
model: "gpt-3.5-turbo",
messages: conversation,
max_tokens: 150
});
const newGeneratedText = newResponse.choices[0].message.content;
console.log(newGeneratedText);Function calling
获取当日天气情况-Function calling实现
js
import OpenAI from "openai";
const openai = new OpenAI();
// Example dummy function hard coded to return the same weather
// In production, this could be your backend API or an external API
function getCurrentWeather(location, unit = "fahrenheit") {
if (location.toLowerCase().includes("tokyo")) {
return JSON.stringify({ location: "Tokyo", temperature: "10", unit: "celsius" });
} else if (location.toLowerCase().includes("san francisco")) {
return JSON.stringify({ location: "San Francisco", temperature: "72", unit: "fahrenheit" });
} else if (location.toLowerCase().includes("paris")) {
return JSON.stringify({ location: "Paris", temperature: "22", unit: "fahrenheit" });
} else {
return JSON.stringify({ location, temperature: "unknown" });
}
}
async function runConversation() {
// Step 1: send the conversation and available functions to the model
const messages = [
{ role: "user", content: "What's the weather like in San Francisco, Tokyo, and Paris?" },
];
const tools = [
{
type: "function",
function: {
name: "get_current_weather",
description: "Get the current weather in a given location",
parameters: {
type: "object",
properties: {
location: {
type: "string",
description: "The city and state, e.g. San Francisco, CA",
},
unit: { type: "string", enum: ["celsius", "fahrenheit"] },
},
required: ["location"],
},
},
},
];
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo-1106",
messages: messages,
tools: tools,
tool_choice: "auto", // auto is default, but we'll be explicit
});
const responseMessage = response.choices[0].message;
// Step 2: check if the model wanted to call a function
const toolCalls = responseMessage.tool_calls;
if (responseMessage.tool_calls) {
// Step 3: call the function
// Note: the JSON response may not always be valid; be sure to handle errors
const availableFunctions = {
get_current_weather: getCurrentWeather,
}; // only one function in this example, but you can have multiple
messages.push(responseMessage); // extend conversation with assistant's reply
for (const toolCall of toolCalls) {
const functionName = toolCall.function.name;
const functionToCall = availableFunctions[functionName];
const functionArgs = JSON.parse(toolCall.function.arguments);
const functionResponse = functionToCall(
functionArgs.location,
functionArgs.unit
);
messages.push({
tool_call_id: toolCall.id,
role: "tool",
name: functionName,
content: functionResponse,
}); // extend conversation with function response
}
const secondResponse = await openai.chat.completions.create({
model: "gpt-3.5-turbo-1106",
messages: messages,
}); // get a new response from the model where it can see the function response
return secondResponse.choices;
}
}
runConversation().then(console.log).catch(console.error);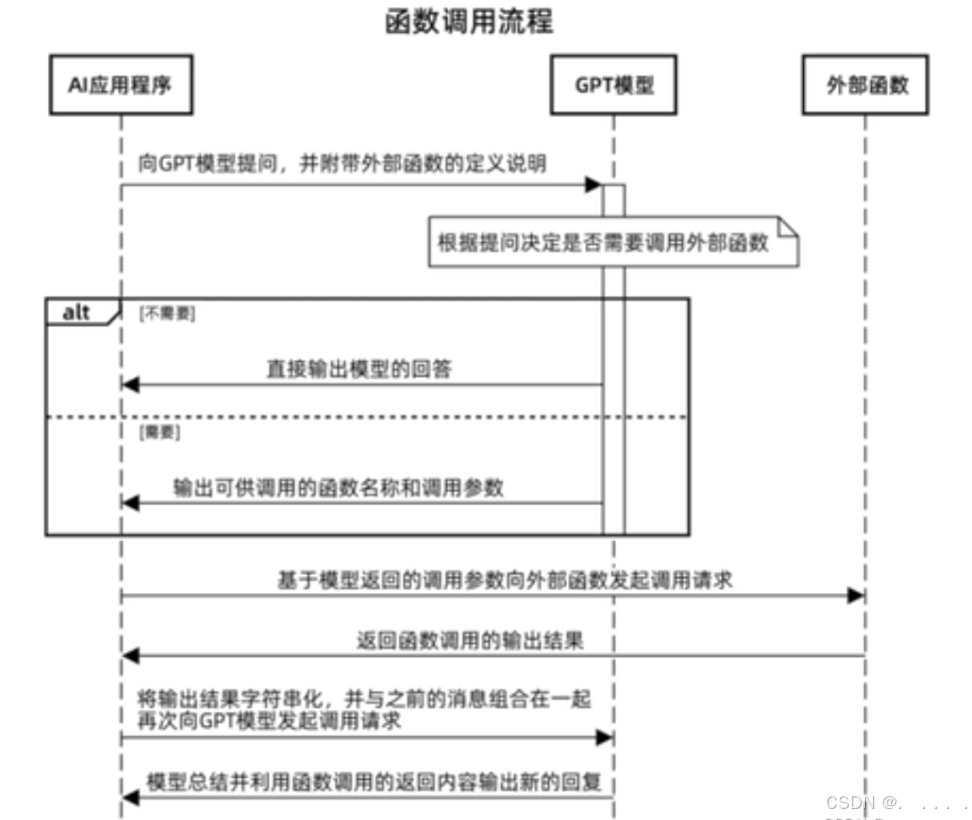
当前页面属于所属技术栈、一键分类功能
GPT训练实战
openAI GPT开发平台
1、领取openAI keys
2、将秘钥保存到环境变量中 - 建议
3、在Python中调用openAI API
开源大模型有哪些?
国外:
国内:
如何训练一个大模型?
训练一个大模型的一般过程
1. 预训练阶段
大模型首先在大量的无标签数据上进行训练,预训练的最终目的是让模型学习到语言的统计规律 和一般知识。在这个过程中模型能够学习到词语的语义、句子的语法结构、以及文本的一般知识和上下文信息。需要注意的是,预训练本质上是 一个无监督学习过程;
预训练模型的核心模型特征:
自回归与生成式
- 自回归概念,大模型的预训练过程是采用了一种名为自回归 (Autoregressive)的方法,自回归模型是一种序列模型,它在预测下一个输出时,会将之前的所有输出作为输入,然后根据统计规律、结合已经输入的样本,预测下个位置各单词出现的概率,然后输出概率最大的单词,类似于完形 填空;
- 生成式概念:生成式模型可以根据之前的样本的概率分布生成下一个词,生成式模型预测时会存在一定的随机性;
双向自回归与自回归:
主要的区别就在于自回归模型只看前文,而双向自回归 模型会同时考虑前文和后文。
得到预训练模型(Pretrained Model), 也被称为基座模型(Base Model),模型具备通用的预测能力。如GLM-130B模 型、OpenAI的A、B、C、D四大模型,都 是基座模型;
2. 微调阶段
预训练好的模型然后在特定任务的数据 上进行进一步的训练。这个过程通常涉 及对模型的权重进行微小的调整,以使 其更好地适应特定的任务;
得到最终能力各异的模型,例如 gpt code系列、gpt text系列、ChatGLM-6B等模型;
部署大模型的硬件基础
LangChain
诞生背景
LangChain是什么?
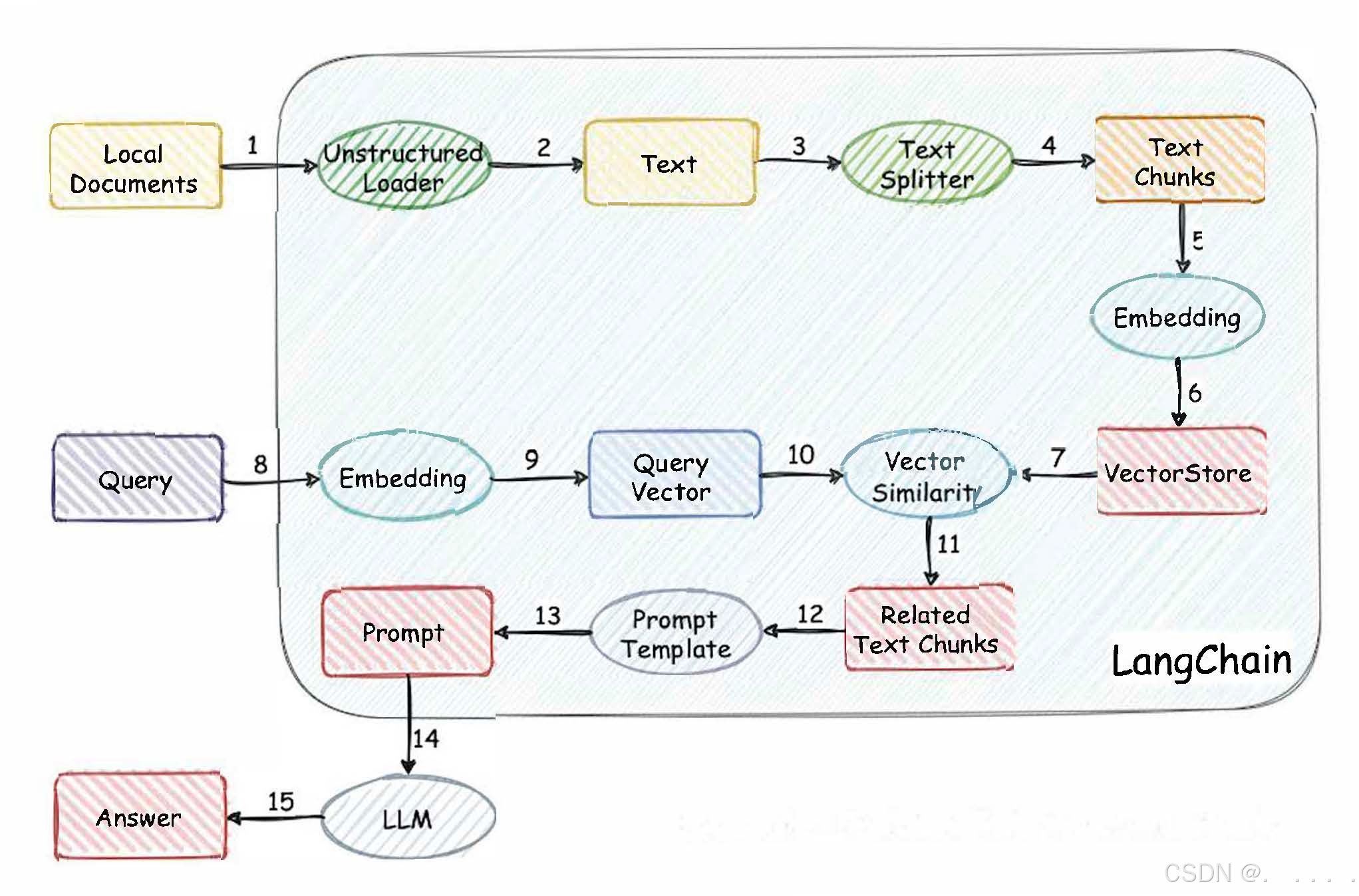
LangChain的六大功能模块
LangChain认为,未来的基于LLM的AI应用都是基于 这六个元素拼凑而成,类似乐高积木。
- Models:LangChain认为,AI应用开发必不可少的就是LLM,因此提供了非常便捷的接入各LLM的接口,包括GPT模型和ChatGLM-6B,均可以通过 LangChain的Models接口进行调用;
- Prompts:LangChain认为,简化提示难度、丰富提示灵活度是未来AI应用 之必须,因此提供了Prompts功能模块,用于给开发者提供灵活的自定义提 示模版的功能;
- Chains:LangChain认为,为了更好的理解人类意图,AI工具的内部执行流程 应该类似于管道流水线,这种流程在机器学习领域被称为Pipeline,在 LangChain的定义中被称为Chains;
- Agents:LangChain认为,未来AI工具必然需要和本地工具进行交互,例如 自主在谷歌浏览器上进行搜索互联网上结果等,此时AI工具内部需要创建一个 代理来使用这些工具,进而拓展AI工具本身的功能,这就是所谓的Agents;
- Memory:LangChain认为,记住人类的提示和自身操作将是提升用户体验的 关键,因此必须要通过某些方法来存储这些信息。相关存储信息的方法都被封 装在LangChain的Memory模块中;
- Index:这是截止目前LangChain最后添加的功能模块,用于提供本地文件索 引的功能,从而让AI工具更方便的进行本地文件的管理;