大家好,我是唐叔!又是干货分享时间!今天我要给大家安利的这个pypandoc ,绝对是Python生态中处理文档转换的隐藏神器!它不仅能帮你轻松搞定几十种文档格式的相互转换,还能无缝集成到你的自动化脚本中。接下来,就跟着唐叔一起深入了解这个利器吧!
一、什么是pypandoc?为什么你需要它?
pypandoc是一个Python包装器,它封装了强大的Haskell库pandoc。pandoc被誉为"文档转换的瑞士军刀",支持在Markdown、HTML、LaTeX、Word、PDF等数十种格式之间进行转换。
核心优势:
- 支持格式丰富:覆盖了开发中常见的所有文档格式
- 转换质量高:保持文档结构和样式的高度一致性
- Pythonic接口:提供简洁的Python API,易于集成到现有项目中
- 跨平台:Windows、Linux、macOS全平台支持
二、安装与配置:快速上手
基础安装
bash
pip install pypandoc安装pandoc后端
pypandoc需要pandoc作为后端,如果系统未安装,可以使用以下命令自动安装:
bash
# 自动下载并安装pandoc
import pypandoc
pypandoc.download_pandoc()或者手动安装pandoc后,pypandoc会自动检测系统安装的版本。
可以参考唐叔的另一篇文章:【问题解决】pypandoc报错"No pandoc was found"?三步搞定环境配置!-CSDN博客
三、基础用法:从简单示例开始
示例1:Markdown转Word
这是最常见的场景,将技术文档从Markdown转换为Word:
python
import pypandoc
# 将Markdown转换为Word
output = pypandoc.convert_file(
'demo.md', # 源文件
'docx', # 转换格式
outputfile='demo.docx' # 目标文件
)
print(f"转换成功:{output}")整体文本内容转换效果基本一致,字体格式、换行等则没有完全保持一致。
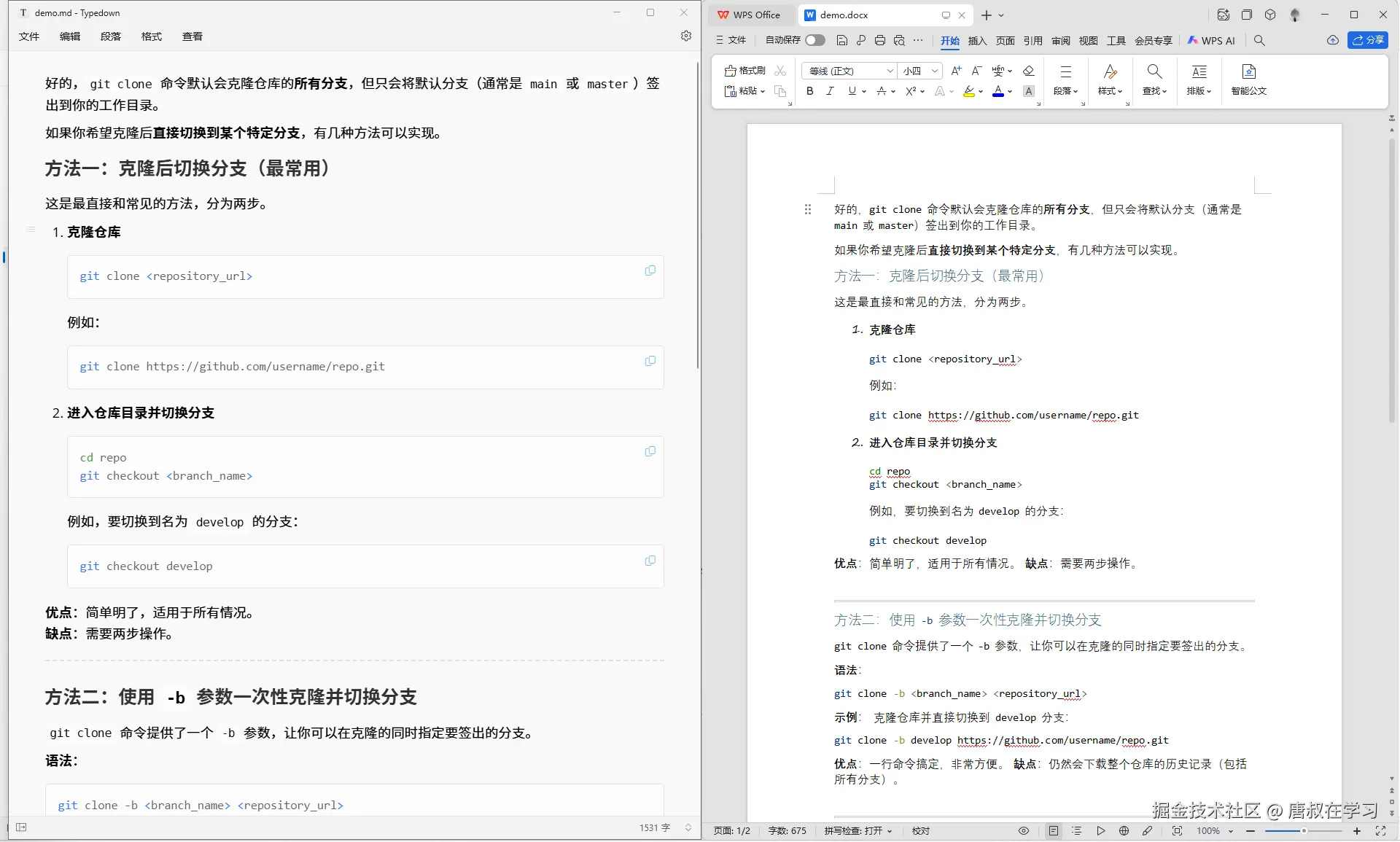
示例2:HTML转Markdown
从网页内容提取并转换为Markdown:
python
import pypandoc
html_content = """
<h1>Python开发指南</h1>
<p>这是一份<strong>重要</strong>的开发文档</p>
<ul>
<li>列表项1</li>
<li>列表项2</li>
</ul>
"""
markdown_output = pypandoc.convert_text(
html_content,
'md',
format='html'
)
print(markdown_output)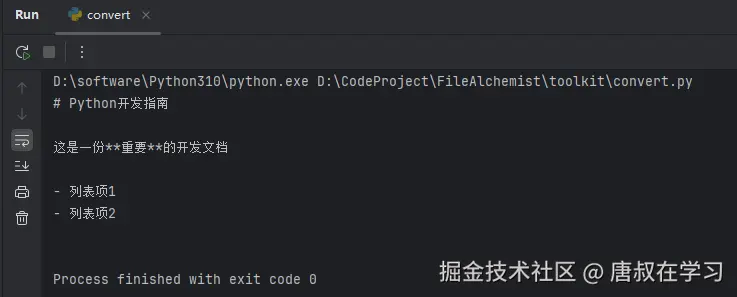
pandoc支持的常见格式转换还有很多,具体清单,可以见本文附录。
四、实战场景:开发中的典型应用
场景1:技术文档自动化转换
在CI/CD流水线中自动生成多种格式的文档:
python
import pypandoc
from pathlib import Path
def convert_tech_docs(md_file):
"""将技术文档转换为多种格式"""
base_name = Path(md_file).stem
# 转换为Word
pypandoc.convert_file(
md_file,
'docx',
outputfile=f'{base_name}.docx'
)
# 转换为PDF(需要LaTeX环境)
try:
pypandoc.convert_file(
md_file,
'pdf',
outputfile=f'{base_name}.pdf'
)
except Exception as e:
print(f"PDF转换失败(需要安装LaTeX): {e}")
# 转换为HTML
pypandoc.convert_file(
md_file,
'html',
outputfile=f'{base_name}.html'
)
print("文档转换完成!")
# 使用示例
convert_tech_docs('API参考文档.md')场景2:Jupyter Notebook批量导出
批量处理Notebook文件转换:
python
import pypandoc
import json
def notebook_to_markdown(notebook_file):
"""将Jupyter Notebook转换为Markdown"""
with open(notebook_file, 'r', encoding='utf-8') as f:
notebook_data = json.load(f)
markdown_content = []
for cell in notebook_data['cells']:
if cell['cell_type'] == 'markdown':
markdown_content.append(''.join(cell['source']))
full_markdown = '\n\n'.join(markdown_content)
output_file = notebook_file.replace('.ipynb', '.md')
with open(output_file, 'w', encoding='utf-8') as f:
f.write(full_markdown)
return output_file
# 转换为其他格式
markdown_file = notebook_to_markdown('数据分析教程.ipynb')
pypandoc.convert_file(markdown_file, 'docx', outputfile='数据分析教程.docx')场景3:博客内容批量处理
将本地Markdown博客转换为发布所需的HTML:
python
import pypandoc
import os
def process_blog_posts(directory):
"""处理博客目录下的所有Markdown文件"""
for filename in os.listdir(directory):
if filename.endswith('.md'):
md_file = os.path.join(directory, filename)
html_file = md_file.replace('.md', '.html')
# 转换为带样式的HTML
pypandoc.convert_file(
md_file,
'html',
outputfile=html_file,
extra_args=['--self-contained', '--css', 'blog-style.css']
)
print(f"已转换: {filename}")
# 使用示例
process_blog_posts('./blog_posts')五、高级技巧:定制化转换
使用过滤器增强功能
pandoc支持使用过滤器来增强转换过程:
python
# 需要先安装pandoc过滤器
# pip install pandoc-filters
def convert_with_filters():
"""使用过滤器进行高级转换"""
output = pypandoc.convert_file(
'document.md',
'docx',
filters=['pandoc-citeproc'], # 引用处理过滤器
outputfile='document_with_refs.docx'
)
return output自定义模板和样式
为不同输出格式定制样式:
python
# 使用自定义Word模板
pypandoc.convert_file(
'report.md',
'docx',
outputfile='report.docx',
extra_args=['--reference-doc', 'custom-template.docx']
)
# 自定义PDF样式
pypandoc.convert_file(
'thesis.md',
'pdf',
outputfile='thesis.pdf',
extra_args=[
'--pdf-engine=xelatex',
'--template', 'eisvogel',
'-V', 'mainfont=SimSun'
]
)六、常见问题与解决方案
问题1:中文字符支持
确保正确处理中文文档:
python
def convert_chinese_document():
"""处理中文文档转换"""
output = pypandoc.convert_file(
'中文文档.md',
'docx',
outputfile='中文文档.docx',
extra_args=[
'--pdf-engine=xelatex', # 使用xelatex引擎支持中文
'-V', 'CJKmainfont=SimSun' # 设置中文字体
]
)
return output问题2:批量处理性能优化
处理大量文档时的优化策略:
python
from concurrent.futures import ThreadPoolExecutor
import pypandoc
def batch_convert_files(file_list, target_format):
"""批量转换文件,使用多线程提高效率"""
def convert_single_file(input_file):
output_file = input_file.replace('.md', f'.{target_format}')
try:
pypandoc.convert_file(
input_file,
target_format,
outputfile=output_file
)
return f"成功: {input_file}"
except Exception as e:
return f"失败: {input_file} - {e}"
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(convert_single_file, file_list))
return results七、总结
通过今天的学习,相信大家已经掌握了pypandoc这个强大的文档转换工具。让我们回顾一下重点:
- 安装简单:pip install pypandoc即可开始使用
- 功能强大:支持数十种文档格式的相互转换
- 应用场景丰富:从技术文档自动化到博客内容处理都能胜任
- 高度可定制:支持过滤器、模板等高级功能
- 开发友好:提供Pythonic的API,易于集成
pypandoc真正实现了"一次编写,多处发布"的文档工作流,极大提升了开发效率。特别是在自动化脚本、CI/CD流水线、内容管理系统等场景中,它都能发挥巨大作用。
唐叔的建议:在日常开发中,善用pypandoc这样的工具,能够让你从繁琐的文档格式处理中解放出来,更专注于核心开发工作。赶快把它加入到你的开发工具箱吧!
附录:pypandoc核心支持格式清单
附录1:pypandoc支持的输入格式
这些是pypandoc可以读取和理解的源文件格式。你可以把这些格式的文档作为转换的起点。
| 格式 | 文件扩展名 | 说明 & 典型应用场景 |
|---|---|---|
| Markdown | .md, .markdown |
最常用输入格式。写技术文档、博客、README的首选。 |
| CommonMark | .md |
Markdown的标准化版本,兼容性更好。 |
| GitHub-Flavored Markdown | .md |
GitHub风格的Markdown,支持表格、任务列表等。 |
| HTML | .html, .htm |
热点场景:爬虫抓取网页内容后,转为结构化文档。 |
| Jupyter Notebook | .ipynb |
热点场景:将数据分析结果或机器学习笔记转换成报告或文档。 |
| Microsoft Word | .docx |
办公自动化:读取Word文档内容,转为其他格式进行再处理。 |
| LaTeX | .tex |
学术论文写作,可转换为更通用的格式进行分享。 |
| reStructuredText | .rst |
Python官方文档常用格式。 |
| AsciiDoc | .adoc, .asciidoc |
另一种强大的轻量级标记语言。 |
| Textile | .textile |
主要用于一些老牌的Wiki系统。 |
| OPML | .opml |
大纲处理,常用于思维导图工具导出。 |
| Haddock | 无 | Haskell的文档格式。 |
| MediaWiki | 无 | Wikipedia使用的格式。 |
| DokuWiki | 无 | DokuWiki系统使用的格式。 |
| JATS | 无 | 主要用于学术出版。 |
附录2:pypandoc支持的输出格式
这些是pypandoc可以转换生成的目标文件格式。你可以把源文档变成你需要的任何样子。
| 格式 | 文件扩展名 | 说明 & 典型应用场景 |
|---|---|---|
| Microsoft Word | .docx |
最常用输出之一。交给产品、运营等非技术同事审阅。 |
.pdf |
最常用输出之二。用于正式提交、邮件发送、存档。 | |
| HTML | .html |
热点场景:生成静态博客、项目文档网站、邮件正文。 |
| HTML5 | .html |
现代HTML标准,支持更多新特性。 |
| LaTeX | .tex |
作为生成PDF的中间步骤,或进行学术投稿。 |
| EPUB | .epub |
数字出版:制作电子书。 |
| Markdown | .md |
格式标准化,或将复杂格式简化为纯文本。 |
| CommonMark | .md |
输出标准化的Markdown。 |
| GitHub-Flavored Markdown | .md |
输出适合在GitHub上显示的Markdown。 |
| reStructuredText | .rst |
为Python项目生成官方文档。 |
| AsciiDoc | .adoc |
转换为另一种强大的文档格式。 |
| JATS | .xml |
用于学术期刊投稿。 |
| Man Page | 无 | 为Linux/Unix系统生成手册页。 |
| Plain Text | .txt |
提取纯文本内容,用于摘要或简单查看。 |
| OPML | .opml |
生成大纲,可导入思维导图工具。 |
| MediaWiki | 无 | 发布到Wikipedia等Wiki平台。 |
| DokuWiki | 无 | 发布到DokuWiki系统。 |
| Slidy | 无 | 生成网页版的幻灯片。 |
| Slideous | 无 | 生成网页版的幻灯片。 |
| DZSlides | 无 | 生成网页版的幻灯片。 |
| Reveal.js | .html |
热点场景:生成非常酷炫的网页版演示文稿。 |