Hello!这里是程序员 Feri------ 13 年 + 开发经验、带过团队、创过业,专注分享编程知识干货。
感谢你的关注与交流,愿我们能相伴你的编程路。
数据预处理:数据清洗的艺术(食材筛选指南)
数据如同烹饪食材:既有新鲜可用的正常数据,也有需要剔除的异常值,还有重复多余的冗余特征------未经处理直接使用,再优秀的"菜谱"(模型)也难以烹制出美味佳肴。
1.1 异常值识别:数据中的"离群分子"
以房价预测为例,当出现"100平米售价1000万"的异常记录(通常由录入错误导致),这类"极端值"会误导模型得出"所有房屋都能卖出天价"的错误结论,必须预先清理。
操作指南:基于IQR的异常值检测法
类似于划定儿童身高标准范围(如小学1-3年级正常身高1.1-1.4米),我们为数据设定"合理区间",超出此范围即视为异常值。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 配置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 1. 生成模拟房价数据(100套房源)
np.random.seed(42) # 固定随机种子保证结果可复现
X = 2 * np.random.rand(100, 1) # 房屋面积:0-200㎡(缩小100倍便于计算)
y = 4 + 3 * X + np.random.randn(100, 1) # 基准房价:40万+3万/㎡+随机波动
# 人为添加异常值(录入错误案例)
y[10] = 20 # 原值70万误录为200万
y[25] = 25 # 原值85万误录为250万
# 2. 箱线图异常值检测
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.boxplot(y, vert=False, tick_labels=['房价(10万)'])
plt.title('原始数据:红圈标注异常房价')
plt.grid(alpha=0.3)
# 3. IQR法计算合理范围
Q1 = np.percentile(y, 25) # 下四分位数
Q3 = np.percentile(y, 75) # 上四分位数
IQR = Q3 - Q1 # 四分位距
lower_bound = Q1 - 1.5 * IQR # 合理范围下限
upper_bound = Q3 + 1.5 * IQR # 合理范围上限
# 4. 数据清洗(保留正常范围数据)
y_flat = y.ravel()
normal_idx = (y_flat >= lower_bound) & (y_flat <= upper_bound)
X_clean = X[normal_idx]
y_clean = y[normal_idx]
# 5. 清洗效果可视化
plt.subplot(1, 2, 2)
plt.boxplot(y_clean, vert=False, tick_labels=['房价(10万)'])
plt.title('清洗后:异常值已移除')
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
# 6. 模型效果对比
# 原始数据建模
X_train_bad, X_test_bad, y_train_bad, y_test_bad = train_test_split(X, y, test_size=0.2, random_state=42)
y_train_bad_flat = y_train_bad.ravel()
y_test_bad_flat = y_test_bad.ravel()
model_bad = LinearRegression()
model_bad.fit(X_train_bad, y_train_bad_flat)
y_pred_bad = model_bad.predict(X_test_bad)
mse_bad = mean_squared_error(y_test_bad_flat, y_pred_bad)
# 清洗后数据建模
X_train_good, X_test_good, y_train_good, y_test_good = train_test_split(X_clean, y_clean, test_size=0.2, random_state=42)
y_train_good_flat = y_train_good.ravel()
y_test_good_flat = y_test_good.ravel()
model_good = LinearRegression()
model_good.fit(X_train_good, y_train_good_flat)
y_pred_good = model_good.predict(X_test_good)
mse_good = mean_squared_error(y_test_good_flat, y_pred_good)
print(f"原始数据MSE:{mse_bad:.2f}(预测误差较大)")
print(f"清洗后MSE:{mse_good:.2f}(预测精度显著提升)")
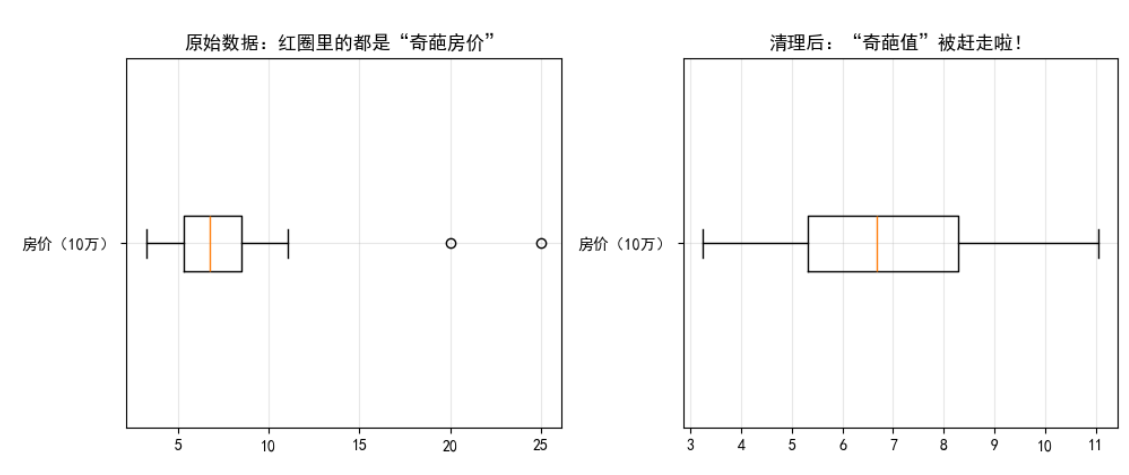
核心洞见:
- 箱线图中的离群点如同班级里的异常身高,直观醒目
- MSE降低验证了清洗效果------如同剔除变质食材能提升菜品质量
- 数据预处理是保证模型效果的基础工序,重要性不亚于烹饪前的食材准备