python爬虫之分页抓取数据
一、环境准备
-
requests:发出请求
-
pandas:保存数据到 csv文件
-
依赖安装命令:
yamlpip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
二、爬取思路
- 分析api中返回的分页参数, 获取api中返回的数据总条数, 如下图

- 总页数为 总条数(count) / 每页条数(limit), 通过math函数取上界
- 计算request需要的分页参数 limit 和 offset, 请求时传入
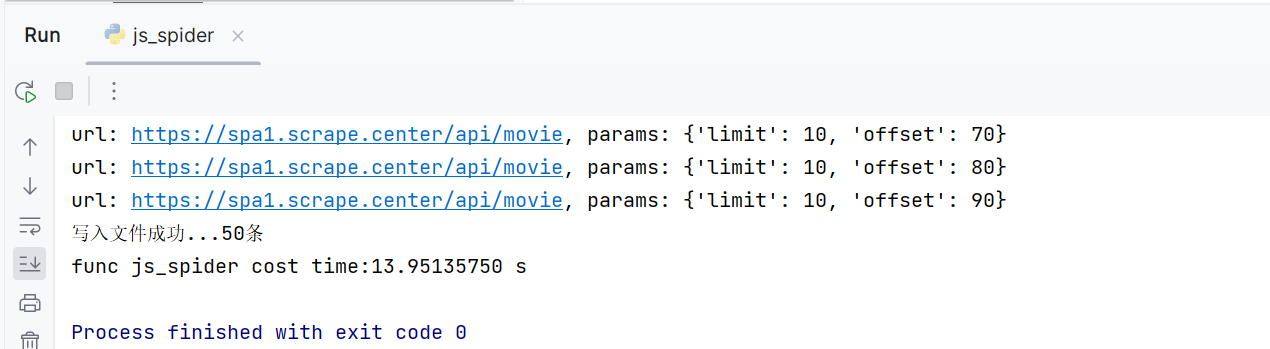
- 循环抓取直至最后一页, 数据量过多, 可以进行分批写入
- 通过装饰器模式 计算程序总执行时间
三、代码示例
python
import requests
import pandas as pd
import math
import time
import os
def request(url, params):
print(f'url: {url}, params: {params}')
r = requests.get(url, params=params);
return r.json();
def parseJson(json_data):
movie_list = []
results = json_data['results']
for result in results:
movie_info = {'name': f"{result['name']} - {result['alias']}",
'categories': ','.join(result['categories']),
'location': ','.join(result['regions']),
'duration': result['minute'],
'release_date': result['published_at'],
'score': result['score']}
movie_list.append(movie_info)
return movie_list
def save(data):
df = pd.DataFrame(data);
# 设置表头
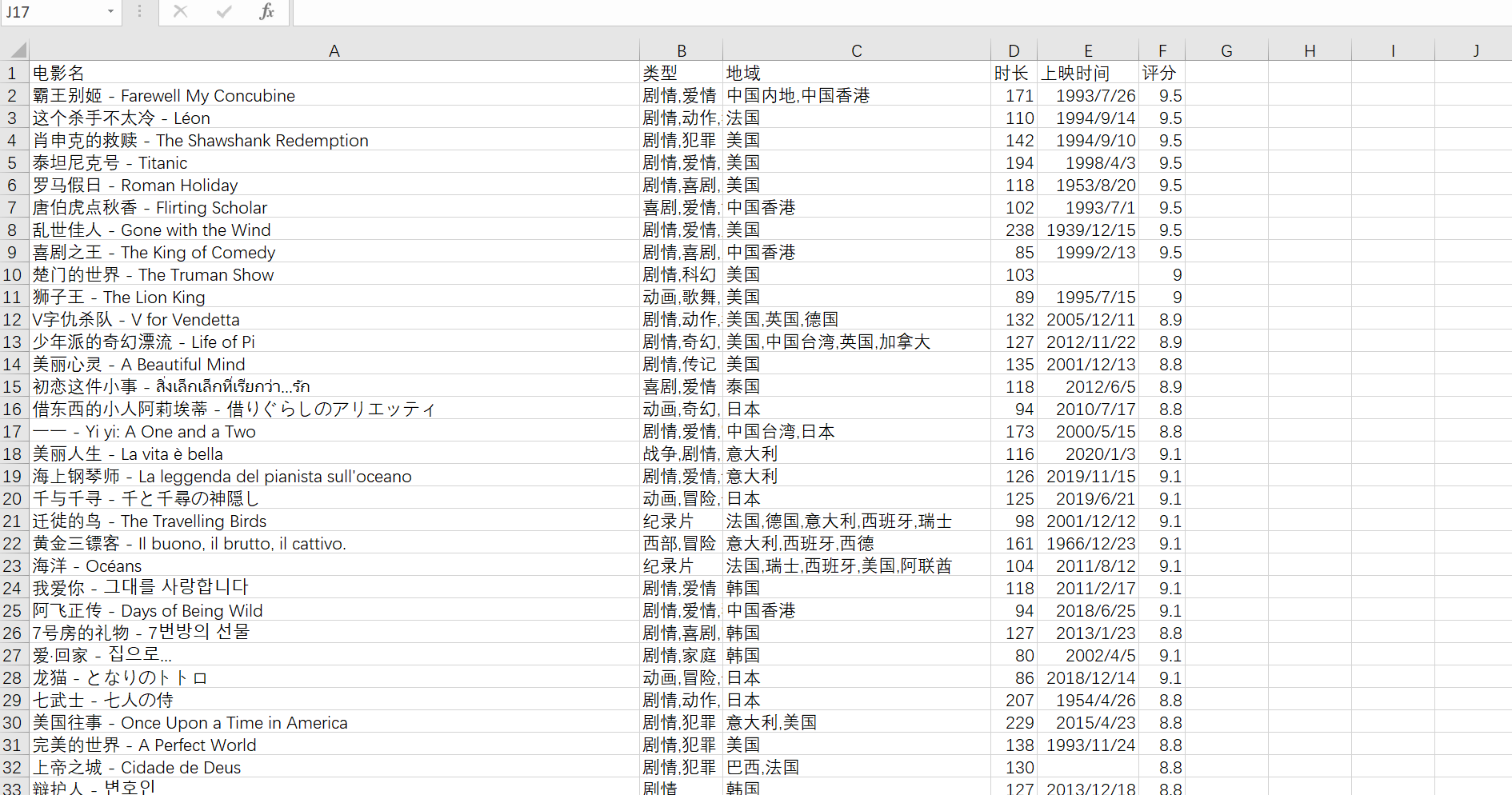
df.columns = ['电影名', '类型', '地域', '时长', '上映时间', '评分'];
df.to_csv(file_path, index=False, encoding='utf-8-sig', mode='a', header=not os.path.exists(file_path));
print(f'写入文件成功...{len(data)}条')
# 计算耗费时间
def cost_time(func):
def fun(*args, **kwargs):
t = time.perf_counter()
result = func(*args, **kwargs)
print(f'func {func.__name__} cost time:{time.perf_counter() - t:.8f} s')
return result
return fun
movie_list = []
file_path = 'data_js.csv'
@cost_time
def js_spider():
index = 1;
limit = 10;
total_page = 1;
url = 'https://spa1.scrape.center/api/movie';
while (True):
offset = (index - 1) * limit;
params = {
'limit': limit,
'offset': offset
}
# 发出请求
jsonData = request(url, params)
# 解析json
movie_list_page = parseJson(jsonData)
movie_list.extend(movie_list_page)
# 分批写入文件
if len(movie_list) >= 50:
save(movie_list)
movie_list.clear()
# 获取总页数, 网址最后一页数据有问题, 所以取下界
if index == 1:
total_page = math.floor(jsonData['count'] / limit);
elif index == total_page:
break
index += 1
time.sleep(0.2)
# 存储剩余的数据
if len(movie_list) > 0:
save(movie_list)
if __name__ == '__main__':
js_spider()四、结果展示